Tumblr 爬虫
Vertraut von Profis bei führenden Unternehmen











Tumblr-Daten mit Thunderbit freischalten
Extrahieren Sie Tumblr-Daten wie Beitragstext und Like-Zahlen ganz mühelos.
Die ganze Tumblr-Story erfassen
Auf Tumblr-Übersichtsseiten werden oft nur Ausschnitte angezeigt. Um das vollständige Bild zu bekommen, brauchen Sie den gesamten Beitragstext, Autorendetails und alle zugehörigen Daten. Thunderbit besucht automatisch jede verlinkte Unterseite, extrahiert die Details und fügt sie als neue Spalten hinzu. So erfassen Sie post_id, post_date und mehr ganz ohne manuelles Klicken.
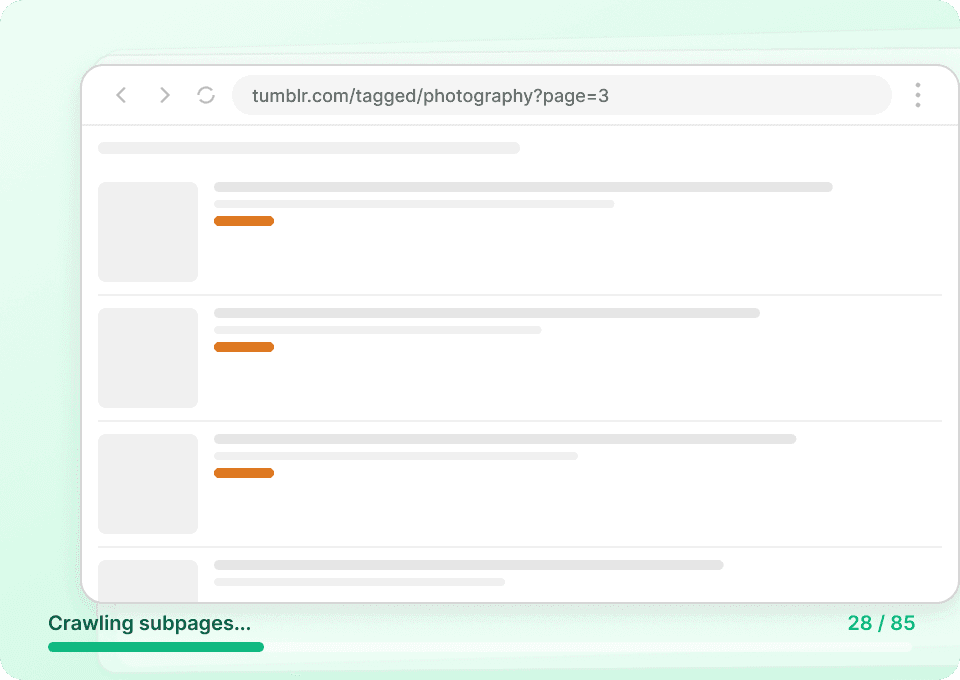
Ihre Tumblr-Datenerfassung automatisieren
Tumblr-Daten ändern sich ständig. Dieselben Blogs immer wieder manuell auszulesen, ist mühsam. Mit dem geplanten Auslesen von Thunderbit richten Sie wiederkehrende Aufgaben im Autopilot ein. Neue Daten wie like_count und post_content landen direkt in Google Sheets – ganz ohne Ihr Zutun.
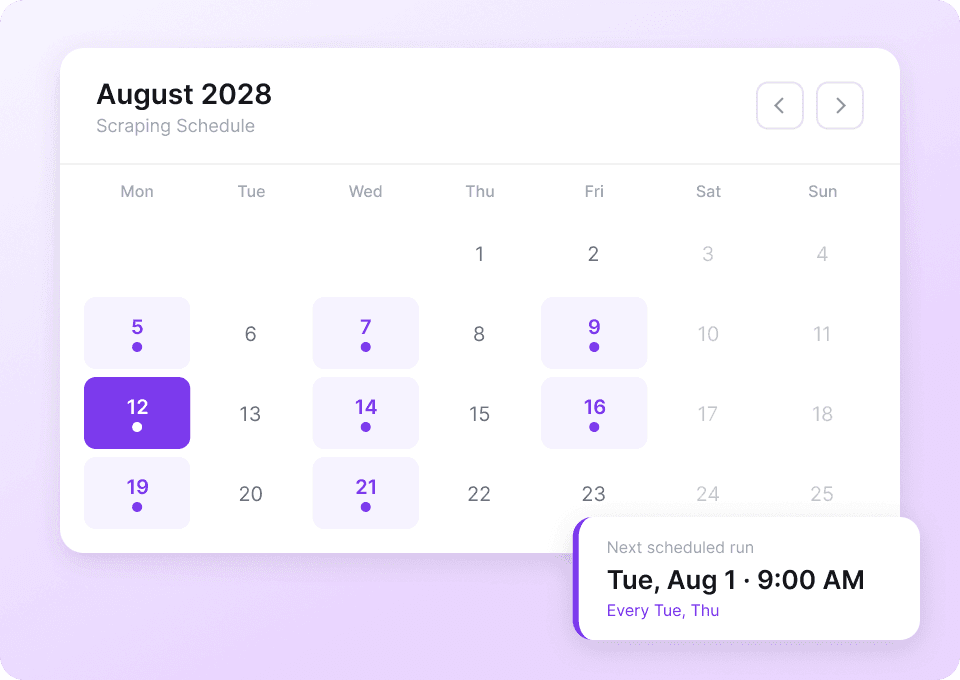
Tumblr-Posts in zwei Klicks auslesen
Vergessen Sie komplizierten Code oder CSS-Selektoren. Mit Thunderbit extrahieren Sie Tumblr-Daten in nur zwei Klicks. Zeigen Sie einfach auf die gewünschten Daten, und die semantische KI von Thunderbit erkennt die relevanten Felder wie post_type und post_author und extrahiert sie. Ganz ohne Programmierung erhalten Sie die Daten, die Sie von Tumblr brauchen.
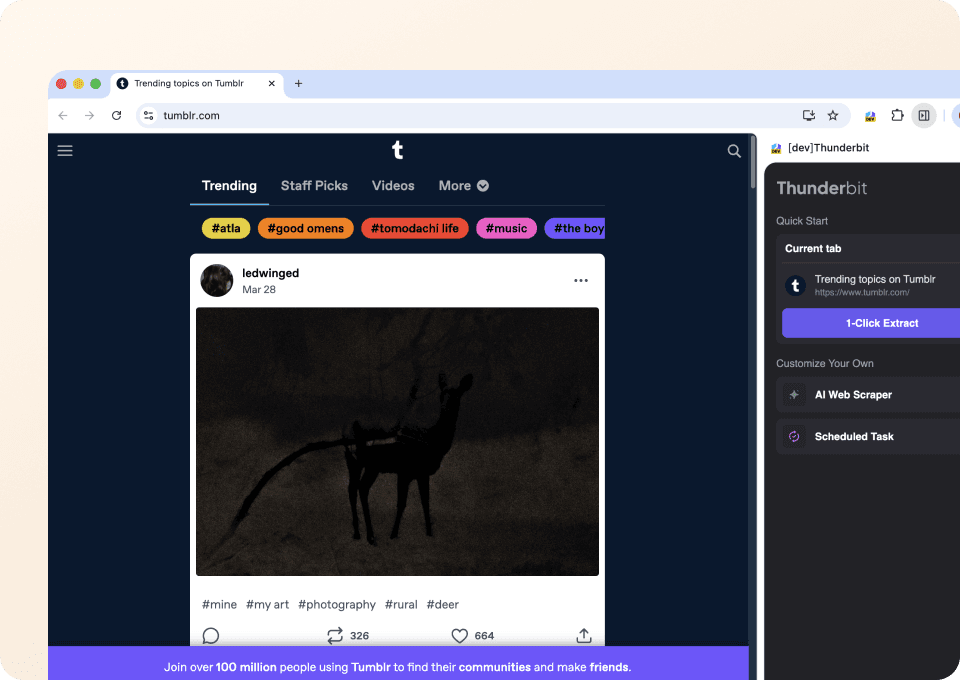
Warum unterscheidet sich Thunderbit von herkömmlichen Tumblr-Scrapern?
Tumblr-Daten mühelos extrahieren, selbst wenn sich Layouts ändern oder unerwartet verschieben.
Herkömmliche Scraper
Die alte VorgehensweiseThunderbit KI
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.






Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.

Trustpilot-Scraper
Verwandle Trustpilot-Seiten in eine saubere Tabelle mit Bewertungen, Ratings und Namen der Rezensenten. Wir lesen jede Seite für dich, sodass kein Code und kein Copy-Paste nötig ist.
Mehr erfahren ->On the Beach Web-Scraper
Mit dem Thunderbit On the Beach Scraper können Sie Urlaubs- und Hotelangebote, Preise, Bewertungen und vieles mehr von On the Beach in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge sammeln und strukturieren Sie Reisedaten im Handumdrehen – ideal für Analyse, Vergleich oder Reiseplanung. Perfekt für Reiseprofis, Analysten und Urlaubsplaner.
Mehr erfahren ->
Herold-Scraper
Mit dem Thunderbit Herold-Scraper können Sie Daten aus den Geschäfts- und Personensuchergebnissen von Herold in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie gezielt Firmennamen, Adressen, Telefonnummern, E-Mail-Adressen und mehr – perfekt für Leadgenerierung, Recherche oder Marketing. Ideal für Vertriebsteams, Marketer und Forschende, die strukturierte Herold-Daten benötigen.
Mehr erfahren ->Substack-Scraper
Hole dir Abonnentenzahlen, Artikeltitel und Beschreibungen von Substack-Publikationen in eine saubere Tabelle – ganz ohne Code, die KI übernimmt die Strukturierung.
Mehr erfahren ->
Tieba-Scraper
Mit dem Thunderbit Tieba Web-Scraper können Sie gezielt Daten aus Baidu Tieba erfassen – darunter aktuelle Trendthemen und Forenkategorien. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Themen, Links, Beitragszahlen und Nutzeraktivitäten – perfekt für Recherche, Marketing oder Content-Erstellung. Ideal, um Social-Media-Trends und Diskussionen auf Tieba zu analysieren.
Mehr erfahren ->
People-Search-Scraper
Mit dem Thunderbit People-Search-Scraper können Sie strukturierte Daten aus People-Search-Profilen und Seiten zur Rückwärtssuche von Telefonnummern extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie blitzschnell Namen, Orte, Telefonnummern, E-Mail-Adressen und mehr – ideal für Recherche, Marketing oder Lead-Generierung. Perfekt für Marketer, Analysten und Unternehmen, die öffentliche Kontaktdaten und Informationen benötigen.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Die kostenlose Testphase bietet unbegrenzte Credits für 8 Webseiten.