

Imagina esto: lanzas tu sitio web, listo para recibir una avalancha de clientes entusiasmados, y descubres que la mitad de tu tráfico son… robots. No de ciencia ficción, sino rastreadores digitales: motores de búsqueda, bots de IA, arañas de analítica, todos recorriendo tu sitio día y noche, como un desfile interminable de invitados invisibles. En 2026, esto ya no es una curiosidad más en los registros del servidor; es la nueva normalidad. Entender quién —o qué— rastrea tu sitio, con qué frecuencia y por qué, ya forma parte esencial de dirigir cualquier negocio online.
Como alguien que ha pasado años en SaaS, automatización e IA, he visto cómo el web crawling ha pasado de ser un detalle técnico entre bastidores a convertirse en un reto empresarial de primer nivel. Las cifras son impactantes: los bots ya representan casi la mitad de todo el tráfico de internet, y en algunos lugares superan a los humanos. Con el auge de los rastreadores impulsados por IA, que absorben contenido para entrenar grandes modelos de lenguaje, la apuesta nunca había sido tan alta: para tu infraestructura, tu presupuesto y tu marca. Vamos a analizar las últimas estadísticas de web crawling, las referencias del sector y lo que todo esto significa para tu negocio en 2026.
Web Crawling en 2026: una foto del panorama
Extrae datos de cualquier sitio web usando IA Get Started Free
El web crawling ha alcanzado un nivel completamente nuevo de escala y complejidad. Cada día, miles de millones de solicitudes automatizadas recorren internet, enviadas por una legión cada vez mayor de rastreadores. Tradicionalmente, los bots de motores de búsqueda como Googlebot y Bingbot eran los protagonistas, indexando páginas para que los usuarios pudieran encontrarlas en los resultados de búsqueda. Pero ahora se les suma una nueva generación: rastreadores de datos para IA, scrapers de redes sociales, bots de analítica y más.
Aquí va la cifra principal, y depende de la forma en que la midas. El informe Year in Review 2025 de Cloudflare mostró que bots y rastreadores de IA juntos representaban aproximadamente el 53% de las solicitudes HTML en su red a principios de diciembre de 2025, mientras el tráfico humano caía al 47%. Imperva, analizando su propia base de clientes empresariales en el Bad Bot Report 2026 (publicado el 29 de abril de 2026), llegó a la misma conclusión para el año natural 2025: 53% bots, 47% humanos, frente al 51/49 del año anterior. Dos perspectivas muy distintas, el mismo hallazgo: el tráfico automatizado ya es la mayor mitad de la web. La novedad no es solo el volumen, sino el elenco. Antes los indexadores de búsqueda dominaban la categoría de bots. En 2026, una parte cada vez mayor corresponde a rastreadores de entrenamiento de IA que alimentan chatbots y motores de respuesta.
El panorama es más diverso que nunca:
- Bots buenos: indexadores de búsqueda, monitores de disponibilidad, scrapers de datos legítimos.
- Bots malos: spam, hacking, scraping no autorizado.
- Rastreadores de IA: los recién llegados, que recopilan contenido para entrenamiento de IA y respuestas en tiempo real.
Los rastreadores de IA suelen comportarse de forma distinta a sus primos de los motores de búsqueda. Pueden recuperar el contenido completo de una página para análisis semántico, no solo indexar palabras clave, y suelen operar a gran escala: a veces inundan los sitios con millones de solicitudes en cuestión de días. ¿El resultado? El web crawling ya es ubicuo, crece y se diversifica, combinando la indexación tradicional con el apetito insaciable de la IA por los datos.
Estadísticas clave de web crawling que toda empresa debería conocer
Vamos con los números que están dando forma a la web en 2026. Estas cifras no son solo para lucirse en una trivia: son las referencias que deberían guiar tu infraestructura, tu estrategia de contenidos y tu resultado final.
Bots vs. humanos: ¿quién está ganando la guerra del tráfico?
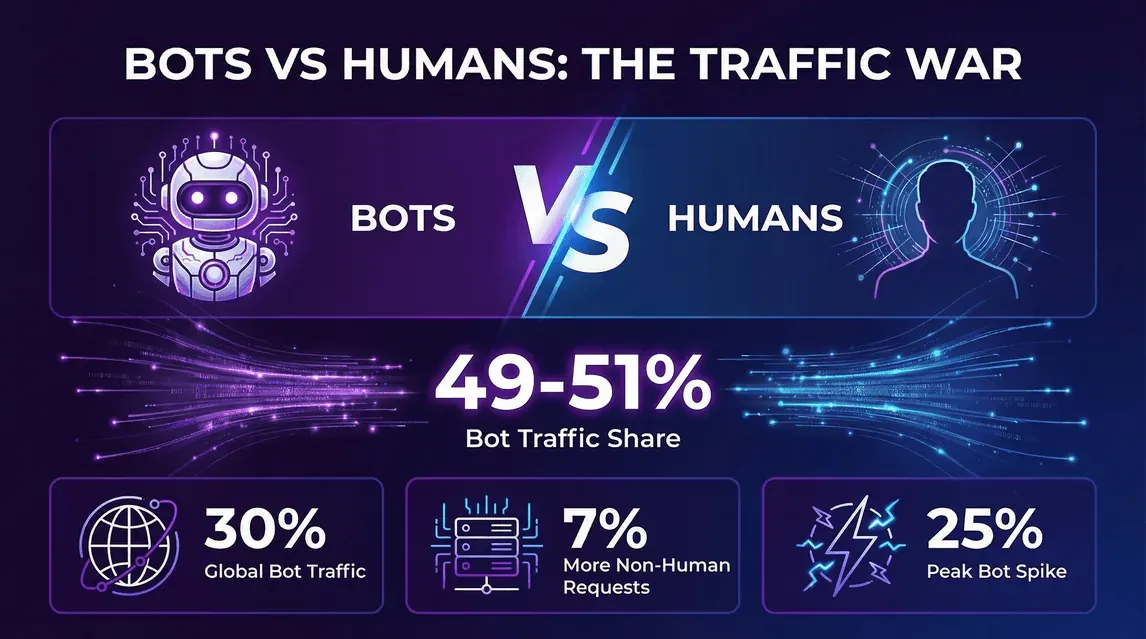
- Imperva, Bad Bot Report 2026 (abril de 2026): el tráfico automatizado alcanzó el 53% de todo el tráfico web en 2025, frente al 51% en 2024. En consecuencia, el tráfico humano bajó del 49% al 47%.
- Cloudflare Year in Review 2025: a 2 de diciembre de 2025, el 47% de las solicitudes HTML en la red de Cloudflare provenían de humanos, el 44% de bots no relacionados con IA y otro ~9% de bots de IA y Googlebot combinados.
- La tendencia no es un simple bache trimestral: Imperva ha mostrado un aumento de la cuota de bots cada año desde 2019, y el salto entre 2024 y 2025 estuvo impulsado sobre todo por rastreadores de entrenamiento de IA, no por la combinación habitual de scraping y credential stuffing.
- Qué significa para los propietarios de sitios: si tus analíticas no filtran bots, aproximadamente la mitad de tus solicitudes brutas no viene de una persona. Dimensionar la infraestructura con base en registros sin segmentar bots te hará sobredimensionar; y quedarte corto en la capacidad para gestionar bots perjudicará a la mitad que SÍ es humana.
El auge de los rastreadores de IA
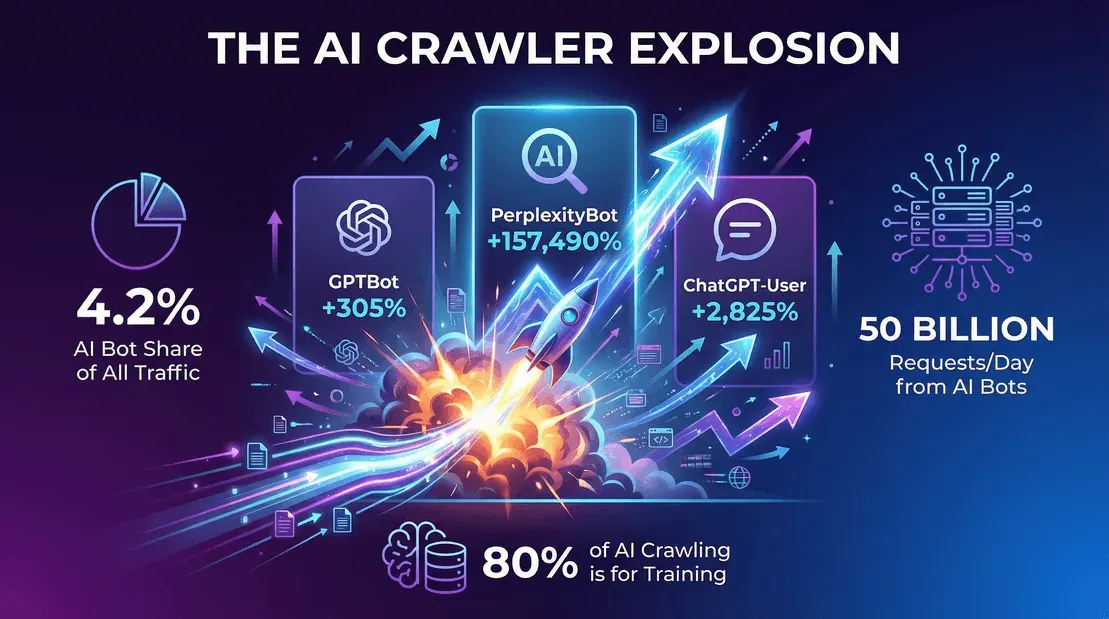
- La cuota de tráfico de bots de IA sigue subiendo. Según el Year in Review 2025 de Cloudflare, los bots de IA (excluyendo Googlebot) representaban aproximadamente el 4,2% de las solicitudes HTML a finales de 2025, mientras que Googlebot por sí solo sumaba otro 4,5%. La categoría que no existía hace tres años ya casi tiene el mismo tamaño que Googlebot.
- GPTBot de OpenAI pasó del 7,7% de las solicitudes de rastreo en mayo de 2025 al 3,6% de las solicitudes de páginas únicas a finales de 2025 (Cloudflare YIR 2025). El porcentaje parece menor, pero eso se debe a que Cloudflare cambió el denominador a páginas únicas y a que el campo se volvió más concurrido. En volumen bruto, GPTBot sigue siendo uno de los tres principales rastreadores de IA en la web abierta.
- ClaudeBot de Anthropic se sitúa junto a Meta-ExternalAgent en torno al 2,4% de las solicitudes de páginas únicas a finales de 2025. La cuota relativa de ClaudeBot cayó interanualmente (bajó un 46% en la ventana de Cloudflare de mayo de 2024 a mayo de 2025) antes de repuntar cuando Anthropic aceleró el reentrenamiento.
- PerplexityBot sigue siendo pequeño en términos absolutos —alrededor del 0,06% de las solicitudes de páginas únicas a finales de 2025—, pero su trayectoria de crecimiento es la más pronunciada de todos los grandes bots de IA.
- Googlebot sigue siendo, con diferencia, el mayor rastreador de la web abierta. El Year in Review de Cloudflare lo situó en torno a 200 veces el volumen de páginas únicas de PerplexityBot.
El tráfico de rastreadores en contexto
Aquí tienes un ejemplo real de un hilo de Reddit a finales de 2025 — un desarrollador extrayendo 30 días de registros del servidor:
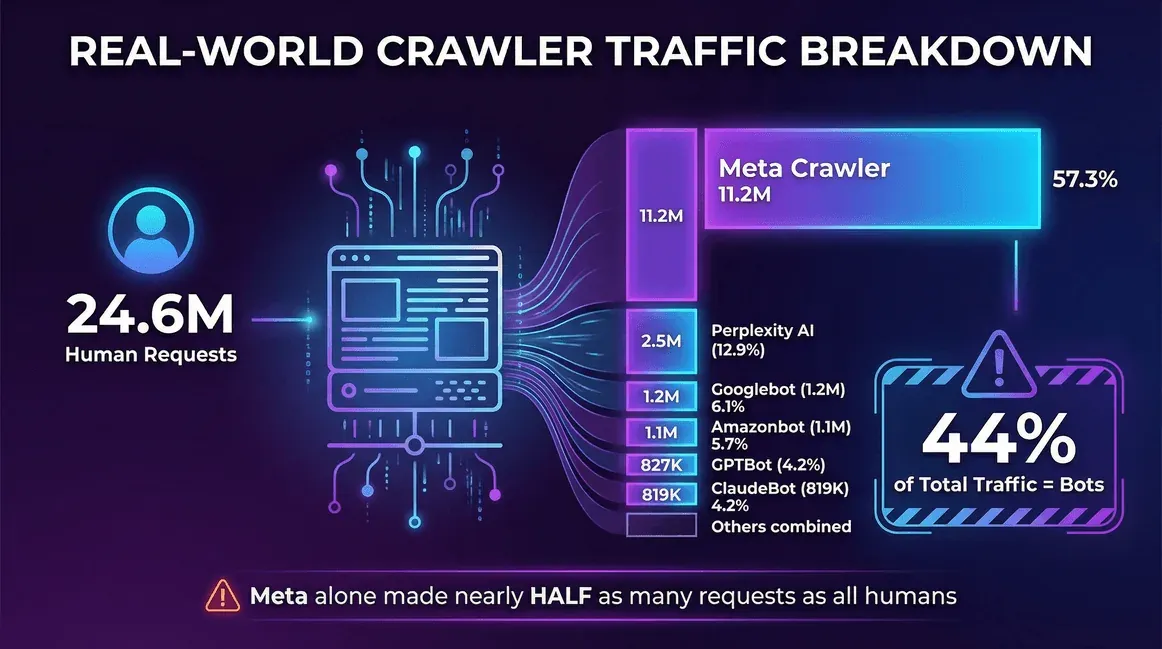
| Fuente de tráfico | Solicitudes (mensuales) | Cuota de rastreadores |
|---|---|---|
| Usuarios reales (humanos) | 24,647,904 | -- |
| Meta Crawler (Facebook) | 11,175,701 | 57,3% |
| Perplexity AI | 2,512,747 | 12,9% |
| Googlebot | 1,180,737 | 6,1% |
| Amazonbot | 1,120,382 | 5,7% |
| OpenAI GPTBot | 827,204 | 4,2% |
| ClaudeBot (Anthropic) | 819,256 | 4,2% |
| Bingbot | 599,752 | 3,1% |
| ChatGPT-User (OpenAI) | 557,511 | 2,9% |
| Ahrefs Crawler | 449,161 | 2,3% |
| ByteDance Spider | 267,393 | 1,4% |
En este sitio, los bots representaron el 44% del tráfico total; y el rastreador de Meta por sí solo realizó casi la mitad de solicitudes que todos los usuarios reales juntos.
La visión general
- El tráfico de rastreadores (bots de búsqueda + IA) creció un 18% entre mayo de 2024 y mayo de 2025 en un conjunto constante de sitios (blog.cloudflare.com).
- Los bots de entrenamiento de LLM representaron casi el 80% de todo el tráfico de “bots” en algunas grandes CDN (webscraft.org).
- La red de Cloudflare recibió alrededor de 50.000 millones de solicitudes de rastreo al día solo de bots de IA a finales de 2025 (webscraft.org).
El auge de los rastreadores de IA: cómo la IA está cambiando el web crawling
Hablemos del elefante —o debería decir, del robot— en la habitación: los rastreadores de IA. Estos bots no solo indexan tu sitio para búsqueda: se están devorando contenido para entrenar grandes modelos de lenguaje o para ofrecer respuestas instantáneas impulsadas por IA. Y lo hacen a una escala que haría sonrojar incluso al motor de búsqueda más ambicioso.
¿Qué está impulsando el boom de los rastreadores de IA?
- Modelos de IA hambrientos de datos: los LLM modernos necesitan conjuntos de datos enormes y diversos. La web es su bufé, y tu contenido está en el menú.
- Entrenamiento frente a respuestas en tiempo real: alrededor del 80% del rastreo de bots de IA es con fines de entrenamiento, no solo para responder consultas en vivo.
- Nuevos patrones de rastreo: los bots de IA pueden golpear los sitios en ráfagas masivas, a veces rastreando millones de páginas en días, especialmente cuando reentrenan o actualizan modelos.
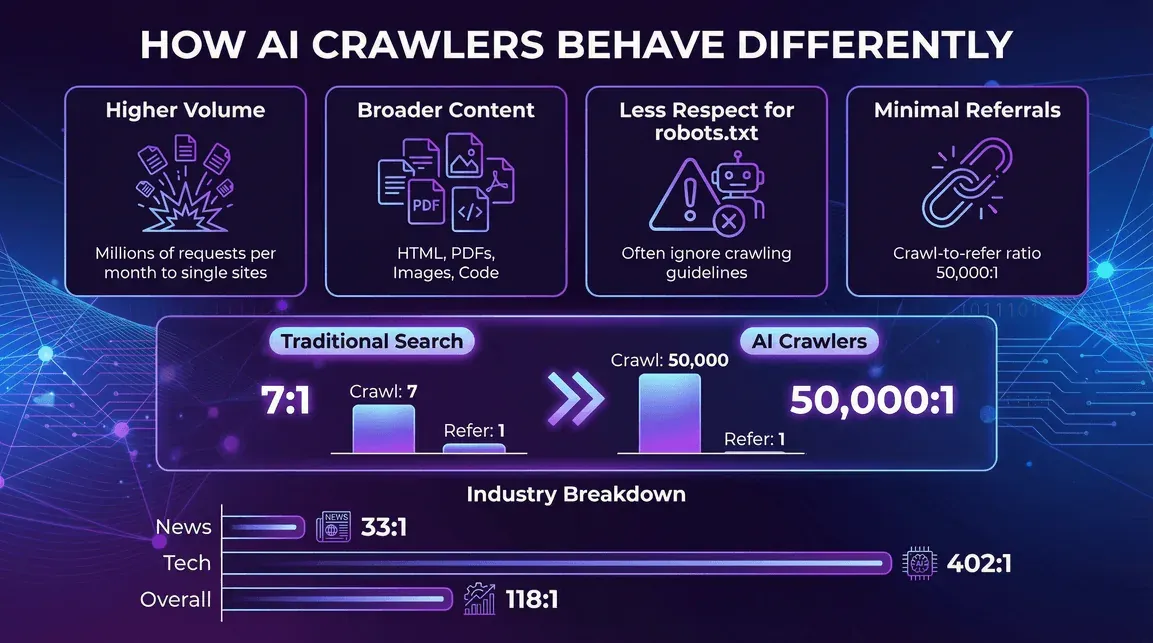
En qué se diferencian los rastreadores de IA
- Mayor volumen por rastreador: un solo bot de IA puede generar millones de solicitudes al mes a un mismo sitio (ejemplo en Reddit).
- Tipos de contenido más amplios: no solo HTML: PDFs, imágenes, código, lo que sea.
- Menor respeto por robots.txt: algunos rastreadores de IA ignoran o solo cumplen parcialmente las pautas de rastreo (blog.cloudflare.com).
- Muy poco tráfico de referencia. Esta es la parte que más debería preocupar a los editores. El análisis de Cloudflare de julio de 2025 sobre crawl-to-click situó la proporción en alrededor de 38.000 páginas rastreadas por cada visita referida para Anthropic, 1.091:1 para OpenAI y 194:1 para Perplexity. En comparación, el rastreador de búsqueda tradicional de Google todavía devuelve una referencia cada pocas páginas rastreadas. Los rastreadores de IA toman mucho y devuelven muy poco, y la brecha se amplía a medida que más respuestas se muestran dentro de la interfaz del chatbot en lugar de llevar al usuario a hacer clic.
Tráfico de rastreadores de IA por sector
No todos los sectores reciben el mismo nivel de rastreo. Por ejemplo:
- Noticias y publicaciones: mucha actividad de rastreadores de IA, pero ratios de referencia algo mejores (por ejemplo, el ratio crawl-to-refer de Perplexity es de 33:1 en sitios de noticias, frente a 118:1 en general) (blog.cloudflare.com).
- Tecnología y electrónica: GPTBot y Amazonbot dominan, con ratios crawl-to-refer aún altos (por ejemplo, el ratio de OpenAI es de 402:1 en tecnología) (blog.cloudflare.com).
- Finanzas, academia y otros: cada sector tiene su propia mezcla de bots y tasas de referencia, pero la tendencia es clara: los rastreadores de IA están en todas partes, y la mayoría no devuelve mucho tráfico.
Principales rastreadores web en 2026: ¿quién rastrea más la web?
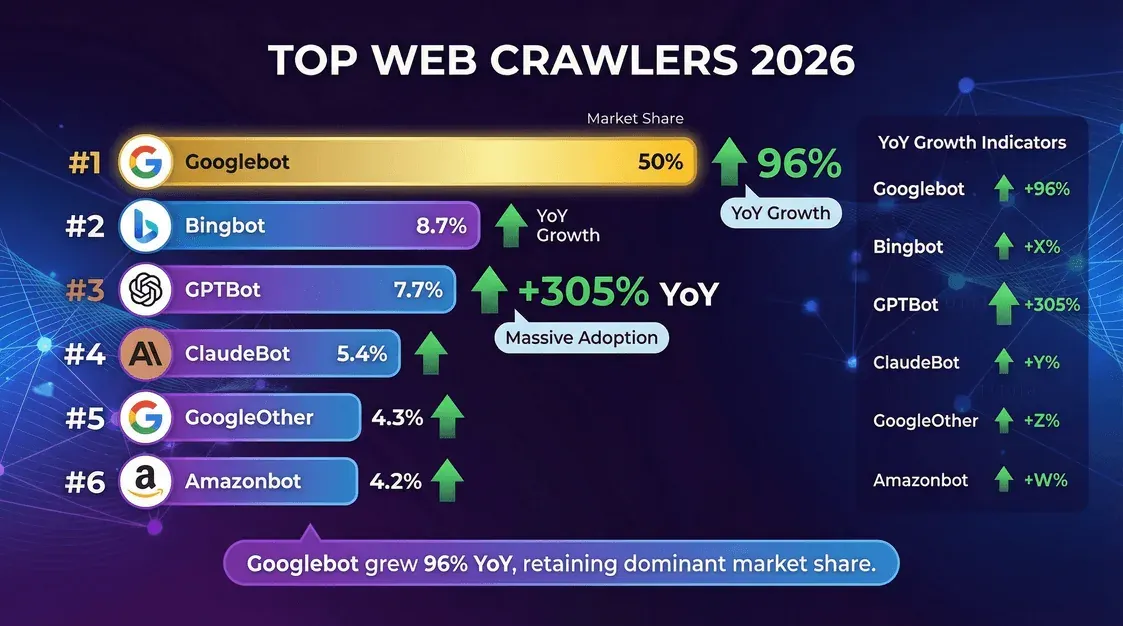
¿Quiénes son los protagonistas de este drama del crawling? Aquí tienes la clasificación, basada en los datos de Cloudflare de mediados de 2025:
| Rastreador (propietario) | Cuota de solicitudes de páginas únicas (oct.–nov. 2025) | Notas |
|---|---|---|
| Googlebot (Google) | 11,6% | Sigue siendo el rastreador más grande. Cloudflare YIR 2025: aproximadamente 200 veces el volumen de PerplexityBot. |
| GPTBot (OpenAI) | 3,6% | El mayor rastreador de entrenamiento de IA dedicado. Bajó respecto a la cuota de mayo de 2025 después de que Cloudflare cambiara el denominador y el campo de bots de IA se llenara más. |
| Bingbot (Microsoft) | 2,6% | Impulsa tanto la búsqueda de Bing como el grounding de Copilot. |
| Meta-ExternalAgent | 2,4% | Rastreador de ingesta de contenido de Meta para el entrenamiento de Llama. Entró en el top cinco en 2025. |
| ClaudeBot (Anthropic) | 2,4% | Repuntó a finales de 2025 tras una fuerte caída interanual a principios de año. |
| Applebot (Apple) | crece rápido | Se disparó hasta la categoría alta en el primer trimestre de 2026, según un análisis secundario de los datos de Cloudflare. |
| PerplexityBot | 0,06% | Cuota absoluta pequeña, pero el crecimiento relativo más rápido entre los grandes bots de IA. |
Fuente: Year in Review 2025 de Cloudflare, medido por la cuota de páginas únicas rastreadas en octubre y noviembre de 2025. Nota: este es un denominador distinto al dato de “cuota de todas las solicitudes de rastreo” de mayo de 2025 usado en informes anteriores; las clasificaciones son comparables, pero los porcentajes no lo son de forma directa.
Algunas conclusiones clave:
- Googlebot sigue siendo el rey, responsable de la mitad de toda la actividad de crawling.
- GPTBot y el rastreador de Meta son los que más rápido suben, y la cuota de GPTBot se triplicó en un año.
- PerplexityBot y los agentes ChatGPT-User tienen una cuota total pequeña, pero crecen a velocidad vertiginosa.
Referencias de web crawling: tasas de rastreo, rendimiento y throughput
 El web crawling no va solo de volumen: va de velocidad y eficiencia. Esto es lo que necesitas saber sobre las tasas de rastreo y las referencias de rendimiento en 2026.
El web crawling no va solo de volumen: va de velocidad y eficiencia. Esto es lo que necesitas saber sobre las tasas de rastreo y las referencias de rendimiento en 2026.
Tasa de rastreo: ¿a qué velocidad recuperan páginas los rastreadores?
- La tasa de rastreo suele medirse en páginas por segundo (o solicitudes por segundo) (IBM).
- Hilos/conexiones paralelas: más hilos = mayor tasa de rastreo potencial. Por ejemplo, 200 hilos con un retraso de 2 segundos por sitio pueden dar unas 100 páginas por segundo (IBM).
- Referencias del mundo real: 100–200 páginas por segundo es típico de un rastreador bien optimizado en un clúster de servidores decente.
- Google y Bing: probablemente recuperan miles de páginas por segundo a nivel global, repartidas entre millones de sitios.
Factores que influyen en la tasa de rastreo
- Número de hilos/recuperadores paralelos: más hilos, más velocidad (hasta que aparezcan otros cuellos de botella).
- Número de sitios activos: rastrear varios dominios en paralelo multiplica el throughput.
- Retraso de rastreo/tiempo de espera: más demora = menor tasa de rastreo.
- Límites de recursos: ancho de banda, CPU y velocidad de escritura en la base de datos pueden convertirse en cuellos de botella.
- Rendimiento del sitio objetivo: los sitios lentos o con limitación de tasa reducen la velocidad de rastreo.
Por ejemplo, si tu rastreador tiene 100 hilos y un retraso de 1 segundo por sitio, podrías recuperar unas 100 páginas por segundo, salvo que tu base de datos no pueda seguir el ritmo; en ese caso, el cuello de botella será el almacenamiento, no la red.
El impacto empresarial del web crawling: costes, oportunidades y riesgos
El web crawling no es solo una curiosidad técnica: es un asunto empresarial, con costes y oportunidades reales.
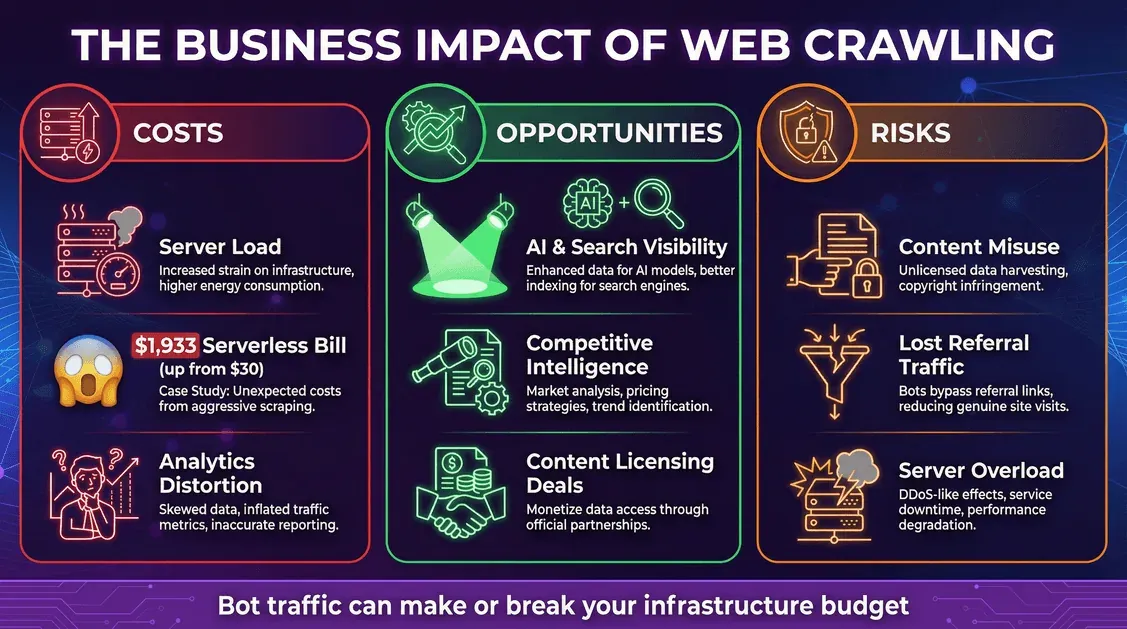
Costes: infraestructura y facturas inesperadas
- Carga del servidor: cada solicitud de un bot consume CPU, memoria y ancho de banda.
- Facturas en la nube: si trabajas con un modelo de pago por uso (como serverless), los bots pueden generar cargos serios. Un desarrollador vio cómo el rastreador de Meta generó 11 millones de solicitudes en un mes, lo que llevó a una factura serverless de 1.933 dólares (frente a 30 dólares).
- Distorsión de analíticas: los bots pueden sesgar tus métricas web y dificultar la interpretación del comportamiento real de los usuarios.
Oportunidades: visibilidad y aprovechamiento de datos
- Visibilidad en IA y búsqueda: que tu contenido entre en datos de entrenamiento de IA o índices de búsqueda puede ampliar el alcance de tu marca (blog.cloudflare.com).
- Inteligencia competitiva: las empresas usan rastreadores para estudios de mercado, seguimiento de precios y mucho más.
- Monetización: algunos medios ya están licenciando su contenido a empresas de IA.
Riesgos: uso indebido del contenido y pérdida de tráfico
- Uso indebido del contenido: los rastreadores de IA pueden incorporar tu contenido a sus modelos, a veces sin permiso claro ni compensación.
- Pérdida de tráfico de referencia: las respuestas de IA pueden satisfacer a los usuarios sin enviarlos a tu sitio, lo que lleva a una “desintermediación”.
- Seguridad y tiempo de inactividad: los rastreadores agresivos pueden saturar tus servidores y provocar ralentizaciones o caídas.
Cómo gestionar el tráfico de rastreadores web: mejores prácticas
Entonces, ¿cómo evitar que los bots te coman la tostada —o tu presupuesto en la nube—?
1. Optimiza tu robots.txt
- Usa
robots.txtpara permitir o bloquear bots concretos. La mayoría de los rastreadores reputados (como Googlebot) lo respetan, pero muchos bots de IA pueden no hacerlo (blog.cloudflare.com). - A mediados de 2025, alrededor del 14% de los principales sitios había empezado a añadir reglas explícitas para bots de IA (blog.cloudflare.com).
2. Usa herramientas de gestión de bots
- Los firewalls de aplicaciones web (WAF) y los servicios de gestión de bots pueden bloquear o limitar la tasa de tráfico sospechoso.
- Cloudflare y otros proveedores ofrecen funciones de mitigación de bots e incluso herramientas de “AI Audit” para creadores de contenido (blog.cloudflare.com).
3. Implementa limitación de tasa y caché
- Limita las solicitudes rápidas procedentes de un mismo bot.
- Sirve contenido cacheado a los bots siempre que sea posible; no dejes que disparen funciones serverless costosas ni consultas a la base de datos (ejemplo en Reddit).
4. Supervisa y analiza el tráfico de bots
- Vigila los registros de tu servidor. Sabe qué bots te visitan, con qué frecuencia y cuándo.
- Configura alertas para picos inusuales de tráfico.
5. Mantente al día con los estándares emergentes
- Estate atento a nuevas meta etiquetas o cabeceras HTTP para permisos de uso de IA (por ejemplo,
<meta name="ai:allow" content="no">). - Sigue de cerca iniciativas del sector como ContentSignals.org y protocolos de pago como x402.
Tendencias de web crawling a vigilar en 2026 y más allá
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
El panorama del web crawling evoluciona a gran velocidad. Esto es lo que yo estoy siguiendo de cerca —y lo que tú también deberías seguir—:
- El crawling impulsado por IA no deja de crecer: espera aún más bots de IA, rastreando más tipos de contenido (texto, imágenes, vídeo).
- Licencias de contenido y estándares de pago. La idea del “Salvaje Oeste” empieza a sonar anticuada. Anthropic anunció a finales de 2025 un acuerdo de 1.500 millones de dólares con autores por reclamaciones sobre datos de entrenamiento, el mayor acuerdo entre una editorial y una empresa de IA hasta la fecha. Meta firmó acuerdos plurianuales de licencias de contenido con CNN, Fox News, People Inc. y USA Today, y los acuerdos AP–Google y Axios–OpenAI de principios de 2025 ya se consideran el modelo a seguir más que la excepción. Aún se están presentando nuevas demandas —cinco editoriales demandaron a Meta en Manhattan el 5 de mayo de 2026—, así que el panorama legal dista mucho de estar cerrado, pero la dirección es clara: el contenido se valora, se paga y se litiga por él, no solo se scrapea. En el plano de los protocolos, x402 y ContentSignals.org empiezan a parecer candidatos serios para las capas de pago entre máquinas y permisos entre máquinas, respectivamente.
- La regulación está en camino: cabe esperar más claridad legal sobre lo que los bots pueden y no pueden hacer, sobre todo en lo relativo a datos de entrenamiento de IA (reuters.com).
- Estándares técnicos para el uso de contenido: aparecerán nuevas meta etiquetas, extensiones de robots.txt y declaraciones de bots legibles por máquina.
- Colaboración entre editores e IA: en lugar de ser objetivos pasivos, más editores negociarán feeds de datos estructurados o APIs para empresas de IA.
Conclusión: qué significan estas estadísticas de web crawling para tu negocio
La idea principal es esta: el web crawling es una fuerza dominante en 2026, y no muestra señales de desaceleración. Los bots automatizados —especialmente los rastreadores de IA— son ahora responsables de una enorme parte de tu tráfico, y su impacto en tu infraestructura, tu presupuesto y tu estrategia de contenidos no deja de crecer.
¿Qué deberías hacer?
- Espera tráfico intenso de bots: planifica tu infraestructura, presupuesto y monitorización en consecuencia.
- Conoce tus rastreadores: no todos los bots son iguales; adapta tu enfoque a cada uno.
- Supervisa tus métricas: sigue el tráfico de bots igual que sigues a los visitantes humanos.
- Protege tu contenido y tu bolsillo: usa controles técnicos, acuerdos legales y estándares emergentes.
- Aprovecha el lado positivo: aparecer en índices de IA y búsqueda puede impulsar tu marca; solo asegúrate de recibir valor a cambio.
- Mantente informado y adáptate: el panorama del crawling está cambiando rápido. Vigila nuevos estándares, regulaciones y modelos de negocio.
Como alguien que ha pasado años creando herramientas de automatización e IA (y ahora en Thunderbit), te puedo decir esto: las empresas que prosperan en esta nueva era son las que tratan el web crawling como una prioridad estratégica, no como una simple molestia técnica. Tanto si trabajas en ventas, ecommerce, marketing o inmobiliaria, entender las estadísticas de web crawling y las referencias del sector ya es algo imprescindible.
Así que, la próxima vez que revises los registros de tu servidor y veas un desfile de bots, no te limites a suspirar y seguir adelante. Usa los datos. Compara tu sitio con referencias. Ajusta tu estrategia. Y recuerda: en la era de la IA, los bots no están por llegar, ya están aquí. Haz que trabajen para ti, no al revés.
Mantente alerta, sigue siendo curioso y que tus registros de servidor siempre jueguen a tu favor.
Prueba Thunderbit AI Web Scraper gratis
¿Quieres saber más sobre web scraping, automatización y productividad impulsada por IA? Echa un vistazo al blog de Thunderbit para profundizar, aprender paso a paso y descubrir las últimas tendencias. Y si ya estás listo para tomar el control de tus propios datos, prueba la extensión de Chrome de Thunderbit para web scraping con IA: sin código, sin complicaciones, solo resultados.
Prueba AI Web Scraper Get Started Free
Citas y lecturas adicionales:
- From Googlebot to GPTBot: Who’s Crawling Your Site in 2025 (Cloudflare)
- Cloudflare Report Reveals Global Internet Traffic Grew 19% in 2025—but a Lot of It Was Just Bots (TechRadar)
- How Crawling Works in the AI Era 2025 (Webscraft)
- Meta’s Crawler Made 11 Million Requests to My Site in 30 Days (Reddit)
- Monitoring - Web Crawler Crawl Rate (IBM)
- A Timeline of the Major Deals Between Publishers and AI Tech Companies in 2025 (Digiday)
- Launching the x402 Foundation with Coinbase (Cloudflare)




