
Wenn Sie schon einmal versucht haben, Daten von einer Website zu ziehen, die Inhalte erst beim Scrollen lädt, Preise hinter einem Login versteckt oder ihr Layout gefühlt jede zweite Woche ändert, kennen Sie das Problem. Statische Scraper reichen heute einfach nicht mehr aus. Tatsächlich setzen inzwischen über auf Web Scraping für alternative Daten, und automatisieren die Preisüberwachung von Wettbewerbern. Der Haken dabei: Ein großer Teil dieser Daten steckt auf dynamischen Websites, wird per JavaScript geladen und ist hinter Nutzerinteraktionen verborgen. Genau hier kommen Headless-Browser-Automatisierung und Tools wie Puppeteer ins Spiel.
Ich beschäftige mich seit Jahren mit Automatisierung und KI-Tools – und ja, ich habe für Sales- und Operations-Teams auch meinen fairen Anteil an Websites gescraped. Dabei habe ich aus erster Hand gesehen, wie Puppeteer Daten erschließen kann, die traditionelle Scraper übersehen. Ich habe aber auch erlebt, wie schnell der Programmieraufwand für Business-Anwender zum Dealbreaker wird. Deshalb zeige ich Ihnen in diesem Leitfaden genau, was ein Puppeteer-Scraper ist, wie Sie ihn für Web Scraping einsetzen und wann Sie vielleicht doch zu etwas noch Einfacherem greifen sollten – etwa zu , unserem KI-gestützten Web-Scraper ohne Programmierung.
Was ist ein Puppeteer-Scraper? Ein kurzer Überblick
 Fangen wir mit den Grundlagen an. ist eine Open-Source-Node.js-Bibliothek von Google, mit der Sie einen Headless-Chrome- oder Chromium-Browser per JavaScript steuern können. Einfach gesagt: Es ist, als hätten Sie einen Roboter, der Webseiten öffnen, Buttons klicken, Formulare ausfüllen, scrollen und – vor allem – Daten extrahieren kann, ohne dass Sie dabei überhaupt etwas auf dem Bildschirm sehen.
Fangen wir mit den Grundlagen an. ist eine Open-Source-Node.js-Bibliothek von Google, mit der Sie einen Headless-Chrome- oder Chromium-Browser per JavaScript steuern können. Einfach gesagt: Es ist, als hätten Sie einen Roboter, der Webseiten öffnen, Buttons klicken, Formulare ausfüllen, scrollen und – vor allem – Daten extrahieren kann, ohne dass Sie dabei überhaupt etwas auf dem Bildschirm sehen.
Was macht Puppeteer so besonders?
- Es kann dynamische Inhalte rendern – das heißt, es wartet darauf, dass JavaScript geladen wird, genau wie ein echter Nutzer.
- Es kann Nutzeraktionen simulieren: klicken, tippen, scrollen und sogar Pop-ups behandeln.
- Es eignet sich perfekt für Websites, auf denen Daten erst nach einer Interaktion erscheinen, etwa bei E-Commerce-Listings, Social Feeds oder Dashboards.
Wie schlägt es sich im Vergleich zu anderen Tools?
- Selenium: Der Klassiker der Browser-Automatisierung. Funktioniert mit vielen Browsern und Sprachen, ist aber umfangreicher und etwas altmodischer. Für Cross-Browser-Tests ist es stark, für Chrome-/Node.js-Projekte ist Puppeteer oft reaktionsschneller.
- Thunderbit: Hier wird es für mich spannend. Thunderbit ist ein KI-gestützter Web-Scraper ohne Programmierung, der direkt in Ihrem Browser arbeitet. Statt Skripte zu schreiben, klicken Sie einfach auf „KI-Felder vorschlagen“ und lassen die KI entscheiden, was extrahiert werden soll. Ideal für Business-Anwender, die Ergebnisse ohne Code wollen (mehr dazu später).
Kurz gesagt: Puppeteer = maximale Kontrolle (wenn Sie programmieren). Thunderbit = maximaler Komfort (wenn Sie nicht programmieren wollen).
Warum Puppeteer-Web-Scraping für Business-Anwender wichtig ist
Seien wir ehrlich: Web Scraping ist längst nicht mehr nur etwas für Hacker oder Data Scientists. Sales-, Operations-, Marketing- und sogar Immobilien-Teams nutzen Webdaten, um sich einen Vorsprung zu verschaffen. Und weil so viele geschäftskritische Informationen hinter dynamischen Websites verborgen sind, ist Puppeteer oft der Schlüssel, um sie zu erschließen.
Hier sind einige typische Anwendungsfälle aus der Praxis:
| Anwendungsfall | Wer profitiert | Auswirkung / ROI |
|---|---|---|
| Lead-Generierung | Vertrieb, Business Development | Automatisierter Aufbau von Prospect-Listen; spart pro Vertriebsmitarbeiter über 8 Stunden pro Woche (Fallstudie) |
| Preisüberwachung | E-Commerce, Produkt-Operations | Wettbewerber in Echtzeit verfolgen; ein Unternehmen sparte 3,8 Mio. USD pro Jahr (Quelle) |
| Marktforschung | Marketing, Strategie, Finanzen | 67 % der Anlageberater nutzen gescrapte Webdaten; in manchen Fällen bis zu 890 % ROI (Quelle) |
| Immobilien-Aggregation | Makler, Analysten | Über 50 Immobilienseiten in Minuten statt Stunden scrapen (Quelle) |
| Compliance-Tracking | Operations, Recht | Überwachung automatisieren; ein Versicherer vermied 50 Mio. USD an Strafzahlungen (Quelle) |
Und nicht zu vergessen: verbringen ein Viertel ihrer Woche mit repetitiven Aufgaben wie der Datenerfassung. Das mit Web Scraping zu automatisieren ist nicht nur nett, sondern ein echter Wettbewerbsvorteil.
Erste Schritte: So richten Sie Ihren Puppeteer-Scraper ein
Bereit, loszulegen? So bekommen Sie Puppeteer in unter 10 Minuten zum Laufen – vorausgesetzt, Sie kommen mit ein bisschen JavaScript zurecht:
1. Node.js installieren
Puppeteer läuft auf Node.js. Laden Sie die aktuelle LTS-Version von herunter.
2. Einen neuen Projektordner erstellen
Öffnen Sie Ihr Terminal und führen Sie aus:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteer installieren
1npm install puppeteerDabei wird auch eine kompatible Chromium-Version heruntergeladen (etwa 100 MB).
4. Ihr erstes Skript erstellen
Legen Sie eine Datei mit dem Namen scrape.js an:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Seitentitel:', title);
8 await browser.close();
9})();Starten Sie es mit:
1node scrape.jsWenn Sie „Seitentitel: Example Domain“ sehen, Glückwunsch – Sie haben gerade Chrome automatisiert!
Ihr erstes Puppeteer-Web-Scraping-Skript bauen
Jetzt wird es praktisch. Angenommen, Sie möchten Zitate von scrapen, einer Demo-Website für Scraper.
Schritt 1: Zur Seite navigieren
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Schritt 2: Daten extrahieren
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Schritt 3: Paginierung behandeln
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Zitate wie oben extrahieren
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Schritt 4: In JSON speichern
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Und schon haben Sie einen einfachen Puppeteer-Scraper, der navigiert, extrahiert, Seiten durchgeht und Daten speichert.
Fortgeschrittene Puppeteer-Scraper-Techniken: Dynamische Inhalte handhaben
Die meisten realen Websites sind nicht so simpel wie eine statische Liste. So gehen Sie mit den kniffligen Fällen um:
1. Auf dynamische Elemente warten
1await page.waitForSelector('.product-list-item');So stellen Sie sicher, dass die gewünschten Inhalte geladen sind, bevor Sie versuchen, sie abzurufen.
2. Nutzeraktionen simulieren
- Einen Button klicken:
await page.click('#load-more'); - In ein Feld tippen:
await page.type('#search', 'laptop'); - Für Infinite Scroll scrollen:
1// Hinweis: page.waitForTimeout wurde in Puppeteer v22 entfernt. Verwenden Sie stattdessen einfach ein Promise. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. Logins handhaben**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Mit per AJAX geladenen Daten umgehen Manchmal stehen die Daten nicht im DOM, sondern kommen über einen API-Call. Netzwerkantworten können Sie so abfangen:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Daten verarbeiten
5 }
6});Praxisbeispiel: Produktdaten von einer E-Commerce-Website scrapen
Setzen wir alles zusammen. Stellen Sie sich vor, Sie möchten nach dem Login Produktnamen, Preise und Bilder von einer (Demo-)E-Commerce-Website scrapen.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Schritt 1: Anmelden
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Schritt 2: Zur Kategorieseite gehen
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Schritt 3: Produkte extrahieren
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Schritt 4: In JSON speichern
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Dieses Skript meldet sich an, navigiert, scrapt und speichert – alles automatisch. Für anspruchsvollere Anforderungen können Sie Paginierungsschleifen ergänzen oder sogar in jedes Produkt klicken, um mehr Details zu erfassen.
Thunderbit: Puppeteer-Scraper mit KI einfacher machen
Wenn Sie bis hierhin mitgelesen haben und denken: „Klingt gut, aber ich möchte nicht jedes Mal Code schreiben, wenn ich einen neuen Datensatz brauche“, sind Sie nicht allein. Genau deshalb haben wir entwickelt.
Was macht Thunderbit anders?
- Kein Code erforderlich: Installieren Sie einfach die , öffnen Sie die Seite, die Sie scrapen möchten, und klicken Sie auf „KI-Felder vorschlagen“.
- KI-gestützte Felderkennung: Thunderbit liest die Seite und schlägt die besten Spalten vor – etwa „Produktname“, „Preis“, „Bild“ und so weiter.
- Beherrscht dynamische Inhalte: Infinite Scroll, Pop-ups und Unterseiten? Thun derbit-KI kommt damit zurecht, klickt sich durch Paginierung oder besucht sogar jede Produktdetailseite, um Ihre Daten anzureichern.
- Sofortiger Export: Senden Sie Ihre Daten mit einem Klick direkt an Excel, Google Sheets, Notion oder Airtable. Exporte kosten nichts extra.
- Vorlagen für beliebte Websites: Sie möchten Amazon, Zillow oder LinkedIn scrapen? Thunderbit hat sofort einsatzbereite Vorlagen – kein Setup nötig.
- Scraping in der Cloud oder im Browser: Für große Aufgaben kann Thunderbit in der Cloud bis zu 50 Seiten gleichzeitig scrapen.
Ich habe Nutzer erlebt, die in weniger als fünf Minuten von „Ich wünschte, ich könnte diese Daten bekommen“ zu „Hier ist meine Tabelle“ gekommen sind. Und das Beste? Kein Stress mehr wegen kaputter Skripte, wenn sich die Website ändert – Thunderbits KI passt sich spontan an.
Puppeteer vs. Thunderbit: Das richtige Web-Scraping-Tool wählen
Also, was sollten Sie einsetzen? So würde ich es für Teams einordnen:
| Faktor | Puppeteer (Code) | Thunderbit (No-Code, KI) |
|---|---|---|
| Benutzerfreundlichkeit | Erfordert JavaScript- und DOM-Kenntnisse | Klicken statt tippen, KI schlägt Felder vor |
| Einrichtungsgeschwindigkeit | Stunden bis Tage bei komplexen Aufgaben | Minuten – einfach installieren und loslegen |
| Kontrolle/Flexibilität | Maximal: beliebige Logik skripten, mit anderem Code integrieren | Hoch für Standardfälle; weniger geeignet für sehr individuelle Workflows |
| Dynamische Inhalte | Manuelles Skripten für Wartezeiten, Klicks und Scrollen | Integrierte KI verarbeitet dynamische Inhalte, Paginierung und Unterseiten automatisch |
| Wartung | Sie besitzen die Skripte – Updates bei Website-Änderungen selbst einbauen | KI passt sich Layout-Änderungen an; weniger Pflegeaufwand für Nutzer |
| Datenexport | Eigene Exportlogik schreiben | Export mit einem Klick nach Excel, Sheets, Notion, Airtable, CSV, JSON |
| Am besten geeignet für | Entwickler, stark individualisierte oder groß angelegte Scrapes | Business-Anwender, Projekte mit kurzer Laufzeit, nicht-technische Teams |
| Kosten | Kostenlos (abgesehen von Ihrer Zeit und ggf. Infrastruktur) | Kostenloser Plan verfügbar; kostenpflichtige Tarife nach Credits (siehe Thunderbit-Preise) |
Kurzfazit:
- Nutzen Sie Puppeteer, wenn Sie volle Kontrolle brauchen, über Programmierressourcen verfügen oder Scraping in eine größere App integrieren möchten.
- Nutzen Sie Thunderbit, wenn Sie schnell Ergebnisse wollen, nicht programmieren möchten oder nicht-technische Teammitglieder befähigen wollen.
Ehrlich gesagt habe ich Teams oft beides nutzen sehen: Thunderbit für schnelle Erfolge und Prototypen, Puppeteer für tiefe Integrationen oder Sonderfälle.
Schritt-für-Schritt-Checkliste: Ein erfolgreiches Puppeteer-Web-Scraping-Projekt durchführen
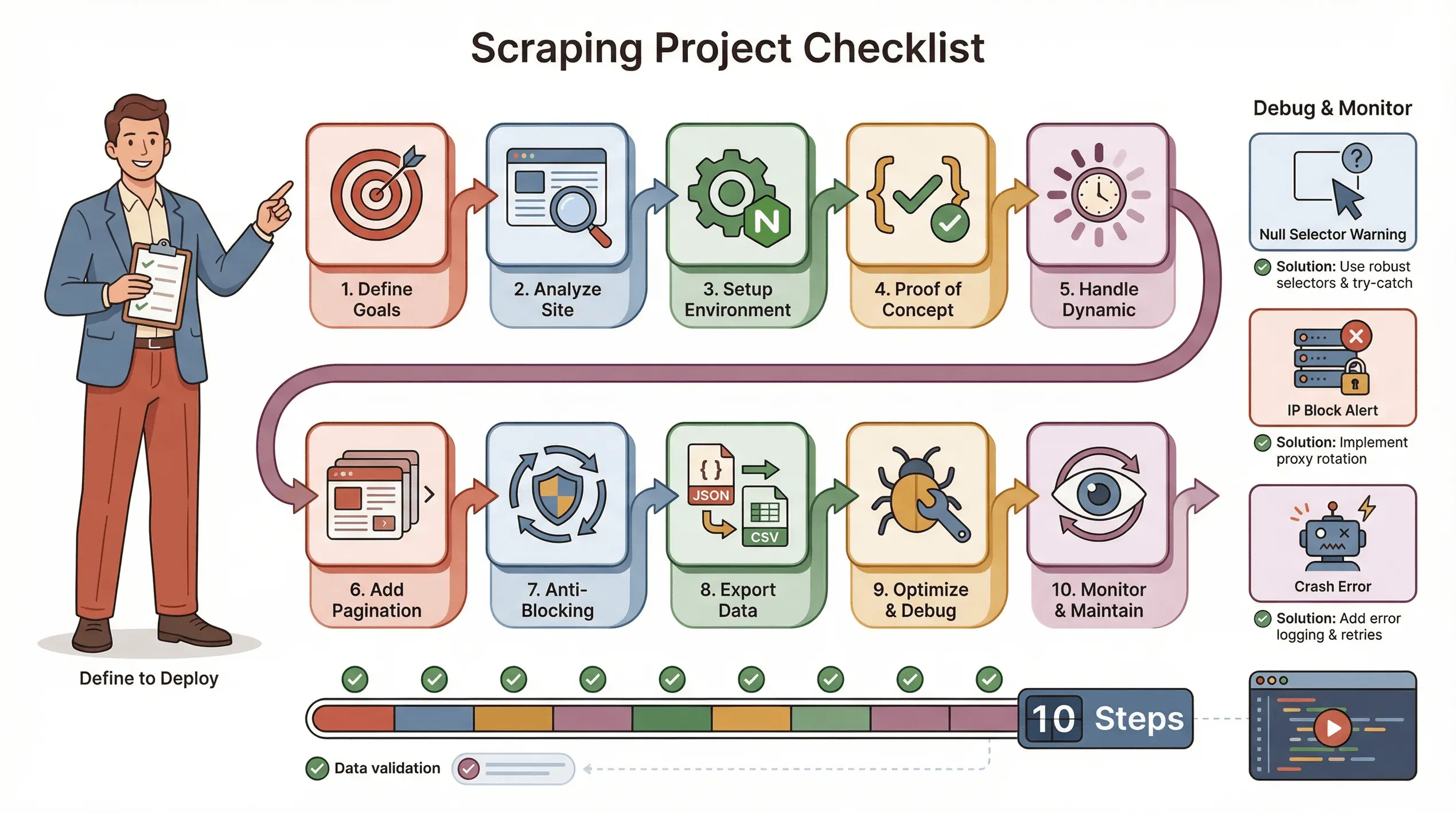 Hier ist meine Standard-Checkliste für ein reibungsloses Puppeteer-Scraping-Projekt:
Hier ist meine Standard-Checkliste für ein reibungsloses Puppeteer-Scraping-Projekt:
- Ziele definieren: Welche Daten brauchen Sie? Wo liegen sie?
- Website analysieren: Ist sie dynamisch? Braucht sie ein Login? Gibt es Anti-Bot-Maßnahmen?
- Umgebung einrichten: Node.js, Puppeteer und alle Hilfsbibliotheken.
- Einen Proof of Concept schreiben: Mit einer Seite starten, die Selektoren sauber hinbekommen.
- Dynamische Inhalte behandeln:
waitForSelectorverwenden, Klicks/Scrollen nach Bedarf simulieren. - Paginierung oder Schleifen ergänzen: Alle Seiten scrapen, nicht nur eine.
- Anti-Blocking-Taktiken umsetzen: Verzögerungen zufällig variieren, einen echten User-Agent setzen, bei Bedarf Proxys nutzen.
- Daten exportieren und prüfen: Als JSON/CSV speichern und auf Vollständigkeit prüfen.
- Optimieren und Fehler abfangen:
try/catcheinbauen, Fortschritt protokollieren, fehlende Daten sauber behandeln. - Überwachen und pflegen: Websites ändern sich – halten Sie Ihr Skript aktuell.
Tipps zur Fehlerbehebung:
- Wenn Selektoren
nullzurückgeben, prüfen Sie das HTML und arbeiten Sie mit Wartezeiten. - Wenn Sie blockiert werden, verlangsamen Sie die Abfragen, rotieren Sie IPs oder nutzen Sie Stealth-Plugins.
- Wenn Ihr Skript abstürzt, prüfen Sie auf Speicherlecks oder unbehandelte Ausnahmen.
Fazit und wichtigste Erkenntnisse
Web Scraping ist für datengetriebene Teams zu einer unverzichtbaren Fähigkeit geworden. Puppeteer gibt Ihnen die Möglichkeit, Daten sogar von den dynamischsten, JavaScript-lastigen Websites zu extrahieren – allerdings braucht es dafür Programmierkenntnisse und laufende Pflege. Für Business-Anwender, die auf Code verzichten und direkt an die Daten kommen wollen, bietet Thunderbit eine KI-gestützte Alternative ohne Programmierung, die schnell, flexibel und überraschend robust ist.
Meine Empfehlung:
- Wenn Sie technisch sind und tiefgehende Anpassungen brauchen, beginnen Sie mit Puppeteer.
- Wenn Sie Geschwindigkeit, Einfachheit und weniger Wartung wollen, probieren Sie aus (die ist ein guter Startpunkt).
- Für die meisten Teams deckt eine Mischung aus beidem 99 % der Anforderungen an Webdaten ab.
Sie möchten weitere Leitfäden wie diesen? Schauen Sie im vorbei – mit Tutorials, Vergleichen und den neuesten Entwicklungen im KI-gestützten Web Scraping.
FAQs
1. Was ist ein Puppeteer-Scraper und warum wird er für Web Scraping verwendet?
Puppeteer ist eine Node.js-Bibliothek, mit der Sie einen Headless-Chrome-Browser per JavaScript steuern können. Sie wird für Web Scraping eingesetzt, weil sie dynamische Inhalte laden, Nutzeraktionen simulieren und Daten von Websites extrahieren kann, die traditionelle Scraper nicht bewältigen.
2. Wie schneidet Puppeteer im Vergleich zu Selenium und Thunderbit ab?
Selenium funktioniert mit mehreren Browsern und Sprachen, ist aber umfangreicher. Puppeteer ist für Chrome/Node.js optimiert und bei vielen Scraping-Aufgaben schneller. Thunderbit hingegen ist ein No-Code-Tool mit KI, mit dem auch nicht-technische Nutzer Daten mit nur wenigen Klicks scrapen können.
3. Was sind die wichtigsten geschäftlichen Vorteile von Puppeteer-Web-Scraping?
Die Automatisierung der Datenerfassung spart Zeit, reduziert Fehler und ermöglicht Echtzeit-Einblicke für Vertrieb, Marketing, Operations und mehr. Die Anwendungsfälle reichen von Lead-Generierung über Preisüberwachung bis hin zu Marktforschung.
4. Was sind die größten Herausforderungen beim Scraping mit Puppeteer?
Die Hauptprobleme sind dynamische Inhalte, Anti-Bot-Sperren und die Pflege von Skripten, wenn sich Websites ändern. Sie müssen Code schreiben, um Wartezeiten zu steuern, Interaktionen zu simulieren und Fehler zu behandeln.
5. Wann sollte ich Thunderbit statt Puppeteer verwenden?
Nutzen Sie Thunderbit, wenn Sie ohne Code arbeiten möchten, schnell Ergebnisse brauchen oder nicht-technische Teammitglieder befähigen wollen. Es ist ideal für Standard-Scraping-Aufgaben, kurzfristige Projekte oder wenn Sie Daten mit minimalem Aufwand nach Excel oder Google Sheets exportieren möchten.
Bereit für eine intelligentere Art des Scrapens? oder noch tiefer einsteigen mit weiteren Leitfäden im . Viel Erfolg beim Scrapen!
Mehr erfahren