Los datos son un recurso valioso y durarán más que cualquier sistema.
- , científico informático e inventor de la World Wide Web
Cada día, Google procesa de búsquedas: no solo son respuestas a preguntas del día a día, sino una auténtica mina de información sobre tendencias, movimientos de la competencia y datos clave de los consumidores. Si trabajas en ventas, eres especialista en o te dedicas al marketing, puedes convertir estos datos en estrategias de negocio que realmente funcionen.
¿Todavía sigues copiando y pegando esta información a mano? Es momento de dejar atrás ese método.
En este post te contamos qué es el SERP de Google, qué tipo de datos puedes encontrar y te enseñamos tres formas de extraer resultados de búsqueda de Google usando un raspador SERP, incluyendo la opción más fácil: el Raspador Web IA y sin código de .
¿Qué es la página de resultados de Google (SERP)?
El (página de resultados del motor de búsqueda) es lo que aparece cuando escribes tus palabras clave en buscadores como , o . Es la puerta de entrada al tráfico web, el primer paso antes de hacer clic en cualquier enlace.
Una de las claves del SERP es que se basa en datos en tiempo real: los cambios en los algoritmos, nuevas funciones, tendencias de búsqueda y actualizaciones en las webs pueden modificar los resultados. Además, los buscadores personalizan los resultados según tu historial y ubicación, así que dos personas pueden ver resultados diferentes al mismo tiempo. Esto complica la extracción eficiente de datos si no tienes conocimientos técnicos.
Como Google acapara más del de la cuota mundial de buscadores, entender cómo funciona el SERP de Google y cómo aprovecharlo es fundamental para cualquier negocio.
¿Qué datos contiene el SERP de Google?
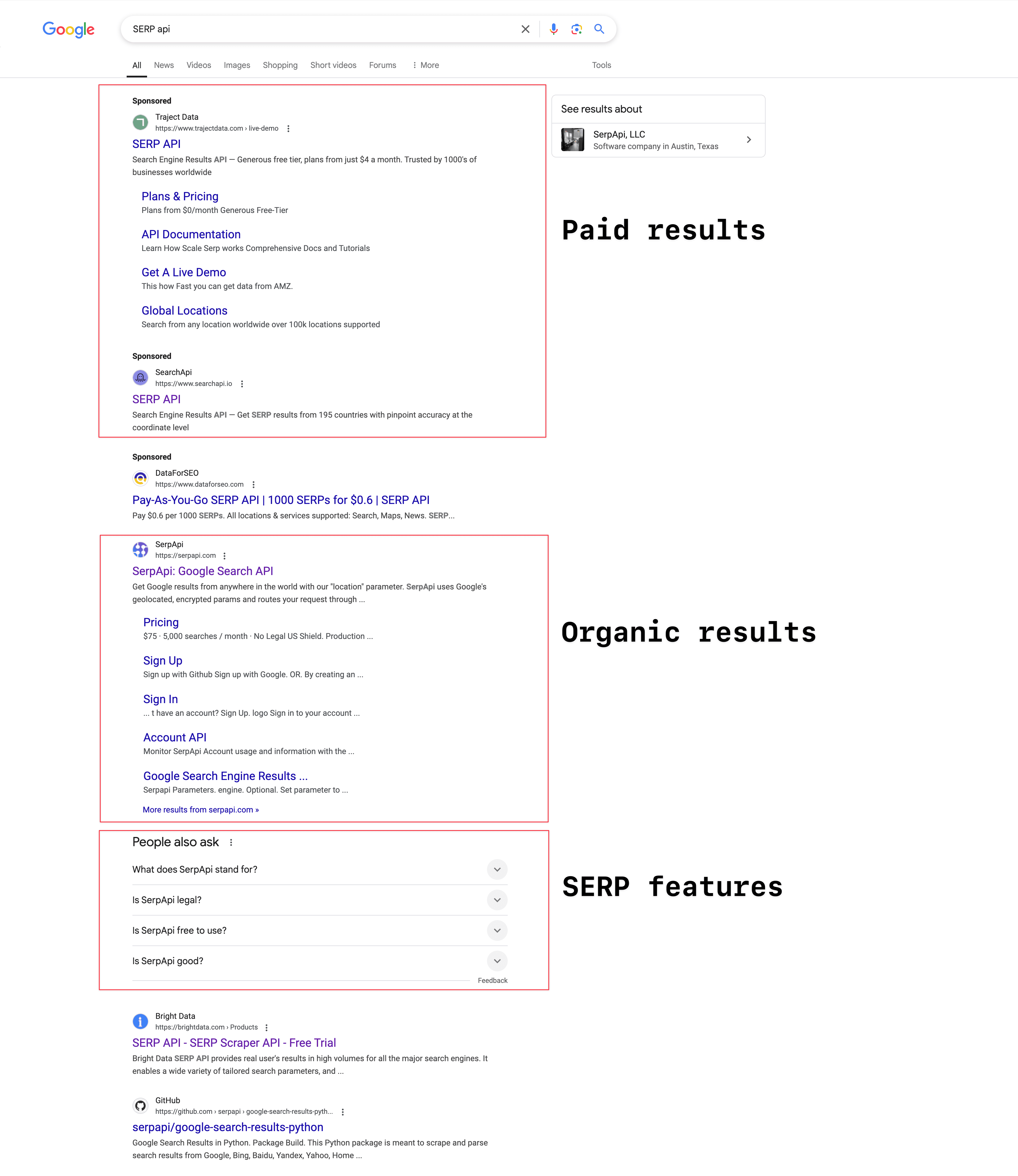
Estructura del SERP de Google
La estructura del SERP de Google cambia según la búsqueda, pero normalmente se compone de tres partes principales:
-
Resultados de pago: Son los que aparecen como "Anuncio" o "Patrocinado". Las empresas pagan a Google para salir por encima o debajo de los resultados orgánicos. No siempre aparecen, depende de la búsqueda. En 2023, los ingresos publicitarios de Google llegaron a los 264.590 millones de dólares, según .
-
Resultados orgánicos: Son los resultados que no son de pago, y se muestran según la relevancia y el posicionamiento de la página. Incluyen título, descripción y URL.
-
Funciones SERP: Son elementos que Google añade para mejorar la experiencia del usuario y que están en constante evolución. Aquí entran los fragmentos destacados, resúmenes generados por IA, el cuadro de "Otras preguntas de los usuarios" (PAA), paneles de conocimiento, packs locales (para búsquedas con ubicación), vídeos, imágenes y resultados de compras.
Tipos de datos
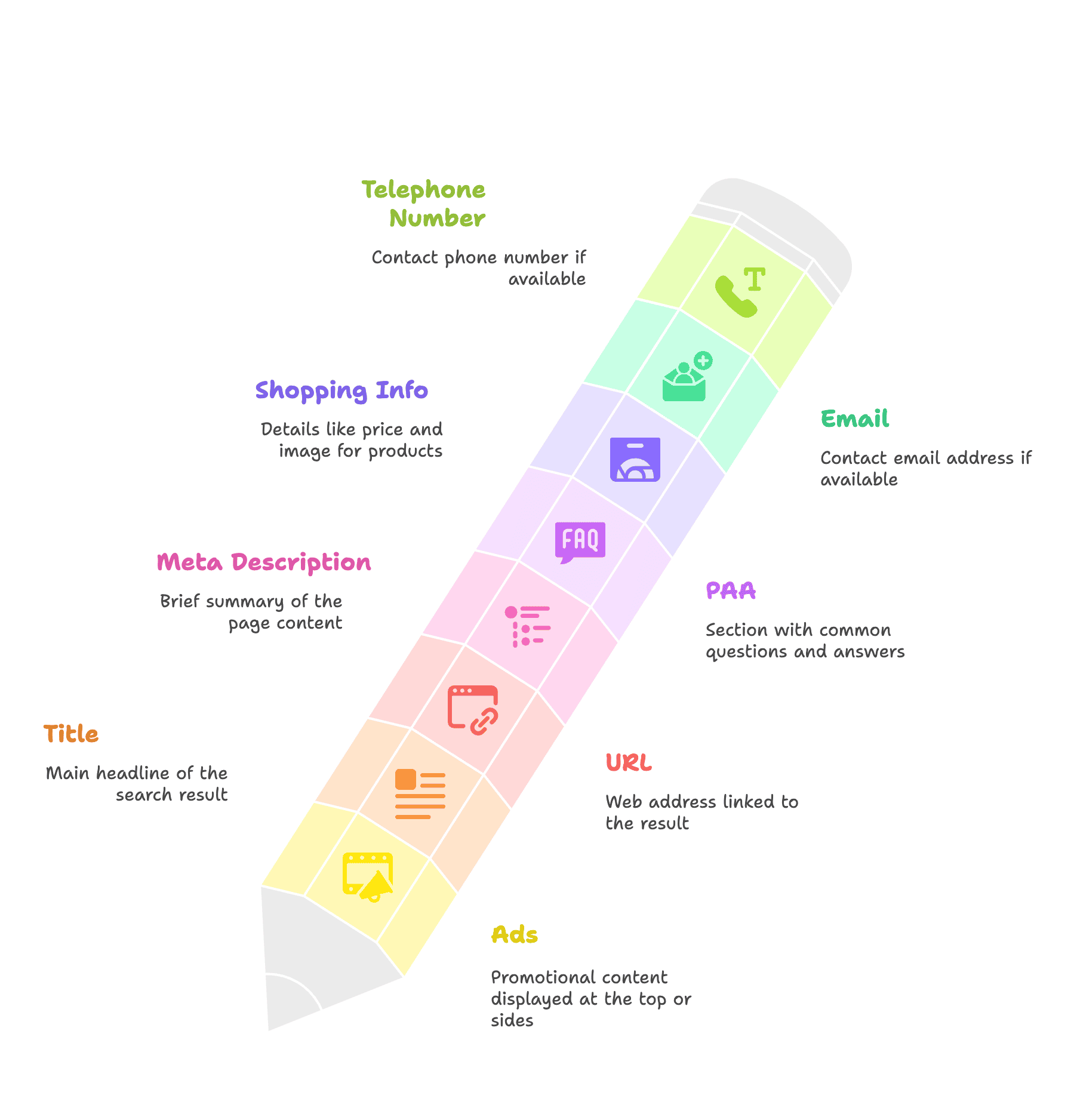
Conocer la estructura del SERP te ayuda a identificar qué información puedes extraer, como:
- Anuncios
- Título
- URL
- Meta descripción
- Cuadro PAA
- Información de compras: precio, imagen
- Correo electrónico
- Número de teléfono
¿Para qué sirve la información del SERP?
Ventas
Con búsquedas bien afinadas, los equipos de ventas pueden generar leads y descubrir oportunidades que otros pasan por alto. Google permite extraer datos de potenciales clientes en redes sociales, como correos y teléfonos, facilitando el contacto directo. Más adelante te enseñamos cómo usar el SERP para captar leads de Instagram.
Investigación de mercado
El SERP es una herramienta clave para los marketers. Por ejemplo, al analizar a la competencia, puedes extraer anuncios y productos de tus rivales para entender sus estrategias y mejorar las tuyas.
El SERP también te ayuda a anticipar tendencias de mercado. Analizar las palabras clave que aparecen puede revelar nuevas oportunidades. Si tienes una tienda de ropa y ves que crecen las búsquedas de "moda sostenible", quizá sea el momento de sumar productos alineados con esa tendencia.
Análisis SEO
El SERP es la base para los especialistas en SEO. Analizando estos datos, pueden ajustar sus estrategias de palabras clave y optimizar el contenido para mejorar el posicionamiento.
Por ejemplo, si extraes las preguntas del cuadro PAA y analizas cómo evolucionan, puedes descubrir nuevas inquietudes de los usuarios y adaptar tu contenido para responderlas.
Análisis de contenido
Para periodistas, extraer resultados de Google Noticias permite analizar tendencias y temas de interés público, orientando la producción de contenidos. En nuestra guía te contamos más sobre cómo extraer artículos con un raspador web.
¿Cómo extraer datos de la página de resultados de Google?
Ahora que ya sabes para qué sirve la información del SERP, la siguiente pregunta es: ¿cómo recolectarla?
Copiar y pegar a mano es posible, pero nada práctico si necesitas muchos datos. Gracias a la tecnología, sobre todo la IA, hoy podemos usar raspadores web para automatizar el proceso. Aquí tienes tres formas de hacerlo:
Usando Thunderbit AI Web Scraper
es un raspador web IA sin código que te permite extraer cualquier dato de una web. Puedes usar nuestras o personalizar las columnas a tu gusto. Veamos un ejemplo para ventas, Generación de leads, y cómo encontrar contactos cualificados paso a paso con Thunderbit.
-
Paso 1: Añade Thunderbit como extensión de Chrome e inicia sesión con tu cuenta de Google o correo electrónico.
-
Paso 2: Escribe tu consulta de búsqueda.
Para afinar los resultados, puedes usar .
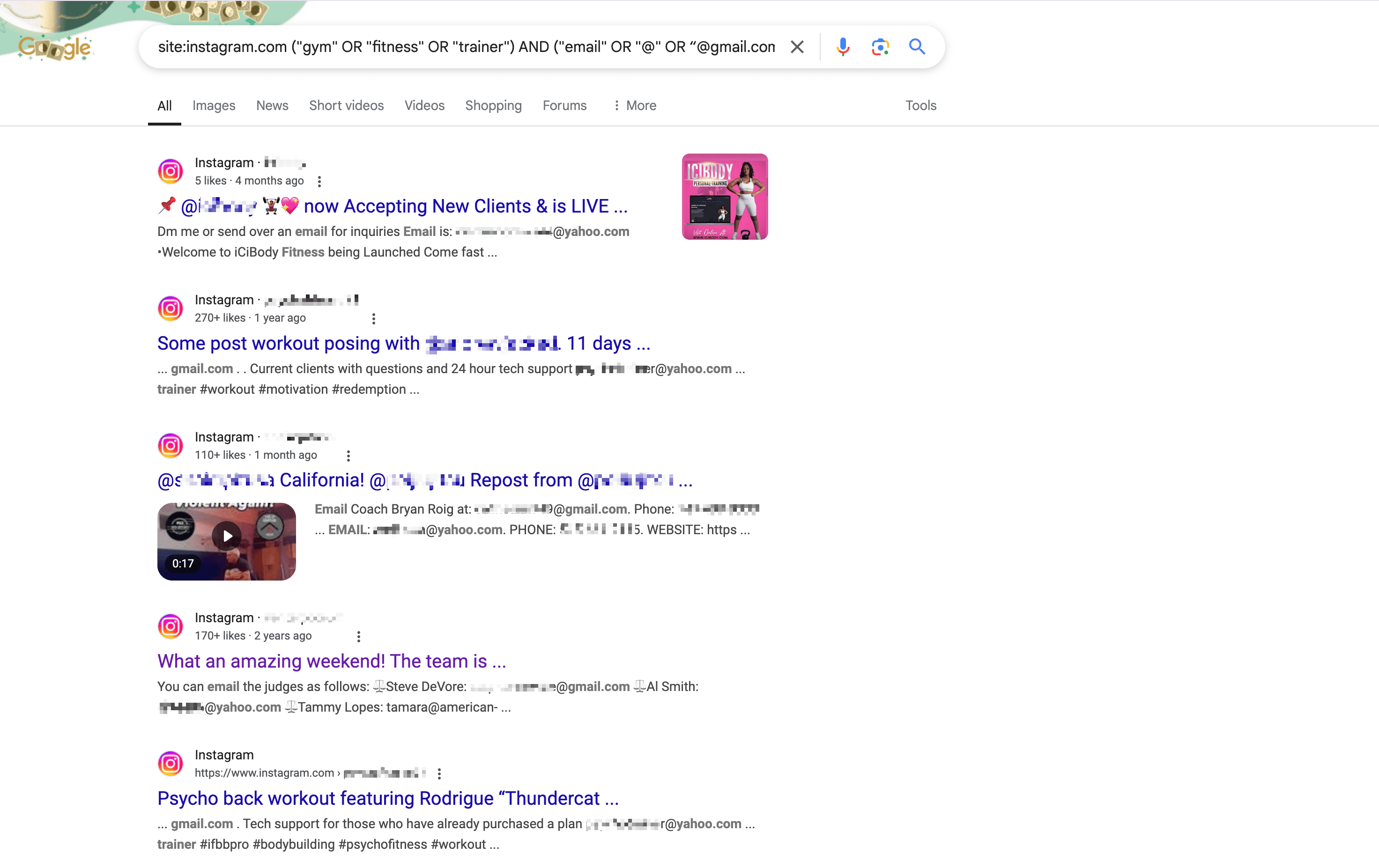
Por ejemplo, aquí tienes una consulta generada por para encontrar correos de personas relacionadas con gimnasios en Los Ángeles en Instagram:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")Escribe la consulta en Google y pulsa Enter: verás toda la información que necesitas en los resultados.
-
Paso 3: Lanza Thunderbit y extrae los datos
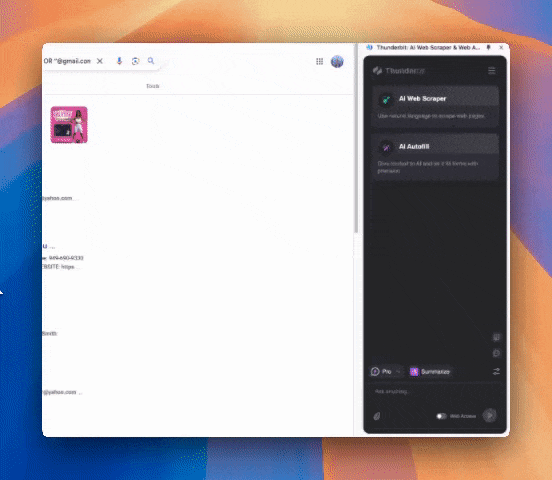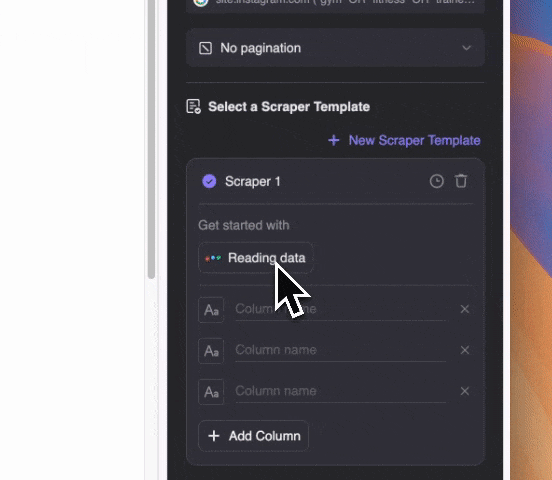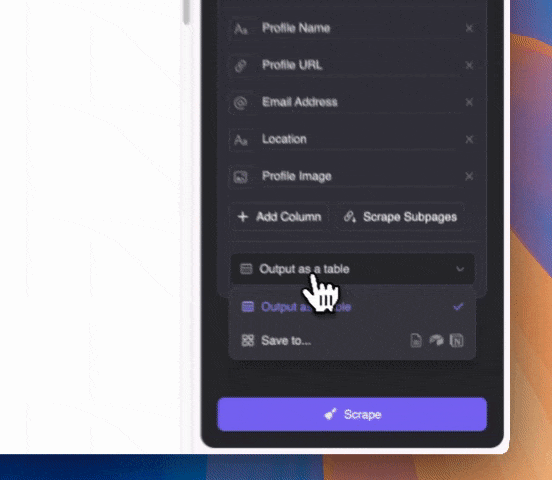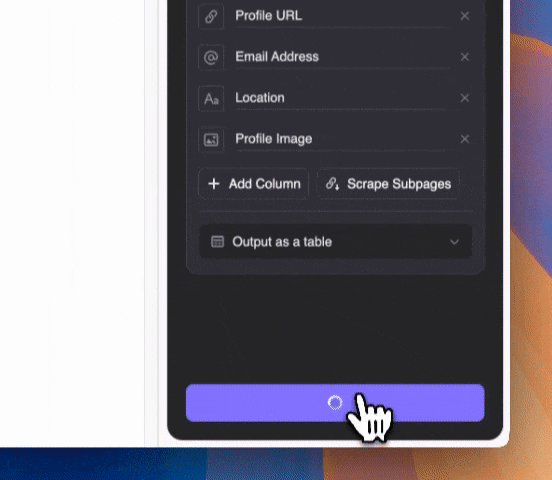 Describe en lenguaje natural el tipo de contenido que quieres extraer (puedes hacer clic en "Agregar instrucción detallada de columna" para especificar más). Elige exportar como tabla o directamente a Notion, Airtable o Google Sheets.
Describe en lenguaje natural el tipo de contenido que quieres extraer (puedes hacer clic en "Agregar instrucción detallada de columna" para especificar más). Elige exportar como tabla o directamente a Notion, Airtable o Google Sheets.Recuerda que Thunderbit usa IA para ayudarte a extraer datos. Así, aunque los correos estén mezclados con otros textos en los fragmentos del SERP, la IA los detectará y extraerá correctamente.
Haz clic en Extraer y espera los resultados.
Usando un raspador web tradicional
Los raspadores web tradicionales también permiten extraer datos del SERP de Google en masa. Así puedes hacerlo con WebScraper.io:
- Instala la extensión Web Scraper y abre las herramientas de desarrollador de Chrome.
- Haz clic en “Crear nuevo sitemap” y pon como URL de inicio la página de resultados de Google.
- Configura los selectores para elegir los datos que te interesan.
| Nombre del selector | Tipo | Selector | ¿Múltiple? |
|---|---|---|---|
| nombre | Texto | selecciona el nombre del usuario | No ❌ |
| perfil | Texto | selecciona la meta descripción de esta página | No ❌ |
-
Ejecuta el raspador y exporta los datos.
-
Tras extraer las bios, tendrás que sacar los correos de Excel usando una fórmula regex:
1texto=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(suponiendo que A2 contiene el texto del perfil)
Así podrás extraer cualquier dirección de correo que necesites.
El problema de este método es que necesitas entender la estructura web y, si la página cambia (algo que pasa mucho), tendrás que reconfigurar los selectores.
Usando la API oficial de Google o APIs SERP de terceros
Google tiene una API oficial llamada , que permite acceder a los resultados de búsqueda de forma programática. Debes crear y configurar tu , conseguir una clave API y usar la librería requests de Python para hacer peticiones. Sin embargo, solo puedes acceder a lo que Google permite y el volumen está muy limitado. Si buscas personalización, este método puede quedarse corto.
Otra opción es usar APIs de raspado SERP de terceros (como Zen SERP, SerpApi, ScrapingBee). También requieren configuración y programación. Tras la instalación, tendrás que escribir código para obtener los perfiles de Instagram y luego extraer los correos de la bio. Esto puede ser complicado si no tienes experiencia técnica.
1import requests
2from bs4 import BeautifulSoup
3import re
4# Credenciales de SerpApi
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Paso 1: Obtener URLs de perfiles de Instagram desde SerpApi
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Paso 2: Extraer correo de la bio del perfil de Instagram
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Ejemplo de uso
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Perfiles de Instagram encontrados:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"Correos encontrados en \{profile\}: \{emails\}")
44 else:
45 print(f"No se encontró correo en \{profile\}")Comparativa de los 3 métodos
¿Buscas la forma más rápida y sencilla sin conocimientos técnicos? → Elige
¿Quieres controlar cada campo y tienes nociones de HTML/CSS? → Opta por un raspador web tradicional
¿Necesitas acceder a millones de datos a bajo coste y cuentas con un experto técnico? → Usa una API SERP de terceros
¿Es legal usar un raspador de Google?
La legalidad del scraping web es una duda muy común. La respuesta corta: depende. La legalidad varía según el país, el propósito, los términos de uso y el tipo de contenido. No hay una única respuesta.
Los prohíben el scraping automático de sus servicios. Sin embargo, en general, . El fin del scraping (comercial o sin ánimo de lucro) también influye mucho en la legalidad.
Para asegurarte de que tu actividad es ética y legal, te recomendamos leer bien los términos de uso, extraer solo datos públicos y no utilizar la información para fines ilícitos. Si vas a hacer scraping a gran escala, consulta con un profesional legal.
Conclusión
Los datos son “, y el SERP de Google es una mina por explotar. Quienes sepan transformar estos datos en acciones concretas tendrán ventaja en un mercado cada vez más competitivo. La generación de leads, la investigación de mercado y la optimización SEO son solo algunos ejemplos de uso.
Según tu perfil técnico, presupuesto, volumen de datos y necesidades, te hemos presentado el innovador Raspador Web IA Thunderbit, los raspadores tradicionales y las APIs SERP.
Si eres profesional de negocio y quieres extraer todos los resultados con un solo clic, Thunderbit es tu mejor aliado. ¿A qué esperas? .
FAQ
1. ¿Qué tipo de datos puedo extraer de una página de resultados de Google (SERP)?
Puedes extraer títulos, URLs, descripciones, anuncios, fragmentos destacados, información de compras (precio, imágenes), preguntas de "Otras preguntas de los usuarios", correos electrónicos, teléfonos y mucho más.
2. ¿En qué se diferencia Thunderbit de los raspadores tradicionales o las APIs SERP?
es una extensión de Chrome con IA y sin código que te permite extraer datos estructurados usando lenguaje natural, sin configurar selectores ni programar. Los raspadores tradicionales requieren configuración técnica y las APIs implican programación y límites de acceso.
3. ¿Necesito conocimientos técnicos para usar Thunderbit y extraer resultados de Google?
No. Thunderbit está pensado para usuarios sin experiencia técnica. Solo tienes que describir los datos que buscas y la IA se encarga del resto.
4. ¿Puedo exportar los datos extraídos a Google Sheets o Notion?
Sí. Thunderbit permite exportar directamente a Google Sheets, Airtable, Notion o descargar los datos en tabla, para que los uses al instante.
5. ¿Cuáles son los usos prácticos de extraer datos del SERP de Google?
Algunos ejemplos: generación de leads, análisis de la competencia, SEO, detección de tendencias y planificación de contenidos. Por ejemplo, los equipos de ventas pueden encontrar contactos, los marketers analizar anuncios y los SEOs monitorizar palabras clave y preguntas relacionadas.