
The web isn’t just a digital playground anymore—it’s the world’s biggest data warehouse, and everyone from sales teams to market analysts is racing to tap into it. But let’s be honest: trying to gather web data by hand is about as fun as assembling IKEA furniture without instructions (and with twice as many leftover screws).
As businesses rely more on real-time market intelligence, competitive pricing, and lead generation, the need for efficient, reliable data crawling tools has never been greater. In fact, nearly to drive decisions, and the global web scraping market is on track to .
If you’re tired of copy-pasting, missing out on fresh leads, or just want to see what’s possible when you let automation do the heavy lifting, you’re in the right place. I’ve spent years building and testing web extraction tools (and yes, leading the team at ), so I know firsthand how the right tool can turn hours of grunt work into a two-click breeze. Whether you’re a non-coder looking for instant results or a developer who wants full control, this list of the top 10 best data crawling tools will help you find your perfect match.
Why Choosing the Right Data Crawling Tools Matters
Let’s get real: the difference between a good data crawling tool and a mediocre one isn’t just convenience—it’s a direct line to business growth. When you automate web extraction, you’re not just saving time (though one G2 reviewer reported ), you’re also reducing errors, unlocking new opportunities, and making sure your team is always working with the freshest, most accurate data. Manual research is slow, error-prone, and often outdated by the time you’re done. With the right tool, you can monitor competitors, track prices, or build lead lists in minutes—not days.
Case in point: a beauty retailer used web scraping to monitor competitor stock and pricing, . That’s the kind of impact you just can’t get with spreadsheets and elbow grease.
How We Evaluated the Best Data Crawling Tools
With so many options out there, picking the right data crawling tool can feel like speed-dating at a tech conference. Here’s the criteria I used to separate the best from the rest:
- Ease of Use: Can you get started without a PhD in Python? Is there a visual interface or AI assistance for non-coders?
- Automation Capabilities: Does it handle pagination, subpages, dynamic content, and scheduling? Can it run in the cloud for big jobs?
- Pricing and Scalability: Is there a free tier or affordable entry plan? How does the cost scale as your data needs grow?
- Feature Set and Integration: Can you export to Excel, Google Sheets, or via API? Are there templates, scheduling, or built-in data cleaning features?
- Best For: Who’s the tool really designed for—business users, developers, or enterprise teams?
I’ve included a quick comparison table at the end, so you can see how each tool stacks up.
Now, let's dive into the top 10 best data crawling tools for efficient web extraction in 2026.
1. Thunderbit
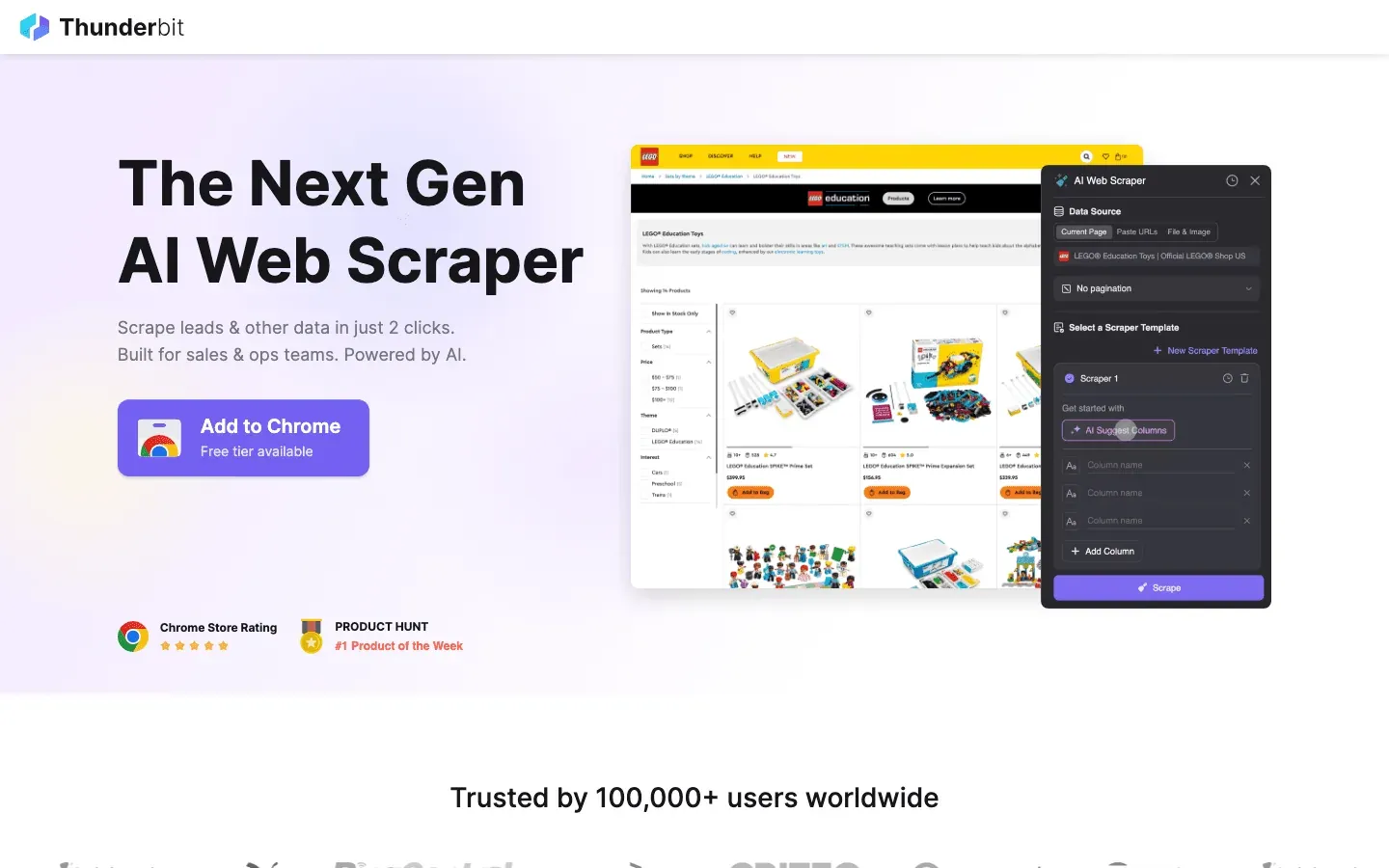 is my go-to recommendation for anyone who wants data crawling to be as easy as ordering takeout. Built as an AI-powered Chrome extension, Thunderbit is all about 2-click scraping: just hit “AI Suggest Fields” and let the AI figure out what’s on the page, then click “Scrape” to grab the data. No coding, no fiddling with selectors—just instant results.
is my go-to recommendation for anyone who wants data crawling to be as easy as ordering takeout. Built as an AI-powered Chrome extension, Thunderbit is all about 2-click scraping: just hit “AI Suggest Fields” and let the AI figure out what’s on the page, then click “Scrape” to grab the data. No coding, no fiddling with selectors—just instant results.
What makes Thunderbit a favorite for sales, marketing, and ecommerce teams? It’s designed for real-world business workflows:
- AI Suggest Fields: The AI reads the page and recommends the best columns to extract—names, prices, emails, you name it.
- Subpage Scraping: Need more details? Thunderbit can automatically visit each subpage (like product details or LinkedIn profiles) and enrich your table.
- Instant Export: Push your data straight to Excel, Google Sheets, Airtable, or Notion. All exports are free.
- One-Click Templates: For popular sites (Amazon, Zillow, Instagram), use instant templates for even faster results.
- Free Data Export: There’s no paywall for getting your data out.
- Scheduled Scraping: Set up recurring jobs in plain English (“every Monday at 9am”)—perfect for price monitoring or weekly lead updates.
Thunderbit uses a credit system (1 credit = 1 row), with a for up to 6 pages (or 10 with a trial boost). Paid plans start at $15/month for 500 credits, making it affordable for teams of any size.
If you want to see how Thunderbit works in action, check out our or . It’s the tool I wish I had back when I was drowning in manual data entry.
2. Octoparse
 is a heavyweight in the data crawling world, especially for enterprise users who need serious power. It offers a visual desktop interface (Windows and Mac) where you can point-and-click to build extraction workflows—no coding required. But don’t let the friendly UI fool you: under the hood, Octoparse handles logins, infinite scroll, rotating proxies, and even CAPTCHA solving.
is a heavyweight in the data crawling world, especially for enterprise users who need serious power. It offers a visual desktop interface (Windows and Mac) where you can point-and-click to build extraction workflows—no coding required. But don’t let the friendly UI fool you: under the hood, Octoparse handles logins, infinite scroll, rotating proxies, and even CAPTCHA solving.
- 500+ Pre-Built Templates: Start fast with templates for Amazon, Twitter, LinkedIn, and more.
- Cloud-Based Scraping: Run jobs on Octoparse’s servers, schedule tasks, and scale up for big projects.
- API Access: Integrate scraped data directly into your business apps or databases.
- Advanced Automation: Handles dynamic content, pagination, and multi-step workflows.
The free tier covers 10 tasks plus a generous 50,000-row monthly export cap, so it's a real working tier — not just a teaser. Paid plans start at $69/month for Standard (annual billing; ~$82/month if you pay month-to-month) and $249/month for Professional. The learning curve is steeper than Thunderbit's, but if you need to scrape thousands of pages reliably and want cloud execution, Octoparse is still one of the longer-running options worth a serious look. Pricing verified against on 2026-05-13.
3. Scrapy
 is the gold standard for developers who want full control over their data crawling projects. It’s an open-source Python framework that lets you code custom spiders (crawlers) for any website. If you can dream it, you can build it with Scrapy.
is the gold standard for developers who want full control over their data crawling projects. It’s an open-source Python framework that lets you code custom spiders (crawlers) for any website. If you can dream it, you can build it with Scrapy.
- Full Programmability: Write Python code to define exactly how to crawl and parse any site.
- Asynchronous & Fast: Handles thousands of pages in parallel for large-scale projects.
- Extensible: Add middleware for proxies, headless browsers, or custom logic.
- Strong Community: Tons of tutorials, plugins, and support for tricky scraping scenarios.
Scrapy is free and open-source, but it does require programming skills. If you have a technical team or want to build a custom pipeline, Scrapy is hard to beat. For non-coders, though, it’s a steep hill to climb.
4. ParseHub
 is a visual, no-code web scraping tool that’s perfect for non-coders facing complex websites. Its point-and-click interface lets you select elements, define actions, and build scraping workflows—even for sites with dynamic content or tricky navigation.
is a visual, no-code web scraping tool that’s perfect for non-coders facing complex websites. Its point-and-click interface lets you select elements, define actions, and build scraping workflows—even for sites with dynamic content or tricky navigation.
- Visual Workflow Builder: Click to select data, set up pagination, and handle pop-ups or dropdowns.
- Handles Dynamic Content: Works with JavaScript-heavy sites and interactive pages.
- Cloud Runs & Scheduling: Run scrapes in the cloud and schedule recurring jobs.
- Export to CSV, Excel, or via API: Easy integration with your favorite tools.
ParseHub offers a free plan (5 projects), with paid plans starting at . It’s a bit pricier than some competitors, but the visual approach makes it accessible for analysts, marketers, and researchers who need more than a basic Chrome extension.
5. Apify
 is both a platform and a marketplace for web crawling. It offers a huge library of pre-built “Actors” (ready-made scrapers) for popular sites, plus the ability to build and run your own custom crawlers in the cloud.
is both a platform and a marketplace for web crawling. It offers a huge library of pre-built “Actors” (ready-made scrapers) for popular sites, plus the ability to build and run your own custom crawlers in the cloud.
- 5,000+ Ready-Made Actors: Instantly scrape Google Maps, Amazon, Twitter, and more.
- Custom Scripting: Developers can use JavaScript or Python to build advanced crawlers.
- Cloud Scaling: Run jobs in parallel, schedule tasks, and manage data in the cloud.
- API & Integration: Plug results into your apps, workflows, or data pipelines.
Apify gives you $5 of free platform credit to start, then steps up to Starter at $29/month, Scale at $199/month, and Business at $999/month — each tier is "platform credit + pay-as-you-go for compute units," so usage really does drive the bill. There's a bit of a learning curve, but if you want both plug-and-play actors and the ability to write your own crawlers in JS or Python, Apify is one of the strongest options on this list. Pricing verified against on 2026-05-13.
6. Data Miner
 is a Chrome extension built for quick, template-based data crawling. It’s perfect for business users who want to grab data from tables or lists without any setup.
is a Chrome extension built for quick, template-based data crawling. It’s perfect for business users who want to grab data from tables or lists without any setup.
- Huge Template Library: Over a thousand recipes for common sites (LinkedIn, Yelp, etc.).
- Point-and-Click Extraction: Select a template, preview the data, and export instantly.
- Browser-Based: Works with your current session—great for scraping behind logins.
- Export to CSV or Excel: Get your data into a spreadsheet in seconds.
The covers 500 pages/month, with paid plans from $20/month. It’s best for small, one-off tasks or when you need data right now—just don’t expect it to handle massive jobs or complex automation.
7. Import.io
 is an enterprise-grade platform for organizations that need continuous, reliable web data integration. It’s more than just a crawler—it’s a managed service that delivers clean, structured data directly into your business systems.
is an enterprise-grade platform for organizations that need continuous, reliable web data integration. It’s more than just a crawler—it’s a managed service that delivers clean, structured data directly into your business systems.
- No-Code Extraction: Visual setup for defining what data to pull.
- Real-Time Data Feeds: Stream data into dashboards, analytics tools, or databases.
- Compliance & Reliability: Handles IP rotation, anti-bot measures, and legal compliance.
- Managed Services: Import.io’s team can set up and maintain your scrapers.
Pricing is , with a 14-day free trial for the SaaS platform. If your business depends on always-fresh web data (think retail, finance, or market research), Import.io is worth a look.
8. WebHarvy
 is a desktop-based scraper for Windows users who want a point-and-click solution without a subscription. It’s especially popular with small businesses and individuals who prefer a one-time purchase.
is a desktop-based scraper for Windows users who want a point-and-click solution without a subscription. It’s especially popular with small businesses and individuals who prefer a one-time purchase.
- Visual Pattern Detection: Click on data elements, and WebHarvy auto-detects repeating patterns.
- Handles Text, Images, and More: Extracts all common data types, including emails and URLs.
- Pagination & Scheduling: Navigate multi-page sites and set up scheduled scrapes.
- Export to Excel, CSV, XML, JSON, or SQL: Flexible output for any workflow.
A single-user license is , making it a cost-effective choice for regular use—just note it’s Windows-only.
9. Mozenda
 is a cloud-based data crawling platform built for business operations and ongoing data needs. It combines a desktop designer (Windows) with powerful cloud execution and automation.
is a cloud-based data crawling platform built for business operations and ongoing data needs. It combines a desktop designer (Windows) with powerful cloud execution and automation.
- Visual Agent Builder: Design extraction routines with a point-and-click interface.
- Cloud Scaling: Run multiple agents in parallel, schedule jobs, and manage data centrally.
- Data Management Console: Combine, filter, and clean datasets after extraction.
- Enterprise Support: Dedicated account managers and managed services for large teams.
Mozenda's self-serve Pilot plan is $500/month (5,000 processing credits, 10 agents, 10GB storage), and Enterprise is quote-only. There's also a 14-day free Trial tier with 500 credits if you want to kick the tires before committing. Mozenda is best for companies that want reliable, repeatable web data baked into daily operations — pricing is real and the platform expects you to take it seriously. Pricing verified against on 2026-05-13.
10. BeautifulSoup
 is the classic Python library for parsing HTML and XML. It’s not a full crawler, but it’s beloved by developers for small-scale, custom scraping projects.
is the classic Python library for parsing HTML and XML. It’s not a full crawler, but it’s beloved by developers for small-scale, custom scraping projects.
- Simple HTML Parsing: Easily extract data from static web pages.
- Works with Python Requests: Combine with other libraries for fetching and crawling.
- Flexible & Lightweight: Perfect for quick scripts or educational projects.
- Huge Community: Tons of tutorials and Stack Overflow answers.
BeautifulSoup is , but you’ll need to write code and handle crawling logic yourself. It’s best for developers or learners who want to understand the nuts and bolts of web scraping.
Comparison Table: Data Crawling Tools at a Glance
| Tool | Ease of Use | Automation Level | Pricing | Export Options | Best For |
|---|---|---|---|---|---|
| Thunderbit | Very easy, no-code | High (AI, subpages) | Free trial, from $15/mo | Excel, Sheets, Airtable, Notion, CSV | Sales, marketing, ecommerce, non-coders |
| Octoparse | Moderate, visual UI | Very high, cloud | Free, $83–$299/mo | CSV, Excel, JSON, API | Enterprises, data teams, dynamic sites |
| Scrapy | Low (Python req’d) | High (customizable) | Free, open-source | Any (via code) | Developers, large-scale custom projects |
| ParseHub | High, visual | High (dynamic sites) | Free, from $189/mo | CSV, Excel, JSON, API | Non-coders, complex web structures |
| Apify | Moderate, flexible | Very high, cloud | Free, $29–$999/mo | CSV, JSON, API, cloud storage | Devs, businesses, ready-made or custom actors |
| Data Miner | Very easy, browser | Low (manual) | Free, $20–$99/mo | CSV, Excel | Quick, one-off extractions, small datasets |
| Import.io | Moderate, managed | Very high, enterprise | Custom, volume-based | CSV, JSON, API, direct integration | Enterprises, continuous data integration |
| WebHarvy | High, desktop | Medium (scheduling) | $129 one-time | Excel, CSV, XML, JSON, SQL | SMBs, Windows users, regular scraping |
| Mozenda | Moderate, visual | Very high, cloud | $250–$450+/mo | CSV, Excel, JSON, cloud, DB | Ongoing, large-scale business operations |
| BeautifulSoup | Low (Python req’d) | Low (manual coding) | Free, open-source | Any (via code) | Developers, learners, small custom scripts |
How to Choose the Right Data Crawling Tool for Your Team
Picking the best data crawling tool isn’t about finding the “most powerful”—it’s about finding the right fit for your team’s skills, needs, and budget. Here’s my quick advice:
- Non-coders or business users: Start with Thunderbit, ParseHub, or Data Miner for instant results and easy setup.
- Enterprise or large-scale needs: Look at Octoparse, Mozenda, or Import.io for automation, scheduling, and support.
- Developers or custom projects: Scrapy, Apify, or BeautifulSoup offer full control and flexibility.
- Budget-conscious or one-off jobs: WebHarvy (Windows) or Data Miner (browser) are cost-effective and simple.
Always test your top choices with a free trial on your actual target sites—what works on one site might not work on another. And don’t forget to think about integration: if you need your data in Sheets, Notion, or a database, make sure your tool supports it out of the box.
Conclusion: Unlocking Business Value with the Best Data Crawling Tools
Web data is the new oil, but only if you have the right machinery to extract and refine it. With modern data crawling tools, you can turn hours of manual research into minutes of automated insight—fueling smarter sales, sharper marketing, and more agile operations. Whether you’re building lead lists, tracking competitors, or just tired of copy-pasting, there’s a tool on this list that can make your life a whole lot easier.
So, take a look at your team’s needs, try out a few of these tools, and see how much more you can accomplish when you let automation do the heavy lifting. And if you want to see what AI-powered, 2-click scraping looks like, . Happy crawling—and may your data always be fresh, structured, and ready for action.
FAQs
1. What is a data crawling tool, and why do I need one?
A data crawling tool automates the process of extracting information from websites. It saves time, reduces errors, and helps teams gather up-to-date data for sales, marketing, research, and operations—far more efficiently than manual copy-pasting.
2. Which data crawling tool is best for non-technical users?
Thunderbit, ParseHub, and Data Miner are top picks for non-coders. Thunderbit stands out for its 2-click AI-powered workflow, while ParseHub offers a visual approach for more complex sites.
3. How do pricing models differ among data crawling tools?
Pricing varies widely: some tools (like Thunderbit and Data Miner) offer free tiers and affordable monthly plans, while enterprise platforms (like Import.io and Mozenda) use custom or volume-based pricing. Always check if the tool’s cost matches your data needs.
4. Can I use these tools for ongoing, scheduled data extraction?
Yes—tools like Thunderbit, Octoparse, Apify, Mozenda, and Import.io support scheduled or recurring crawls, making them ideal for ongoing price monitoring, lead generation, or market research.
5. What should I consider before choosing a data crawling tool?
Consider your team’s technical skills, the complexity of the sites you need to crawl, data volume, integration needs, and budget. Test a few tools with your real-world tasks before committing to a paid plan.
For more deep dives and practical guides, check out the .
Learn More