Substack 爬蟲

深受領先企業專業人士信賴











使用 Thunderbit 解鎖 Substack 資料
將 Substack 資料直接傳送到您的應用程式
別再手動複製貼上 Substack 的出版物資訊,例如作者名稱、文章標題與訂閱者數。使用 Thunderbit,只要一次點擊,就能把擷取到的資料直接送到 Google Sheets、Notion 或 Airtable。無需繁瑣的人工操作,就能分析出版物趨勢與內容成效。
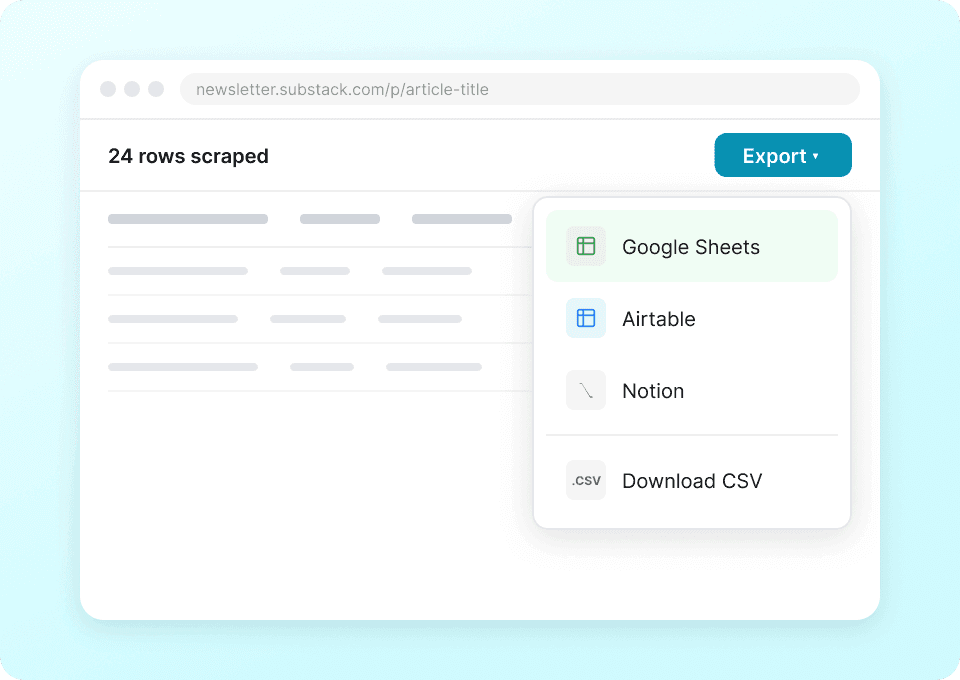
一個爬蟲,搞定 Substack 與更多網站
別被迫為每個網站都使用不同的爬蟲。Thunderbit 開箱即用就能處理 Substack,並內建超過 50 種其他熱門平台的預建範本。先擷取出版物描述、文章內容等資料,再用同一個工具蒐集其他網站的資料。
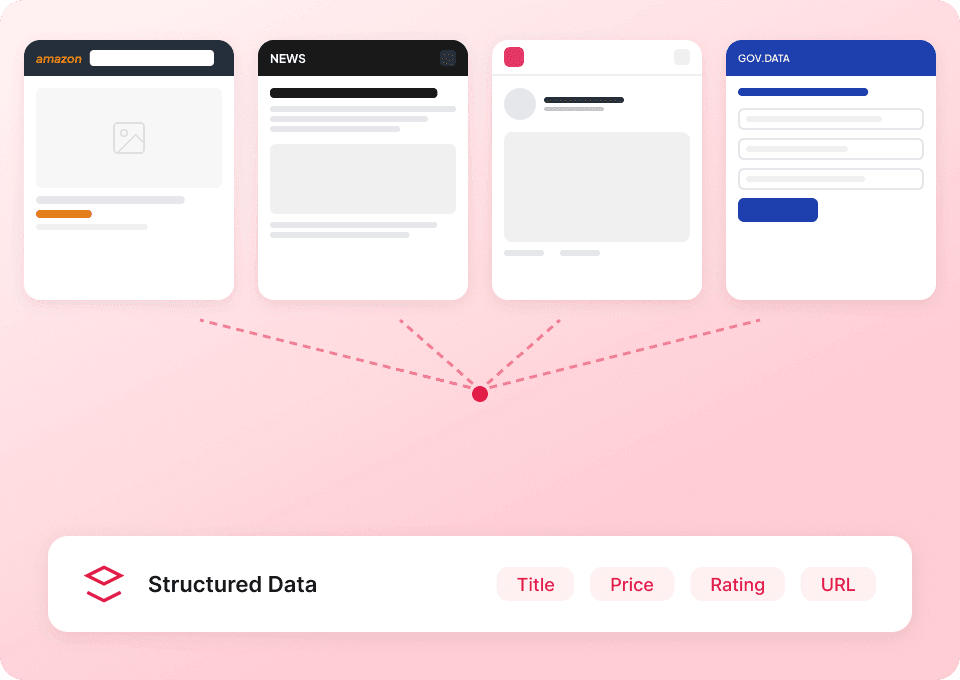
取得完整的 Substack 全貌
Substack 的出版物列表頁通常只顯示摘要。Thunderbit 會自動前往每個文章子頁面擷取完整內容,讓您獲得完整資料集。一次取得完整的文章標題、作者名稱、出版物名稱與文章內容。
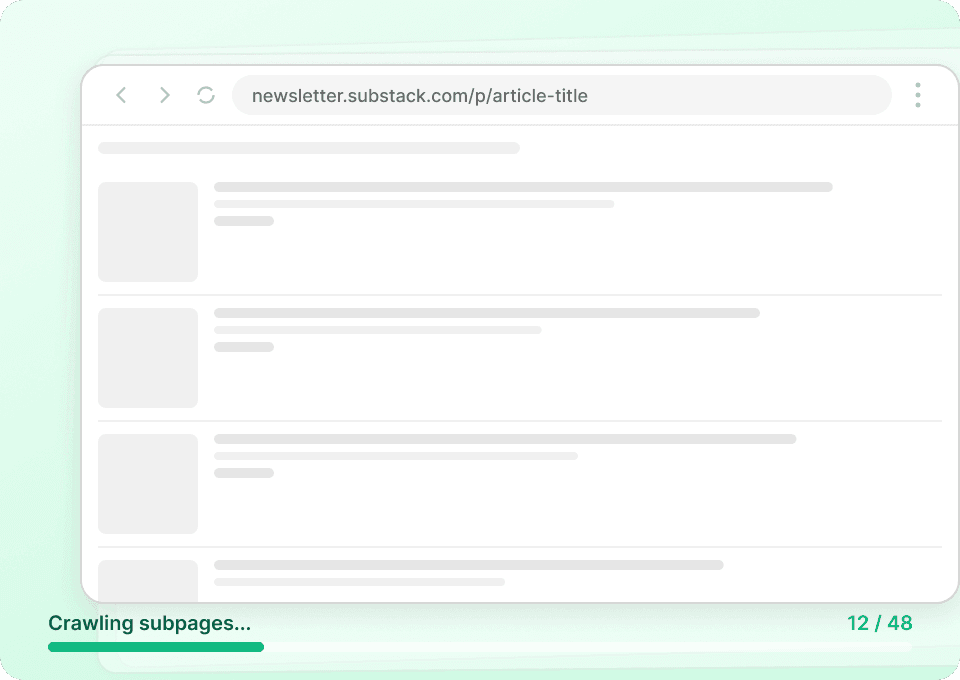
擷取 Substack 總是卡關嗎?
看看為什麼 Thunderbit 在 Substack 資料擷取上勝過傳統爬蟲。
傳統爬蟲
舊式做法Thunderbit
更聰明的方法別只聽我們說
看看我們的使用者怎麼說 Thunderbit。






常見問題
相關 應用場景
探索 Thunderbit 網頁爬蟲的更多應用場景。

UNIQLO 網頁爬蟲
只要 2 次點擊,就能透過 Thunderbit 的 Chrome 擴充功能擷取 Uniqlo 商品資料,例如名稱、價格與可用尺寸。
了解更多 ->PeopleWhiz 爬蟲
Thunderbit PeopleWhiz 爬蟲讓您透過 AI 欄位建議,從 PeopleWhiz 搜尋結果與個人檔案中擷取資料。快速蒐集姓名、聯絡資訊、地點等內容,適用於研究、行銷或開發潛在客戶。將 PeopleWhiz 資料迅速且高效地轉換為結構化資料集。
了解更多 ->
Amarillas.com 爬蟲
Thunderbit Amarillas.com 爬蟲可協助你從 Amarillas.com 擷取結構化資料,包括汽車旅館與餐廳等商家資訊。透過 AI 智慧欄位建議,快速收集商家名稱、地址、聯絡電話、評分與評論,無論是市場調查、行銷推廣或名單開發都能輕鬆應用。
了解更多 ->
UpCity 爬蟲
Thunderbit UpCity 爬蟲可協助你從 UpCity 的廣告代理商列表與服務評論中擷取資料。透過 AI 智能欄位建議,快速收集代理商名稱、地點、評分、聯絡方式及詳細評論內容,方便分析與研究。非常適合行銷人員、研究者及企業主取得結構化的 UpCity 資料。
了解更多 ->
白頁爬蟲
Thunderbit White Pages 爬蟲結合 AI 智能欄位建議,讓你輕鬆從 White Pages 電話與商業名錄中擷取資料。無論是名單開發、行銷推廣或市場研究,只需幾下點擊,即可收集姓名、電話、地址與網站網址。
了解更多 ->Tradera 爬蟲
Thunderbit Tradera 爬蟲讓你輕鬆擷取 Tradera 刊登與商品頁面的資料。透過 AI 智能欄位建議,快速收集商品名稱、價格、分類、圖片與描述,方便分析或庫存管理。非常適合電商賣家、收藏家及研究人員,輕鬆獲取結構化的 Tradera 數據。
了解更多 ->準備好加速你的資料擷取了嗎?
加入已使用 Thunderbit 自動化網頁抓取流程的 100,000+ 專業人士行列。
免費試用可提供 8 個網頁的無限額度。