
هناك شيء مُرضٍ بشكل غريب في مشاهدة سكربت يقتحم موقعًا بسرعة ويجمع البيانات بينما أنت ترتشف قهوتك. إذا كنت مثلي، فربما سألت نفسك: «كيف أجعل استخراج الويب أسرع وأذكى وأقل إزعاجًا؟»
هذا بالضبط ما جذبني إلى عالم استخراج الويب باستخدام OpenClaw. ففي مشهد رقمي تعتمد فيه أكثر من 90% من الشركات على استخراج بيانات الويب لكل شيء، من العملاء المحتملين إلى معلومات السوق، فإن إتقان الأدوات المناسبة ليس مجرد استعراض تقني، بل ضرورة تجارية.
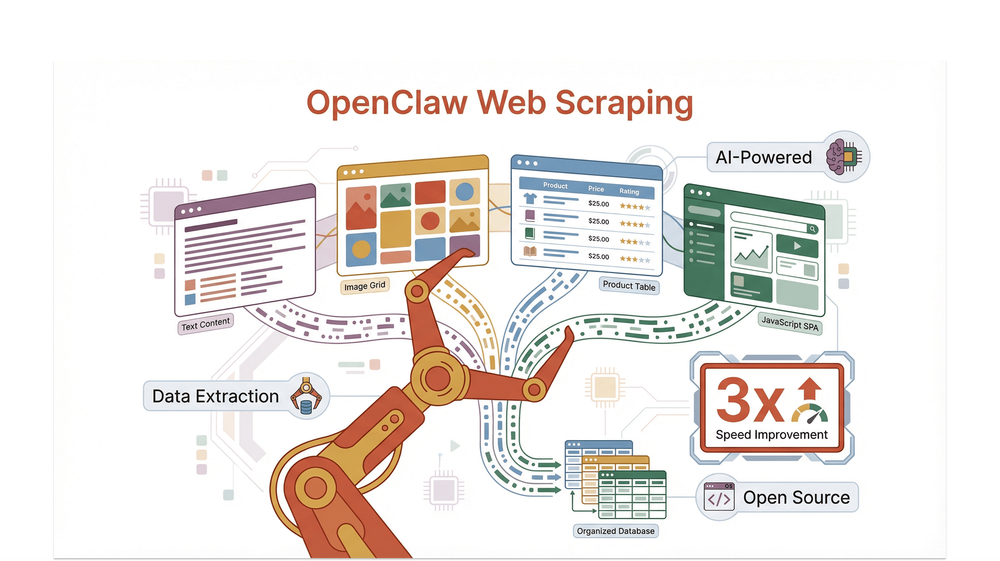
أصبح OpenClaw بسرعة من الأدوات المفضلة في مجتمع الاستخراج، خصوصًا لمن يتعاملون مع المواقع الديناميكية أو الغنية بالصور أو المعقدة التي تُنهك الأدوات التقليدية.
في هذا الدليل، سأرشدك خلال كل شيء، من إعداد OpenClaw إلى بناء تدفقات عمل متقدمة ومؤتمتة. ولأن هدفي دائمًا توفير الوقت، سأريك أيضًا كيف تعزّز عملية الاستخراج بميزات Thunderbit المدعومة بالذكاء الاصطناعي، لتصبح سيرورة العمل قوية وممتعة فعلًا في الاستخدام.
جرّب Thunderbit لاستخراج ويب أذكى
ما هو استخراج الويب باستخدام OpenClaw؟
لنبدأ من الأساسيات. يشير استخراج الويب باستخدام OpenClaw إلى استخدام منصة OpenClaw — وهي بوابة وكلاء مفتوحة المصدر ومستضافة ذاتيًا — لأتمتة استخراج البيانات من المواقع. OpenClaw ليس مجرد أداة استخراج أخرى؛ بل هو نظام معياري يربط قنوات الدردشة المفضلة لديك، مثل Discord أو Telegram، بمجموعة من أدوات الوكلاء، بما في ذلك أدوات جلب الويب، وأدوات البحث، وحتى متصفح مُدار للمواقع الثقيلة بجافاسكريبت التي تُرهق الأدوات الأخرى.
ما الذي يجعل OpenClaw مميزًا في استخراج بيانات الويب؟ صُمّم ليكون مرنًا ومتينًا في آن واحد. يمكنك استخدام أدوات مدمجة مثل web_fetch لاستخراج HTTP البسيط، أو تشغيل متصفح Chromium يتحكم به الوكيل للمحتوى الديناميكي، أو ربط مهارات مبنية من المجتمع، مثل openclaw-plugin-web-scraper، لسير عمل أكثر تقدمًا. وهو مفتوح المصدر (برخصة MIT)، ويجري تطويره بنشاط، ويضم منظومة مزدهرة من الإضافات والمهارات، ما يجعله خيارًا ممتازًا لكل من يأخذ الاستخراج واسع النطاق على محمل الجد.
يتعامل OpenClaw مع مجموعة واسعة من أنواع البيانات وتنسيقات المواقع، بما في ذلك:
- النصوص وHTML المنظّم
- الصور وروابط الوسائط
- المحتوى الديناميكي المُولّد عبر JavaScript
- هياكل DOM المعقدة متعددة الطبقات
ولأنه قائم على الوكلاء، يمكنك تنسيق مهام الاستخراج، وأتمتة التقارير، وحتى التفاعل مع بياناتك في الوقت الحقيقي — وكل ذلك من تطبيق الدردشة المفضل لديك أو الطرفية.
لماذا يُعد OpenClaw أداة قوية لاستخراج بيانات الويب
إذًا، لماذا يتجه هذا العدد الكبير من محترفي البيانات وعشاق الأتمتة إلى OpenClaw؟ دعنا نفكك نقاط القوة التقنية التي تجعله قوة حقيقية في استخراج الويب:
السرعة والتوافق
بُنيت بنية OpenClaw للسرعة. وتستفيد أداته الأساسية web_fetch من طلبات HTTP GET مع استخراج ذكي للمحتوى، وتخزين مؤقت، ومعالجة لإعادة التوجيه. وفي الاختبارات الداخلية واختبارات المجتمع، يتفوق OpenClaw باستمرار على الأدوات القديمة مثل BeautifulSoup أو Selenium عند استخراج كميات كبيرة من البيانات من المواقع الثابتة وشبه الديناميكية (docs.openclaw.ai).
لكن ما يتألق فيه OpenClaw حقًا هو التوافق. بفضل وضع المتصفح المُدار، يستطيع التعامل مع المواقع التي تعتمد على JavaScript في العرض — وهو أمر يوقع كثيرًا من أدوات الاستخراج التقليدية في المشاكل. سواء كنت تستهدف كتالوج تجارة إلكترونية غنيًا بالصور أو تطبيقًا أحادي الصفحة مع تمرير لا نهائي، فإن ملف Chromium الذي يتحكم به الوكيل في OpenClaw ينجز المهمة.
التحمّل أمام تغييرات المواقع
واحدة من أكبر المتاعب في استخراج الويب هي التعامل مع تحديثات المواقع التي تكسر سكربتاتك. صُمم نظام الإضافات والمهارات في OpenClaw ليكون مرنًا أمام ذلك. على سبيل المثال، توفر الأغلفة المحيطة بمكتبة Scrapling استخراجًا تكيفيًا، ما يعني أن أداة الاستخراج الخاصة بك تستطيع «إعادة العثور» على العناصر حتى لو تغيّر تخطيط الموقع — وهي ميزة كبيرة للمشاريع طويلة الأمد.
الأداء في الواقع العملي
في اختبارات مباشرة جنبًا إلى جنب، أظهرت تدفقات العمل المبنية على OpenClaw ما يلي:

- استخراج أسرع بما يصل إلى 3 مرات في المواقع المعقدة متعددة الصفحات مقارنةً بأدوات Python التقليدية (scrapling.readthedocs.io)
- معدلات نجاح أعلى في الصفحات الديناميكية الثقيلة بجافاسكريبت، بفضل المتصفح المُدار
- تعامل أفضل مع الصفحات المختلطة المحتوى (نصوص، صور، مقاطع HTML)
وغالبًا ما تؤكد شهادات المستخدمين قدرة OpenClaw على «العمل ببساطة» في الحالات التي تفشل فيها الأدوات الأخرى — خاصة عند استخراج البيانات من مواقع ذات تخطيطات معقدة أو إجراءات مضادة للروبوتات.
البدء: إعداد OpenClaw لاستخراج الويب
هل أنت مستعد للغوص؟ إليك كيفية تشغيل OpenClaw على نظامك.
الخطوة 1: تثبيت OpenClaw
يدعم OpenClaw أنظمة Windows وmacOS وLinux. وتوصي الوثائق الرسمية بالبدء عبر مسار الإعداد الموجّه:
openclaw onboard
يقودك هذا الأمر خلال الإعداد الأولي، بما في ذلك فحوصات البيئة والتهيئة الأساسية.
الخطوة 2: تثبيت الاعتماديات المطلوبة
بحسب سير عملك، قد تحتاج إلى:
- Node.js (للبوابة الأساسية)
- Python 3.10+ (للإضافات/المهارات التي تستخدم Python، مثل أغلفة Scrapling)
- Chromium/Chrome (لوضع المتصفح المُدار)
على Linux، قد تحتاج إلى تثبيت حزم إضافية لدعم المتصفح. وتضم الوثائق قسمًا مخصصًا لاستكشاف الأخطاء وإصلاحها للمشكلات الشائعة.
الخطوة 3: ضبط أدوات الويب
أعد إعداد مزود البحث على الويب:
openclaw configure --section web
يتيح لك هذا الاختيار من مزودين مثل Brave أو DuckDuckGo أو Firecrawl.
الخطوة 4: تثبيت الإضافات أو المهارات (اختياري)
لفتح إمكانيات استخراج متقدمة، ثبّت إضافات أو مهارات من المجتمع. على سبيل المثال، لإضافة openclaw-plugin-web-scraper:
git clone https://github.com/hvkeyn/openclaw-plugin-web-scraper.git
cd openclaw-plugin-web-scraper
openclaw plugins install .
openclaw gateway restart

نصائح احترافية للمبتدئين
- شغّل
openclaw security auditبعد تثبيت أي إضافات جديدة للتحقق من الثغرات الأمنية (docs.openclaw.ai). - إذا كنت تستخدم Node عبر nvm، فتحقق جيدًا من شهادات CA لديك — فعدم التطابق قد يكسر طلبات HTTPS (docs.openclaw.ai).
- اعزل دائمًا الإضافات ومكونات المتصفح داخل آلة افتراضية أو حاوية لمزيد من الأمان.
دليل المبتدئين: أول مشروع استخراج باستخدام OpenClaw
لننشئ مشروع استخراج بسيطًا — ولا تحتاج إلى دكتوراه في علوم الحاسوب.
الخطوة 1: اختر الموقع المستهدف
اختر موقعًا يحتوي على بيانات منظّمة، مثل قائمة منتجات أو دليل. في هذا المثال، سنستخرج عناوين المنتجات من صفحة تجارة إلكترونية تجريبية.
الخطوة 2: افهم بنية DOM
استخدم أداة «Inspect Element» في متصفحك لتحديد وسوم HTML التي تحتوي على البيانات التي تريدها (مثل <h2 class="product-title">).
الخطوة 3: أعد إعداد فلاتر الاستخراج
باستخدام مهارات OpenClaw المبنية على Scrapling، يمكنك استخدام محددات CSS لاستهداف العناصر. إليك مثالًا لسكربت يستخدم مهارة openclaw-ultra-scraping:
PYTHON=/opt/scrapling-venv/bin/python3
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text"
يجلب هذا الأمر الصفحة ويستخرج جميع عناوين المنتجات.
الخطوة 4: التعامل الآمن مع البيانات
صدّر النتائج إلى CSV أو JSON لتسهيل التحليل:
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o products.csv
مفاهيم أساسية موضحة
- مخططات الأدوات: تحدد ما الذي يمكن لكل أداة أو مهارة فعله (الجلب، الاستخراج، الزحف).
- تسجيل المهارات: أضف قدرات استخراج جديدة إلى OpenClaw عبر ClawHub أو التثبيت اليدوي.
- التعامل الآمن مع البيانات: تحقّق دائمًا من مخرجاتك ونقّحها قبل استخدامها في الإنتاج.
أتمتة تدفقات العمل المعقدة لاستخراج الويب باستخدام OpenClaw

بعد أن تتقن الأساسيات، حان وقت الأتمتة. إليك كيفية بناء تدفق عمل يعمل من تلقاء نفسه بينما تركز أنت على أمور أهم — مثل الغداء.
الخطوة 1: أنشئ مهارات مخصصة وسجّلها
اكتب أو ثبّت مهارات تناسب احتياجات الاستخراج الخاصة بك. على سبيل المثال، قد ترغب في استخراج معلومات المنتج وصوره، ثم إرسال تقرير يومي.
الخطوة 2: أعد إعداد المهام المجدولة
على Linux أو macOS، استخدم cron لجدولة سكربتات الاستخراج:
0 6 * * * /usr/bin/python3 /path/to/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o /data/products_$(date +\%F).csv
على Windows، استخدم Task Scheduler مع معلمات مشابهة.
الخطوة 3: التكامل مع الأدوات الأخرى
للتنقل الديناميكي (مثل النقر على الأزرار أو تسجيل الدخول)، امزج OpenClaw مع Selenium أو Playwright. يمكن للعديد من مهارات OpenClaw استدعاء هذه الأدوات أو قبول سكربتات أتمتة المتصفح.
مقارنة بين سير العمل اليدوي والمؤتمت
| الخطوة | سير العمل اليدوي | سير العمل المؤتمت باستخدام OpenClaw |
|---|---|---|
| استخراج البيانات | تشغيل السكربت يدويًا | مجدول عبر cron/Task Scheduler |
| التنقل الديناميكي | النقر يدويًا | مؤتمت عبر Selenium/المهارات |
| تصدير البيانات | نسخ/لصق أو تنزيل | تصدير تلقائي إلى CSV/JSON |
| التقارير | ملخص يدوي | إنشاء التقارير تلقائيًا وإرسالها بالبريد |
| معالجة الأخطاء | الإصلاح أثناء العمل | إعادة المحاولة والتسجيل المدمجان |
والنتيجة؟ بيانات أكثر، ومره أقل، وتدفق عمل يتوسع مع طموحك.
رفع الكفاءة: دمج ميزات Thunderbit المدعومة بالذكاء الاصطناعي مع OpenClaw
وهنا تصبح الأمور أكثر إثارة. بصفتي الشريك المؤسس لـ Thunderbit، أؤمن بقوة بدمج أفضل ما في العالمين: محرك الاستخراج المرن في OpenClaw وميزة كشف الحقول والتصدير المدعومة بالذكاء الاصطناعي في Thunderbit.
كيف يعزز Thunderbit قوة OpenClaw
- اقتراح الحقول بالذكاء الاصطناعي: يستطيع Thunderbit تحليل صفحة ويب تلقائيًا وتوصية بأفضل الأعمدة لاستخراجها — لا مزيد من التخمين في محددات CSS.
- تصدير فوري للبيانات: صدّر بياناتك المستخرجة مباشرة إلى Excel أو Google Sheets أو Airtable أو Notion بنقرة واحدة (مستندات Thunderbit).
- تدفق عمل هجين: استخدم OpenClaw للتنقل المعقد ومنطق الاستخراج، ثم مرّر النتائج إلى Thunderbit لتعيين الحقول وإثرائها وتصديرها.

مثال على تدفق عمل هجين
- استخدم المتصفح المُدار في OpenClaw أو مهارة Scrapling لاستخراج البيانات الخام من موقع ديناميكي.
- استورد النتائج إلى Thunderbit.
- انقر على «اقتراح الحقول بالذكاء الاصطناعي» لتعيين البيانات تلقائيًا.
- صدّر إلى التنسيق أو المنصة التي تفضّلها.
هذا المزيج يغيّر قواعد اللعبة للفرق التي تحتاج إلى القوة وسهولة الاستخدام معًا — مثل فرق عمليات المبيعات، ومحللي التجارة الإلكترونية، وكل من سئم التعامل مع جداول البيانات الفوضوية.
جرّب اقتراح الحقول بالذكاء الاصطناعي في Thunderbit
استكشاف الأخطاء وإصلاحها في الوقت الحقيقي: الأخطاء الشائعة في OpenClaw وكيفية حلها
حتى أفضل الأدوات تتعثر أحيانًا. إليك دليلًا سريعًا لتشخيص المشكلات الشائعة في استخراج OpenClaw وإصلاحها:
الأخطاء الشائعة
- مشكلات المصادقة: تحظر بعض المواقع الروبوتات أو تتطلب تسجيل دخول. استخدم المتصفح المُدار في OpenClaw أو اربطه مع Selenium لتدفقات تسجيل الدخول (docs.openclaw.ai).
- الطلبات المحجوبة: بدّل user agents، أو استخدم بروكسيات، أو خفّض معدل الطلبات لتجنّب الحظر.
- أخطاء التحليل: تحقّق مرة أخرى من محددات CSS/XPath؛ فقد تكون بنية الموقع قد تغيّرت.
- أخطاء الإضافات/المهارات: شغّل
openclaw plugins doctorلتشخيص المشكلات في الإضافات المثبتة (docs.openclaw.ai).
أوامر التشخيص
openclaw status– التحقق من حالة البوابة والأدوات.openclaw security audit– فحص الثغرات.openclaw browser --browser-profile openclaw status– التحقق من صحة أتمتة المتصفح.
موارد المجتمع
أفضل الممارسات لاستخراج OpenClaw بشكل موثوق وقابل للتوسع

هل تريد الحفاظ على سلاسة الاستخراج واستدامته؟ إليك قائمتي المرجعية:
- احترم robots.txt: لا تستخرج إلا ما يُسمح لك به.
- خفّض وتيرة الطلبات: تجنب إغراق المواقع بعدد كبير من الطلبات في الثانية.
- تحقق من المخرجات: راجع بياناتك دائمًا للتأكد من اكتمالها ودقتها.
- راقب الاستخدام: سجّل عمليات الاستخراج وانتبه للأخطاء أو الحظر.
- استخدم بروكسيات عند التوسع: بدّل عناوين IP لتفادي حدود المعدل.
- انشر في السحابة: للمهام الكبيرة، شغّل OpenClaw في آلة افتراضية أو بيئة حاويات.
- تعامل مع الأخطاء بسلاسة: أضف منطق إعادة المحاولة والبدائل إلى سكربتاتك.
| افعل | لا تفعل |
|---|---|
| استخدم الإضافات/المهارات الرسمية | ثبّت كودًا غير موثوق بشكل أعمى |
| شغّل فحوصات الأمان بانتظام | تجاهل تحذيرات الثغرات |
| اختبر في بيئة staging قبل الإنتاج | استخرج بيانات حساسة أو خاصة |
| وثّق تدفقات عملك | اعتمد على محددات ثابتة داخل الكود |
نصائح متقدمة: تخصيص OpenClaw وتوسيعه لاحتياجات فريدة
إذا كنت مستعدًا لتصبح مستخدمًا متقدمًا بحق، فإن OpenClaw يتيح لك بناء مهارات وإضافات مخصصة لمهام متخصصة.
تطوير مهارات مخصصة
- اتبع وثائق SDK الخاصة بمهارات OpenClaw لإنشاء أدوات استخراج جديدة.
- استخدم Python أو TypeScript بحسب ما ترتاح له.
- سجّل مهارتك في ClawHub لتسهيل المشاركة وإعادة الاستخدام.
ميزات متقدمة
- ربط المهارات معًا: امزج عدة خطوات استخراج (مثلًا: استخراج صفحة قائمة ثم زيارة كل صفحة تفاصيل).
- المتصفحات غير المرئية: استخدم Chromium المُدار من OpenClaw أو اربطه مع Playwright للمواقع الثقيلة بجافاسكريبت.
- تكامل وكلاء الذكاء الاصطناعي: صِل OpenClaw بخدمات ذكاء اصطناعي خارجية لتحليل البيانات أو إثرائها بذكاء أكبر.
معالجة الأخطاء وإدارة السياق
- ابنِ معالجة أخطاء قوية داخل مهاراتك (try/except في Python، وcallbacks للأخطاء في TypeScript).
- استخدم كائنات السياق لتمرير الحالة بين خطوات الاستخراج.
وللاستلهام، اطّلع على المهارات التي ساهم بها المجتمع وعلى مرجع API الخاص بـ Scrapling.
الخلاصة وأهم النقاط
لقد غطّينا الكثير — من تثبيت OpenClaw وتشغيل أول عملية استخراج، إلى بناء تدفقات عمل مؤتمتة وهجينة مع Thunderbit. وإليك ما آمل أن تتذكره:
- OpenClaw منصة مرنة وقوية ومفتوحة المصدر لاستخراج بيانات الويب، خصوصًا في المواقع المعقدة أو الديناميكية.
- منظومة الإضافات والمهارات فيه تمكّنك من التعامل مع كل شيء، من الجلب البسيط إلى استخراج متقدم متعدد الخطوات.
- دمج OpenClaw مع ميزات Thunderbit المدعومة بالذكاء الاصطناعي يجعل تعيين الحقول وتصدير البيانات وأتمتة سير العمل أمرًا سهلًا جدًا.
- ابقَ آمنًا وملتزمًا: راجع بيئتك، واحترم قواعد المواقع، وتحقق من بياناتك.
- لا تخف من التجربة: مجتمع OpenClaw نشط ومرحّب — انضم إليه، وجرّب مهارات جديدة، وشارك نجاحاتك.
إذا كنت تبحث عن رفع كفاءة الاستخراج لديك أكثر، فـ Thunderbit هنا لمساعدتك. وإذا أردت مواصلة التعلم، فاطّلع على مدونة Thunderbit لمزيد من الشروحات المتعمقة والأدلة العملية.
استخراج موفق — وليصِبِ المحدد دائمًا هدفه.
الأسئلة الشائعة
1. ما الذي يميز OpenClaw عن أدوات استخراج الويب التقليدية مثل BeautifulSoup أو Scrapy؟
يُبنى OpenClaw كبوابة وكلاء مع أدوات معيارية، ودعم متصفح مُدار، ونظام إضافات/مهارات. وهذا يجعله أكثر مرونة للمواقع الديناميكية أو الثقيلة بجافاسكريبت أو الغنية بالصور، وأسهل في أتمتة تدفقات العمل من البداية إلى النهاية مقارنةً بالأطر التقليدية المعتمدة على كثافة الكود (docs.openclaw.ai).
2. هل يمكنني استخدام OpenClaw إذا لم أكن مطورًا؟
نعم! مسار الإعداد ومنظومة الإضافات في OpenClaw مناسبان للمبتدئين. وللمهام الأكثر تعقيدًا، يمكنك استخدام المهارات التي يبنيها المجتمع أو دمج OpenClaw مع أدوات بدون كود مثل Thunderbit لتسهيل تعيين الحقول والتصدير.
3. كيف أستكشف الأخطاء الشائعة في OpenClaw وأصلحها؟
ابدأ بـ openclaw status و openclaw security audit. ولمشكلات الإضافات، استخدم openclaw plugins doctor. راجع الوثائق الرسمية ومشكلات GitHub للحصول على حلول للمشكلات الشائعة.
4. هل استخدام OpenClaw لاستخراج الويب آمن وقانوني؟
كما هو الحال مع أي أداة استخراج، احترم دائمًا شروط خدمة الموقع وملف robots.txt. OpenClaw مفتوح المصدر ويعمل محليًا، لكن عليك مراجعة الإضافات أمنيًا وتجنّب استخراج البيانات الحساسة أو الخاصة دون إذن (github.com).
5. كيف يمكنني دمج OpenClaw مع Thunderbit للحصول على نتائج أفضل؟
استخدم OpenClaw لمنطق الاستخراج المعقد، ثم استورد البيانات الخام إلى Thunderbit. ستقوم ميزة اقتراح الحقول بالذكاء الاصطناعي في Thunderbit بتعيين بياناتك تلقائيًا، ويمكنك التصدير مباشرة إلى Excel أو Google Sheets أو Notion أو Airtable — ما يجعل سير عملك أسرع وأكثر موثوقية (مستندات Thunderbit).
هل تريد أن ترى كيف يمكن لـ Thunderbit الارتقاء باستخراجك؟ نزّل إضافة Chrome وابدأ اليوم ببناء تدفقات عمل أذكى وهجينة. ولا تنسَ الاطلاع على قناة Thunderbit على YouTube للحصول على شروحات ونصائح عملية.
جرّب Thunderbit لاستخراج ويب أذكى Get Started Free
اعرف المزيد




