Déjame contarte un secreto: internet es como la biblioteca más grande que existe, pero la mayoría de los libros están pegados y no se pueden abrir fácilmente. Todos los días hablo con emprendedores, marketers y equipos de ventas que saben que hay información valiosísima escondida en esas páginas web—especificaciones de productos, precios de la competencia, opiniones de clientes, datos de contacto—pero sacar ese texto no es tan fácil como parece. Llevo años metido en el mundo SaaS y la automatización, y he visto de todo: desde jornadas eternas de copiar y pegar hasta experimentos caseros con Python. ¿La buena noticia? Hoy en día, extraer texto de una página web es mucho más sencillo (y menos doloroso) gracias a los nuevos raspadores web IA y extensiones inteligentes para el navegador.
En esta guía te voy a mostrar todos los métodos prácticos que conozco, desde el clásico copiar y pegar hasta soluciones avanzadas con IA como (sí, es nuestro producto, pero te contaré lo bueno y lo malo). Seas un crack de las hojas de cálculo, un programador o simplemente alguien cansado de dejarse la vista frente a la pantalla, aquí vas a encontrar el paso a paso que mejor se adapte a ti. Vamos a abrir esos libros digitales y conseguir el texto que necesitas.
¿Qué significa extraer texto de una página web?
Cuando hablamos de “extraer texto de una web”, nos referimos a sacar la información que ves (y a veces la que no ves) en una página y convertirla en un formato útil—como una hoja de cálculo, una base de datos o incluso un documento limpio de Word. Pero no todo el texto de una web es igual:
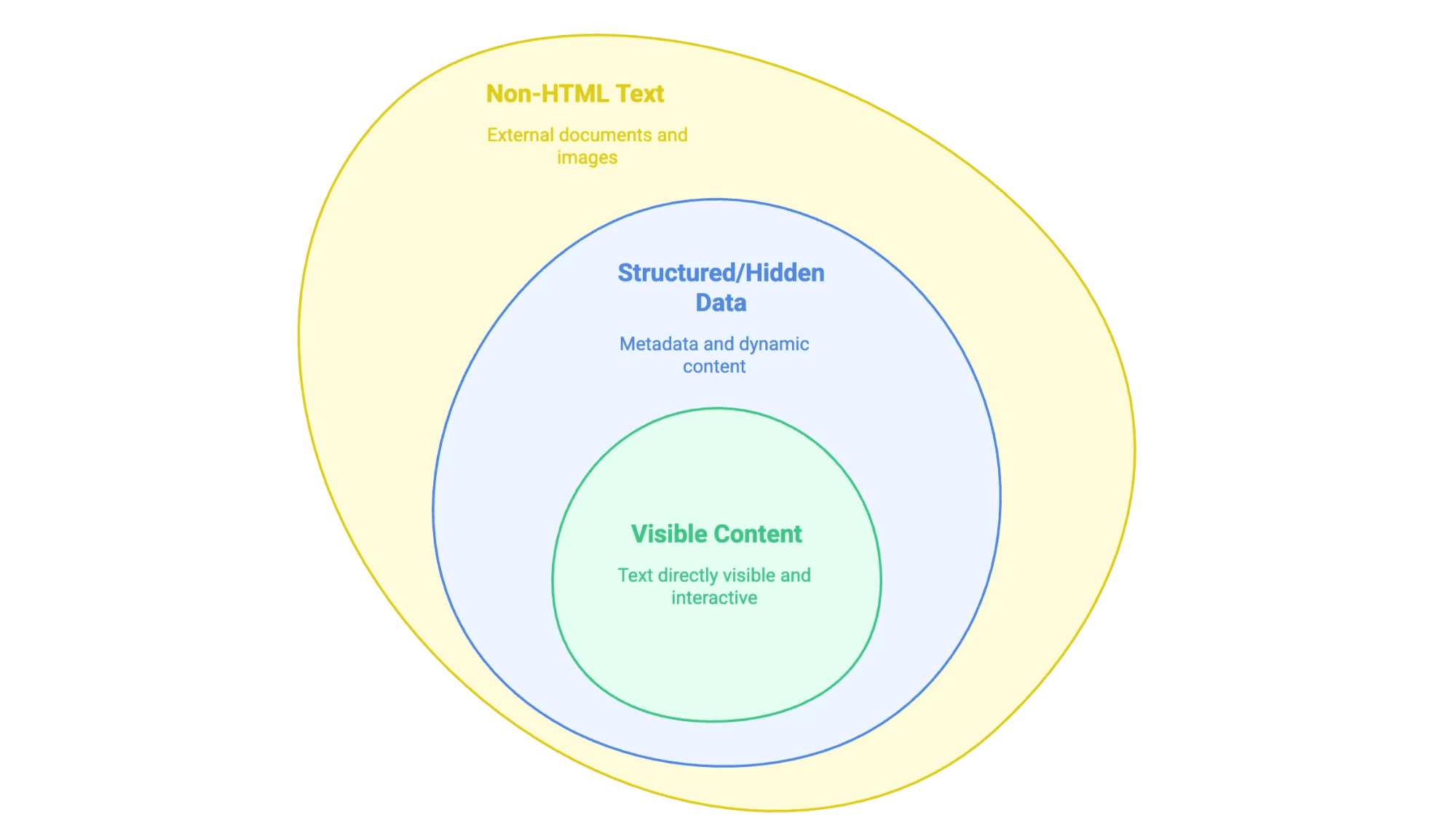
- Contenido visible: Es lo que puedes seleccionar con el ratón—textos, títulos, listas, tablas, descripciones de productos, artículos de blog, etc.
- Datos estructurados u ocultos: Como los metadatos en etiquetas
<meta>, scripts JSON-LD o información que carga JavaScript y solo aparece al hacer clic o desplazarte. - Texto no HTML: Archivos PDF, documentos Word e incluso imágenes con texto (como contratos escaneados o infografías) que están enlazados o incrustados en la web.
El truco está en saber qué tipo de texto buscas, porque cada uno requiere una técnica diferente para extraerlo.
¿Por qué extraer texto de una web? Beneficios y casos de uso
Seamos sinceros: nadie se pone a extraer texto de páginas web por diversión (a menos que tengas un hobby muy peculiar). Las empresas lo hacen porque realmente aporta valor. El mercado de software de web scraping superó los , y sigue creciendo. ¿Por qué?
| Equipo | Ejemplo de uso | Beneficio |
|---|---|---|
| Ventas | Extraer directorios para leads y contactos | Prospección más rápida y completa |
| Marketing | Extraer artículos de la competencia y datos SEO | Análisis de contenido, detectar tendencias |
| Operaciones | Monitorizar precios en tiendas online | Precios dinámicos, control de stock |
| Inmobiliaria | Reunir anuncios y detalles de propiedades | Análisis de mercado, generación de leads |
| Soporte | Recopilar reseñas y preguntas en foros | Análisis de sentimiento, detección temprana de problemas |
Algunos ejemplos reales:

- Generación de leads: Una empresa de suministros para restaurantes en minutos en vez de días.
- Monitorización de la competencia: Minoristas como John Lewis usando datos de precios extraídos.
- Análisis SEO: Los equipos extraen metadatos y palabras clave para .
Y con herramientas impulsadas por IA, las empresas ahorran en la recolección de datos frente a los métodos tradicionales.
Métodos manuales: lo básico de copiar y pegar texto de una web
Empecemos por lo más sencillo. A veces solo necesitas un fragmento rápido—sin herramientas complicadas.
Cómo extraer texto manualmente
- Copiar y pegar: Abre la página, selecciona el texto y pulsa Ctrl+C (o clic derecho > Copiar). Luego pégalo en tu documento o Excel.
- Guardar como: En el navegador, ve a Archivo > Guardar como. Elige “Página web, solo HTML” para obtener el código fuente, o a veces .txt para solo el texto.
- Imprimir a PDF: Usa la opción de imprimir del navegador y selecciona “Guardar como PDF”. Después abre el PDF y copia el texto (o usa la función “Guardar como texto” del lector de PDF).
- Herramientas de desarrollador: Clic derecho > Inspeccionar o pulsa F12 para abrir las DevTools. Puedes ver el HTML, buscar metadatos o JSON oculto y copiar lo que necesites.
Limitaciones
La extracción manual sirve para tareas puntuales, pero es un suplicio para volúmenes grandes. Es . Créeme, he visto becarios pasar días copiando tablas fila por fila—nadie quiere ese trabajo.
Usar extensiones de navegador y herramientas online para extraer texto de webs
¿Listo para dar un salto de nivel? Las extensiones y herramientas online son la opción ideal para la mayoría de usuarios de negocio: sin código, sin complicaciones, solo señalar y hacer clic.
¿Por qué usar estas herramientas?

- Mucho más rápido que copiar y pegar a mano
- No necesitas saber programar
- Pueden manejar tablas, listas e incluso archivos
- Exportan a Excel, Google Sheets, CSV, etc.
Vamos a ver las opciones más populares.
Thunderbit: Raspador Web IA para extraer texto rápido y preciso
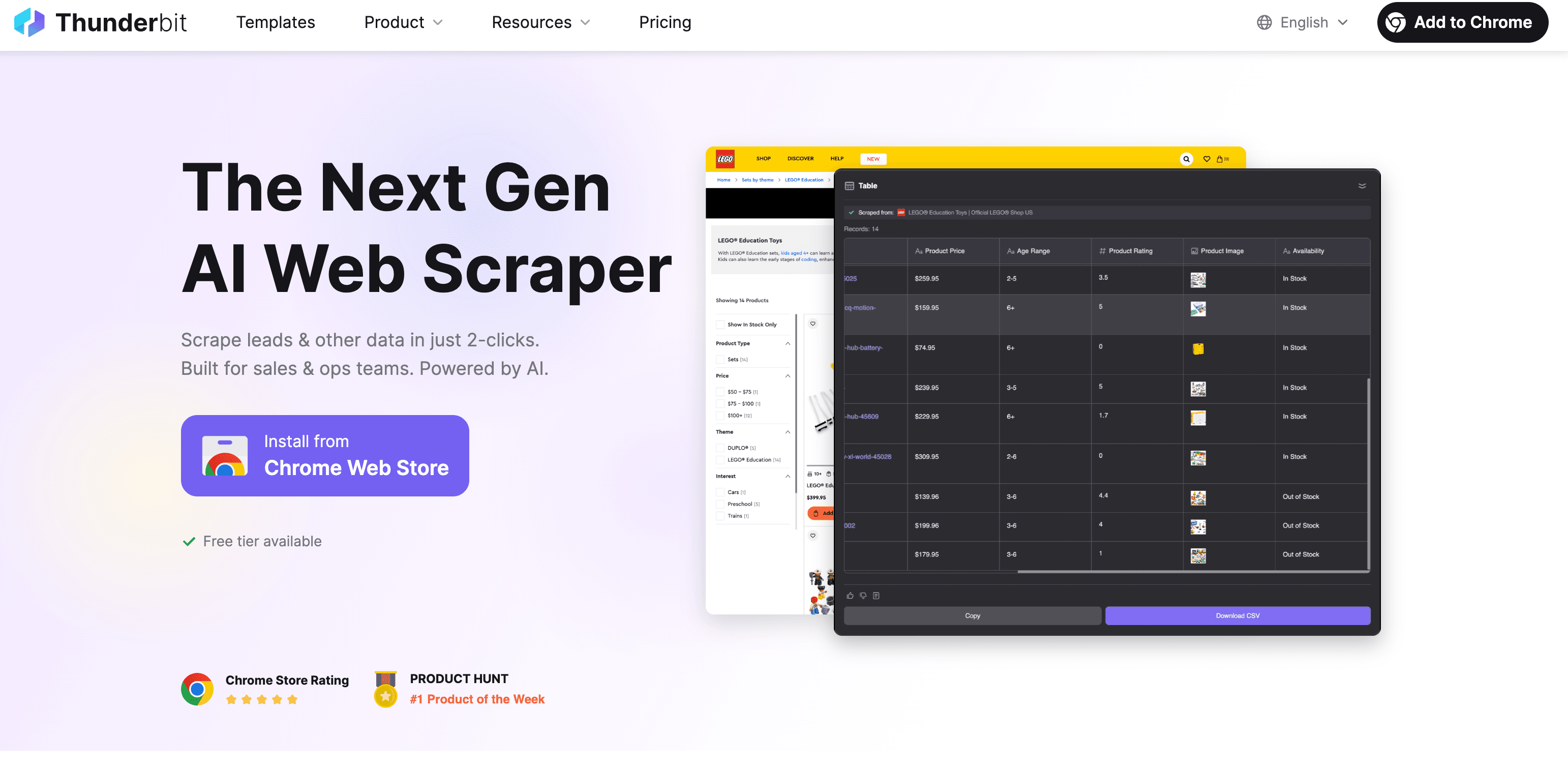
Vale, aquí soy un poco parcial, pero está pensado para que extraer texto de la web sea tan fácil como pedir comida a domicilio. Así funciona:
Paso a paso: extraer texto con Thunderbit
- Instala la extensión de Chrome: desde la Chrome Web Store.
- Abre la web: Ve a la página de la que quieres extraer el texto.
- Haz clic en “AI Sugerir Campos”: La IA de Thunderbit analiza la página y te sugiere qué campos (columnas) extraer—por ejemplo, nombre del producto, precio, descripción, etc.
- Revisa y ajusta: Puedes modificar los campos sugeridos o añadir los tuyos.
- Haz clic en “Extraer”: Thunderbit recoge los datos, incluso de subpáginas o listas paginadas si hace falta.
- Exporta: Descarga tus datos a Excel, Google Sheets, Airtable, Notion o como CSV/JSON. Sin costes extra por exportar.
¿Qué hace diferente a Thunderbit?
- Sugerencia de campos con IA: No tienes que pelearte con selectores ni código. La IA detecta lo importante de la página.
- Gestiona subpáginas y paginación: ¿Necesitas detalles de cada producto en una categoría? Thunderbit puede navegar automáticamente.
- Extrae de PDFs, imágenes y documentos: ¿Tienes un manual en PDF o una imagen con especificaciones? El OCR integrado de Thunderbit también extrae ese texto.
- Soporte multilingüe: Funciona en 34 idiomas (todavía no en klingon, pero estamos en ello).
- Exportación gratuita: No hay muro de pago para sacar tus datos.
- Casos de uso: Descripciones de productos, datos de contacto, contenido de blogs, listas de leads, lo que necesites.
¿Quieres verlo en acción? Visita nuestro para guías como .
Otras extensiones y herramientas online
Mención rápida a otras herramientas que puedes encontrar:
- Raspador Web (): Gratuito, de apuntar y hacer clic, pero tiene curva de aprendizaje. Ideal para analistas técnicos, pero hay que configurar “sitemaps” y selectores. Soporta paginación, pero no PDFs ni imágenes. .
- CopyTables: Súper sencillo—copia tablas HTML al portapapeles o Excel. Perfecto para capturas rápidas de tablas, pero solo funciona página a página y solo con tablas. .
- ScraperAPI (): Para desarrolladores. Envías una URL y te devuelve el HTML (gestiona proxies, bloqueos, etc.), pero tienes que procesar el texto tú mismo. .
¿Cuándo usar cada herramienta?
- Thunderbit: Si buscas rapidez, ayuda de IA y soporte para varios formatos (incluyendo PDFs/imágenes).
- Raspador Web: Si te gusta trastear y quieres más control.
- CopyTables: Si solo necesitas una tabla, rápido.
- ScraperAPI: Si vas a programar tu propio raspador.
Web scraping automatizado: soluciones de programación para extraer texto
Si eres desarrollador (o tienes uno a mano), programar tu propio raspador te da el máximo control. El flujo básico es:
- Enviar petición HTTP: Usa
requestsde Python o similar para obtener la página. - Parsear el HTML: Usa
BeautifulSoup,lxmloScrapypara localizar el texto que buscas. - Extraer y exportar: Saca el texto, límpialo y guárdalo en CSV, JSON o una base de datos.
Ejemplo: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Pros y contras
- Ventajas: Máxima flexibilidad, puedes manejar cualquier web o tipo de dato, integración con tus sistemas.
- Desventajas: Requiere saber programar, mantenimiento continuo y lidiar con bloqueos anti-bots.
¿Cuándo elegir esta opción?
- Si necesitas extraer miles (o millones) de páginas.
- Si la web es compleja (logins, formularios por pasos).
- Si quieres integrar el scraping directamente en tu app o flujo de trabajo.
Extraer texto de formatos no HTML: PDFs, Word y imágenes
Las webs no solo son HTML—están llenas de PDFs, documentos Word e imágenes con texto valioso. Así puedes extraerlo:
PDFs
- PDFs con texto: Usa herramientas como Adobe Acrobat, o librerías como
PDFMineroPyPDF2para extraer el texto. - PDFs escaneados: Usa OCR (Reconocimiento Óptico de Caracteres) como Tesseract, o .
Documentos Word/Excel
- Word: Usa
python-docxpara leer archivos .docx. - Excel: Usa
openpyxlopandaspara archivos .xlsx.
Imágenes
- Herramientas OCR: Tesseract como opción open source, o servicios en la nube para mayor precisión. Imágenes de buena calidad (150–300 DPI) dan mejores resultados.
El enfoque de Thunderbit
El “Image/Document Parser” te permite subir o enlazar un PDF, imagen o documento, y la IA extrae el texto (e incluso sugiere columnas si detecta una tabla). No necesitas usar varias herramientas—trata los archivos igual que cualquier página web.
Comparativa de métodos: ¿qué solución de extracción de texto te conviene?
Aquí tienes una tabla comparativa para ayudarte a decidir:
| Método | Facilidad de uso | Escalabilidad | Nivel técnico necesario | Tipos de datos soportados | Ideal para |
|---|---|---|---|---|---|
| Manual (Copiar-Pegar) | Muy fácil | Baja | Ninguno | Solo texto visible | Tareas pequeñas y puntuales |
| Extensiones/Herramientas | Fácil–Media | Media | Bajo–Medio | HTML, algunas tablas | Usuarios no técnicos, trabajos pequeños–medianos |
| Herramientas IA (Thunderbit) | Muy fácil | Alta | Ninguno | HTML, PDFs, imágenes, más | Empresas, contenido variado |
| Programación (Código) | Difícil | Muy alta | Alto | Cualquiera (con librerías adecuadas) | Desarrolladores, proyectos a gran escala |
| Extracción no HTML (OCR) | Media | Baja–Media | Media | PDFs, imágenes, docs | Cuando los archivos/imágenes son clave |
Si buscas la opción más rápida, flexible y sencilla—sobre todo para negocios—las herramientas con IA como Thunderbit son difíciles de superar. Pero si necesitas control total o vas a extraer datos a gran escala, programar tu propio sistema puede ser lo mejor.
Resumen: empieza a extraer texto de webs hoy mismo
- Internet está repleto de datos valiosos, pero no siempre es fácil acceder a ellos.
- Los métodos manuales sirven para tareas pequeñas, pero no escalan.
- Las extensiones de navegador y los raspadores web IA como hacen que extraer texto sea rápido, preciso y accesible para todos—sin necesidad de programar.
- Para contenido no HTML (PDFs, imágenes), busca herramientas con OCR y análisis de documentos integrados.
- Elige el método que mejor se adapte a las habilidades de tu equipo, el tamaño del proyecto y el tipo de datos que necesitas.
¡Feliz extracción! Ojalá tus días de Ctrl+C sean cada vez menos. Con las herramientas adecuadas, extraer datos web puede convertirse en un proceso automático y sin complicaciones, liberando tu tiempo para tareas más valiosas. Olvídate de pasar horas copiando y pegando: ahora tienes soluciones inteligentes y eficientes al alcance de tu mano. ¡Adiós al trabajo manual y bienvenido a una productividad real!
Preguntas frecuentes
¿Puedo extraer datos de cualquier web? No siempre. Algunas webs bloquean los raspadores o tienen políticas que lo prohíben. Revisa siempre las condiciones de uso del sitio.
¿Qué tan precisos son los raspadores web IA? Herramientas como Thunderbit son muy precisas, aunque en páginas muy complejas o dinámicas puede que necesites ajustar algunos detalles.
¿Necesito saber programar para usar herramientas de web scraping? No, herramientas como Thunderbit y otras extensiones están pensadas para usuarios sin conocimientos técnicos.
¿Qué tipo de datos puedo extraer de PDFs o imágenes? Las herramientas OCR pueden extraer texto, tablas e incluso datos ocultos de PDFs escaneados e imágenes, haciendo la extracción mucho más versátil.
Más información