JD.COM Scraper











JD.com-Produktdaten mühelos extrahieren
Saubere JD-Daten, direkt exportbereit
Rohdaten zu erhalten ist nur die halbe Miete. Thunderbit strukturiert und formatiert Ihre JD.com-Daten automatisch bereits während der Extraktion. Exportieren Sie Produktnamen, Preise, SKUs, Bewertungen, Rezensionenzahlen und Marken in bereinigter Form — bereit für die Analyse, ohne mühsames Datenaufbereiten.
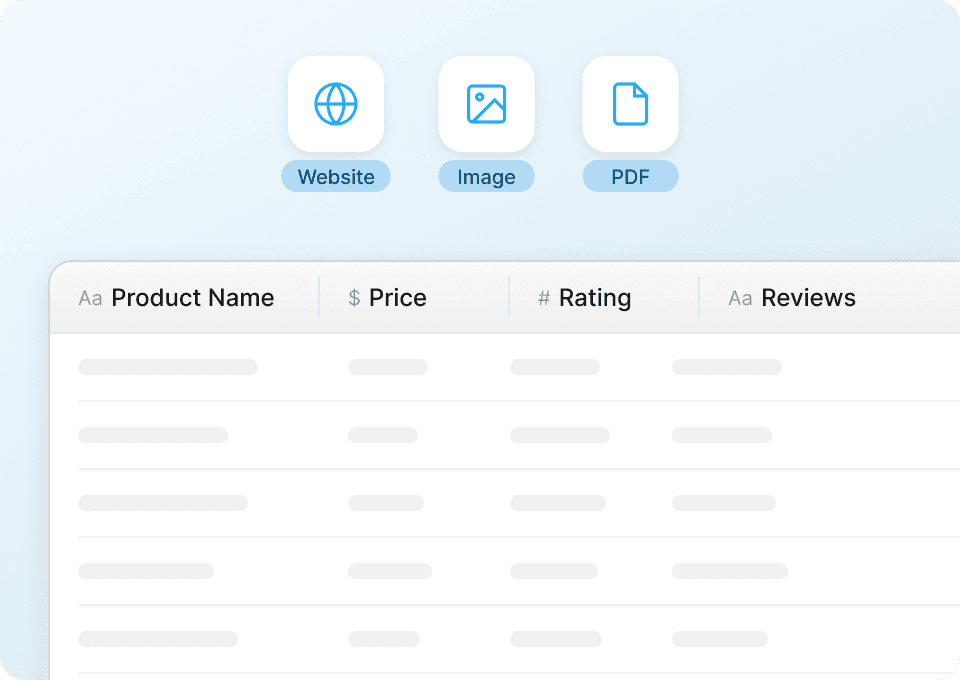
JD-Unterseiten für vollständige Details scrapen
Auf JD.com-Listingseiten fehlt oft der vollständige Kontext. Thunderbit besucht automatisch jede Produkt-Unterseite, um komplette Details wie Spezifikationen, Beschreibungen und Merkmale zu erfassen — ganz ohne manuelles Durchklicken. Alle Daten von Unterseiten werden als neue Spalten angehängt, sodass Sie mit einem einzigen Export einen vollständigen Produktdatensatz erhalten.
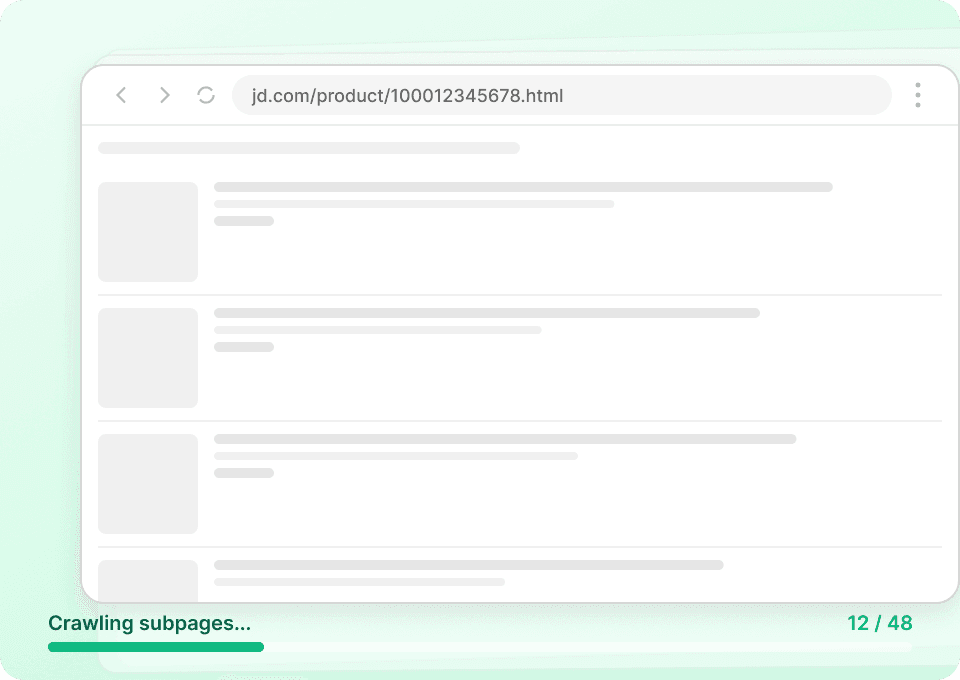
JD-Datenextraktion im großen Maßstab
Produkt für Produkt auf JD.com zu scrapen ist langsam und auf Dauer nicht praktikabel. Mit Thunderbit können Sie Daten von Hunderten JD.com-Seiten gleichzeitig extrahieren — übergeben Sie einfach eine URL-Liste, und Thunderbit erledigt den Rest. Produktnamen, Preise und alle wichtigen Datenpunkte werden automatisch abgerufen, unabhängig vom Umfang.

Schwierigkeiten beim effektiven Scrapen von JD.com?
Sehen Sie, wie Thunderbit die Datenextraktion im Vergleich zu herkömmlichen Methoden vereinfacht.
Traditionelle Scraper
Die alte VorgehensweiseThunderbit
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Sieh dir an, was unsere Nutzer über Thunderbit sagen.





Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web-Scraper.

Amarillas.com Scraper
Mit dem Thunderbit Amarillas.com-Scraper können Sie strukturierte Daten von Amarillas.com extrahieren, darunter Einträge von Motels und Restaurants. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Firmennamen, Standorte, Kontaktnummern, Bewertungen und Rezensionen – ideal für Recherche, Marketing oder Lead-Generierung.
Mehr erfahren ->
ReverseAustralia Scraper
Mit dem Thunderbit ReverseAustralia Scraper können Sie Daten von Beschwerde- und Kommentarseiten auf ReverseAustralia extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Telefonnummern, Beschreibungen von Beschwerden, Kommentartexte, Nutzernamen und vieles mehr – ideal für Analysen oder Recherchen. Perfekt für Marketer, Forschende und Unternehmen, die strukturierte Feedbackdaten benötigen.
Mehr erfahren ->
Trustpilot-Scraper
Extrahieren Sie Trustpilot-Bewertungen, Sternebewertungen und Rezensenten-Details in nur 2 Klicks — und exportieren Sie alles direkt nach Google Sheets, Excel oder Notion. Kein Code, kein Copy-Paste, nur saubere, strukturierte Daten, die sofort analysiert und geteilt werden können.
Mehr erfahren ->
HKTVmall Web-Scraper
Produktnamen, Preise, Bewertungen und mehr aus HKTVmall-Angeboten in nur 2 Klicks extrahieren — ganz ohne Programmierung. Exportieren Sie die Daten direkt nach Excel, Google Sheets oder Notion und verwandeln Sie HKTVmall-Daten in umsetzbare Erkenntnisse.
Mehr erfahren ->On the Beach Web-Scraper
Mit dem Thunderbit On the Beach Scraper können Sie Urlaubs- und Hotelangebote, Preise, Bewertungen und vieles mehr von On the Beach in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge sammeln und strukturieren Sie Reisedaten im Handumdrehen – ideal für Analyse, Vergleich oder Reiseplanung. Perfekt für Reiseprofis, Analysten und Urlaubsplaner.
Mehr erfahren ->
iBegin Scraper
Mit dem Thunderbit iBegin-Scraper können Sie Suchergebnisse und detaillierte Unternehmensinformationen von der iBegin-Website extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Firmennamen, Kontaktdaten, Adressen, Bewertungen und vieles mehr – ideal für Leadgenerierung, Recherche oder Marketinganalysen.
Mehr erfahren ->Bereit, deine Datenextraktion auf das nächste Level zu bringen?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.



