Artikel-Scraper











Artikeldaten mühelos freischalten
Extrahieren Sie wichtige Artikeldaten ohne Programmierkenntnisse.
Bleibt automatisch aktuell
Haben Sie genug von Scrapern, die bei jedem Website-Relaunch kaputtgehen? Thunderbit versteht die Bedeutung einer Seite und nicht nur feste Positionen von Elementen. So extrahieren Sie Artikeltitel, Autoren und Inhalte zuverlässig – selbst wenn sich die Struktur einer Website ändert.

Automatisieren Sie Ihre Artikeldaten-Erfassung
Metadaten zu Artikeln wie Veröffentlichungsdaten, Keywords und Kategorien ändern sich ständig. Planen Sie Thunderbit für den automatischen Abruf ein und lassen Sie frische Inhalte direkt in Google Sheets, Notion oder Airtable liefern – ganz ohne manuelle Arbeit.
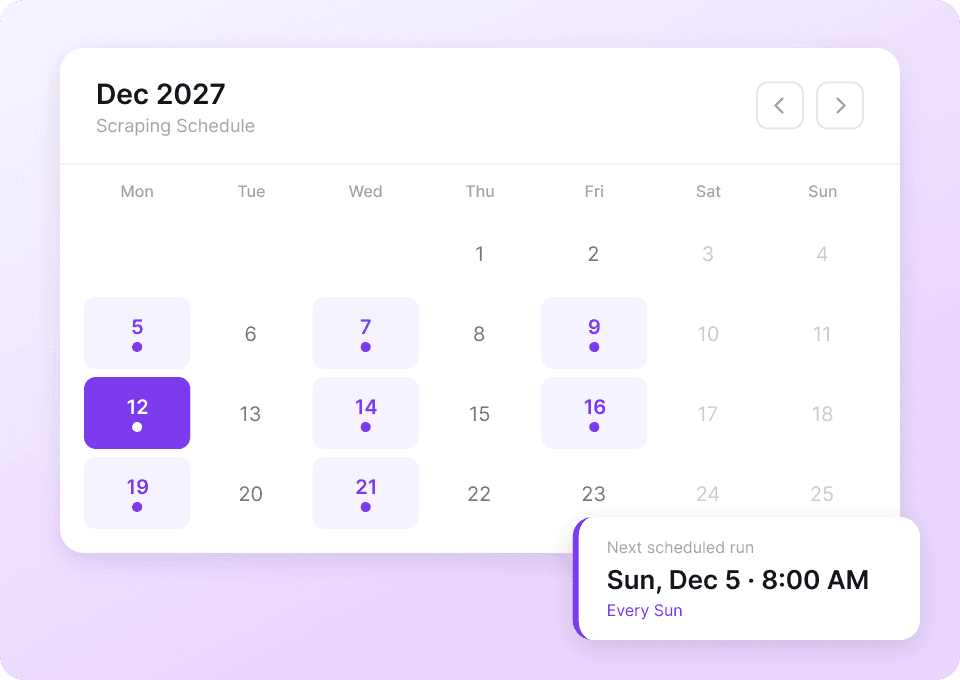
Daten von jeder Website scrapen
Warum für jede Nachrichtenquelle einen anderen Scraper verwenden? Thunderbit funktioniert sofort auf jeder Website. Mit über 50 vorgefertigten Vorlagen dauert das Sammeln von Artikeldaten – unabhängig vom Verlag – nur wenige Klicks.
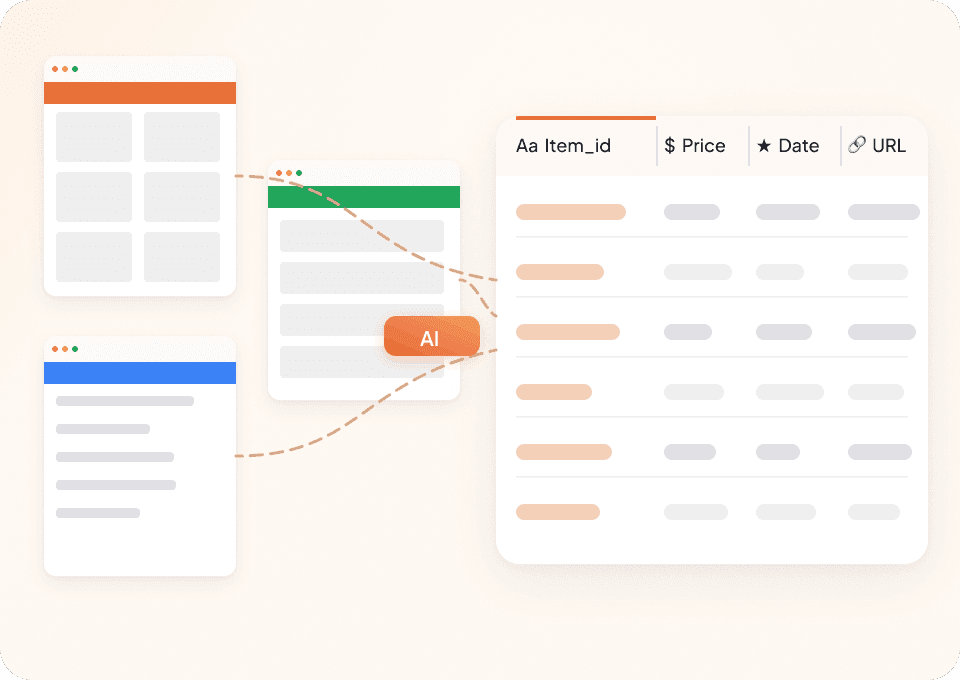
Warum unterscheidet sich Thunderbit von herkömmlichen Artikel-Scrapern?
Thunderbit nutzt KI, um Daten aus Artikeln schnell und zuverlässig zu extrahieren.
Traditionelle Scraper
Die alte VorgehensweiseThunderbit KI
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.




Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.
PeopleWhiz-Scraper
Der Thunderbit PeopleWhiz-Scraper ermöglicht es dir, mit KI-gestützten Feldvorschlägen Daten aus PeopleWhiz-Suchergebnissen und Profilen zu extrahieren. Erfasse Namen, Kontaktdaten, Standorte und mehr für Recherche, Marketing oder Lead-Generierung. Verwandle PeopleWhiz-Daten schnell und effizient in strukturierte Datensätze.
Mehr erfahren ->
White Pages Scraper
Mit dem Thunderbit White Pages-Scraper können Sie ganz einfach Daten aus Telefon- und Firmenverzeichnissen der White Pages extrahieren. Dank KI-gestützter Felderkennung sammeln Sie Namen, Telefonnummern, Adressen und Webseiten-Links für Leadgenerierung, Marketing oder Recherche – und das in wenigen Klicks.
Mehr erfahren ->
People-Search-Scraper
Mit dem Thunderbit People-Search-Scraper können Sie strukturierte Daten aus People-Search-Profilen und Seiten zur Rückwärtssuche von Telefonnummern extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie blitzschnell Namen, Orte, Telefonnummern, E-Mail-Adressen und mehr – ideal für Recherche, Marketing oder Lead-Generierung. Perfekt für Marketer, Analysten und Unternehmen, die öffentliche Kontaktdaten und Informationen benötigen.
Mehr erfahren ->Substack-Webscraper
Extrahieren Sie Substack-Abonnentenzahlen, Artikeltitel und Beschreibungen von Publikationen in nur 2 Klicks — und exportieren Sie die Daten anschließend nach Excel, Google Sheets oder Notion. Ganz ohne Code; Thunderbits KI übernimmt die Strukturierung für Sie.
Mehr erfahren ->
BestPrice GR Web-Scraper
Mit dem KI-gestützten BestPrice GR Web-Scraper von Thunderbit können Sie Produktlisten, Preise und detaillierte Informationen von BestPrice.gr in wenigen Klicks extrahieren. Ideal für Vertriebs-, Marketing- und E-Commerce-Teams, die schnell und effizient strukturierte Daten benötigen.
Mehr erfahren ->
TripAdvisor Unternehmenslisten-Scraper
Mit dem Thunderbit TripAdvisor Business Listings Scraper können Sie Daten aus den Geschäftseinträgen, dem Ressourcenbereich und dem Eigentümerforum von TripAdvisor extrahieren. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Ressourcennamen, URLs, Beschreibungen, Forenthemen, Autoren und Beiträge – ideal für Recherche, Marketing oder Analyse.
Mehr erfahren ->Bereit, deine Datenextraktion auf das nächste Level zu bringen?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.



