

Necesitaba seguir más de 200 fuentes de noticias para detectar artículos de tendencia. ¿Hacerlo manualmente? Eso es un trabajo de jornada completa. ¿Un scraper tradicional? Se rompía cada vez que un sitio cambiaba su diseño.
Entonces probé los extractores de artículos con IA. Un clic, datos limpios, sin selectores CSS. La diferencia fue enorme.
Si eres periodista, especialista en SEO o investigador y necesitas extraer artículos a gran escala, esta comparación te ahorrará mucho ensayo y error. He probado tanto scrapers tradicionales sin código como opciones impulsadas por IA; esto es lo que realmente funciona.
Extrae datos de cualquier sitio web con IA Get Started Free
En resumen
| Ventajas | Desventajas | Ideal para | |
|---|---|---|---|
| Extractor de artículos con IA | - Puede extraer varios sitios web con alta precisión - Elimina automáticamente el ruido - Se adapta a cambios en la estructura web - Admite carga de contenido dinámico - Bajo coste de limpieza de datos | - Mayor coste computacional - Tiempo de procesamiento más largo - Algunas páginas pueden requerir intervención manual - Puede activar mecanismos antiextracción | - Extraer sitios con contenido complejo o dinámico (p. ej., portales de noticias, redes sociales) - Recopilación de datos a gran escala |
| Extractor de artículos tradicional sin código | - Ejecución rápida - Menor coste - Bajo uso de recursos del servidor y locales - Alta capacidad de control | - Mantenimiento frecuente por cambios en la estructura web - No puede extraer varios sitios a la vez - No maneja contenido dinámico - Alto coste de limpieza de datos | - Extracción rápida y masiva de páginas web estáticas sencillas - Recursos informáticos limitados, restricciones de presupuesto |
¿Qué es un extractor de artículos? ¿Por qué importa un extractor de artículos con IA?
Un extractor de artículos es un tipo de Raspador Web que puede localizar y extraer información como títulos, autores, fechas de publicación, contenido, palabras clave, imágenes y vídeos de sitios de noticias, organizándola en formatos estructurados como JSON, CSV o Excel.
Los extractores de artículos tradicionales sin código se basan en selectores CSS para extraer contenido según la estructura HTML de una página web. Sin embargo, este enfoque tiene sus inconvenientes:
- Falta de universalidad: distintas estructuras web necesitan selectores CSS específicos para cada sitio, y cualquier cambio en la estructura puede dejarlos inservibles, obligando a actualizarlos con frecuencia.
- Incapacidad para manejar contenido dinámico: muchos sitios usan AJAX o JavaScript para cargar contenido, algo que los selectores CSS no pueden extraer directamente.
- Procesamiento de datos limitado: los selectores CSS solo pueden capturar fragmentos HTML sin limpieza, formato, análisis semántico ni análisis de sentimiento adicionales.
 Llega el extractor de artículos con IA.
Llega el extractor de artículos con IA.
-
Esta tecnología usa LLM para entender las páginas web, ofreciendo:
- Reconocimiento inteligente: identifica títulos, autores, resúmenes y contenido principal.
- Eliminación automática de ruido: distingue el contenido principal de la navegación, los anuncios y los artículos relacionados, mejorando la calidad de los datos y la eficiencia de la extracción.
- Adaptabilidad a cambios web: aunque cambien las estructuras o los estilos, la IA puede seguir extrayendo gracias a la comprensión semántica y a las características visuales.
- Generalización entre sitios: a diferencia de los scrapers tradicionales, los scrapers con IA pueden aplicarse en distintos sitios sin ajustes manuales.
- Integración con NLP y aprendizaje profundo: completa tareas como traducción, resumen y análisis de sentimiento.
¿Qué hace que el mejor extractor de artículos en 2026 destaque?
Un extractor de artículos de primer nivel equilibra rendimiento, coste, facilidad de uso, flexibilidad y escalabilidad. Estos son los criterios para elegir el mejor extractor de artículos en 2026:

- Facilidad de uso: interfaz intuitiva, sin necesidad de programar.
- Precisión en la extracción de artículos: identifica con exactitud la información relevante, sin anuncios ni elementos de navegación.
- Adaptación a cambios web: se ajusta automáticamente a cambios en la estructura o el estilo del sitio sin mantenimiento frecuente.
- Adaptabilidad a distintos sitios web: funciona en diversas estructuras web.
- Manejo de contenido dinámico: admite carga dinámica de contenido con JavaScript o AJAX.
- Manejo multimedia: reconoce imágenes, vídeos y audio.
- Manejo antiextracción: usa rotación de IP, soluciones CAPTCHA y proxies para sortear mecanismos antiextracción.
- Uso equilibrado de recursos: no consume memoria ni recursos de cómputo en exceso.
Los mejores extractores de artículos y noticias de un vistazo
| Herramientas | Funciones clave | Ideal para | Precio |
|---|---|---|---|
| Thunderbit | Extractor impulsado por IA; plantillas prediseñadas; admite extracción de pdf, imágenes y documentos; capacidades avanzadas de procesamiento de datos | Usuarios sin perfil técnico que necesitan extraer varios sitios de nicho | Prueba gratuita de 7 días, desde 9 $/mes (plan anual) |
| WebScraper.io | Extensión del navegador; compatibilidad con contenido dinámico; sin integración con proxy | Usuarios que no trabajan con páginas web complejas ni funciones avanzadas | Prueba gratuita de 7 días, desde 40 $/mes (plan anual) |
| Browse.ai | Raspador web y monitor sin código; robots prediseñados; navegador virtual; varios métodos de paginación; potente integración | Empresas que necesitan extraer sitios complejos a gran escala | 19 $/mes (plan anual) |
| Octoparse | Raspador sin código basado en selectores CSS; detección automática y generación del flujo de trabajo; plantillas prediseñadas para artículos; navegador virtual; mecanismos anti-anti-extracción | Empresas que necesitan extraer sitios complejos | Desde 99 $/mes (plan anual) |
| Bardeen | Capacidades integrales de automatización web; plantillas prediseñadas; extractor sin código; integración fluida con el espacio de trabajo | Equipos GTM que integran la extracción de artículos en flujos de trabajo existentes | Prueba gratuita de 7 días, desde 99 $/mes (plan anual) |
| PandaExtract | Interfaz fácil de usar; detección y etiquetado automáticos | Usuarios que necesitan una extracción rápida con un solo clic, sin configuraciones complejas | 49 $ pago único |
El extractor de artículos con IA más potente para usuarios de empresa
- Ventajas:
- Usa lenguaje natural para pedir a la IA el reconocimiento y análisis de información web, eliminando los selectores CSS
- Análisis de datos asistido por IA, incluida la conversión de formato, resumen, clasificación, traducción y etiquetado
- Plantillas de artículos prediseñadas para extraer con un solo clic listas de artículos y su contenido
- Precios asequibles con una excelente relación calidad-precio
- Desventajas:
- Actualmente solo está disponible como extensión de Chrome
- No es adecuado para extracción de datos a gran escala
- La velocidad es menor en extracciones de varias páginas, aunque puede ejecutarse en segundo plano para obtener resultados más rápidos
Prueba el extractor de artículos con IA de Thunderbit
Un extractor de artículos impulsado por IA para uso empresarial
Browse.ai
- Ventajas:
- Extractor y monitor de artículos sin código
- Admite operación con navegador virtual para evitar activar mecanismos antiextracción
- Numerosos robots de extracción de artículos prediseñados para extraer con un clic Google News, Medium, Hacker News y más
- Integración profunda con plataformas como Zapier y Make para conectar herramientas
- Desventajas:
- Usar la extracción profunda requiere crear dos robots, lo que complica el proceso
- Los selectores CSS carecen de precisión en sitios de nicho
- Es caro y resulta más adecuado para tareas de extracción continua a gran escala
Un extractor sin código para extracción de datos a pequeña escala
PandaExtract
- Ventajas:
- Identifica automáticamente listas y detalles de artículos con una interfaz fácil de usar
- Puede extraer listas, detalles, correos electrónicos e imágenes; es adecuado para extracción estructurada a pequeña escala
- Pago único para uso de por vida
- Desventajas:
- Solo está disponible como extensión del navegador; no puede ejecutarse en la nube
- La versión gratuita solo permite copiar, no exportar a CSV, JSON, etc.
Un extractor de artículos listo para usar para organizaciones
Octoparse
- Ventajas:
- Extractor de artículos sin código con detección automática para reconocer la estructura web y generar el flujo de trabajo de extracción
- Numerosas plantillas prediseñadas para extraer artículos, listas para usar
- Usa navegador virtual con rotación de IP, soluciones CAPTCHA y proxies para sortear mecanismos antiextracción
- Desventajas:
- La detección automática sigue dependiendo de la lógica de selectores CSS, con una precisión media
- Las funciones avanzadas requieren aprendizaje y conocimientos técnicos
- Coste elevado para extracción de datos a gran escala
La automatización más completa para equipos GTM
Bardeen
- Ventajas:
- Extractor de artículos sin código que usa LLM para automatizar con un solo clic
- Se integra con más de 100 aplicaciones, incluidas Google Sheets, Slack y Zoom
- Potentes herramientas de automatización web para análisis con IA después de extraer los datos
- Ideal para integrar la extracción de datos en flujos de trabajo existentes
- Desventajas:
- Depende mucho de playbooks prediseñados; los flujos personalizados requieren prueba y error
- Aunque es una plataforma sin código, entender y configurar automatizaciones complejas puede requerir tiempo de aprendizaje para usuarios no técnicos
- La configuración de extracción en subpáginas es compleja
- Muy caro
Un extractor de artículos ligero para extraer datos al instante
Webscraper.io
- Ventajas:
- Raspador sin código con interfaz de apuntar y hacer clic
- Admite carga de contenido dinámico
- Funciona en la nube
- Se integra con Dropbox, Google Sheets y Amazon
- Desventajas:
- No tiene plantillas prediseñadas; requiere crear un sitemap personalizado
- Tiene curva de aprendizaje para usuarios que no están familiarizados con los selectores CSS
- La configuración de paginación y extracción de subpáginas es compleja
- La versión en la nube es cara
Soluciones más avanzadas para ingenieros
Para quienes tienen perfil técnico, existen APIs de extractores de artículos. Estas soluciones ofrecen:
- Flexibilidad: llamadas directas a la API para extracción personalizada, con compatibilidad con renderizado dinámico y rotación de IP
- Escalabilidad: integración en canalizaciones de datos personalizadas para necesidades empresariales de alto volumen y alta frecuencia
- Bajo coste de mantenimiento: no hace falta gestionar pools de proxies ni estrategias antiextracción, lo que ahorra tiempo operativo
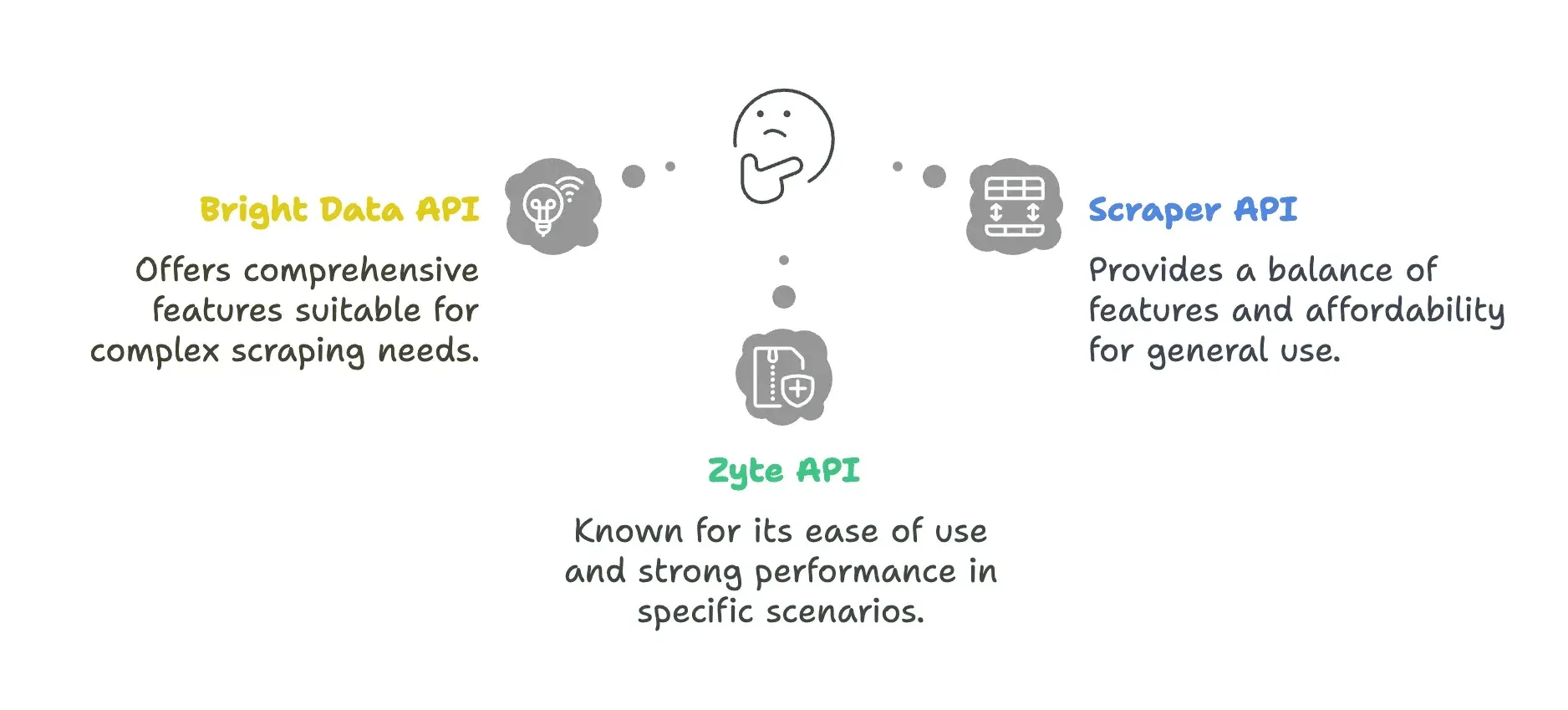
Soluciones API de un vistazo
| API | Ventajas | Desventajas |
|---|---|---|
| Bright Data API | - Amplia red de proxies (más de 72 M de IP en 195 países) - Geolocalización avanzada hasta nivel de ciudad/código postal - Sólido Proxy Manager para rotación de IP | - Tiempos de respuesta más lentos (22,08 s de media) - Precio más alto, no apto para equipos pequeños - Curva de aprendizaje más pronunciada para la configuración |
| ScraperAPI | - Precio inicial más bajo, desde 49 $ - Función Autoparse para extraer datos automáticamente - Reproductor de interfaz web para pruebas | - A menudo cobra por solicitudes bloqueadas - Funciones limitadas de renderizado de JavaScript - Los costes pueden dispararse con el parámetro premium |
| Zyte API | - Capacidades de análisis con IA - No cobra por solicitudes fallidas | - Coste inicial más alto (unos 450 $/mes) - Los créditos no se trasladan de un mes a otro |
- API de Web Scraper de Bright Data
- Ventajas:
- Desventajas:
- Alto coste (se factura por solicitud y ancho de banda), baja rentabilidad para proyectos pequeños
- API de Scraper
- Ventajas:
- 40 M de proxies globales, cambio automático entre IP de centros de datos y residenciales, omite la verificación de Cloudflare e integra soluciones CAPTCHA de terceros (p. ej., 2Captcha)
- Endpoints estructurados y scrapers asíncronos para mayor velocidad de extracción
- Desventajas:
- Coste adicional por renderizado de páginas dinámicas, compatibilidad limitada con sitios AJAX complejos
- Ventajas:
- API de Zyte
- Ventajas:
- Extracción automática de datos web impulsada por IA, sin necesidad de desarrollar y mantener reglas de extracción para cada sitio
- Precios flexibles de pago por uso
- Desventajas:
- Las funciones avanzadas (p. ej., gestión de sesiones, navegador programable) requieren aprendizaje
- Ventajas:
¿Cómo elegir tu extractor de artículos y noticias?
Al elegir un extractor de artículos y noticias, piensa en tus necesidades de negocio, tu perfil técnico y tu presupuesto.

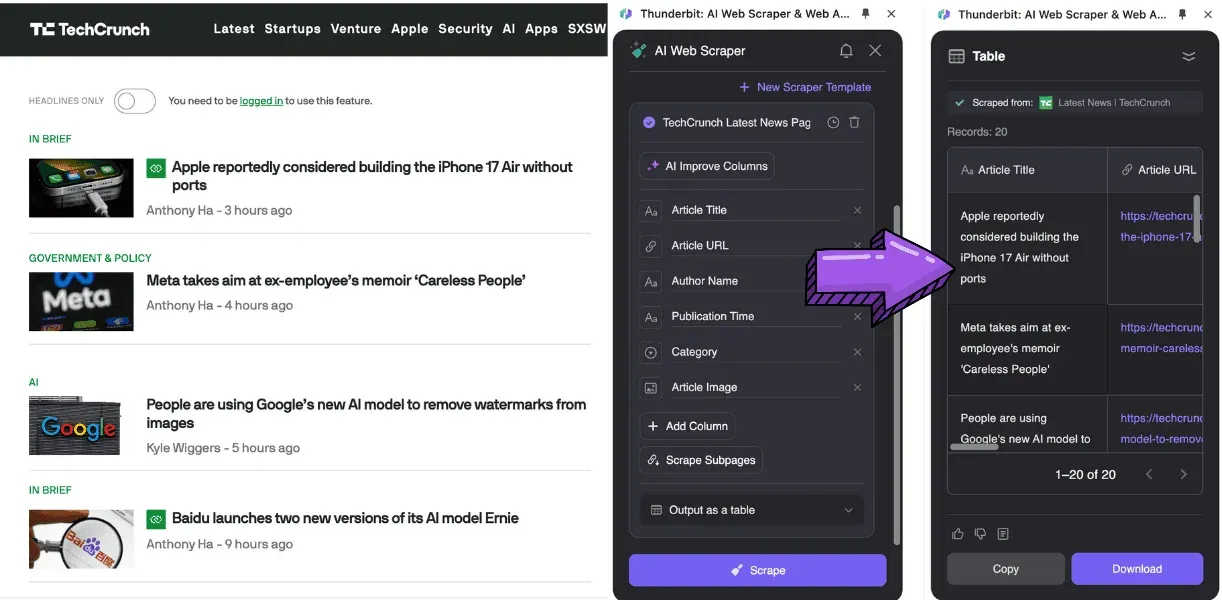
- Si necesitas extraer varios sitios de nicho sin construir un extractor para cada página y además cuentas con presupuesto, Thunderbit es tu mejor opción. No depende de selectores CSS, sino que usa IA para analizar la estructura web, lo que permite aplicar análisis con IA después de extraer los datos. Para Thunderbit AI, todos los sitios web son iguales, y captura artículos completos con precisión.
- Para extraer noticias y artículos de sitios grandes como Wall Street Journal o Google News, necesitarás un extractor de artículos con mecanismos antiextracción robustos y plantillas prediseñadas, como Browse.ai u Octoparse. Sin embargo, la mejor opción es una extensión de Chrome como Thunderbit: el proceso de extracción imita la navegación y el copiado manual, permitiendo usar credenciales de inicio de sesión sin configuraciones complicadas.
- Si necesitas extracción continua de datos a gran escala, son más adecuadas las herramientas con funciones de programación, como Octoparse.
- Para trabajo en equipo e integración fluida con flujos de trabajo existentes, Bardeen es ideal, ya que ofrece una amplia gama de herramientas de automatización web más allá de la extracción de artículos.
- Si quieres un extractor de artículos ligero para extraer datos pequeños sin perder tiempo aprendiendo, elige un extractor de artículos de apuntar y hacer clic como PandaExtract.
- Si tienes perfil técnico o estás construyendo un extractor de artículos empresarial, considera herramientas API o construir tu propio scraper, además de estos scrapers sin código.
Conclusión
En este artículo hemos presentado el concepto y los casos de uso empresarial de los extractores de artículos y noticias. Los scrapers tradicionales se basan en selectores CSS, por lo que requieren ciertos conocimientos de HTML y CSS web, especialmente para operaciones avanzadas. La nueva generación de extractores de artículos impulsados por IA se apoya por completo en la comprensión semántica y las capacidades de reconocimiento visual de la IA, superando a los scrapers tradicionales en adaptación a cambios en la estructura web, generalización entre sitios, manejo de contenido dinámico y limpieza y análisis posteriores de datos.
El artículo también enumeró seis extractores de artículos y noticias, además de herramientas API útiles para desarrolladores, comparando sus ventajas y desventajas, las escalas de datos adecuadas, las funciones web y los usuarios objetivo. Al evaluar la extracción de artículos y noticias, elige la solución que encaje con tus necesidades de negocio, equilibrando rendimiento y coste.
Preguntas frecuentes
1. ¿Qué es un extractor de artículos con IA y cómo funciona?
- Usa IA para analizar y extraer contenido de páginas web sin necesidad de selectores CSS.
- Identifica títulos, autores, fechas de publicación y contenido principal con gran precisión.
- Elimina automáticamente anuncios, menús de navegación y otros elementos irrelevantes.
- Se adapta a cambios en la estructura web y funciona en distintos sitios web.
2. ¿Cuáles son las ventajas de usar un extractor de artículos impulsado por IA frente a los scrapers tradicionales?
- Puede extraer contenido de varios sitios web con una sola herramienta.
- Gestiona contenido dinámico, incluidas páginas cargadas con JavaScript y AJAX.
- Requiere menos configuración manual y menos mantenimiento que los scrapers basados en CSS.
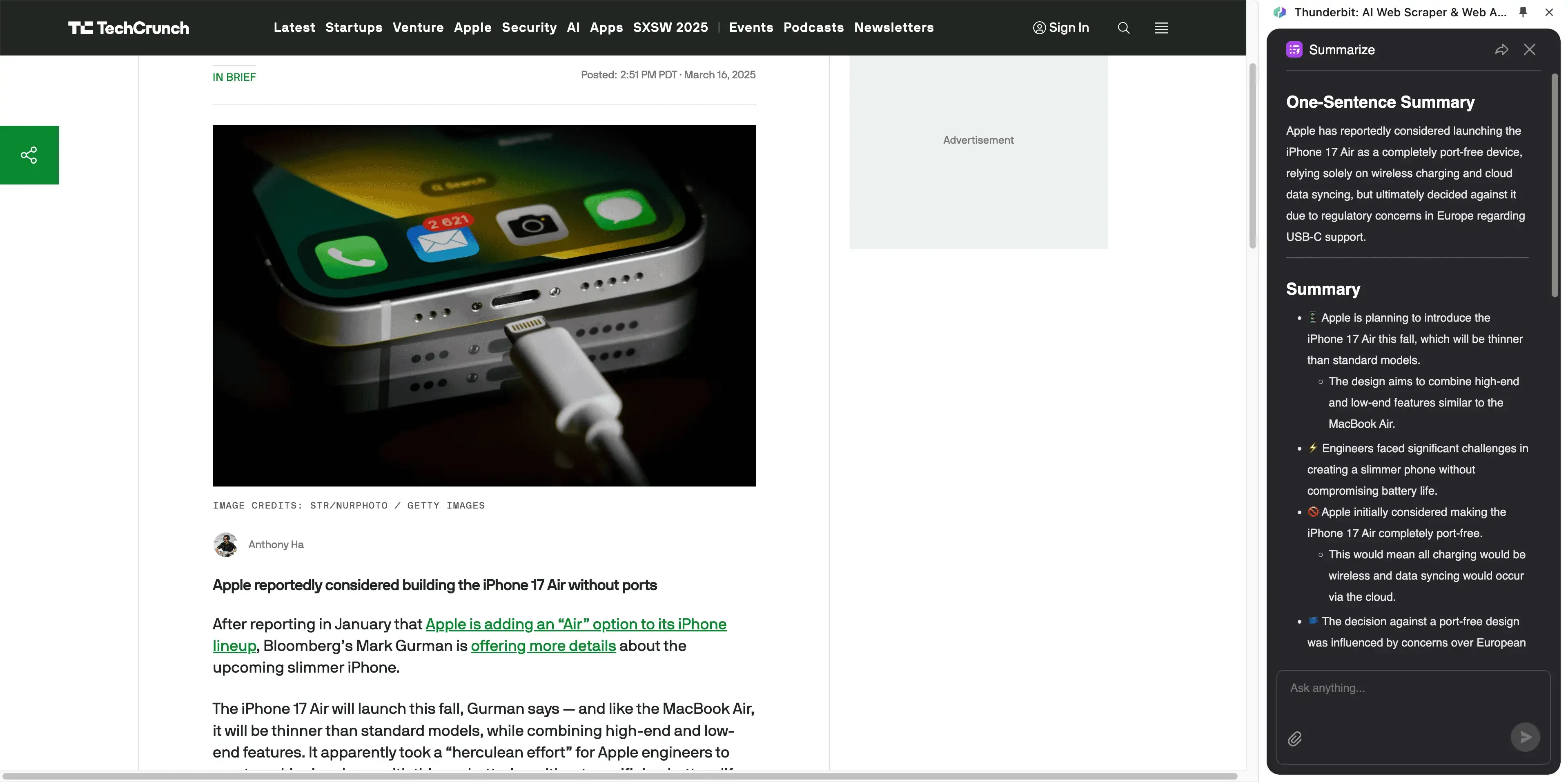
- Ofrece funciones adicionales como resumen, traducción y análisis de sentimiento.
3. ¿Puedo usar Thunderbit para extraer artículos con IA sin saber programar?
- Sí, Thunderbit está diseñado para usuarios no técnicos con una interfaz sencilla y sin código.
- Usa IA para detectar y extraer automáticamente el contenido de los artículos.
- Ofrece plantillas prediseñadas para una extracción rápida y eficiente.
- Permite exportar datos a distintos formatos como CSV, JSON y Google Sheets.
Más información:
- ¿Qué es el web scraping?
- Cómo usar IA para el web scraping
- Web scraping moderno: análisis en profundidad de las herramientas con IA
- Extracción de noticias: herramientas, casos de uso y desafíos
Prueba el Raspador Web IA Get Started Free




