
Wer schon mal versucht hat, Daten von einer Website zu holen, die Inhalte erst beim Scrollen lädt, Preise hinter einem Login versteckt oder ständig ihr Layout ändert, weiß, wie nervig das sein kann. Mit klassischen statischen Web-Scrapern kommt man da heute einfach nicht mehr weit. Tatsächlich nutzen inzwischen über Web-Scraping für alternative Daten, und automatisieren die Konkurrenzpreis-Überwachung. Das Problem: Viele dieser Daten liegen auf dynamischen Seiten, die per JavaScript geladen werden und sich hinter Nutzeraktionen verstecken. Genau hier kommen Headless-Browser-Automatisierung und Tools wie Puppeteer ins Spiel.
Ich entwickle seit Jahren Automatisierungs- und KI-Tools und habe dabei schon viele Webseiten für Sales- und Operationsteams mit Web-Scraping bearbeitet. Dabei habe ich erlebt, wie Puppeteer Daten zugänglich macht, an die klassische Web-Scraper nicht rankommen. Aber ich weiß auch, dass der Programmieraufwand für viele Unternehmen eine echte Hürde ist. In diesem Guide zeige ich dir, was ein Puppeteer-Scraper ist, wie du ihn fürs Web-Scraping nutzt und wann vielleicht eine noch einfachere Lösung wie , unser KI-basierter No-Code-Web-Scraper, die bessere Wahl ist.
Was ist ein Puppeteer Scraper? Ein schneller Überblick
 Fangen wir mit den Basics an. ist eine Open-Source-Bibliothek von Google für Node.js, mit der du einen Headless-Chrome- oder Chromium-Browser per JavaScript steuern kannst. Stell dir vor, es ist wie ein Roboter, der Webseiten öffnet, Buttons klickt, Formulare ausfüllt, scrollt und – am wichtigsten – Daten extrahiert, ohne dass du irgendwas auf dem Bildschirm siehst.
Fangen wir mit den Basics an. ist eine Open-Source-Bibliothek von Google für Node.js, mit der du einen Headless-Chrome- oder Chromium-Browser per JavaScript steuern kannst. Stell dir vor, es ist wie ein Roboter, der Webseiten öffnet, Buttons klickt, Formulare ausfüllt, scrollt und – am wichtigsten – Daten extrahiert, ohne dass du irgendwas auf dem Bildschirm siehst.
Was macht Puppeteer besonders?
- Es kann dynamische Inhalte rendern – also warten, bis JavaScript geladen ist, wie ein echter User.
- Es kann Nutzeraktionen nachahmen: Klicken, Tippen, Scrollen und sogar Pop-ups bedienen.
- Perfekt für Seiten, auf denen Daten erst nach Interaktion erscheinen, z. B. Produktlisten, Social Feeds oder Dashboards.
Wie schlägt es sich im Vergleich zu anderen Tools?
- Selenium: Der Klassiker der Browser-Automatisierung. Funktioniert mit vielen Browsern und Sprachen, ist aber etwas schwerfälliger und wirkt inzwischen etwas altbacken. Für Cross-Browser-Tests super, aber Puppeteer ist für Chrome/Node.js-Projekte oft flotter.
- Thunderbit: Hier wird’s spannend. Thunderbit ist ein No-Code, KI-gestützter Web-Scraper, der direkt im Browser läuft. Anstatt Skripte zu schreiben, klickst du einfach auf „KI-Felder vorschlagen“ und die KI erkennt automatisch, was extrahiert werden soll. Ideal für alle, die Ergebnisse ohne Programmierung wollen (mehr dazu gleich).
Kurz gesagt: Puppeteer = maximale Kontrolle (wenn du coden willst). Thunderbit = maximaler Komfort (wenn du keine Lust auf Code hast).
Warum Puppeteer Web Scraping für Unternehmen wichtig ist
Fakt ist: Web-Scraping ist längst nicht mehr nur was für Hacker oder Data Scientists. Vertrieb, Operations, Marketing und sogar Immobilien-Teams nutzen Webdaten, um sich Vorteile zu verschaffen. Und weil so viele geschäftskritische Infos hinter dynamischen Seiten versteckt sind, ist Puppeteer oft der Schlüssel, um an diese Daten zu kommen.
Hier ein paar Praxisbeispiele:
| Anwendungsfall | Wer profitiert | Nutzen / ROI |
|---|---|---|
| Lead-Generierung | Vertrieb, Business Dev | Automatisierte Erstellung von Kontaktlisten; spart 8+ Stunden/Woche pro Mitarbeiter (Case Study) |
| Preisüberwachung | E-Commerce, Produktteams | Echtzeit-Überwachung der Konkurrenz; ein Unternehmen sparte $3,8 Mio/Jahr (Quelle) |
| Marktforschung | Marketing, Strategie, Finanzen | 67 % der Investmentberater nutzen Webdaten; bis zu 890 % ROI möglich (Quelle) |
| Immobilien-Aggregation | Makler, Analysten | Über 50 Immobilienseiten in wenigen Minuten scrapen (Quelle) |
| Compliance-Überwachung | Operations, Recht | Automatisiertes Monitoring; ein Versicherer verhinderte $50 Mio Strafen (Quelle) |
Nicht zu vergessen: verbringen ein Viertel ihrer Arbeitszeit mit wiederkehrenden Aufgaben wie Datenerfassung. Web-Scraping zu automatisieren ist also kein „Nice-to-have“, sondern ein echter Wettbewerbsvorteil.
Einstieg: So richtest du deinen Puppeteer Scraper ein
Bereit, loszulegen? So bringst du Puppeteer in weniger als 10 Minuten zum Laufen (wenn du mit JavaScript vertraut bist):
1. Node.js installieren
Puppeteer läuft auf Node.js. Hol dir die aktuelle LTS-Version von .
2. Neues Projektverzeichnis anlegen
Öffne dein Terminal und gib ein:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteer installieren
1npm install puppeteerDadurch wird auch eine passende Chromium-Version (ca. 100 MB) heruntergeladen.
4. Erstes Skript erstellen
Lege eine Datei namens scrape.js an:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Führe das Skript aus mit:
1node scrape.jsWenn du „Page title: Example Domain“ siehst, hast du Chrome erfolgreich automatisiert!
Dein erstes Puppeteer Web Scraping Skript schreiben
Jetzt wird’s praktisch. Angenommen, du willst Zitate von extrahieren (eine Demo-Seite für Web-Scraper).
Schritt 1: Zur Seite navigieren
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Schritt 2: Daten extrahieren
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Schritt 3: Paginierung verarbeiten
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Zitate wie oben extrahieren
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Schritt 4: Als JSON speichern
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Fertig – ein einfacher Puppeteer-Scraper, der navigiert, extrahiert, paginiert und speichert.
Fortgeschrittene Puppeteer Scraper-Techniken: Dynamische Inhalte meistern
Die meisten echten Websites sind komplexer als eine statische Liste. So gehst du mit Herausforderungen um:
1. Auf dynamische Elemente warten
1await page.waitForSelector('.product-list-item');So stellst du sicher, dass die gewünschten Inhalte geladen sind, bevor du sie abgreifst.
2. Nutzeraktionen simulieren
- Button klicken:
await page.click('#load-more'); - In ein Feld tippen:
await page.type('#search', 'laptop'); - Für unendliches Scrollen:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Logins automatisieren
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Mit AJAX-Daten umgehen Manchmal sind die Daten nicht im DOM, sondern kommen per API. Du kannst Netzwerkantworten abfangen mit:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Daten verarbeiten
5 }
6});Praxisbeispiel: Produktdaten von einer E-Commerce-Seite scrapen
Setzen wir alles zusammen. Du willst Produktnamen, Preise und Bilder von einer (Demo-)E-Commerce-Seite nach dem Login extrahieren.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Schritt 1: Einloggen
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Schritt 2: Zur Kategorie-Seite gehen
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Schritt 3: Produkte extrahieren
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Schritt 4: Als JSON speichern
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Dieses Skript loggt sich ein, navigiert, extrahiert und speichert – alles automatisch. Für komplexere Anforderungen kannst du z. B. Paginierung oder Detailseiten ergänzen.
Thunderbit: Puppeteer Scraper mit KI noch einfacher machen
Falls du jetzt denkst: „Klingt cool, aber ich will nicht jedes Mal Code schreiben, nur um ein paar Daten zu bekommen“, bist du nicht allein. Genau deshalb haben wir entwickelt.
Was macht Thunderbit anders?
- Kein Code nötig: Einfach die installieren, Seite öffnen und auf „KI-Felder vorschlagen“ klicken.
- KI-gestützte Felderkennung: Thunderbit liest die Seite und schlägt passende Spalten wie „Produktname“, „Preis“, „Bild“ usw. vor.
- Dynamische Inhalte meistern: Unendliches Scrollen, Pop-ups, Unterseiten? Thunderbits KI klickt sich durch Paginierung oder besucht sogar jede Produktdetailseite, um deine Daten zu vervollständigen.
- Sofortiger Export: Mit einem Klick direkt nach Excel, Google Sheets, Notion oder Airtable exportieren – ohne Zusatzkosten.
- Vorlagen für beliebte Seiten: Amazon, Zillow oder LinkedIn scrapen? Thunderbit bietet fertige Templates – keine Einrichtung nötig.
- Cloud- oder Browser-Scraping: Für große Projekte kann Thunderbit bis zu 50 Seiten gleichzeitig in der Cloud scrapen.
Ich habe gesehen, wie Nutzer in weniger als fünf Minuten von „Wie komme ich an diese Daten?“ zu „Hier ist meine Tabelle“ kommen. Und das Beste: Keine Angst mehr vor kaputten Skripten, wenn sich die Website ändert – Thunderbits KI passt sich automatisch an.
Puppeteer vs. Thunderbit: Das richtige Web Scraping Tool wählen
Wie entscheidest du dich am besten? So wähle ich für Teams:
| Kriterium | Puppeteer (Code) | Thunderbit (No-Code, KI) |
|---|---|---|
| Benutzerfreundlichkeit | Erfordert JavaScript- und DOM-Kenntnisse | Point-and-Click, KI schlägt Felder vor |
| Setup-Geschwindigkeit | Stunden bis Tage bei komplexen Aufgaben | Minuten – einfach installieren und loslegen |
| Kontrolle/Flexibilität | Maximal: beliebige Logik, Integration in andere Anwendungen | Hoch für Standardfälle; weniger geeignet für sehr individuelle Workflows |
| Dynamische Inhalte | Manuelles Skripting für Wartezeiten, Klicks, Scrolls | KI übernimmt dynamische Inhalte, Paginierung und Unterseiten automatisch |
| Wartung | Du pflegst die Skripte selbst – Anpassung bei Website-Änderungen | KI passt sich Layout-Änderungen an; weniger Wartungsaufwand |
| Datenexport | Export-Logik selbst schreiben | Ein-Klick-Export zu Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ideal für | Entwickler, individuelle oder groß angelegte Scrapes | Business-User, schnelle Projekte, nicht-technische Teams |
| Kosten | Kostenlos (außer Zeit und ggf. Infrastruktur) | Kostenloser Einstieg; kostenpflichtige Pläne nach Credits (siehe Thunderbit Preise) |
Fazit:
- Nutze Puppeteer, wenn du volle Kontrolle brauchst, Entwicklerressourcen hast oder Scraping in eine größere Anwendung integrieren willst.
- Nutze Thunderbit, wenn du schnelle Ergebnisse ohne Programmierung willst oder nicht-technische Kollegen empowern möchtest.
Viele Teams setzen übrigens auf beide: Thunderbit für schnelle Ergebnisse und Prototypen, Puppeteer für tiefe Integrationen oder Spezialfälle.
Schritt-für-Schritt-Checkliste: Erfolgreiches Puppeteer Web Scraping Projekt
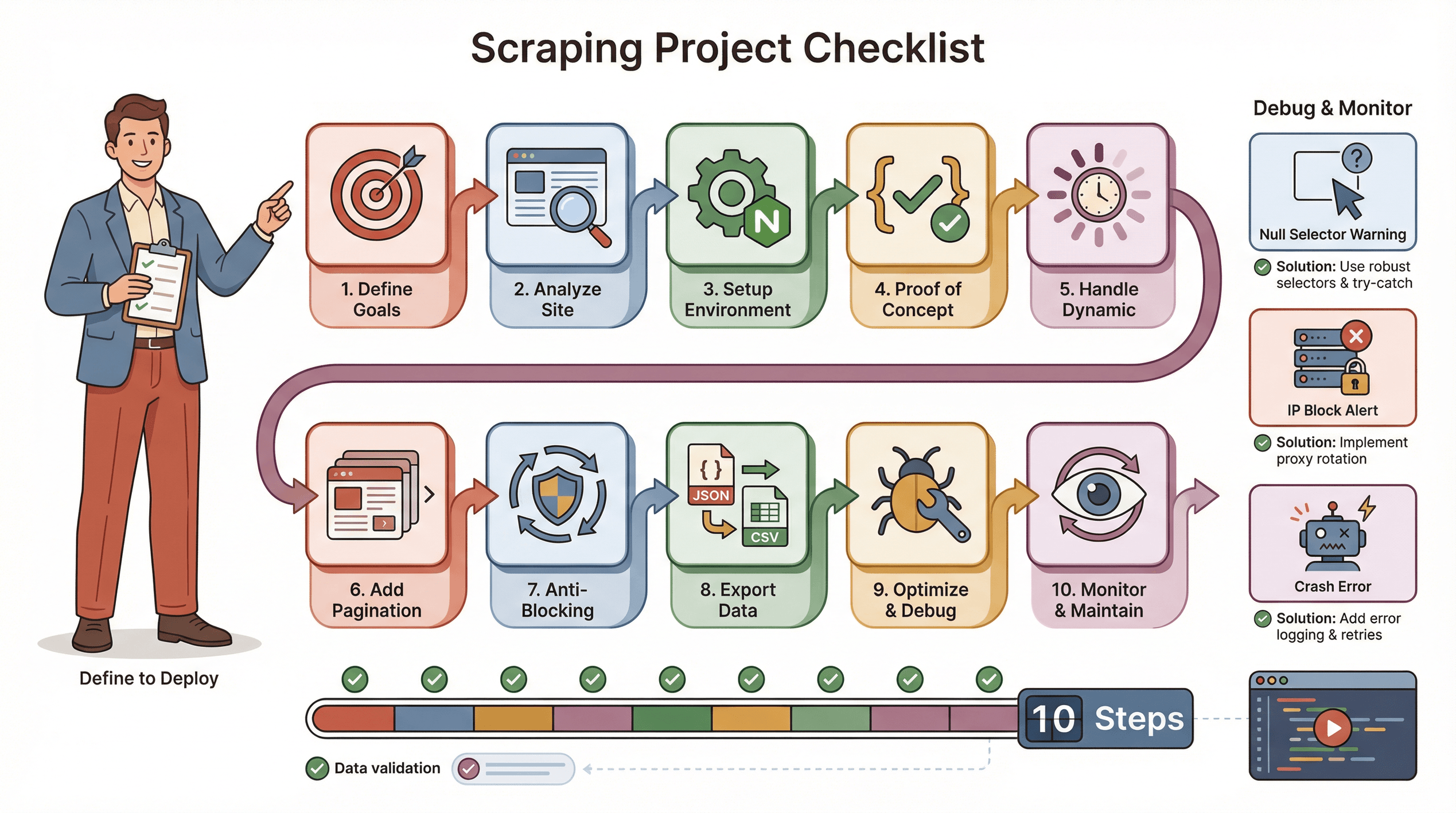 Hier meine bewährte Checkliste für ein reibungsloses Puppeteer-Scraping-Projekt:
Hier meine bewährte Checkliste für ein reibungsloses Puppeteer-Scraping-Projekt:
- Ziele definieren: Welche Daten brauchst du? Wo sind sie zu finden?
- Website analysieren: Ist sie dynamisch? Ist ein Login nötig? Gibt es Anti-Bot-Maßnahmen?
- Umgebung einrichten: Node.js, Puppeteer und ggf. Hilfsbibliotheken installieren.
- Proof-of-Concept schreiben: Mit einer Seite starten, die richtigen Selektoren finden.
- Dynamische Inhalte abdecken:
waitForSelectornutzen, Klicks/Scrolls simulieren. - Paginierung/Schleifen ergänzen: Alle Seiten scrapen, nicht nur eine.
- Anti-Blocking-Taktiken umsetzen: Zufällige Pausen, echten User-Agent setzen, ggf. Proxys nutzen.
- Daten exportieren und prüfen: Als JSON/CSV speichern, auf Vollständigkeit kontrollieren.
- Optimieren und Fehler abfangen: try/catch, Fortschritt loggen, fehlende Daten abfangen.
- Überwachen und pflegen: Websites ändern sich – Skripte regelmäßig anpassen.
Tipps zur Fehlerbehebung:
- Wenn Selektoren null zurückgeben, HTML prüfen und Wartezeiten einbauen.
- Bei Blockaden: Tempo drosseln, IPs rotieren, Stealth-Plugins nutzen.
- Bei Abstürzen: Auf Speicherlecks oder unbehandelte Fehler achten.
Fazit & wichtigste Erkenntnisse
Web-Scraping ist für datengetriebene Teams heute unverzichtbar. Puppeteer macht es möglich, auch komplexe, JavaScript-lastige Seiten zu scrapen – braucht aber Programmierkenntnisse und Pflege. Für alle, die ohne Code direkt an die Daten wollen, bietet Thunderbit eine KI-basierte, No-Code-Alternative, die schnell, flexibel und überraschend leistungsfähig ist.
Meine Empfehlung:
- Wer technisch ist und individuelle Anpassungen braucht, startet mit Puppeteer.
- Wer Wert auf Geschwindigkeit, Einfachheit und wenig Wartung legt, sollte ausprobieren (die ist ein super Einstieg).
- Für die meisten Teams deckt die Kombination aus beiden Tools 99 % aller Webdaten-Anforderungen ab.
Du willst mehr solcher Anleitungen? Im findest du Tutorials, Vergleiche und die neuesten Trends rund um KI-basiertes Web-Scraping.
FAQs
1. Was ist ein Puppeteer Scraper und wofür wird er beim Web Scraping eingesetzt?
Puppeteer ist eine Node.js-Bibliothek, mit der du einen Headless-Chrome-Browser per JavaScript steuern kannst. Sie wird fürs Web-Scraping genutzt, weil sie dynamische Inhalte laden, Nutzeraktionen simulieren und Daten von Seiten extrahieren kann, die klassische Web-Scraper nicht erreichen.
2. Wie unterscheidet sich Puppeteer von Selenium und Thunderbit?
Selenium funktioniert mit mehreren Browsern und Sprachen, ist aber schwerfälliger. Puppeteer ist für Chrome/Node.js optimiert und bei vielen Scraping-Aufgaben schneller. Thunderbit ist dagegen ein No-Code, KI-gestütztes Tool, mit dem auch Nicht-Techniker Daten mit wenigen Klicks scrapen können.
3. Was sind die wichtigsten geschäftlichen Vorteile von Puppeteer Web Scraping?
Automatisierte Datenerfassung spart Zeit, reduziert Fehler und ermöglicht Echtzeit-Einblicke für Vertrieb, Marketing, Operations und mehr. Anwendungsfälle reichen von Lead-Generierung über Preisüberwachung bis zur Marktforschung.
4. Was sind die größten Herausforderungen beim Puppeteer Scraping?
Die größten Hürden sind der Umgang mit dynamischen Inhalten, das Umgehen von Anti-Bot-Schutz und die Wartung der Skripte bei Website-Änderungen. Du musst Code schreiben, um Wartezeiten, Interaktionen und Fehler zu steuern.
5. Wann sollte ich Thunderbit statt Puppeteer nutzen?
Thunderbit ist ideal, wenn du auf Programmierung verzichten, schnelle Ergebnisse erzielen oder nicht-technische Kollegen empowern möchtest. Perfekt für Standard-Scraping, schnelle Projekte oder wenn du Daten unkompliziert nach Excel oder Google Sheets exportieren willst.
Bereit für smarteres Scraping? oder weitere Anleitungen im entdecken. Viel Erfolg beim Scrapen!
Mehr erfahren