Wenn Sie schon einmal versucht haben, genau die richtige Datenmenge von einer Website zu holen — vielleicht eine Liste mit Konkurrenzpreisen, einen Produktkatalog oder frische Sales-Leads — kennen Sie das Gefühl: Standard-Scraping-Tools bringen Sie 80 % des Weges, aber die letzten 20 %? Genau dort treffen Magie und Frust aufeinander. In der heutigen datengetriebenen Welt können sich Unternehmen kein „fast richtig“ leisten. Maßgeschneiderte Extraktions- und Datenerfassungsdienste sind zum Rückgrat moderner Abläufe geworden; der globale Markt für Web-Scraping soll von 754 Millionen US-Dollar im Jahr 2024 auf wachsen. Wenn Ihre Datenstrategie kein Custom Scraping umfasst, sind Sie in Ihrem Markt möglicherweise schon unsichtbar.
Ich habe jahrelang Teams geholfen — von wilden Start-ups bis hin zu etablierten Unternehmen — aus endlosen Copy-Paste-Marathons und fragilen One-Size-Fits-All-Tools herauszukommen. Der Unterschied? Maßgeschneiderte Datenerfassung richtig zu beherrschen. In diesem Leitfaden erkläre ich, was Custom Extraction wirklich bedeutet, warum sie so wichtig ist, wie (der KI-Web-Scraper, den mein Team und ich entwickelt haben) sie radikal einfach macht und wie Sie den richtigen Datenerfassungsdienst für Ihr Unternehmen auswählen. Ich erzähle auch ein paar Geschichten aus dem Maschinenraum — denn seien wir ehrlich: Jeder Daten-Nerd hat davon einige.
Was ist Custom Extraction? Das Potenzial maßgeschneiderter Datenerfassungsdienste freisetzen
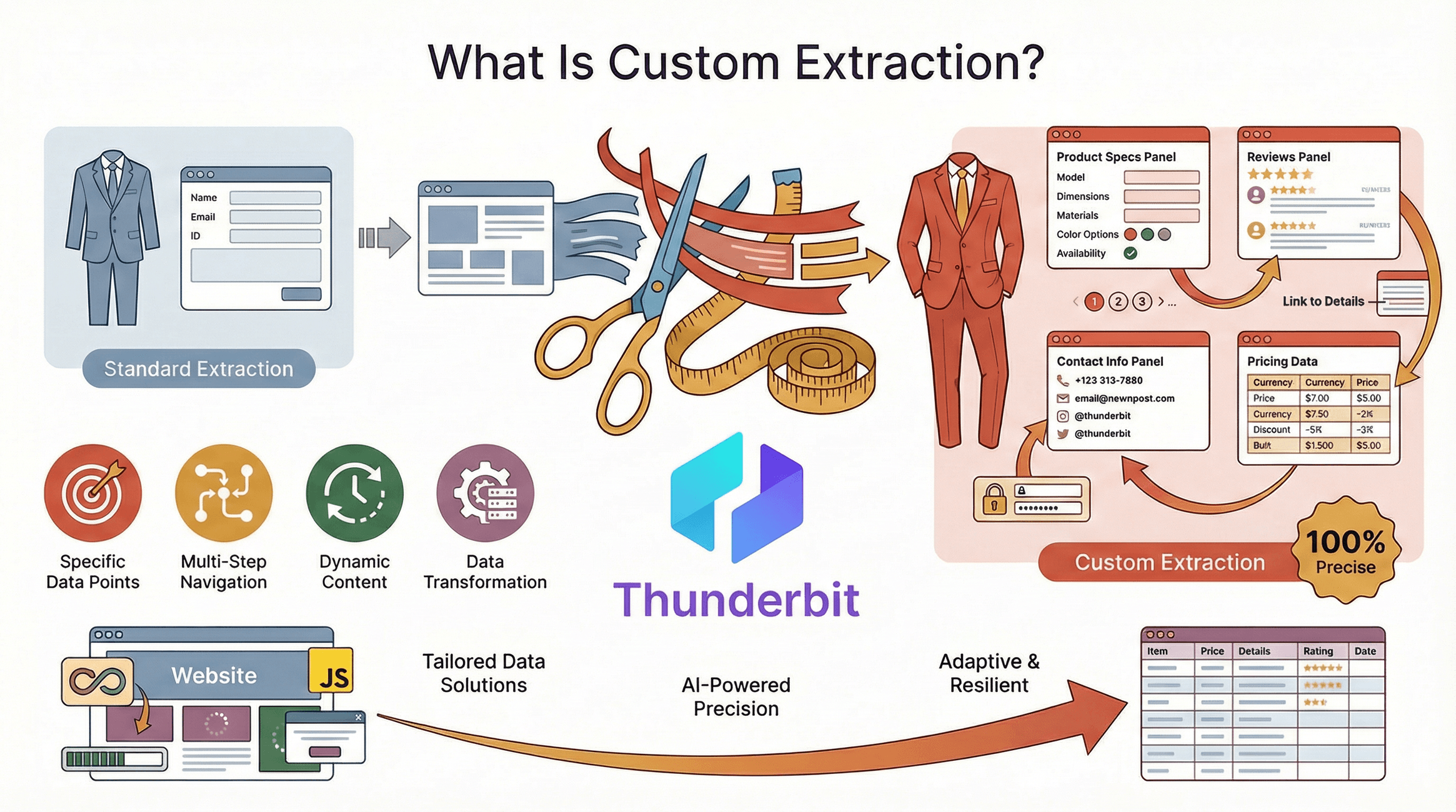 Beginnen wir mit den Grundlagen: Custom Extraction bedeutet, genau die Daten zu bekommen, die Sie brauchen — in dem Format, das Sie wollen — von den Websites, die für Ihr Unternehmen wichtig sind. Anders als Standard-Scraping-Tools, die einfach alles einsammeln, was leicht erreichbar oder sichtbar ist, ist maßgeschneiderte Datenerfassung präzise, anpassungsfähig und robust — selbst dann, wenn Websites komplex oder dynamisch sind oder ihr Layout gefühlt alle zwei Wochen ändern.
Beginnen wir mit den Grundlagen: Custom Extraction bedeutet, genau die Daten zu bekommen, die Sie brauchen — in dem Format, das Sie wollen — von den Websites, die für Ihr Unternehmen wichtig sind. Anders als Standard-Scraping-Tools, die einfach alles einsammeln, was leicht erreichbar oder sichtbar ist, ist maßgeschneiderte Datenerfassung präzise, anpassungsfähig und robust — selbst dann, wenn Websites komplex oder dynamisch sind oder ihr Layout gefühlt alle zwei Wochen ändern.
Stellen Sie es sich wie einen Maßanzug statt wie Ware von der Stange vor. Mit Custom Extraction sind Sie nicht auf „Standard“-Felder oder Vorlagen beschränkt. Sie können:
- bestimmte Datenpunkte auswählen (z. B. Produktspezifikationen, Bewertungen oder Kontaktdaten)
- mehrstufige Navigation abbilden (Pagination, Unterseiten, Logins)
- mit dynamischen Inhalten umgehen (endloses Scrollen, per JavaScript geladene Daten)
- Daten direkt beim Extrahieren formatieren, bereinigen oder transformieren
Warum ist das wichtig? Weil echte Geschäftsanforderungen selten simpel sind. Vielleicht müssen Sie Produktlisten scrapen und dann jedem Link folgen, um detaillierte Spezifikationen und Bewertungen zu erfassen. Oder Sie möchten die Preise der Konkurrenz über Dutzende Seiten hinweg überwachen, aber nur für bestimmte SKUs. Standard-Tools brechen dann ab, übersehen Daten oder zwingen Sie dazu, zum Amateur-HTML-Detektiv zu werden. Custom-Extraction-Dienste dagegen sind genau für solche Szenarien gebaut — oft mit Unterstützung von KI und Natural Language Processing.
Wenn Sie tiefer in den Unterschied zwischen Custom und Standard Scraping eintauchen möchten, sehen Sie sich an.
Warum Custom Data Extraction Services für Unternehmenswachstum wichtig sind
Kommen wir zur Sache: Warum sollten Sie sich für Custom Data Extraction interessieren? Weil es nicht nur ein Tech-Upgrade ist — sondern ein Wachstumstreiber fürs Geschäft. So liefern Custom-Extraction-Dienste echte Ergebnisse:
| Geschäftsbedarf | Maßgeschneiderte Web-Scraping-Lösung | Typisches Ergebnis/ROI |
|---|---|---|
| Lead-Generierung | Aktuelle Kontakte aus Verzeichnissen, LinkedIn oder Bewertungsseiten scrapen | Bis zu 80 % weniger Zeit für manuelle Recherche; größere, relevantere Lead-Listen |
| Preisüberwachung der Konkurrenz | Preise und Bestände auf Wettbewerbsseiten verfolgen, auch bei dynamischen Layouts | Über 4 % mehr Umsatz durch dynamische Preisgestaltung; bis zu 15 % bessere Marge |
| Marktintelligenz & Recherche | Nachrichten, Bewertungen oder Regulierungsunterlagen in großem Maßstab zusammenführen | Über 50 % mehr Datennutzung; schnellere, fundiertere Entscheidungen |
| Produktkatalog-Updates | Produktinfos aus mehreren Quellen ziehen, Unterseiten und Varianten verarbeiten | Immer aktuelle Kataloge; weniger Fehler und manuelle Updates |
| Operative Automatisierung | Wiederkehrende Scrapes für Berichte, Compliance oder Bestände planen | 85 % schnellere Time-to-Market für Daten; 73 % geringere Erfassungskosten |
(, )
Unterm Strich: Custom Extraction ist kein Luxus, sondern eine wettbewerbsrelevante Notwendigkeit. Unternehmen, die sie beherrschen, setzen sich gegen ihre Rivalen durch, reagieren schneller auf Marktveränderungen und entdecken Erkenntnisse, die Wachstum vorantreiben.
Thunderbits Ansatz: Maßgeschneiderte Datenerfassung einfach gemacht
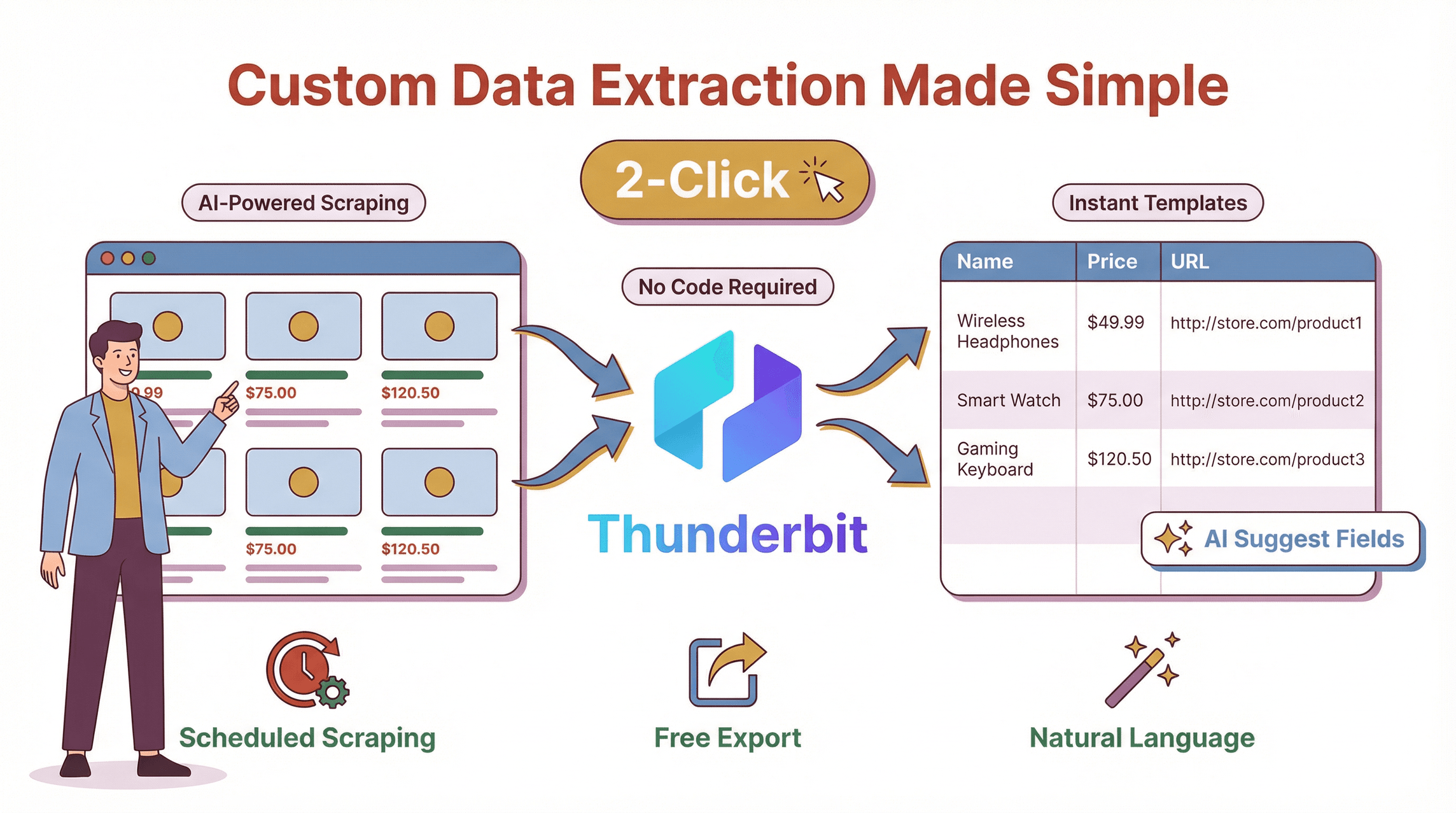
Ich bin ganz ehrlich: Ich habe Thunderbit gebaut, weil ich es leid war, Teams mit klobigen, code-lastigen Scrapern kämpfen zu sehen, die bei jeder kleinen Webseitenänderung auseinanderfielen. Thunderbit ist eine , die maßgeschneiderte Datenerfassung für alle zugänglich machen soll — nicht nur für Entwickler.
Das macht Thunderbit anders:
- KI-gestützte Feldvorschläge: Klicken Sie auf „KI-Felder vorschlagen“, und Thunderbit scannt die Seite und empfiehlt die besten Spalten zum Extrahieren — etwa „Produktname“, „Preis“, „Bild-URL“ oder „E-Mail“. Kein Rätselraten und kein Herumprobieren mit Selektoren mehr.
- Eingabe per natürlicher Sprache: Sie möchten ein Datum extrahieren, eine Beschreibung übersetzen oder Elemente kategorisieren? Sagen Sie Thunderbit einfach auf Deutsch, was Sie brauchen. Die KI findet den Weg.
- Scraping in 2 Klicks: Öffnen Sie die Zielseite, starten Sie Thunderbit und klicken Sie auf „Scrape“. Fertig. Kein Code, keine Vorlagen (außer Sie möchten welche), kein Kopfzerbrechen.
- Komplexe Seiten werden unterstützt: Thunderbit kommt mit Pagination, endlosem Scrollen, Unterseiten und sogar dynamischen, per JavaScript geladenen Inhalten zurecht. Es passt sich an, wenn sich Websites verändern.
- Unterseiten-Scraping: Sie brauchen mehr Details zu jedem Eintrag? Thunderbit kann automatisch jede Unterseite besuchen (z. B. Produktdetailseiten) und Ihre Tabelle anreichern.
- Geplantes Scraping: Richten Sie wiederkehrende Scrapes mit natürlicher Sprache ein („jeden Montag um 9 Uhr“) und lassen Sie Thunderbit den Rest erledigen.
- Sofortvorlagen: Für beliebte Seiten wie Amazon, Zillow oder LinkedIn bietet Thunderbit Vorlagen mit einem Klick — keine Einrichtung nötig.
- Kostenloser Datenexport: Exportieren Sie Ihre Daten nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON — ohne Bezahlschranken, ohne Limits.
Thunderbits Mission ist einfach: Anwenderinnen und Anwender sollen beschreiben können, was sie möchten, und die KI übernimmt die technische Schwerarbeit. Es ist, als hätten Sie einen KI-gestützten Forschungsassistenten, der nie müde wird und sich nie über Kaffee beschwert.
Schritt für Schritt: Thunderbit für Custom Data Scraping nutzen
Gehen wir einen realen Workflow für maßgeschneiderte Extraktion mit Thunderbit durch. Ich verwende ein Produktkatalog-Beispiel, aber die Schritte sind ähnlich für Leads, Bewertungen oder alles andere.
Schritt 1: Thunderbit installieren
Öffnen Sie die und fügen Sie sie Ihrem Browser hinzu. Registrieren Sie sich für ein kostenloses Konto — für den Gratis-Tarif ist keine Kreditkarte erforderlich.
Schritt 2: Ihre Zielwebsite öffnen
Navigieren Sie zu der Seite, die Sie scrapen möchten (z. B. eine Kategorieseite mit Produktlisten).
Schritt 3: Thunderbit starten und „KI-Felder vorschlagen“ nutzen
Klicken Sie auf das Thunderbit-Symbol. Drücken Sie auf „KI-Felder vorschlagen“ — die KI von Thunderbit scannt die Seite und schlägt Spalten wie „Produktname“, „Preis“, „Bild-URL“ usw. vor. Sie können Felder bei Bedarf umbenennen, hinzufügen oder entfernen.
Schritt 4: Mit KI-Eingabeaufforderungen für Felder anpassen
Sie möchten etwas Bestimmtes extrahieren? Für jedes Feld können Sie eine eigene Anweisung hinzufügen — etwa „extrahiere das Datum im Format JJJJ-MM-TT“ oder „übersetze die Beschreibung ins Spanische“. Thunderbits KI wendet Ihre Regel während der Extraktion an.
Schritt 5: Pagination oder Unterseiten-Scraping aktivieren (falls nötig)
Wenn sich Ihre Daten über mehrere Seiten erstrecken, aktivieren Sie Pagination. Wenn Sie Details von Unterseiten benötigen (z. B. Produktdetailseiten), nutzen Sie das Unterseiten-Scraping — Thunderbit besucht dann automatisch jeden Link und zieht zusätzliche Informationen in Ihre Tabelle.
Schritt 6: Auf „Scrape“ klicken und zusehen, wie die Daten fließen
Thunderbit extrahiert Ihre Daten und übernimmt Navigation und Formatierung automatisch. Währenddessen sehen Sie eine Vorschau-Tabelle.
Schritt 7: Ihre Daten exportieren
Sobald Sie mit dem Ergebnis zufrieden sind, exportieren Sie direkt nach . Sie können die Daten auch als CSV oder JSON herunterladen.
Das war’s. Kein Code, keine Vorlagen (außer Sie möchten welche) und keine „Warum funktioniert das nicht?“-Momente. Mehr Details finden Sie in .
Thunderbit mit anderen Datenerfassungsdiensten vergleichen
Werden wir kurz nerdig. Wie schlägt sich Thunderbit im Vergleich zu anderen Datenerfassungsdiensten wie Azure AI Document Intelligence oder klassischen Scrapern?
| Funktion / Kriterium | Thunderbit | Azure AI Document Intelligence | Klassische Scraper (z. B. Octoparse, Scrapy) |
|---|---|---|---|
| Benutzerfreundlichkeit | No-Code, KI-gestützt, Einrichtung in 2 Klicks | Entwicklerorientiert, API-basiert | Steile Lernkurve, oft mit Code |
| Custom Extraction | Natürliche Sprachprompts, KI für Felder | Eigene ML-Modelle für Dokumente | Manuelle Konfiguration, Selektoren, Skripte |
| Webseiten werden unterstützt | Ja (HTML, dynamisch, Unterseiten) | Nein (fokussiert auf Dokumente/PDFs) | Ja, aber Probleme mit dynamischen Seiten |
| Dokumente/PDFs werden unterstützt | Ja (über Browser-/PDF-Modus) | Ja (OCR, ML) | Manchmal, aber begrenzt |
| Anpassungsfähigkeit | KI passt sich Layout-Änderungen an | ML passt sich neuen Dokumenten an | Bricht bei Seitenänderungen, braucht Updates |
| Planung | Integriert, per natürlicher Sprache | Über API, benötigt Integration | Manchmal, aber komplex |
| Exportoptionen | Sheets, Excel, Airtable, Notion, CSV, JSON | API/JSON, braucht Entwicklerintegration | CSV, Excel, DB, je nach Tool unterschiedlich |
| Support | Modernes SaaS, reaktionsschnell | Enterprise, formeller Support | Community oder Anbieter, je nach Lösung |
| Preisgestaltung | Kostenloser Tarif, nutzungsbasierte Credits | Nutzungsbasiert, Fokus auf Enterprise | Kostenlos (Open Source) oder Monatspläne |
Thunderbits Stärke liegt in der Web-Datenerfassung für Business-Anwender, die Leistung ohne Schmerzen möchten. Azure ist hervorragend für Dokumentenverarbeitung in großem Maßstab, aber nicht fürs Crawlen von Websites. Klassische Scraper sind in den richtigen Händen stark, brauchen aber technisches Know-how und ständige Pflege.
Für einen tieferen Vergleich siehe .
So wählen Sie den richtigen Custom-Data-Extraction-Dienst für Ihre Anforderungen aus
Einen Datenerfassungsdienst auszuwählen, geht nicht nur um Funktionen — sondern darum, ob er zu Ihnen passt. Diese Checkliste hilft Ihnen bei der Entscheidung:
- Datenqualität & Zuverlässigkeit: Liefert das Tool genaue, saubere und vollständige Daten? Können Sie es auf Ihren Zielseiten testen?
- Flexibilität & Anpassung: Kommt es mit Ihren spezifischen Websites, dynamischen Inhalten, Logins oder Unterseiten zurecht? Können Sie eigene Felder oder Transformationen definieren?
- Compliance & Ethik: Hält es rechtliche und ethische Vorgaben ein? Respektiert es Datenschutzgesetze und die Nutzungsbedingungen der Seiten?
- Skalierbarkeit & Leistung: Schafft es Ihr Datenvolumen und Ihre Frequenz? Bietet es Cloud-Scraping oder parallele Verarbeitung?
- Integration & Workflow: Können Sie Daten in Ihre Tools exportieren (Sheets, Excel, CRM usw.)? Unterstützt es Planung oder Automatisierung?
- Support & Dokumentation: Gibt es reaktionsschnellen Support und klare Dokumentation? Gibt es Tutorials oder eine Wissensdatenbank?
- Sicherheit: Werden Ihre Daten sicher verarbeitet? Sind Login-Daten verschlüsselt? Gibt es Compliance-Zertifizierungen?
- Kosten: Ist die Preisstruktur transparent und für Ihre Bedürfnisse wirtschaftlich? Gibt es versteckte Gebühren oder Bezahlschranken?
Testen Sie jeden Kandidaten in der Praxis. Scrapen Sie eine echte Website, exportieren Sie die Daten und prüfen Sie, wie gut das Tool in Ihren Workflow passt. Weitere Tipps finden Sie in .
Custom Data Scraping in Ihre Geschäftsabläufe integrieren
Daten zu extrahieren ist nur die halbe Miete — der eigentliche Wert entsteht, wenn daraus ein Teil Ihrer täglichen Abläufe wird. So binden Sie Custom Data Extraction in Ihr Unternehmen ein:
- Wiederkehrende Aufgaben automatisieren: Nutzen Sie geplantes Scraping, um Ihre Daten aktuell zu halten — tägliche Preischecks, wöchentliche Lead-Updates usw.
- Daten in Ihre Tools einspeisen: Exportieren Sie direkt nach . Verwenden Sie Zapier, Make oder n8n, um weiter zu automatisieren (z. B. neue Leads in Ihr CRM zu übertragen).
- Benachrichtigungen einrichten: Integrieren Sie Slack oder E-Mail, um über wichtige Änderungen informiert zu werden — etwa wenn ein Wettbewerber Preise senkt oder ein neues Produkt startet.
- In der Cloud zusammenarbeiten: Verwenden Sie geteilte Datenbanken (Airtable, Notion), damit gescrapte Daten teamübergreifend verfügbar sind.
- End-to-End automatisieren: Kombinieren Sie Scraping mit BI-Tools (Tableau, Power BI) für Live-Dashboards oder lösen Sie Aktionen aus (z. B. Repricing) auf Basis der gescrapten Daten.
Zur Inspiration sehen Sie sich an.
Best Practices, um den Wert von Custom Data Extraction Services zu maximieren
Sie möchten das Maximum aus Ihren Custom-Extraction-Bemühungen herausholen? Das habe ich gelernt — manchmal auf die harte Tour:
- Klare Ziele definieren: Wissen Sie genau, welche Daten Sie brauchen und warum. Scrapen Sie nicht nur, weil Sie es können — scrapen Sie mit Ziel.
- Klein anfangen, oft testen: Starten Sie mit kleinen Piloten, prüfen Sie die Daten und skalieren Sie erst dann hoch, wenn Sie sicher sind.
- Datenqualität überwachen: Prüfen Sie Ergebnisse regelmäßig stichprobenartig. Richten Sie Validierungsregeln oder Alarme für Ausreißer ein.
- Frequenz optimieren: Scrapen Sie so oft wie nötig, aber nicht öfter. Zu viel Scraping kann zu Blockaden führen (und verärgert Ihr IT-Team).
- Ethisch und regelkonform bleiben: Beachten Sie Seitenregeln, Datenschutzgesetze und ethische Leitlinien. Scrapen Sie keine sensiblen oder gesperrten Daten.
- Feld-Prompts nutzen: Verwenden Sie KI-Prompts, um Daten während der Extraktion zu bereinigen, zu formatieren oder anzureichern.
- Daten schützen: Behandeln Sie Zugangsdaten und gescrapte Daten sorgfältig — mit Verschlüsselung und Zugriffskontrollen.
- Prozess dokumentieren: Halten Sie fest, was Sie scrapen, von wo und wie oft. Das spart später viel Ärger.
- Iterieren und verbessern: Betrachten Sie Custom Extraction als einen sich entwickelnden Prozess. Verfeinern Sie Ihren Ansatz, wenn sich Anforderungen ändern.
Mehr zu Best Practices finden Sie in .
Fazit & wichtigste Erkenntnisse: Heben Sie Ihre Datenstrategie mit Custom Extraction auf das nächste Level
Maßgeschneiderte Datenerfassung und Datenscraping-Dienste sind nicht nur etwas für Daten-Nerds — sie sind Must-have-Tools für jedes Unternehmen, das schnell sein, wettbewerbsfähig bleiben und klügere Entscheidungen treffen will. Die Zeiten von manuellem Copy-Paste und fragilen Skripten sind vorbei. Mit KI-gestützten Tools wie kann heute jeder Custom Extraction meistern — ganz ohne Programmierung.
Das sollten Sie mitnehmen:
- Custom Extraction = relevante Extraktion. Holen Sie sich die richtigen Daten, nicht nur mehr Daten.
- Der Business-Nutzen ist belegt. Von Sales über Operations bis Marktforschung liefert Custom Scraping echten ROI.
- Benutzerfreundlichkeit ist da. Tools wie Thunderbit demokratisieren Datenerfassung für alle.
- Integration ist alles. Machen Sie gescrapte Daten zu einem Teil Ihres täglichen Workflows, nicht zu einem Silo.
- Wählen Sie mit Bedacht. Stimmen Sie das Tool auf Ihre Anforderungen ab — testen, vergleichen und iterieren Sie.
- Best Practices zahlen sich aus. Klare Ziele, Qualitätschecks und ethische Standards halten Ihre Datenstrategie stark.
Bereit, Ihr Datenspiel auf das nächste Level zu bringen? und einen Custom Scrape an einem echten Geschäftsproblem ausprobieren. Oder, wenn Sie noch tiefer einsteigen möchten, schauen Sie im vorbei — dort finden Sie Deep Dives, Tutorials und das Neueste rund um KI-gestützte Datenerfassung.
Das Web ist eine Goldgrube an Erkenntnissen — Custom Extraction ist Ihr Pickel. Viel Spaß beim Scrapen!
FAQs
1. Was ist Custom Data Extraction, und wie unterscheidet sie sich vom Standard-Scraping?
Custom Data Extraction bedeutet, Ihr Scraping so anzupassen, dass genau die Daten extrahiert werden, die Sie brauchen — in dem Format, das Sie möchten — von jeder Website, selbst wenn sie komplex oder dynamisch ist. Im Gegensatz zu Standard-Tools, die alles Mögliche einsammeln, passt sich Custom Extraction an Ihre Geschäftsanforderungen und sich ändernde Seitenlayouts an.
2. Wer profitiert am meisten von Custom Data Extraction Services?
Vertriebsteams (für Leads), Marketing (für Wettbewerbsbeobachtung), Operations (für Automatisierung), Produktmanager (für Katalog-Updates) und Marktforscher (für Intelligence) erzielen mit Custom Extraction große Gewinne — besonders dann, wenn Standard-Tools an ihre Grenzen stoßen.
3. Wie macht Thunderbit Custom Extraction einfacher?
Thunderbit nutzt KI, um Felder vorzuschlagen, komplexe Navigation zu bewältigen (Pagination, Unterseiten) und Ihnen zu erlauben, in natürlicher Sprache zu beschreiben, was Sie wollen. Kein Code, keine Vorlagen (außer Sie möchten welche) und sofortiger Export in Ihre Lieblingstools.
4. Worauf sollte ich bei der Auswahl eines Datenerfassungsdienstes achten?
Achten Sie auf Datenqualität, Flexibilität, Compliance, Skalierbarkeit, Integrationsoptionen, Support, Sicherheit und Kosten. Testen Sie jeden Dienst an Ihren echten Anforderungen, bevor Sie sich festlegen.
5. Wie kann ich Custom Data Scraping in meine Geschäftsabläufe integrieren?
Automatisieren Sie wiederkehrende Aufgaben, exportieren Sie Daten nach Sheets/Excel/Notion, richten Sie Benachrichtigungen ein und nutzen Sie Workflow-Tools wie Zapier oder n8n. Das Ziel: Webdaten sollen ein lebendiger Teil Ihres täglichen Betriebs werden, nicht nur ein Einmalprojekt.
Bereit zu sehen, was Custom Extraction für Ihr Unternehmen leisten kann? und beginnen, Web-Chaos in geschäftliche Klarheit zu verwandeln.
Mehr erfahren