Substack-Scraper

Vertrauenswürdig für Profis in führenden Unternehmen











Schalte Substack-Daten mit Thunderbit frei
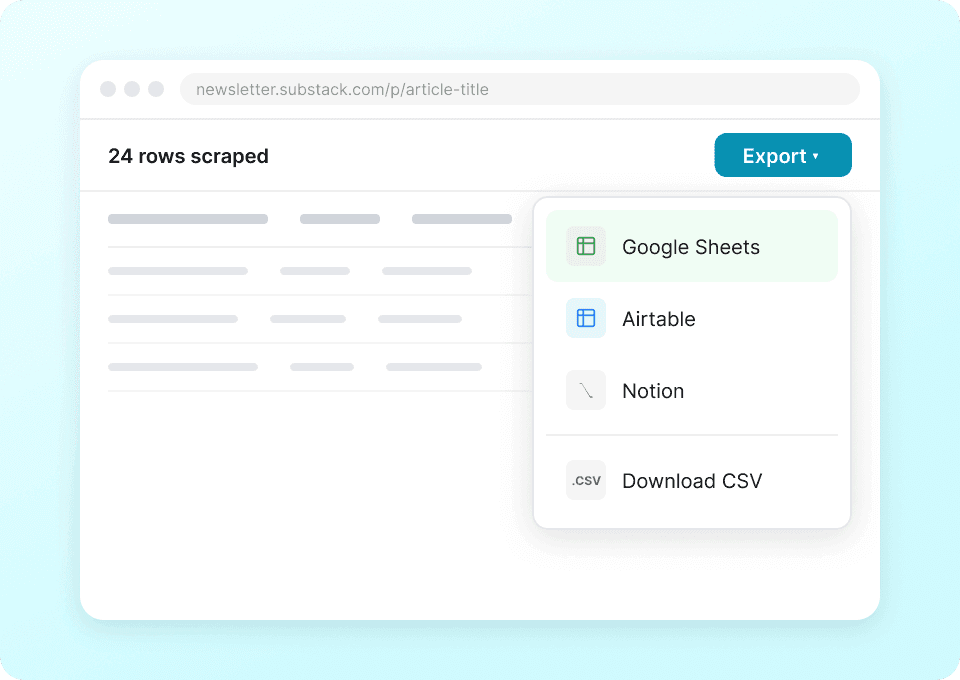
Sende Substack-Daten direkt an deine Apps
Hör auf, Substack-Publikationsdetails wie Autorenname, Artikeltitel und Abonnentenzahl manuell zu kopieren und einzufügen. Mit Thunderbit sendest du deine extrahierten Daten mit nur einem Klick direkt an Google Sheets, Notion oder Airtable. Analysiere Publikationstrends und Content-Performance ohne mühsame Handarbeit.
Ein Scraper für Substack und mehr
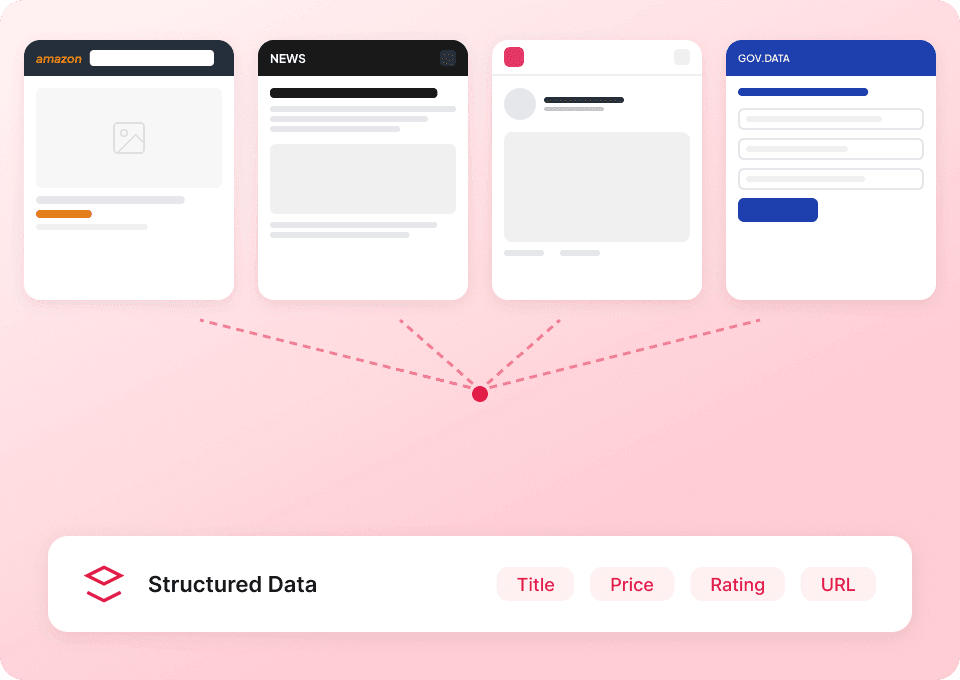
Bleib nicht bei einem anderen Scraper für jede Website hängen. Thunderbit funktioniert sofort mit Substack und enthält über 50 vorgefertigte Vorlagen für andere beliebte Plattformen. Extrahiere Publikationsbeschreibungen, Artikelinhalte und mehr und nutze dasselbe Tool anschließend, um Daten von überall sonst zu sammeln.
Erhalte die vollständige Substack-Story
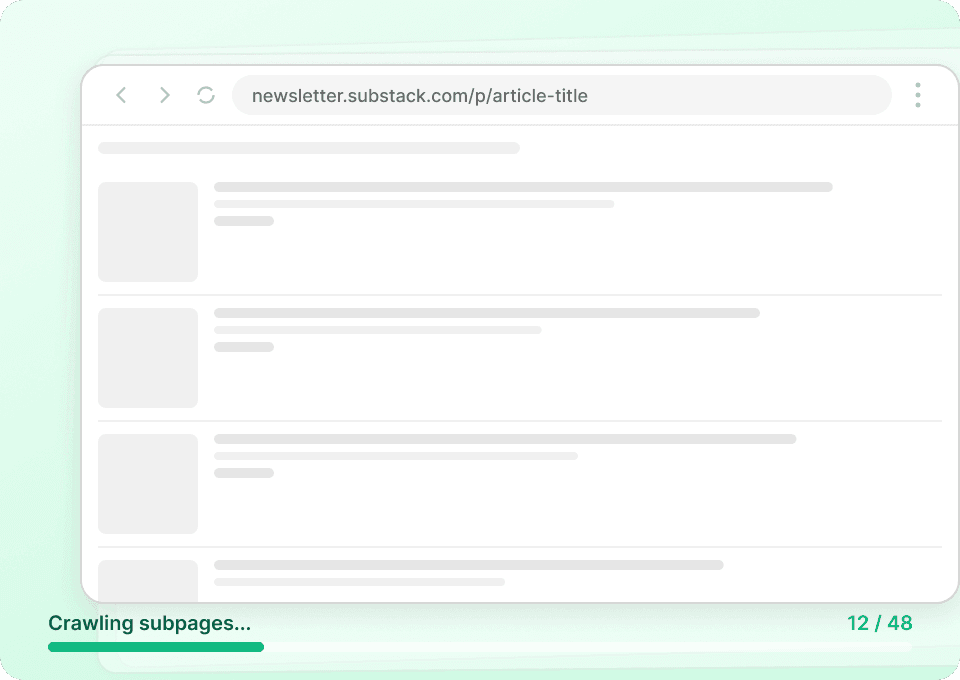
Auf den Übersichtsseiten von Substack-Publikationen werden nur Zusammenfassungen angezeigt. Thunderbit besucht automatisch jede Artikelseite, um den vollständigen Inhalt zu extrahieren, und liefert dir so einen kompletten Datensatz. Erhalte den gesamten Artikeltitel, Autorenname, Publikationsname und Artikelinhalt in einem Durchgang.
Schwierigkeiten, Substack effektiv zu scrapen?
Sieh selbst, warum Thunderbit traditionelle Scraper für Substack-Daten übertrifft.
Traditionelle Scraper
Die alte Art, Dinge zu erledigenThunderbit
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Sieh dir an, was unsere Nutzer über Thunderbit sagen.








Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web-Scraper.
Tradera Web-Scraper
Mit dem Thunderbit Tradera Web-Scraper können Sie mühelos Daten aus Tradera-Angeboten und Produktseiten extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie Produktnamen, Preise, Kategorien, Bilder und Beschreibungen – ideal für Analysen oder die Bestandsverwaltung. Perfekt für Online-Händler, Sammler und Forscher, die strukturierte Tradera-Daten benötigen.
Mehr erfahren ->
Trustpilot-Scraper
Verwandle Trustpilot-Seiten in eine saubere Tabelle mit Bewertungen, Ratings und Namen der Rezensenten. Wir lesen jede Seite für dich, sodass kein Code und kein Copy-Paste nötig ist.
Mehr erfahren ->
UpCity Scraper
Mit dem Thunderbit UpCity-Scraper können Sie Daten aus den Agentur-Listings und Anbieterbewertungen von UpCity extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie im Handumdrehen Agenturnamen, Standorte, Bewertungen, Kontaktdaten und ausführliche Rezensionen – ideal für Analysen oder Recherchen. Perfekt für Marketer, Forscher und Unternehmer, die strukturierte UpCity-Daten benötigen.
Mehr erfahren ->PeopleWhiz-Scraper
Der Thunderbit PeopleWhiz-Scraper ermöglicht es dir, mit KI-gestützten Feldvorschlägen Daten aus PeopleWhiz-Suchergebnissen und Profilen zu extrahieren. Erfasse Namen, Kontaktdaten, Standorte und mehr für Recherche, Marketing oder Lead-Generierung. Verwandle PeopleWhiz-Daten schnell und effizient in strukturierte Datensätze.
Mehr erfahren ->
UNIQLO Web-Scraper
Erfasse Produktdaten von Uniqlo wie Namen, Preise und verfügbare Größen mit nur 2 Klicks – dank der Chrome-Erweiterung von Thunderbit.
Mehr erfahren ->
Amarillas.com Scraper
Mit dem Thunderbit Amarillas.com-Scraper können Sie strukturierte Daten von Amarillas.com extrahieren, darunter Einträge von Motels und Restaurants. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Firmennamen, Standorte, Kontaktnummern, Bewertungen und Rezensionen – ideal für Recherche, Marketing oder Lead-Generierung.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.