Webdaten wachsen geradezu 폭발적으로 – und damit steigt auch der Druck, irgendwie mitzuhalten. Ich habe aus nächster Nähe gesehen, wie Sales- und Operations-Teams mehr Zeit damit verbringen, Tabellen zu „zähmen“ und Daten von Websites rüberzukopieren, als wirklich Entscheidungen zu treffen. Laut Salesforce verbringen Vertriebsmitarbeitende inzwischen , und Asana sagt, dass . Das sind unzählige Stunden, die in manueller Datensammlung versickern – Zeit, die man viel besser in Abschlüsse oder Kampagnen stecken würde.
Die gute Nachricht: Web Scraping ist längst Mainstream – und du musst kein Developer sein, um davon zu profitieren. Ruby ist seit Jahren eine beliebte Wahl, um Webdaten automatisiert zu extrahieren. Kombiniert man Ruby aber mit modernen ki-web-scraper-Lösungen wie , bekommst du das Beste aus beiden Welten: maximale Flexibilität für Programmierende und no-code web-scraper-Komfort für alle anderen. Ob Marketing, E-Commerce oder einfach nur genug vom endlosen Copy-Paste: Dieser Guide zeigt dir, wie du web scraping mit ruby und KI beherrschst – ganz ohne Scraping-Code.
Was ist Web Scraping mit Ruby? Dein Einstieg in automatisierte Daten
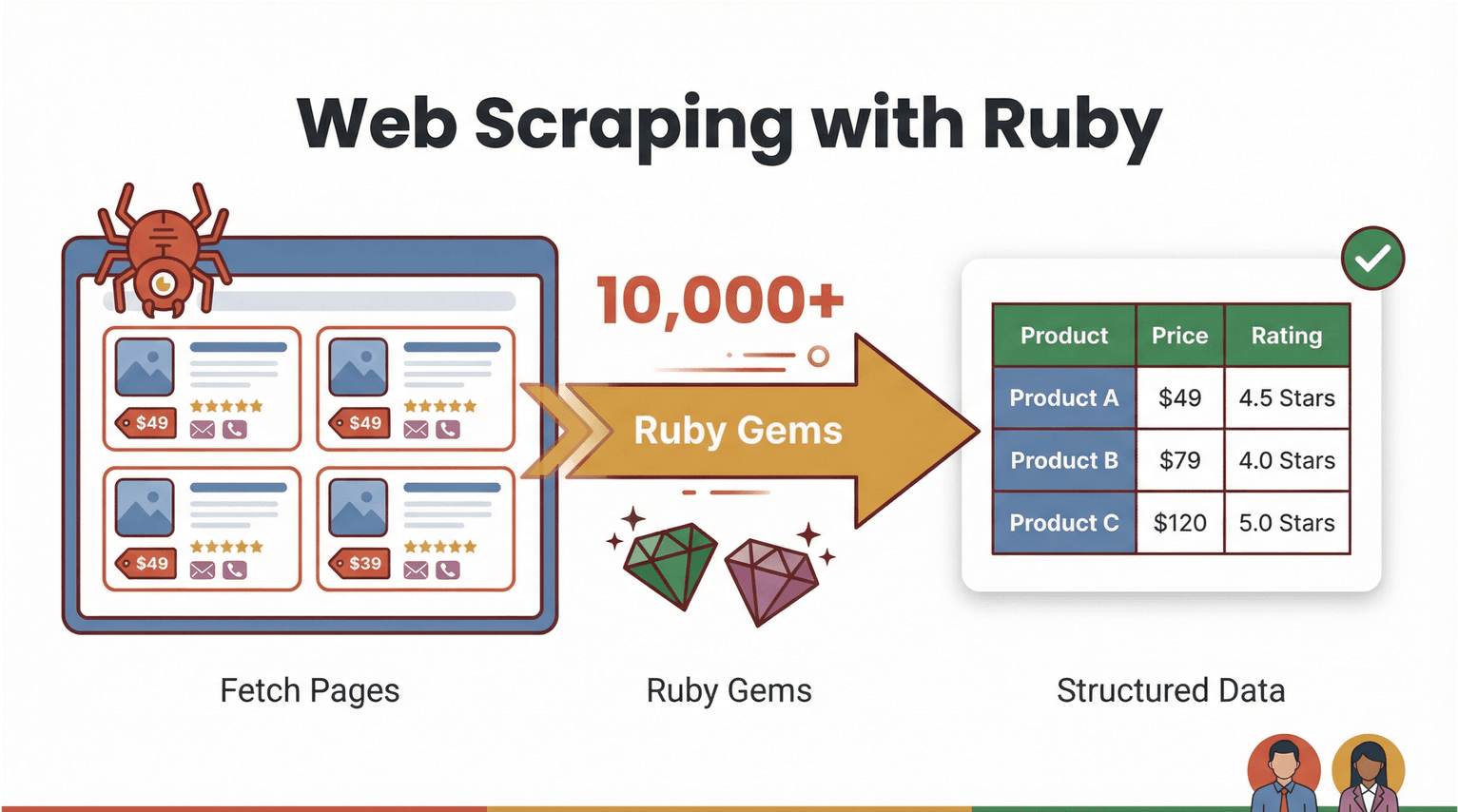
Starten wir mit den Basics. Web Scraping heißt: Software ruft Webseiten ab und zieht gezielt Informationen heraus – zum Beispiel Produktpreise, Kontaktdaten oder Bewertungen – und bringt das Ganze in ein strukturiertes Format (z. B. CSV oder Excel). Mit Ruby ist Web Scraping sowohl leistungsstark als auch ziemlich zugänglich. Die Sprache ist bekannt für ihre gut lesbare Syntax und ein riesiges Ökosystem an „Gems“ (Bibliotheken), die Automatisierung angenehm machen ().
Wie sieht „web scraping mit ruby“ in der Praxis aus? Stell dir vor, du willst aus einem Onlineshop alle Produktnamen und Preise ziehen. Mit Ruby kannst du ein Skript schreiben, das:
- die Webseite herunterlädt (z. B. mit )
- das HTML analysiert und die gewünschten Daten findet (mit )
- die Ergebnisse in eine Tabelle oder Datenbank exportiert
Richtig spannend wird’s, weil du heute nicht mehr immer selbst Code schreiben musst. KI-gestützte no-code web-scraper wie übernehmen inzwischen die Schwerarbeit: Seiten lesen, Felder erkennen und saubere Datentabellen exportieren – mit nur ein paar Klicks. Ruby bleibt ein starkes „Automations-Klebeband“ für individuelle Workflows, aber ki-web-scraper öffnen Business-Teams die Tür zu Webdaten – ohne Programmierhürden.
Warum Web Scraping mit Ruby für Business-Teams wichtig ist

Seien wir ehrlich: Niemand hat Bock, den Tag mit Copy-Paste zu verbringen. Der Bedarf an automatisierter Webdaten-Extraktion steigt massiv – und das aus gutem Grund. So verändert web scraping mit ruby (und KI-Tools) die Arbeit in Unternehmen:
- Lead-Generierung: Kontaktdaten aus Verzeichnissen oder LinkedIn direkt für die Sales-Pipeline ziehen.
- Preisbeobachtung bei Wettbewerbern: Preisänderungen über Hunderte E-Commerce-SKUs verfolgen – ohne manuelle Checks.
- Produktkataloge aufbauen: Produktdetails und Bilder für den eigenen Shop oder Marktplatz aggregieren.
- Marktforschung: Reviews, Ratings oder News-Artikel für Trendanalysen sammeln.
Der ROI ist ziemlich eindeutig: Teams, die Webdaten automatisiert erfassen, sparen wöchentlich Stunden, reduzieren Fehler und arbeiten mit aktuelleren, verlässlicheren Daten. In der Fertigung zum Beispiel – obwohl sich das Datenvolumen in nur zwei Jahren verdoppelt hat. Das ist eine riesige Automatisierungs-Chance.
Hier eine kurze Übersicht, wie web scraping mit ruby und KI-Tools Mehrwert schafft:
| Anwendungsfall | Manueller Schmerzpunkt | Vorteil durch Automatisierung | Typisches Ergebnis |
|---|---|---|---|
| Lead-Generierung | E-Mails einzeln kopieren | Tausende in Minuten extrahieren | 10x mehr Leads, weniger Fleißarbeit |
| Preis-Monitoring | Tägliche Website-Checks | Geplante, automatische Preisabfragen | Preis-Insights in Echtzeit |
| Katalogaufbau | Manuelle Dateneingabe | Massen-Extraktion & Formatierung | Schnellere Launches, weniger Fehler |
| Marktforschung | Reviews händisch lesen | Scrapen und analysieren im großen Stil | Tiefere, aktuellere Erkenntnisse |
Und es geht nicht nur um Tempo: Automatisierung bedeutet weniger Fehler und konsistentere Daten – entscheidend, wenn .
Web-Scraping-Lösungen im Vergleich: Ruby-Skripte vs. KI-Web-Scraper-Tools
Solltest du ein eigenes Ruby-Skript schreiben oder lieber einen KI-gestützten no-code web-scraper nutzen? Schauen wir uns die Optionen an.
Ruby-Scripting: Maximale Kontrolle, mehr Wartungsaufwand
Rubys Ökosystem bietet Gems für nahezu jeden Scraping-Fall:
- : Standardtool zum Parsen von HTML und XML.
- : Zum Abrufen von Webseiten und APIs.
- : Für Seiten mit Cookies, Formularen und Navigation.
- / : Für echte Browser-Automation (ideal bei JavaScript-lastigen Seiten).
Mit Ruby-Skripten bekommst du volle Flexibilität – eigene Logik, Datenbereinigung und Integrationen in interne Systeme. Dafür trägst du auch die Wartung: Ändert eine Website ihr Layout, kann dein Skript brechen. Und ohne Coding-Erfahrung gibt es eine spürbare Lernkurve.
KI-Web-Scraper & No-Code-Tools: Schnell, intuitiv und anpassungsfähig
Moderne no-code web-scraper wie drehen den Spieß um. Statt Code zu schreiben, machst du Folgendes:
- Chrome-Erweiterung öffnen
- „AI Suggest Fields“ klicken, damit die KI erkennt, was extrahiert werden soll
- „Scrape“ starten und Daten exportieren
Thunderbits KI passt sich an wechselnde Web-Layouts an, verarbeitet Unterseiten (z. B. Produktdetails) und exportiert direkt nach Excel, Google Sheets, Airtable oder Notion. Ideal für Business-User, die Ergebnisse ohne Aufwand wollen.
Hier der direkte Vergleich:
| Ansatz | Vorteile | Nachteile | Am besten für |
|---|---|---|---|
| Ruby-Scripting | Volle Kontrolle, eigene Logik, flexibel | Höhere Lernkurve, Wartungsaufwand | Developer, Power-User |
| KI-Web-Scraper | No-Code, schneller Start, passt sich an | Weniger Feintuning, gewisse Limits | Business-Teams, Ops |
Der Trend ist eindeutig: Je komplexer (und „abwehrender“) Websites werden, desto häufiger setzen Business-Workflows auf ki-web-scraper.
Erste Schritte: Ruby-Umgebung fürs Web Scraping einrichten
Wenn du Ruby-Scripting ausprobieren willst, richten wir deine Umgebung ein. Die gute Nachricht: Ruby lässt sich leicht installieren und läuft unter Windows, macOS und Linux.
Schritt 1: Ruby installieren
- Windows: Lade den herunter und folge dem Setup. MSYS2 solltest du mitinstallieren, um native Extensions zu bauen (wichtig für Gems wie Nokogiri).
- macOS/Linux: Nutze für Versionsverwaltung. Im Terminal:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Schau auf Rubys Download-Seite nach der aktuellen stabilen Version: .)
Schritt 2: Bundler und wichtige Gems installieren
Bundler verwaltet Abhängigkeiten:
1gem install bundlerLege eine Gemfile für dein Projekt an:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Dann ausführen:
1bundle installSo bleibt deine Umgebung konsistent und ist bereit fürs Scraping.
Schritt 3: Setup testen
Teste das in IRB (Rubys interaktive Shell):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONWenn eine Versionsnummer erscheint, passt alles.
Schritt für Schritt: Deinen ersten Ruby Web-Scraper bauen
Gehen wir ein echtes Beispiel durch: Wir scrapen Produktdaten von – einer Website, die extra zum Üben gedacht ist.
Hier ein einfaches Ruby-Skript, das Buchtitel, Preise und Lagerstatus extrahiert:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"Das Skript lädt jede Seite, parst das HTML, extrahiert die Daten und schreibt sie in eine CSV-Datei. books.csv kannst du in Excel oder Google Sheets öffnen.
Typische Stolpersteine:
- Wenn Gems fehlen: Gemfile prüfen und
bundle installausführen. - Bei Websites, die Daten per JavaScript nachladen, brauchst du Browser-Automation wie Selenium oder Watir.
Ruby-Scraping mit Thunderbit boosten: KI-Web-Scraper in der Praxis
Jetzt dazu, wie dein Scraping aufs nächste Level hebt – ohne Code.
Thunderbit ist eine , mit der du strukturierte Daten von praktisch jeder Website in zwei Klicks extrahieren kannst. So läuft’s ab:
- Thunderbit-Erweiterung öffnen auf der Seite, die du scrapen willst.
- „AI Suggest Fields“ klicken. Die KI scannt die Seite und schlägt passende Spalten vor (z. B. „Produktname“, „Preis“, „Lagerbestand“).
- „Scrape“ klicken. Thunderbit sammelt die Daten, kümmert sich um Pagination und folgt bei Bedarf Unterseiten.
- Daten exportieren direkt nach Excel, Google Sheets, Airtable oder Notion.
Thunderbit ist besonders stark bei komplexen, dynamischen Seiten – ohne fragile Selektoren oder Code. Und wenn du Workflows kombinieren willst: Daten mit Thunderbit extrahieren und anschließend mit einem Ruby-Skript weiterverarbeiten oder anreichern.
Pro-Tipp: Thunderbits Unterseiten-Scraping ist Gold wert für E-Commerce- und Immobilien-Teams. Du scrapest eine Liste mit Produktlinks und lässt Thunderbit jede Detailseite besuchen, um Spezifikationen, Bilder oder Reviews zu ziehen – automatisch und als angereicherter Datensatz.
Praxisbeispiel: E-Commerce-Produkt- & Preisdaten mit Ruby und Thunderbit scrapen
Setzen wir alles zu einem praxistauglichen Workflow für E-Commerce-Teams zusammen.
Szenario: Du willst Wettbewerberpreise und Produktdetails über Hunderte SKUs hinweg überwachen.
Schritt 1: Mit Thunderbit die Haupt-Produktliste scrapen
- Öffne die Produktübersicht des Wettbewerbers.
- Starte Thunderbit und klicke „AI Suggest Fields“ (z. B. Produktname, Preis, URL).
- Klicke „Scrape“ und exportiere als CSV.
Schritt 2: Daten per Unterseiten-Scraping anreichern
- Nutze in Thunderbit „Scrape Subpages“, um jede Produktdetailseite zu besuchen und zusätzliche Felder zu extrahieren (z. B. Beschreibung, Bestand, Bilder).
- Exportiere die angereicherte Tabelle.
Schritt 3: Mit Ruby verarbeiten oder analysieren
- Nutze ein Ruby-Skript, um Daten zu bereinigen, zu transformieren oder auszuwerten. Zum Beispiel:
- Preise in eine Standardwährung umrechnen
- Out-of-Stock-Produkte herausfiltern
- Kennzahlen und Zusammenfassungen erzeugen
Hier ein kurzes Ruby-Beispiel, das nur verfügbare Produkte filtert:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endErgebnis:
Du gehst von rohen Webseiten zu einer sauberen, handlungsfähigen Datentabelle – bereit für Preisanalysen, Bestandsplanung oder Marketingkampagnen. Und das, ohne eine einzige Zeile Scraping-Code schreiben zu müssen.
No-Code? Kein Problem: Webdaten-Extraktion für alle automatisieren
Was ich an Thunderbit besonders mag: Es macht nicht-technische Teams unabhängig. Du musst weder Ruby noch HTML oder CSS kennen – Erweiterung öffnen, KI arbeiten lassen, exportieren.
Lernkurve: Bei Ruby-Skripten brauchst du Grundlagen in Programmierung und Web-Struktur. Mit Thunderbit bist du in Minuten startklar – nicht erst nach Tagen.
Integration: Thunderbit exportiert direkt in Tools, die Business-Teams ohnehin nutzen: Excel, Google Sheets, Airtable, Notion. Du kannst Scrapes sogar zeitlich planen, um regelmäßig zu monitoren.
Feedback aus der Praxis: Ich habe Marketing-Teams, Sales Ops und E-Commerce-Manager gesehen, die mit Thunderbit alles automatisieren – von Lead-Listen bis Preis-Tracking – ohne jemals IT bemühen zu müssen.
Best Practices: Ruby und KI-Web-Scraper für skalierbare Automatisierung kombinieren
Wenn du einen robusten, skalierbaren Scraping-Workflow aufbauen willst, helfen diese Tipps:
- Website-Änderungen einplanen: KI-Web-Scraper wie Thunderbit passen sich automatisch an. Bei Ruby-Skripten musst du Selektoren aktualisieren, wenn sich Seiten ändern.
- Scrapes planen: Nutze Thunderbits Scheduling für regelmäßige Datenabzüge. Bei Ruby: Cronjob oder Task Scheduler.
- Batch-Verarbeitung: Bei großen Datenmengen in Batches arbeiten, um Sperren zu vermeiden und Systeme nicht zu überlasten.
- Datenformatierung: Vor Analysen immer bereinigen und validieren – Thunderbit exportiert strukturiert, Ruby-Skripte brauchen ggf. zusätzliche Checks.
- Compliance: Nur öffentlich verfügbare Daten scrapen,
robots.txtrespektieren und Datenschutz beachten (insbesondere in der EU – ). - Fallback-Strategien: Wenn eine Seite zu komplex wird oder Scraping blockiert, nach offiziellen APIs oder alternativen Datenquellen suchen.
Wann welches Tool?
- Ruby-Skripte, wenn du volle Kontrolle, eigene Logik oder tiefe Integrationen in interne Systeme brauchst.
- Thunderbit, wenn du schnell, einfach und anpassungsfähig arbeiten willst – besonders für einmalige oder wiederkehrende Business-Aufgaben.
- Beides kombinieren für fortgeschrittene Workflows: Thunderbit extrahiert, Ruby übernimmt Anreicherung, QA oder Integration.
Fazit & wichtigste Erkenntnisse
web scraping mit ruby war schon immer eine Art Superkraft für automatisierte Datensammlung – und mit ki-web-scraper wie Thunderbit ist diese Power jetzt für alle zugänglich. Egal ob du als Developer maximale Flexibilität willst oder als Business-User einfach Ergebnisse brauchst: Du kannst Webdaten-Extraktion automatisieren, Stunden manueller Arbeit sparen und schneller bessere Entscheidungen treffen.
Das solltest du mitnehmen:
- Ruby ist ein starkes Tool für Web Scraping und Automatisierung – besonders mit Gems wie Nokogiri und HTTParty.
- KI-Web-Scraper wie Thunderbit machen Datenextraktion für Nicht-Programmierer zugänglich, z. B. mit „AI Suggest Fields“ und Unterseiten-Scraping.
- Ruby + Thunderbit kombiniert liefert das Beste aus beiden Welten: schnelle no-code web-scraper-Extraktion plus individuelle Automatisierung und Analyse.
- Automatisierte Webdatensammlung ist ein echter Gameplan für Sales, Marketing und E-Commerce – weniger Aufwand, höhere Genauigkeit, neue Insights.
Bereit loszulegen? , ein einfaches Ruby-Skript testen und sehen, wie viel Zeit du sparst. Und wenn du tiefer einsteigen willst: Im findest du weitere Guides, Tipps und Praxisbeispiele.
FAQs
1. Muss ich programmieren können, um Thunderbit fürs Web Scraping zu nutzen?
Nein. Thunderbit ist für nicht-technische Nutzer gemacht. Erweiterung öffnen, „AI Suggest Fields“ klicken, den Rest erledigt die KI. Export nach Excel, Google Sheets, Airtable oder Notion – ohne Code.
2. Was sind die wichtigsten Vorteile von Ruby beim Web Scraping?
Ruby bietet leistungsfähige Bibliotheken wie Nokogiri und HTTParty für flexible, maßgeschneiderte Scraping-Workflows. Ideal für Developer, die volle Kontrolle, eigene Logik und Integrationen brauchen.
3. Wie funktioniert Thunderbits Feature „AI Suggest Fields“?
Thunderbits KI scannt die Webseite, erkennt die relevantesten Datenfelder (z. B. Produktnamen, Preise, E-Mails) und schlägt dir eine strukturierte Tabelle vor. Spalten kannst du vor dem Scrape anpassen.
4. Kann ich Thunderbit mit Ruby-Skripten für fortgeschrittene Workflows kombinieren?
Ja. Viele Teams extrahieren Daten mit Thunderbit (gerade bei komplexen oder dynamischen Seiten) und verarbeiten oder analysieren sie anschließend mit Ruby weiter. Dieser Hybrid-Ansatz eignet sich hervorragend für individuelles Reporting oder Datenanreicherung.
5. Ist Web Scraping legal und sicher für den Business-Einsatz?
Web Scraping ist legal, wenn du öffentlich verfügbare Daten sammelst und Nutzungsbedingungen sowie Datenschutzgesetze einhältst. Prüfe robots.txt und vermeide das Scrapen personenbezogener Daten ohne passende Rechtsgrundlage – besonders in der EU unter GDPR.
Neugierig, wie Web Scraping deinen Workflow verändern kann? Teste Thunderbits Free-Tier oder experimentiere heute mit einem Ruby-Skript. Und falls du hängen bleibst: Der und der sind voll mit Tutorials und Tipps, damit du Webdaten-Automatisierung meisterst – ganz ohne Code.
Mehr erfahren