

Über 200 Nachrichtenquellen auf relevante Artikel im Blick behalten – manuell ist das ein Vollzeitjob. Und ein herkömmlicher Scraper? Der ging bei mir jedes Mal kaputt, sobald eine Website ihr Layout umbaute.
Erst die KI-gestützten Article Scraper haben das geändert: ein Klick, saubere Daten, keine CSS-Selektoren mehr. Der Unterschied zum bisherigen Vorgehen ist deutlich.
Wer als Journalist:in, SEO-Fachkraft oder Forschende:r Artikel in großem Umfang erfassen muss, spart sich mit diesem Vergleich eine Menge Ausprobieren. Ich habe sowohl klassische No-Code-Scraper als auch KI-gestützte Lösungen getestet – und zeige Ihnen, was im Alltag wirklich trägt.
Beliebige Website mit KI scrapen Get Started Free
Kurzfassung
| Vorteile | Nachteile | Am besten geeignet für | |
|---|---|---|---|
| KI-gestützter Article Scraper | - Kann mehrere Websites mit hoher Genauigkeit scrapen - Entfernt Störsignale automatisch - Passt sich an Änderungen der Webstruktur an - Unterstützt dynamisch nachgeladene Inhalte - Geringe Kosten für Datenbereinigung | - Höhere Rechenkosten - Längere Verarbeitungszeit - Einige Seiten benötigen manuelle Eingriffe - Kann Anti-Scraping-Mechanismen auslösen | - Scraping komplexer oder dynamischer Websites (z. B. Nachrichtenportale, soziale Medien) - Datenerfassung in großem Umfang |
| Traditioneller No-Code Article Scraper | - Schnelle Ausführung - Niedrigere Kosten - Geringer Server- und lokaler Ressourcenverbrauch - Hohe Steuerbarkeit | - Häufige Wartung wegen Änderungen der Webstruktur - Kann nicht mehrere Websites gleichzeitig scrapen - Kommt mit dynamischen Inhalten nicht zurecht - Hohe Kosten für Datenbereinigung | - Schnelles Scraping einfacher statischer Webseiten im großen Maßstab - Begrenzte Rechenressourcen, knappe Budgets |
Was ist ein Article Scraper – und warum lohnt sich die KI-Variante?
Ein Article Scraper ist eine Spielart des Web-Scrapers, die Informationen wie Titel, Autoren, Veröffentlichungsdaten, Fließtext, Keywords, Bilder und Videos von Nachrichtenseiten aufspürt, extrahiert und in strukturierte Formate wie JSON, CSV oder Excel bringt.
Traditionelle No-Code-Article-Scraper arbeiten mit CSS-Selektoren und greifen Inhalte über die HTML-Struktur einer Seite ab. Dieser Ansatz hat jedoch Schwächen:
- Mangelnde Allgemeingültigkeit: Jede Webstruktur verlangt eigene CSS-Selektoren. Ändert sich die Struktur, werden sie unbrauchbar, und ständiges Nachjustieren ist die Folge.
- Probleme mit dynamischen Inhalten: Viele Websites laden Inhalte per AJAX oder JavaScript nach, und genau die erreichen CSS-Selektoren nicht direkt.
- Begrenzte Datenverarbeitung: CSS-Selektoren liefern nur HTML-Fragmente – ohne anschließende Bereinigung, Formatierung, semantische Analyse oder Sentiment-Auswertung.
 Hier kommt der KI-gestützte Article Scraper ins Spiel.
Hier kommt der KI-gestützte Article Scraper ins Spiel.
-
Die Technologie setzt LLMs ein, um Webseiten zu verstehen, und bietet:
- Intelligente Erkennung: Titel, Autoren, Zusammenfassungen und Hauptinhalte werden zuverlässig identifiziert.
- Automatisches Entfernen von Störsignalen: Der Haupttext wird von Navigation, Werbung und verwandten Artikeln getrennt, was Datenqualität und Effizienz hebt.
- Robustheit gegenüber Webänderungen: Auch wenn sich Struktur oder Design einer Seite ändern, scrapet die KI dank semantischem Verständnis und visueller Merkmale weiter.
- Plattformübergreifende Generalisierung: Anders als klassische Scraper laufen KI-Scraper ohne manuelle Anpassung auf den verschiedensten Websites.
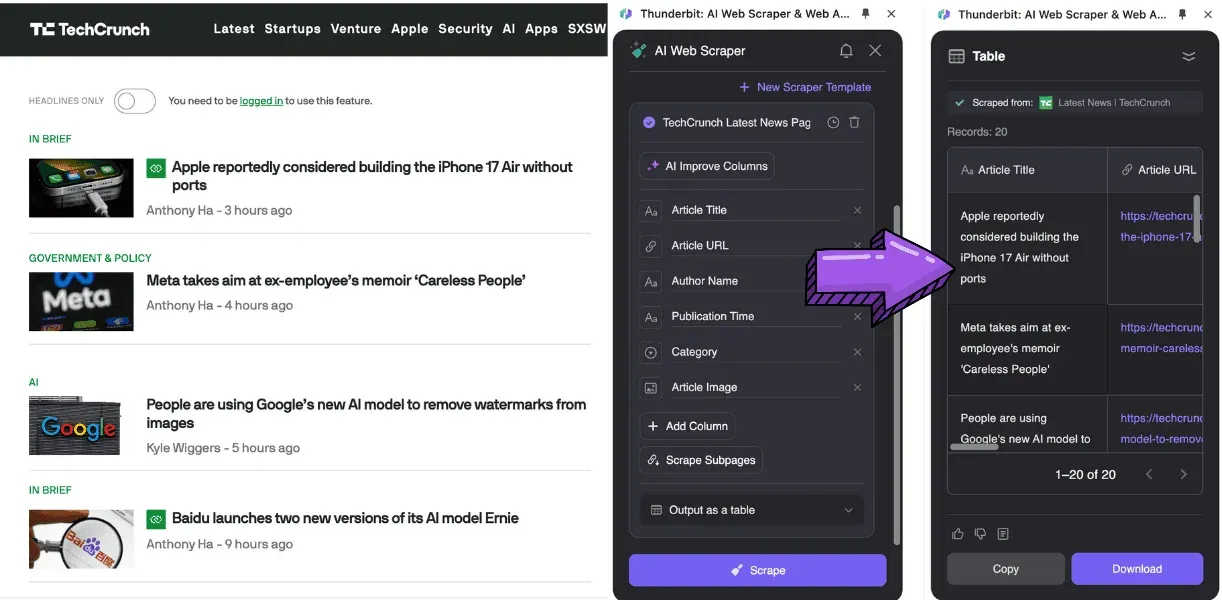
- Verzahnung mit NLP und Deep Learning: Aufgaben wie Übersetzung, Zusammenfassung und Sentiment-Analyse erledigt das Tool gleich mit.
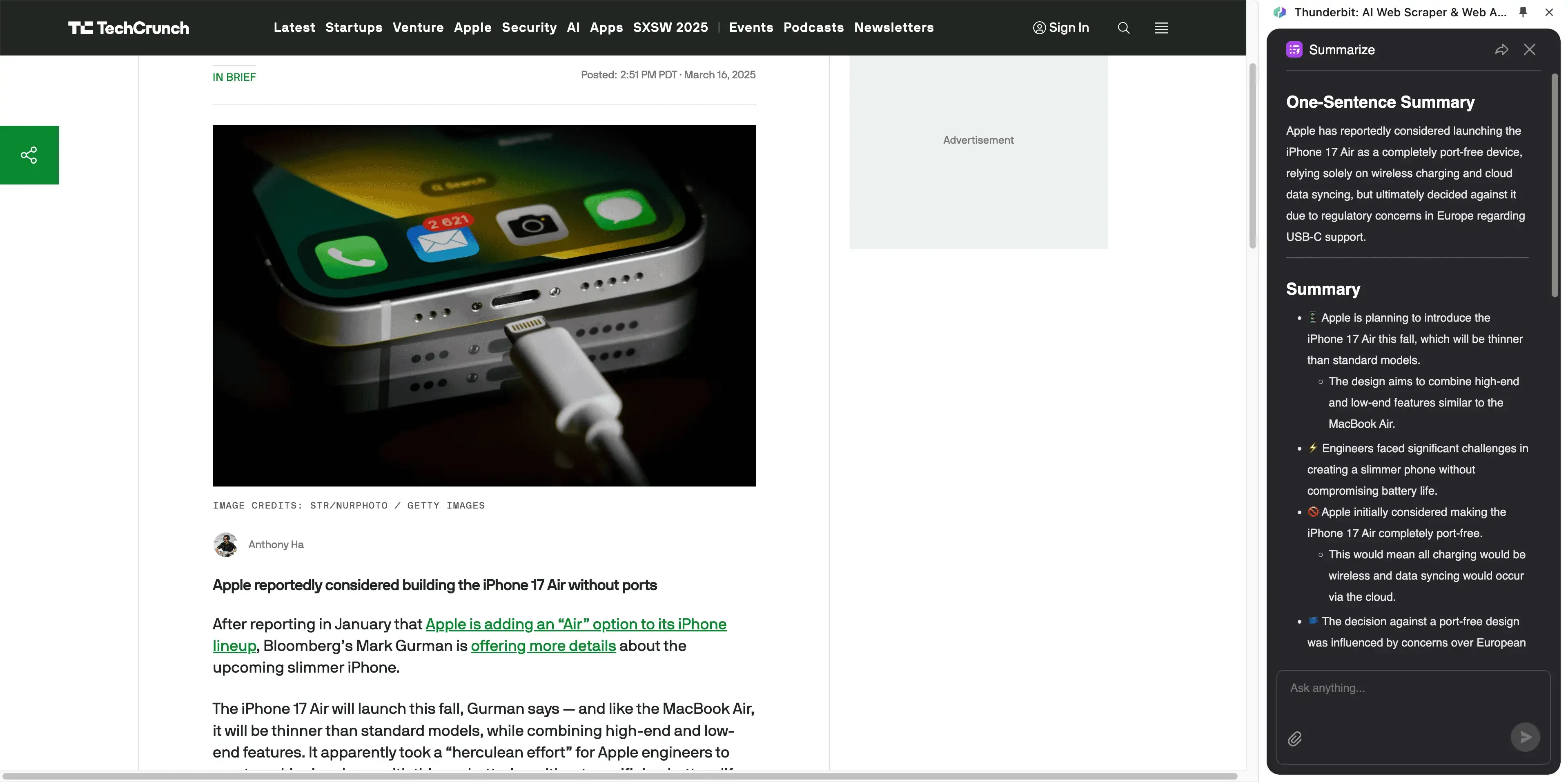
Was zeichnet den besten Article Scraper 2026 aus?
Ein erstklassiger Article Scraper hält Leistung, Kosten, Bedienbarkeit, Flexibilität und Skalierbarkeit in Balance. Diese Kriterien sind 2026 entscheidend:

- Einfache Bedienung: Intuitive Oberfläche, kein Programmieren nötig.
- Genaue Artikelerfassung: Die relevanten Informationen werden präzise erkannt, Werbung und Navigation bleiben außen vor.
- Robustheit gegenüber Webänderungen: Das Tool passt sich automatisch an Struktur- oder Designänderungen an, ohne ständige Wartung.
- Kompatibilität mit vielen Websites: Funktioniert über unterschiedlichste Webstrukturen hinweg.
- Umgang mit dynamischen Inhalten: Unterstützt das Nachladen per JavaScript oder AJAX.
- Multimedia-Verarbeitung: Erkennt Bilder, Videos und Audio.
- Anti-Scraping-Schutz: Setzt IP-Rotation, CAPTCHA-Lösung und Proxys ein, um Sperrmechanismen zu umgehen.
- Ausgewogene Ressourcennutzung: Verbraucht nicht übermäßig Speicher oder Rechenleistung.
Die besten Article- und News-Scraper auf einen Blick
| Tools | Wichtigste Funktionen | Am besten geeignet für | Preisgestaltung |
|---|---|---|---|
| Thunderbit | KI-gestützter Scraper; vorbereitete Vorlagen; Unterstützung für das Scrapen von PDFs, Bildern und Dokumenten; fortgeschrittene Datenverarbeitung | Nutzer ohne technischen Hintergrund, die mehrere Nischen-Websites scrapen möchten | 7 Tage kostenlos testen, ab 9 $/Monat (Jahresplan) |
| WebScraper.io | Browser-Erweiterung; Unterstützung für dynamische Inhalte; keine Proxy-Integration | Nutzer, die keine komplexen Webseiten oder fortgeschrittenen Funktionen benötigen | 7 Tage kostenlos testen, ab 40 $/Monat (Jahresplan) |
| Browse.ai | No-Code-Web-Scraper und Monitoring; vorgefertigte Bots; virtueller Browser; verschiedene Paginierungsmethoden; starke Integrationen | Unternehmen mit Bedarf an komplexem Scraping im großen Maßstab | 19 $/Monat (Jahresplan) |
| Octoparse | No-Code-Scraper auf Basis von CSS-Selektoren; automatische Erkennung und Generierung von Scraping-Workflows; vorgefertigte Article-Scraper-Vorlagen; virtueller Browser; Anti-Anti-Scraping-Mechanismen | Unternehmen mit Bedarf an komplexem Scraping | Ab 99 $/Monat (Jahresplan) |
| Bardeen | Umfassende Web-Automatisierung; vorgefertigte Vorlagen; No-Code-Scraper; nahtlose Integration in den Workspace | GTM-Teams, die Article Scraping in bestehende Workflows einbinden wollen | 7 Tage kostenlos testen, ab 99 $/Monat (Jahresplan) |
| PandaExtract | Benutzerfreundliche Oberfläche; automatische Erkennung und Kennzeichnung | Nutzer, die eine schnelle Extraktion mit einem Klick ohne komplexes Setup benötigen | 49 $ LTD |
Der leistungsstärkste KI-gestützte Article Scraper für Business-Anwender
- Vorteile:
- Ruft per natürlicher Sprache die KI zur Erkennung und Analyse von Webinhalten auf und macht CSS-Selektoren überflüssig
- KI-gestützte Datenaufbereitung – Formatkonvertierung, Zusammenfassung, Klassifizierung, Übersetzung und Tagging
- Vorbereitete Article-Vorlagen für die Extraktion von Artikellisten und Inhalten mit einem Klick
- Erschwingliche Preise mit sehr gutem Preis-Leistungs-Verhältnis
- Nachteile:
- Derzeit nur als Chrome-Erweiterung verfügbar
- Nicht für Scraping in sehr großem Umfang ausgelegt
- Beim Scraping vieler Seiten langsamer, kann aber im Hintergrund arbeiten und Ergebnisse so schneller liefern
Thunderbit KI-gestützten Article Scraper testen
Ein KI-gestützter Article Scraper für den Unternehmenseinsatz
Browse.ai
- Vorteile:
- No-Code-Article-Scraper inklusive Monitoring
- Betreibt einen virtuellen Browser, um Anti-Scraping-Mechanismen nicht auszulösen
- Zahlreiche vorgefertigte Bots, die Google News, Medium, Hacker News und mehr mit einem Klick scrapen
- Tiefe Anbindung an Zapier und Make zur Tool-Verknüpfung
- Nachteile:
- Für Deep Extract müssen zwei Bots erstellt werden, was den Prozess umständlich macht
- CSS-Selektoren arbeiten bei Nischen-Websites ungenau
- Teuer und eher für die kontinuierliche Datenerfassung in großem Maßstab gedacht
Ein No-Code-Scraper für kleine Datenmengen
PandaExtract
- Vorteile:
- Erkennt Artikellisten und Detailseiten automatisch, mit benutzerfreundlicher Oberfläche
- Extrahiert Listen, Detailseiten, E-Mails und Bilder – ideal für strukturierte Erfassung im kleinen Maßstab
- Einmalzahlung für lebenslange Nutzung
- Nachteile:
- Nur als Browser-Erweiterung verfügbar, kein Cloud-Betrieb
- Die kostenlose Version erlaubt nur Kopieren, keinen Export nach CSV, JSON usw.
Ein sofort einsatzbereiter Article Scraper für Organisationen
Octoparse
- Vorteile:
- No-Code-Article-Scraper mit automatischer Erkennung, der die Webstruktur erfasst und Scraping-Workflows generiert
- Zahlreiche vorgefertigte Vorlagen, sofort einsatzbereit
- Virtueller Browser mit IP-Rotation, CAPTCHA-Lösung und Proxys gegen Sperrmechanismen
- Nachteile:
- Die automatische Erkennung beruht weiterhin auf CSS-Selektor-Logik – mit durchschnittlicher Genauigkeit
- Fortgeschrittene Funktionen erfordern Einarbeitung und technisches Know-how
- Hohe Kosten bei großvolumiger Datenerfassung
Die umfassendste Automatisierung für GTM-Teams
Bardeen
- Vorteile:
- No-Code-Article-Scraper mit LLM für Automatisierung per Klick
- Anbindung an über 100 Anwendungen, darunter Google Sheets, Slack und Zoom
- Leistungsstarke Web-Automatisierung für KI-Analysen nach der Datenerfassung
- Ideal, um die Datenerfassung in bestehende Workflows einzubetten
- Nachteile:
- Starke Abhängigkeit von vorgefertigten Playbooks; eigene Workflows kosten Trial-and-Error
- Trotz No-Code-Ansatz brauchen komplexe Automatisierungen für Nicht-Techniker:innen Einarbeitung
- Das Einrichten von Extraktionen auf Unterseiten ist umständlich
- Sehr teuer
Ein schlanker Article Scraper für die schnelle Datenerfassung
Webscraper.io
- Vorteile:
- No-Code-Scraper mit Point-and-Click-Oberfläche
- Unterstützt das Nachladen dynamischer Inhalte
- Cloud-basierter Betrieb
- Anbindung an Dropbox, Google Sheets und Amazon
- Nachteile:
- Keine vorgefertigten Vorlagen, die Sitemap muss selbst erstellt werden
- Lernkurve für alle, die mit CSS-Selektoren nicht vertraut sind
- Umständliches Setup für Paginierung und Extraktion auf Unterseiten
- Die Cloud-Version ist teuer
Fortgeschrittenere Lösungen für Entwickler:innen
Für technisch versierte Nutzer:innen stehen Article-Scraper-APIs bereit. Sie bieten:
- Flexibilität: Direkte API-Aufrufe für maßgeschneidertes Scraping, inklusive dynamischem Rendering und IP-Rotation
- Skalierbarkeit: Einbindung in eigene Datenpipelines für hohe Frequenz und große Datenmengen im Unternehmensmaßstab
- Geringer Wartungsaufwand: Keine Verwaltung von Proxy-Pools oder Anti-Scraping-Strategien nötig, das spart Betriebszeit
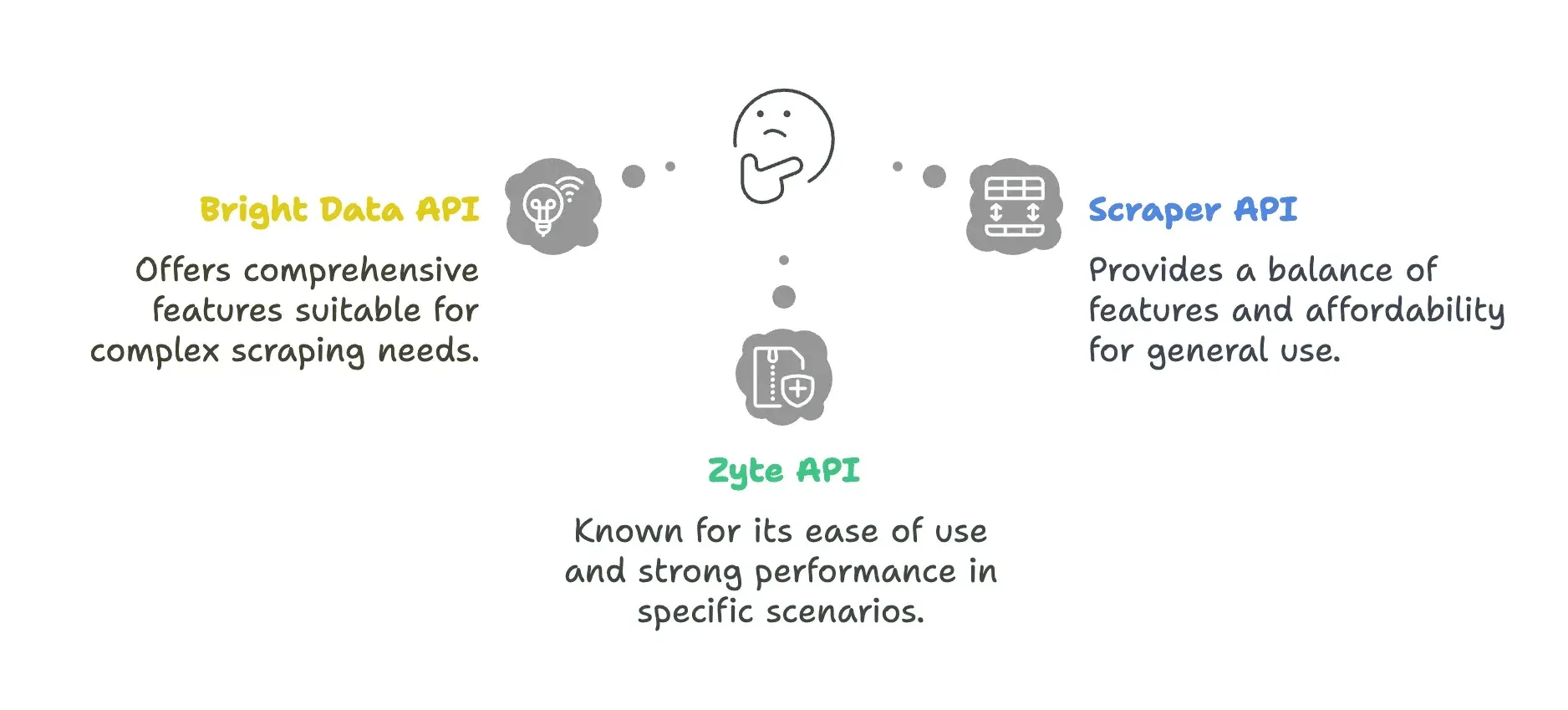
API-Lösungen auf einen Blick
| API | Vorteile | Nachteile |
|---|---|---|
| Bright Data API | - Umfangreiches Proxy-Netzwerk (72 Mio.+ IPs in 195 Ländern) - Fortschrittliches Geo-Targeting bis auf Stadt-/PLZ-Ebene - Robuster Proxy Manager für IP-Rotation | - Langsamere Antwortzeiten (durchschnittlich 22,08 s) - Höhere Preise, für kleinere Teams weniger geeignet - Steilere Lernkurve bei der Konfiguration |
| ScraperAPI | - Niedriger Einstieg ab 49 $ - Autoparse-Funktion zur automatischen Datenextraktion - Web-UI-Player zum Testen | - Berechnet häufig auch blockierte Anfragen - Begrenzte JavaScript-Rendering-Funktionen - Kosten können mit Premium-Parametern stark steigen |
| Zyte API | - KI-gestützte Parsing-Funktionen - Berechnet fehlgeschlagene Anfragen nicht | - Höhere Anfangskosten (ca. 450 $/Monat) - Guthaben wird nicht von Monat zu Monat übertragen |
- Bright Data Web Scraper API
- Vorteile:
- Deckt 195 Länder mit über 72 Mio. Residential IPs ab, beherrscht automatische IP-Rotation und Geo-Simulation und eignet sich ideal für Seiten mit strengen Anti-Scraping-Maßnahmen (etwa Amazon oder Instagram)
- Unterstützt das Nachladen dynamischer JavaScript-Inhalte und das Erfassen von Seiten-Schnappschüssen
- Nachteile:
- Hohe Kosten (Abrechnung pro Anfrage und Bandbreite); für kleine Projekte wenig kosteneffizient
- Vorteile:
- Scraper API
- Vorteile:
- 40 Mio. Proxys weltweit, automatischer Wechsel zwischen Rechenzentrums- und Residential-IP, Umgehung der Cloudflare-Prüfung, Einbindung externer CAPTCHA-Lösungen (z. B. 2Captcha)
- Strukturierte Endpunkte und asynchrone Scraper für mehr Tempo
- Nachteile:
- Zusatzkosten fürs Rendering dynamischer Seiten, eingeschränkte Unterstützung komplexer AJAX-Websites
- Vorteile:
- Zyte API
- Vorteile:
- KI-gestützte automatische Datenextraktion – kein eigenes Pflegen von Extraktionsregeln pro Website nötig
- Flexible Pay-as-you-go-Preise
- Nachteile:
- Fortgeschrittene Funktionen (z. B. Session-Handling, skriptfähiger Browser) erfordern Einarbeitung
- Vorteile:
So wählen Sie Ihren Article- und News-Scraper aus
Bei der Auswahl zählen drei Dinge: Ihr geschäftlicher Bedarf, Ihr technischer Hintergrund und Ihr Budget.

- Wenn Sie mehrere Nischen-Websites scrapen müssen, ohne für jede einen eigenen Scraper zu bauen, und ein Budget haben, ist Thunderbit die beste Wahl. Statt auf CSS-Selektoren zu setzen, analysiert es Webstrukturen per KI und erlaubt KI-Analysen direkt nach der Erfassung. Für die Thunderbit-KI sind alle Websites gleich, sodass komplette Artikel präzise erfasst werden.
- Wenn Sie Nachrichten und Artikel von großen Websites wie dem Wall Street Journal oder Google News scrapen wollen, brauchen Sie robuste Anti-Scraping-Mechanismen und vorgefertigte Vorlagen, etwa bei Browse.ai oder Octoparse. Die beste Option ist jedoch eine Chrome-Erweiterung wie Thunderbit: Die Erfassung ahmt normales Surfen und Kopieren nach, sodass auch Logins ohne kompliziertes Setup funktionieren.
- Wenn Sie dauerhaft in großem Umfang scrapen müssen, eignen sich Tools mit Zeitplan-Funktion wie Octoparse besser.
- Für den Team-Einsatz und die nahtlose Einbindung in bestehende Workflows ist Bardeen ideal, da es über das Article Scraping hinaus eine ganze Reihe von Web-Automatisierungstools mitbringt.
- Wenn Sie einen schlanken Article Scraper für kleine Datenmengen suchen, ohne Zeit ins Lernen zu stecken, wählen Sie einen Point-and-Click-Scraper wie PandaExtract.
- Wenn Sie einen technischen Hintergrund haben oder einen Enterprise-Scraper bauen, sollten Sie API-Tools oder einen eigenen Scraper zusätzlich zu diesen No-Code-Scrapern in Betracht ziehen.
Fazit
Dieser Artikel hat Konzept und Einsatzszenarien von Article- und News-Scrapern vorgestellt. Traditionelle Scraper bauen auf CSS-Selektoren auf und setzen, besonders bei anspruchsvollen Aufgaben, Wissen über HTML und CSS voraus. Die neue Generation der KI-gestützten Article-Scraper verlässt sich dagegen ganz auf semantisches Verständnis und visuelle Erkennung und schlägt klassische Scraper bei der Anpassung an Strukturänderungen, der Generalisierung über Websites hinweg, dem Umgang mit dynamischen Inhalten sowie der anschließenden Bereinigung und Analyse.
Außerdem hat der Artikel sechs nützliche Article- und News-Scraper sowie API-Tools für Entwickler:innen vorgestellt und nach Vor- und Nachteilen, geeigneten Datenmengen, Webfunktionen und Zielgruppen verglichen. Wenn Sie über Article- und News-Scraping nachdenken, wählen Sie die Lösung, die zu Ihrem Bedarf passt und Leistung und Kosten in Balance hält.
FAQs
1. Was ist ein KI-gestützter Article Scraper und wie funktioniert er?
- Er analysiert und extrahiert Inhalte von Webseiten per KI, ohne CSS-Selektoren.
- Er erkennt Titel, Autoren, Veröffentlichungsdaten und Hauptinhalte mit hoher Genauigkeit.
- Er entfernt automatisch Werbung, Navigationsmenüs und andere irrelevante Elemente.
- Er passt sich an Strukturänderungen an und funktioniert über verschiedene Websites hinweg.
2. Welche Vorteile bietet ein KI-gestützter Article Scraper gegenüber traditionellen Scrapern?
- Er extrahiert Inhalte von mehreren Websites mit nur einem Tool.
- Er verarbeitet dynamische Inhalte, auch per JavaScript und AJAX geladene Seiten.
- Er erfordert weniger manuelles Setup und weniger Wartung als CSS-basierte Scraper.
- Er bringt Zusatzfunktionen wie Zusammenfassung, Übersetzung und Sentiment-Analyse mit.
3. Kann ich Thunderbit für KI-gestütztes Article Scraping ohne Programmierkenntnisse nutzen?
- Ja, Thunderbit ist mit seiner schlichten No-Code-Oberfläche für Nicht-Techniker:innen gemacht.
- Es erkennt und extrahiert Artikelinhalte automatisch per KI.
- Es bietet vorgefertigte Vorlagen für schnelles, effizientes Scraping.
- Es exportiert die Daten in Formate wie CSV, JSON und Google Sheets.
Mehr erfahren:
- Was ist Web Scraping
- Wie man KI für Web Scraping nutzt
- Modernes Web Scraping: Ein tiefer Einblick in KI-gestützte Tools
- News Scraping: Tools, Anwendungsfälle und Herausforderungen
KI-Web-Scraper testen Get Started Free




