Das Internet verändert sich ständig – und wer im digitalen Business mithalten will, muss flexibel und schnell reagieren. Aus meiner Zeit im SaaS- und Automatisierungsbereich weiß ich: Am meisten lernt man oft von dem, was schon da ist. Egal, ob du Wettbewerber analysieren, ein neues Produkt aufbauen oder einfach ein Backup deiner eigenen Seite brauchst – die Fähigkeit, jede Website zu klonen (also Inhalte, Struktur oder sogar Funktionen zu erfassen), verschafft Unternehmen einen echten Vorsprung. Dank KI-Tools wie ist das Website klonen heute nicht mehr nur was für Entwickler, sondern für jeden, der einen Browser bedienen kann.
Aber klar: Eine Website zu klonen ist nicht einfach „Speichern unter“ und fertig. Moderne Seiten sind dynamisch, interaktiv und manchmal so schwer zu greifen wie ein nasser Fisch. In diesem Guide zeige ich dir, was „jede Website klonen“ wirklich bedeutet, warum das für Unternehmen so spannend ist, welche Stolpersteine es gibt und – am wichtigsten – wie du mit Tools wie Thunderbit sicher, effizient und rechtlich sauber vorgehst.
Was heißt eigentlich, eine Website zu klonen?
Fangen wir ganz vorne an. „Website klonen“ kann Verschiedenes bedeuten:
- Design klonen: Die Seite so nachbauen, dass sie optisch und funktional wie das Original aussieht.
- Inhalte klonen: Texte, Bilder, Produktinfos und andere sichtbare Daten übernehmen.
- Funktionen klonen: Features wie Suchfelder, Formulare oder interaktive Elemente nachbilden.
Für die meisten Unternehmen geht’s vor allem darum, sichtbare Inhalte und Daten zu kopieren – also das, was du siehst und auswerten kannst, nicht den Quellcode oder geheime Logik. Im Grunde machst du einen Schnappschuss der öffentlichen Website und wandelst ihn in eine strukturierte Datensammlung um – für Analysen, Prototypen oder Archivierung.
Und bevor du fragst: Klonen heißt nicht stehlen oder plagiieren. Die meisten Anwendungsfälle sind völlig legitim – zum Beispiel Wettbewerbsanalysen, schnelles Prototyping oder ein Backup für Compliance. Ziel ist es, Zeit zu sparen und Insights zu gewinnen, nicht das Rad neu zu erfinden oder Rechte zu verletzen.
Warum sollte man eine Website klonen? Typische Business-Usecases
Du wirst staunen, wie viele Teams im Alltag auf Website-Kloning setzen. Hier ein paar der gängigsten Anwendungsfälle:
| Anwendungsfall | Beschreibung & geschäftlicher Nutzen |
|---|---|
| Wettbewerber-Preisüberwachung | Produktseiten von Konkurrenten auslesen, um Preise und Lagerbestände zu verfolgen. Ermöglicht dynamische Preisgestaltung – ein britischer Händler erzielte so einen 4%igen Umsatzanstieg. |
| Leadgenerierung & CRM-Anreicherung | Verzeichnisse oder LinkedIn-Seiten klonen, um Leads zu sammeln. Automatisierung spart bis zu 80% Zeit. |
| Content-Weiterverwendung | FAQs, Blogbeiträge oder Bewertungen duplizieren, um Erkenntnisse zu kuratieren oder Inhalte für die eigene Zielgruppe neu aufzubereiten. |
| Schnelles Prototyping & Design | Frontend bestehender Seiten klonen, um neue Projekte zu beschleunigen – Prototypen in Tagen statt Wochen. |
| Backup & Archivierung | Komplette Kopien von Websites für Compliance oder Dokumentation erstellen. |
Und das ist nur der Anfang. Forscher klonen Social-Media-Seiten, um Trends zu analysieren, SEO-Profis kopieren Seitenstrukturen für Offline-Analysen und fast basieren auf gescrapten Webdaten. Der große Vorteil: Tempo und Erkenntnisgewinn – statt Daten mühsam per Hand zu sammeln oder Designs nachzubauen, bekommst du alles auf einen Schlag.
Die Herausforderungen beim Website klonen: Mehr als Copy & Paste
Wäre das Klonen einer Website so einfach wie „Kopieren > Einfügen“, würde es jeder machen. Aber wer’s probiert hat, weiß: Es ist oft viel komplizierter.
Warum einfaches Kopieren nicht reicht
- Dynamische Inhalte: Viele Seiten laden Daten erst per JavaScript. Ein simples „Seite speichern“ bringt oft nur eine leere Hülle – ohne Bilder, ohne Live-Daten ().
- APIs und Skripte: Manche Inhalte kommen erst nachträglich über APIs. Nur das HTML zu speichern reicht dann nicht.
- Login-Pflicht: Manche Infos sind nur nach Login sichtbar – hier brauchst du Tools, die mit deiner Browsersitzung arbeiten.
- Anti-Scraping-Schutz: CAPTCHAs, Rate-Limits oder Bot-Erkennung können automatisiertes Kopieren blockieren.
- Rechtliche & ethische Grenzen: Nur weil man etwas kopieren kann, heißt das nicht, dass man es darf. Urheberrecht und Nutzungsbedingungen sind zu beachten.
Kurz gesagt: Website klonen braucht technisches Know-how und Verantwortungsbewusstsein. Es geht nicht nur darum, Daten zu bekommen, sondern sie korrekt und rechtssicher zu erfassen.
Website klonen im Vergleich: Von Handarbeit bis KI-Tools
Welche Tools gibt’s? Im Grunde gibt es drei Ansätze, jeder mit eigenen Vor- und Nachteilen:
| Methode | Bedienkomfort | Genauigkeit | Dynamische Inhalte | Exportoptionen | Rechtssicherheit | Wartungsaufwand |
|---|---|---|---|---|---|---|
| Manuelles Kopieren/Download | Mittel | Gering | Schlecht | HTML/CSS/JS | Nutzerabhängig | Hoch (anfällig) |
| Klassisches Web-Scraping | Niedrig | Hoch* | Gut* | CSV/Excel/JSON | Nutzerabhängig | Hoch (bricht leicht) |
| KI-Tools (Thunderbit) | Sehr hoch | Hoch | Exzellent | Excel/Sheets/Notion | Nutzerfreundlich | Niedrig |
*Wenn du weißt, was du tust und alles richtig einstellst.
Manuelles Kopieren/Download
Tools wie HTTrack oder die „Seite speichern“-Funktion im Browser funktionieren bei einfachen, statischen Seiten – sind aber und versagen bei dynamischen Inhalten. Oft fehlen Bilder, das Layout ist kaputt und die Dateistruktur wird schnell unübersichtlich.
Klassisches Web-Scraping
Dazu zählen eigene Skripte (Python, BeautifulSoup usw.) oder visuelle Scraper, bei denen du Felder per Klick auswählst. Sehr mächtig, aber . Wartung ist mühsam – ändert sich die Seite, funktioniert der Web-Scraper oft nicht mehr.
KI-Tools (Thunderbit)
Jetzt wird’s spannend: nutzt KI, um die Seite zu „verstehen“. Du klickst einfach auf „AI Spalten vorschlagen“, die KI erkennt automatisch relevante Datenfelder – und los geht’s. Dynamische Inhalte, Mehrseiten-Navigation und Export zu Excel, Google Sheets, Airtable oder Notion sind inklusive. Das Ganze ist für Nicht-Techniker gemacht – du brauchst keine Programmierkenntnisse.
Für einen ausführlichen Vergleich von Web-Scraper Chrome-Erweiterungen, schau dir an.
Schritt-für-Schritt: So klonst du jede Website mit Thunderbit
Bereit? So gehe ich beim Klonen einer Website mit Thunderbit vor:
Schritt 1: Thunderbit installieren und einrichten
Geh zuerst auf die und registriere dich kostenlos. Installiere dann die . Die Installation ist super easy – ein paar Klicks und fertig.
Nach der Installation findest du das Thunderbit-Icon in deiner Chrome-Leiste. Draufklicken, einloggen und dein erstes Projekt starten. Tipp: Pinne das Icon für schnellen Zugriff. Wenn du eine Seite mit Login scrapen willst, logge dich vorher dort ein – Thunderbit nutzt deine aktuelle Browsersitzung.
Schritt 2: Mit KI Datenfelder erkennen und strukturieren
Ruf die gewünschte Website auf (z. B. eine Produktseite eines Mitbewerbers). Öffne das Thunderbit-Seitenpanel und starte ein neues Scraping-Projekt. Jetzt kommt die Magie: Klick auf „AI Spalten vorschlagen“ (manchmal auch „AI Felder vorschlagen“ genannt) – Thunderbits KI scannt die Seite und schlägt automatisch passende Datenfelder vor, wie Produktname, Preis, Bild-URL, Bewertung usw.
Du kannst die Spalten prüfen, anpassen oder weitere hinzufügen. Willst du z. B. „Verfügbarkeit“ oder „Artikelnummer“ erfassen? Einfach ergänzen – die KI füllt das Feld nach Möglichkeit aus. HTML-Kenntnisse brauchst du keine, die KI übernimmt die Arbeit.
Schritt 3: Website-Daten scrapen und exportieren
Sind die Spalten festgelegt, klickst du auf „Scrapen“ (oder „Start“). Thunderbit extrahiert alle Daten für die gewählten Felder, Zeile für Zeile. Bei Listen (z. B. Produktübersichten) werden alle Einträge erfasst.
Und was ist mit Paginierung oder unendlichem Scrollen? Thunderbit erkennt die meisten Fälle automatisch – bei „Weiter“-Buttons oder Scroll-Mechanismen läuft der Prozess weiter. Bei besonders kniffligen Seiten kannst du manuell nachhelfen oder die erweiterten Einstellungen nutzen, aber für die meisten Business-Websites läuft alles reibungslos.
Nach Abschluss siehst du deine Daten in einer übersichtlichen Tabelle. Der Export ist super einfach: Direkt nach Excel, Google Sheets, Airtable oder Notion – kein nerviges CSV-Handling mehr, sondern sofort nutzbare, strukturierte Daten.
Mehr Details findest du im .
Noch mehr rausholen: Subpage-Scraping für komplette Website-Kopien
Hier spielt Thunderbit seine Stärken aus: Subpage-Scraping. Viele Websites zeigen auf der Hauptseite nur Zusammenfassungen (z. B. Produktname und Preis), während die Details – Beschreibungen, Spezifikationen, Bewertungen – auf Unterseiten versteckt sind.
Mit Thunderbits Subpage-Scraping gehst du einen Schritt weiter. Aktiviere die Funktion, und die KI folgt automatisch den Links zu den Detailseiten, sammelt die Zusatzinfos und fügt sie in deinen Datensatz ein. Wenn du z. B. eine Kategorie „Winterjacken“ klonst, kann Thunderbit jede einzelne Produktseite besuchen und Material, Verfügbarkeit, Kundenbewertungen usw. extrahieren – für einen vollständigen, strukturierten Klon des gesamten Sortiments.
Das spart richtig viel Zeit. Egal, ob du eine umfassende Lead-Liste erstellst, eine Wissensdatenbank archivierst oder einen Produktkatalog analysierst – mit Subpage-Scraping entgeht dir kein Detail.
Ein Praxisbeispiel findest du unter .
Rechtssicherheit: Websites legal und sicher klonen
Jetzt zum wichtigen Punkt: Ist es legal, jede Website zu klonen?
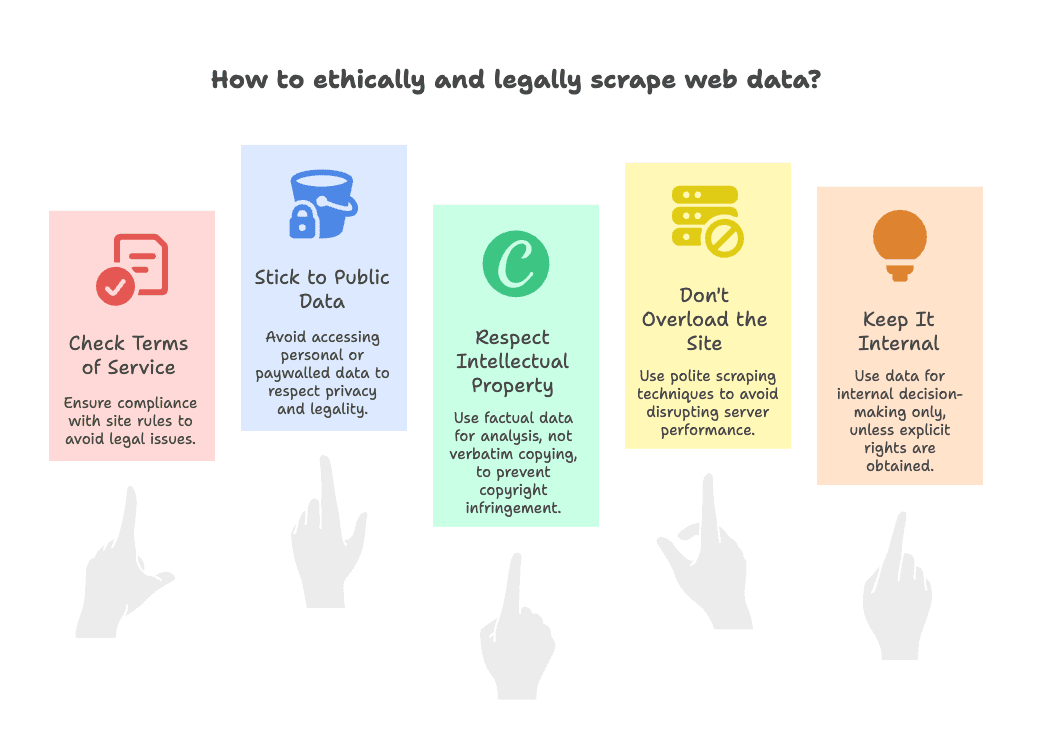
Kurz gesagt: Meistens ja, solange du ein paar Grundregeln beachtest. Hier meine Compliance-Checkliste:
- Nutzungsbedingungen prüfen: Manche Seiten verbieten Scraping ausdrücklich. Dann lieber vorsichtig sein – Daten nur intern nutzen, nicht veröffentlichen ().
- Nur öffentliche Daten scrapen: Erfasse nur, was ohne Login sichtbar ist. Keine persönlichen Daten, E-Mails oder Inhalte hinter Bezahlschranken ().
- Urheberrechte respektieren: Fakten wie Preise oder Produktnamen sind meist unproblematisch. Kreative Inhalte (z. B. Blogtexte, Bilder) können urheberrechtlich geschützt sein – nutze sie nur zur Analyse, nicht zum Nachbau ().
- Server nicht überlasten: Scrape rücksichtsvoll – keine tausenden Anfragen pro Sekunde. Thunderbit hat ein eingebautes Rate-Limit, aber bleib immer fair ().
- Nur intern verwenden: Ohne ausdrückliche Rechte solltest du geklonte Daten nur für interne Entscheidungen nutzen, nicht öffentlich weitergeben.
Thunderbit hilft dir bei der Compliance, indem du Daten direkt in sichere Plattformen wie Google Sheets oder Airtable exportierst und so intern verwalten kannst. Weitere rechtliche Tipps findest du in .
Profi-Tipps: So holst du beim Klonen mit Thunderbit das Maximum raus
Wenn du die Basics drauf hast, kannst du mit diesen Tipps noch mehr aus Thunderbit rausholen:
- Dynamische & interaktive Seiten meistern: Bei Inhalten, die erst nach Klicks erscheinen (z. B. „Alle Bewertungen anzeigen“), führe die Aktion selbst aus und starte dann Thunderbit. Die KI erfasst alles Sichtbare. Bei unendlichem Scrollen: Stückweise scrollen oder die Paginierungsfunktion nutzen ().
- Eigene KI-Prompts: Gib der KI präzise Spaltennamen – z. B. „Autor (Text nach By:)“ oder „Vorteile Zusammenfassung“. Thunderbits KI erkennt den Kontext, klare Spaltennamen wirken wie Mini-Anweisungen ().
- KI für Datenumwandlung: Nutze Thunderbits KI-Zusammenfassung oder verbinde Tools wie ChatGPT, um Daten direkt zu analysieren, kategorisieren oder zu übersetzen ().
- Geplante Scrapes: Richte regelmäßige Scrapes ein, um Websites laufend zu überwachen – ideal für Preisbeobachtung oder neue Stellenanzeigen ().
- Bulk-URL-Scraping: Gib Thunderbit eine Liste von URLs, und es scrapt jede automatisch – perfekt, wenn du die Links schon gesammelt hast.
- Vorlagen für bekannte Seiten: Nutze Thunderbits Sofort-Vorlagen für Seiten wie Amazon oder Zillow und passe sie bei Bedarf an ().
- Sonderfälle meistern: Bei CAPTCHAs oder ungewöhnlichen Layouts hilft oft ein zweiter Durchlauf oder das Anpassen der Spalten. Thunderbits KI ist robust, aber ein kurzer Check schadet nie.
Für noch mehr Möglichkeiten schau dir an.
Fazit & wichtigste Erkenntnisse: Websites sicher und effizient klonen
Website klonen ist längst nicht mehr nur was für Entwickler – es ist eine praktische Methode, die Teams in Vertrieb, Marketing und Operations ganz neue Möglichkeiten eröffnet. Das solltest du mitnehmen:
- Geschäftlicher Nutzen: Website klonen bringt echten Mehrwert – ob du der Konkurrenz voraus sein, Zeit sparen oder fundiertere Entscheidungen treffen willst ().
- Herausforderungen & Lösungen: Moderne Websites sind komplex, aber Tools wie Thunderbit machen das Klonen schnell, präzise und auch für Nicht-Techniker einfach.
- Thunderbit-Vorteil: Mit Features wie „AI Spalten vorschlagen“ und Subpage-Scraping wird aus stundenlanger Handarbeit ein Zwei-Klick-Prozess.
- Rechtssicherheit: Klone immer verantwortungsvoll – nur öffentliche Daten, Urheberrechte beachten und Daten intern nutzen.
- Noch mehr Möglichkeiten: Mit Profi-Tipps und Integrationen meistert Thunderbit auch anspruchsvolle Seiten und Workflows.
Das nächste Mal, wenn du vor einer Produktseite eines Mitbewerbers, einem Lead-Verzeichnis oder einer Wissensdatenbank stehst, die du analysieren willst – denk dran: Du hast die Tools, um Websitedaten sicher und effizient zu klonen. Nutze diese Möglichkeiten verantwortungsvoll – und viel Erfolg bei deinen datengetriebenen Projekten!
FAQs
1. Ist es legal, Websites für geschäftliche Zwecke zu klonen?
In der Regel ja – solange du dich auf öffentliche Daten beschränkst, Urheberrechte respektierst und die Daten intern nutzt. Prüfe immer die Nutzungsbedingungen der Seite und vermeide das Scrapen von persönlichen oder urheberrechtlich geschützten Inhalten ohne Erlaubnis. Mehr dazu in .
2. Was ist der Unterschied zwischen Klonen und Scrapen einer Website?
Klonen heißt meist, eine Kopie von Inhalten, Struktur oder Design einer Seite zu erstellen, während Scraping das gezielte Extrahieren bestimmter Daten meint. Mit Tools wie Thunderbit verschwimmen die Grenzen – du kannst Daten scrapen und so gezielt die benötigten Teile „klonen“.
3. Kann Thunderbit dynamische Inhalte und Unterseiten erfassen?
Ja! Thunderbits KI ist darauf ausgelegt, dynamische Inhalte (z. B. per JavaScript geladene Daten) zu erkennen und kann Links zu Unterseiten folgen, um alle Infos in einem Datensatz zusammenzuführen. So bekommst du mit wenigen Klicks einen vollständigen Website-Klon.
4. Wie exportiere ich geklonte Websitedaten nach Excel oder Google Sheets?
Nach dem Scraping mit Thunderbit kannst du deine Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren – ganz ohne manuelle Nachbearbeitung. Die Daten sind sofort bereit zur Analyse oder Weitergabe.
5. Gibt es Tipps für das Klonen besonders anspruchsvoller Websites?
Nutze individuelle KI-Prompts für präzise Felder, plane regelmäßige Scrapes für laufende Überwachung und setze auf Bulk-URL- und Vorlagenfunktionen für mehr Effizienz. Bei interaktiven Seiten führe Aktionen manuell aus, bevor du scrapest, und prüfe deine Daten immer auf Vollständigkeit.