

網頁爬蟲違法嗎?這大概是我每週都會從創辦人、行銷人員和資料控那裡聽到的百萬美元問題。
如今, 所有網路流量中有 51% 來自機器人——這是自動化流量首次超過真人活動——而且其中很大一部分是為了商業情報、銷售和 AI 訓練而進行的網頁爬蟲。難怪大家都在努力搞清楚法律界線到底畫在哪裡。
有一天,您會看到新聞標題說法院裁定抓取公開資料沒問題;隔天,監管機關又在警告社群媒體上的「非法」資料蒐集。就連像我這樣每天在 Thunderbit 開發 AI 網頁爬蟲工具的人,也會覺得有點混亂。
所以,網頁爬蟲到底違法嗎?答案不是簡單的是或否。這取決於您抓取的是什麼、從哪裡抓、如何使用這些資料,以及您所在國家的法律怎麼說。
在這篇深入解析裡,我會拆解法律環境、破解一些常見迷思,並分享實用建議(外加幾個實戰經驗),幫助您在合規前提下運作——不論您是獨立創業者,還是財富 500 大企業的資料團隊。
網頁爬蟲與法律:界線清楚嗎?
如果您期待一句話就能回答,那我先幫您省點時間:法律並沒有替網頁爬蟲畫出一條明確而清楚的界線。
相反地,這是一套彼此交疊的規範拼圖——資料所有權、隱私、智慧財產、反駭客法,以及那些惹人頭痛的服務條款(ToS)。每一項都可能派上用場,而答案通常要看您的具體情境而定 (multilogin.com)。
先來拆解三個主要法律面向:
- 資料所有權: 一般來說,事實與公開資訊(像是價格或電話號碼)不受著作權保護。但創作內容(文章、圖片)與專有資料庫可能受到保護——尤其在歐盟,還有「資料庫權」這回事 (cliffordchance.com)。
- 隱私: 現代隱私法(例如歐洲的 GDPR、中國的個資法 PIPL)會把個人資料視為受管制資產——即使這些資料是公開貼出的。未具合法依據就抓取姓名、電子郵件或社群檔案,可能會惹上麻煩 (ico.org.uk)。
- 合約(服務條款): 許多網站在 ToS 中明確禁止爬蟲。雖然 ToS 不是法律,但法院可能把它視為具有約束力的合約。違反條款可能導致訴訟,某些情況下,若您繞過技術阻擋,甚至可能觸發反駭客法規 (cliffordchance.com)。
所以,網頁爬蟲違法嗎?有時是,有時不是,而且很多時候答案是「要看情況」。魔鬼就藏在細節裡。
各地法律觀點比較:美國、歐盟、英國、中國
以下這張快速表格可以幫助您了解主要地區如何看待網頁爬蟲:
| 地區 | 公開資料爬取 | 個人/私密資料爬取 | 執法與重點 |
|---|---|---|---|
| 美國 | 一般允許抓取公開資料(見 hiQ v. LinkedIn)。違反 ToS 可能導致民事訴訟。 | 若您繞過登入或濫用個資,則受限/違法。州法(如 CCPA)也可能適用。 | 停止侵害通知函、IP 封鎖、訴訟。若您繞過技術防線,CFAA 可能適用。 |
| 歐盟 | 對非個人公開資料,附條件允許。資料庫權可能適用。歐盟 AI 法案(2026)新增 AI 訓練資料透明度要求。 | 受 GDPR 嚴格規範——即使是公開的個人資料也需要合法依據。 | 資料保護機關可因隱私違規開罰。著作權/資料庫權也會執法。歐盟 AI 法案禁止為 AI 抓取人臉影像。 |
| 英國 | 與歐盟相近。公開的非個人資料可以抓取,但必須尊重資料權與合約。 | 對個資要求嚴格——適用英國 GDPR。Computer Misuse Act 會將未經授權的存取列為刑事犯罪。 | ICO 可因資料保護違規處罰。法院也可能強制執行 ToS。 |
| 中國 | 管制嚴格。公開的非個人資料可供內部使用而抓取,但整體環境仍偏保守。 | 高度受限——PIPL 要求個人資料需取得同意。反不正當競爭法也適用。 | 大規模爬取可能引發刑事案件。法院會用不正當競爭法制止未授權爬取。 |
網頁爬蟲違法嗎?需要考慮的關鍵法律因素
那到底是什麼決定您的爬蟲專案合法還是有風險?以下是幾個最重要的因素:
- 公開資料 vs. 私密資料: 抓取公開網頁上任何人都看得到的資料,一般來說比較安全。若要抓登入後內容、付費牆後內容,或受技術保護的資料?那很可能違法 (thunderbit.com)。
- 資料性質: 個資(姓名、電子郵件、檔案)會觸發隱私法。受著作權保護的內容(文章、圖片)不能整批複製。純事實資料(價格、天氣)通常較無爭議 (oxylabs.io)。
- 使用目的: 內部分析或研究通常比重新發布或出售爬取資料更容易被接受。若您用爬取的資料直接和來源網站競爭,那幾乎就是等著被告 (thunderbit.com)。
- 是否遵守網站規則: 一定要查看 robots.txt 和 ToS。robots.txt 不具法律約束力,但尊重它是最佳實務。違反 ToS 可能導致民事訴訟,甚至更嚴重的後果 (promptcloud.com)。
- 技術措施: 以類似真人的速度抓取,且不要繞過安全機制,這點非常重要。狂轟伺服器或閃避 CAPTCHA,可能就踩進駭客行為的紅線 (cliffordchance.com)。
2024–2026 發生了什麼:重要判例與法規變化
自 2023 年以來,網頁爬蟲的法律環境出現了巨大變化。以下是每位爬蟲實作者都該知道的發展:
重要法院判決
-
Meta v. Bright Data(2024): 美國聯邦法院 裁定 Meta 的服務條款不禁止未登入使用者抓取公開資料。法官認定,「訪客」不會被視為「使用者」,除非他們有帳戶。Meta 隨後撤回了其餘主張。這是公開資料爬取的一大里程碑勝利。
-
X Corp v. Bright Data(2024): Twitter(現為 X)在類似訴訟中敗訴,再次強化了同一原則:未登入即可存取的公開資料,抓取並不構成 ToS 違反,因為爬蟲從未同意那些條款。
-
Reddit v. Perplexity AI(2025 年 10 月): Reddit 起訴 Perplexity AI 與多家爬蟲服務提供商,援引 DMCA 並指控其繞過反機器人系統。這顯示一項新的法律策略:平台正轉向 著作權與反規避主張,而不是 CFAA。
-
NYT v. OpenAI(2025 年 3 月): 聯邦法官 允許《紐約時報》對 OpenAI 的著作權案件繼續進行,駁回了 OpenAI 的撤訴動議。這可能會成為一項重大先例,影響「抓取內容來訓練 AI 模型是否屬於合理使用」的判斷。
-
Anthropic 和解案(2025 年 9 月): Anthropic 同意支付 15 億美元,和解一起美國著作權集體訴訟,該案涉及使用受著作權保護的文本來訓練其 AI 模型——這說明「為 AI 而抓取」的成本是真實存在的。
大趨勢:從 CFAA 轉向合約法與著作權法
趨勢很明顯:CFAA(美國電腦詐欺與濫用法)作為對付公開資料爬蟲的武器,影響力正在下降。 那些試圖用 CFAA 對付公開資料爬取的公司——Meta、X、LinkedIn——大多沒有成功。法律戰場反而正在轉向:
- 合約法(違反 ToS——但法院表示,未簽署/未同意條款的非使用者不受約束)
- 著作權主張(尤其是 AI 訓練資料)
- 反規避法規(DMCA 第 1201 條)
對爬蟲實作者來說,這代表法律風險並沒有消失,只是換了位置。
監管變化
- CCPA 2026 更新: 加州修訂後的 CCPA 規範 於 2026 年 1 月 1 日生效,新增自動化決策技術(ADMT)、風險評估與資料經紀商義務等規則。
- 美國新州隱私法: 印第安納、肯塔基與羅德島已在 2026 年通過全面性隱私法。
- 歐盟 AI 法案: 完整執法將於 2026 年 8 月 2 日開始——要求 AI 開發者揭露訓練資料來源、尊重著作權退出機制,並禁止為 AI 系統抓取人臉影像。
- 《出版者 AI 責任法案》(2026 年 2 月): 這是一項提案中的美國法案,將要求 AI 公司在抓取出版者內容前先取得許可並支付費用。
主要平台的爬取政策:您需要知道什麼
不是每個網站都用同樣方式看待爬蟲。以下是各大平台的整理:它們允許什麼、阻擋什麼,以及法院怎麼說:
| 平台 | ToS 對爬蟲的規定 | 技術防禦 | 法律執行 | 實務上較安全的是什麼 |
|---|---|---|---|---|
| Google(搜尋與地圖) | ToS 禁止自動化存取。Maps Platform 有明確的「No Scraping」條款。 | SearchGuard JS 挑戰、CAPTCHA、速率限制。2025 年更新 robots.txt 以封鎖 AI 爬蟲。 | 2025 年 12 月以 DMCA 對爬蟲提告。積極封鎖 AI 爬蟲(Anthropic、Meta、OpenAI)。 | 從法律角度來看,抓取公開的 Google 地圖商家資料有 دفاع空間(hiQ 先例),但技術封鎖幾乎可預期。盡可能使用官方 API。 |
| Amazon | 使用條款明確禁止任何爬取(「no robot, spider, scraper, or other automated means」)。 | 強力機器人偵測、CAPTCHA、IP 封鎖。robots.txt 封鎖除 Googlebot/Bingbot 外的所有機器人。自 2025 年起也明確封鎖 AI 爬蟲。 | 2025 年 11 月起訴 Perplexity AI。經常發送停止侵害通知函。2026 年 3 月更新 BSA,加入 AI 代理規則。 | 公開產品資料(價格、商品列表)在美國法律下屬於可抓取的事實資料,但 Amazon 反制非常強。請限速,並避免抓取個資。 |
| ToS 禁止爬取;存取服務需使用者同意。 | 多數個人檔案資料需登入,並有反機器人偵測與速率限制。 | hiQ 案確認抓取公開個人檔案不違反 CFAA,但 LinkedIn 在使用假帳號時,以合約/不正當競爭主張勝訴。 | 可見且不需登入的公開個人檔案,法律上較站得住腳。絕不要建立假帳號或抓取登入後資料。 | |
| Meta(Facebook 與 Instagram) | ToS 禁止爬取;登入與未登入資料適用不同規則。 | 多數內容需登入,並有進階機器人偵測。 | 2024 年敗給 Bright Data——法院裁定 ToS 不適用於未登入的爬蟲。其餘主張已撤回。 | 未登入即可看到的公開資料(商家頁面、公開貼文)相對安全。絕不要抓取私密個人檔案或登入後內容。 |
| X(Twitter) | 2023 年更新 ToS,禁止未經書面同意的所有爬取與爬行。並取消舊的 robots.txt 例外。 | robots.txt 封鎖所有爬蟲(Disallow: /)。Cloudflare Turnstile 挑戰。嚴格速率限制(每小時 300 次)。IP 信譽評分。 | 公開資料部分輸給 Bright Data,但在技術存取上限制非常強。 | 公開推文與檔案在法律上較有防守空間,但到 2026 年,X 的技術防線是最難突破的之一。若沒有高級代理基礎設施,很可能被擋。 |
重點結論: 法院一貫認為,抓取公開可見且未登入的資料,不會違反 CFAA。但平台仍可透過合約法、著作權或反規避理由來追究您——而且他們也會用技術障礙讓您很難過。請務必負責任地抓取。
AI 訓練資料與網頁爬蟲:新的法律前線
如果您有留意 2026 年的新聞,您會知道:為訓練 AI 模型而抓取資料,已經變成最火熱的法律戰場。現況如下:
- 著作權訴訟接連不斷。 《紐約時報》、作者與出版商已對 OpenAI、Anthropic 等公司提起訴訟,主張大量抓取受著作權保護的內容來訓練 LLM 並不屬於「合理使用」。Anthropic 在 2025 年以 15 億美元和解一宗重大集體訴訟——這顯示為 AI 而抓取的成本確實很高。
- 「合理使用」抗辯並不穩。 美國法院尚未就「用爬取資料訓練 AI 是否屬於合理使用」做出定論。初步判決顯示,這很大程度取決於資料如何取得以及AI 輸出會被怎麼使用。
- 新的立法即將到來。 《出版者 AI 責任法案》(2026 年 2 月提出)希望要求 AI 公司在抓取出版者內容前先取得許可並支付費用。
- 歐盟 AI 法案(完整執法於 2026 年 8 月) 要求 AI 開發者揭露訓練資料來源、尊重機器可讀的著作權退出機制(依著作權指令的 TDM 例外),並標示 AI 生成內容。它也禁止會從網路抓取人臉影像的 AI 系統。
- AI/LLM 爬蟲快速成長。 AI 爬蟲在短短八個月內,將其網路流量占比從 2.6% 提升到 10.1%,是原本的四倍以上。光是 OpenAI 的 GPTBot 就成長了 305%。作為回應,許多大型網站(Amazon、Reddit、《紐約時報》)都在更新 robots.txt,明確封鎖 AI 爬蟲。
這對您意味著什麼: 如果您是為了傳統商業用途(名單開發、價格監控、市場研究)而抓資料,這些針對 AI 的特別規則可能不會直接適用。但如果您要把爬來的資料餵給 AI 模型,就要非常小心——而且最好先諮詢法律意見。
世界各地的網頁爬蟲法規:快速比較
讓我們把視角拉遠,看看全球規則大致如何:
- 美國: 沒有全面禁止。抓取對外公開網站一般屬合法 (hiQ v. LinkedIn),而 2024 年 Meta 與 X Corp 的判決也進一步強化了公開資料爬取的立場。不過,若抓取登入後內容或繞過技術阻擋,仍可能觸發 CFAA。現在的趨勢則是企業改用合約法與著作權主張。隱私法也在快速擴張:CCPA 已於 2026 年 1 月 1 日生效重大更新,包含自動化決策與資料經紀商義務的新規則。印第安納、肯塔基和羅德島也在 2026 年通過了全面性隱私法。
- 歐盟: 隱私法嚴格。即使是公開的個資,GDPR 也適用。資料庫權可能阻止大規模抓取結構化資料 (cliffordchance.com)。新: 歐盟 AI 法案將於 2026 年 8 月 2 日全面執法,要求 AI 開發者揭露訓練資料來源並尊重著作權退出機制。此法也禁止為 AI 系統從網路抓取人臉影像。
- 英國: 脫歐後大致沿用歐盟規則。公開資料可以抓取,但個資爬取受到嚴格監管。Computer Misuse Act 可能將未授權存取列為刑事犯罪。
- 中國: 管制非常嚴格。PIPL 與資料安全法都要求個資需取得同意。法院會利用反不正當競爭法,阻止損害企業利益的爬取 (malwarebytes.com)。
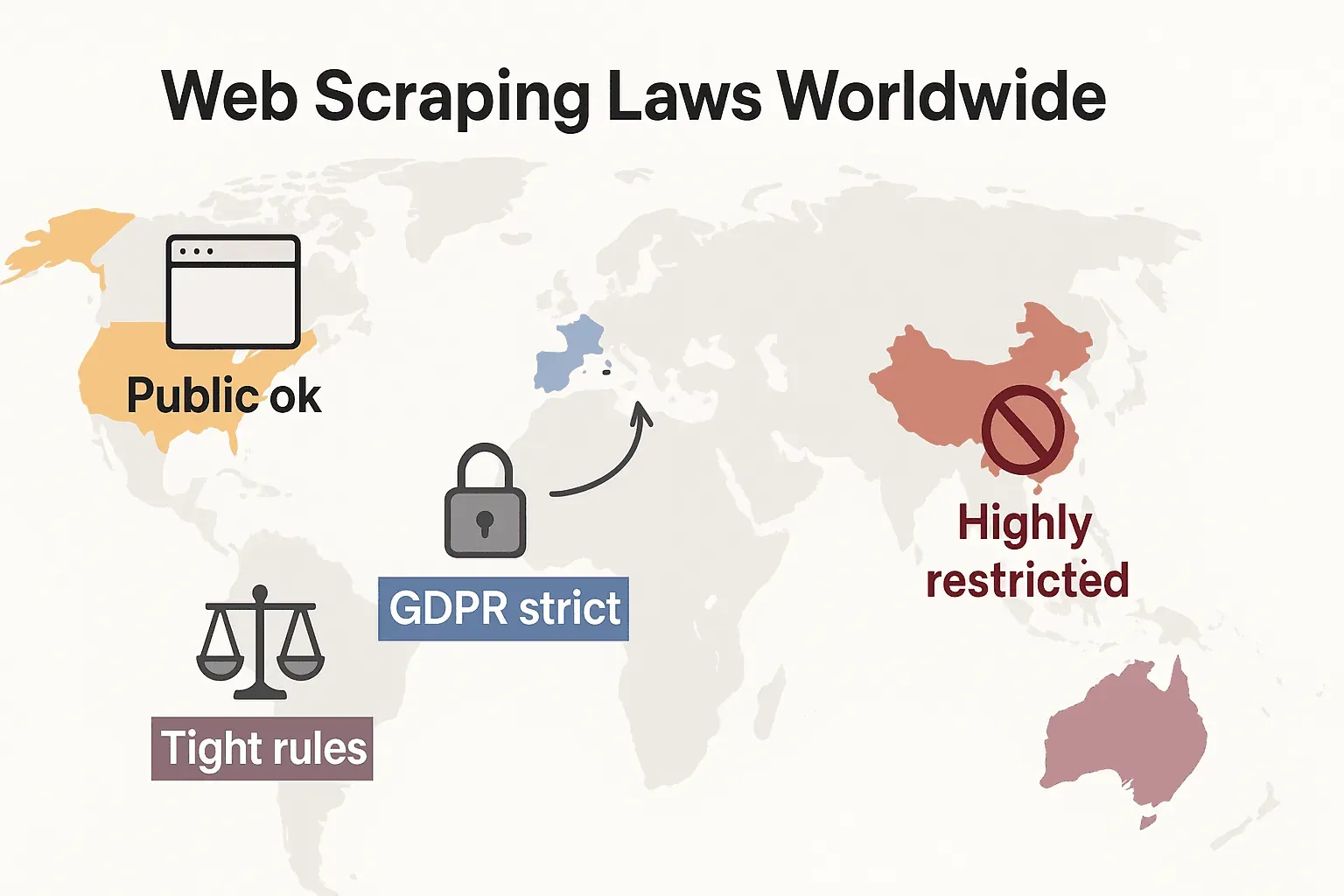
總結來說:為內部使用而抓取公開、非個人資料通常最安全。其他情況呢?請先查看當地法律,並謹慎行事。
關於網頁爬蟲合法性的常見迷思
來破解幾個我常聽到的迷思:
- 迷思 1:「網頁爬蟲一律違法。」
錯。沒有哪條法律禁止所有網頁爬蟲。真正重要的是您怎麼抓、抓什麼 (oxylabs.io)。 - 迷思 2:「只要是公開資料,我就可以隨便用。」
不完全對。公開資料仍可能受到隱私法或著作權法保護,而 ToS 也可能限制某些用途 (ico.org.uk)。 - 迷思 3:「網頁爬蟲跟駭客入侵是一樣的。」
不是。抓取公開網頁不等於駭客行為。繞過登入或技術阻擋才是另一回事 (calawyers.org)。 - 迷思 4:「只要沒被抓到,就沒事。」
這是很危險的想法。許多網站都有反機器人技術,遲早會注意到。沉默不代表同意。 - 迷思 5:「只要我有標註來源,或只是內部使用,就沒問題。」
來源標註不能凌駕著作權或隱私法。內部使用確實比較安全,但不是免死金牌。 - 迷思 6:「所有網頁爬蟲都侵犯隱私。」
不是所有爬取都涉及個資。但如果在沒有防護措施下大量抓取個人資訊,幾乎一定違法 (oxylabs.io)。 - 迷思 7:「如果網站 ToS 禁止爬取,那就一定違法。」
不一定。2024 年,法院在 Meta v. Bright Data 與 X Corp v. Bright Data 中裁定,未曾同意條款的使用者不受 ToS 約束——也就是說,如果您是在未登入、未建立帳號的情況下抓取,網站 ToS 未必適用於您。這仍是持續發展中的領域,但已經是重要轉變。
如何合法抓取資料:合規最佳實務
以下是我常用的合法、負責任網頁爬蟲檢查清單:
- 閱讀並尊重網站的服務條款。 如果條款寫著「禁止爬取」,就該考慮停止,或先取得許可 (ql2.com)。
- 只抓取公開資料。 如果需要密碼,那就是受限內容——不要抓 (thunderbit.com)。
- 查看 robots.txt,並以禮貌方式爬取。 雖然不具法律約束力,但這是良好禮節。不要狂轟伺服器——請分散請求頻率 (promptcloud.com)。
- 避免蒐集個資,除非您有合法依據。 若必須蒐集,請遵守 GDPR/CCPA,並盡量最小化蒐集量。
- 不要整批重發布爬來的內容。 請加入價值或分析,或先取得許可 (thunderbit.com)。
- 不要在未檢查著作權的情況下,把爬來的內容餵給 AI 模型。 法律環境變化很快——若這是您的用途,請先諮詢專業意見。
- 若有官方 API 或資料匯出,就優先使用。 這些就是為此設計的,通常也更安全 (thunderbit.com)。
- 保持透明與可追溯。 如果您蒐集個資,請告知當事人,並保留活動紀錄。
- 資料最小化並妥善保護。 只收集需要的資料,保持正確,並安全儲存。
- 隨時更新資訊,邊緣案例請尋求法律意見。 法規與判決都在快速變動——尤其是歐盟 AI 法案與美國州級隱私法。拿不準時,找專業人士最保險。
試用 Thunderbit Chrome 擴充功能,實現合規爬取
合法使用網頁爬蟲工具:企業需要知道什麼
像 Thunderbit 這類網頁爬蟲工具,讓不會寫程式的人也能輕鬆收集資料,但您仍然需要負責任地使用它們:
- 選擇重視合規的工具。 例如 Thunderbit,只會抓取您在瀏覽器中看得到的內容——不會偷偷破解 API,也不會未經授權存取 (thunderbit.com)。
- 堅持合法用途。 內部分析、市場研究和競爭價格監控一般較安全。若要重發布或出售爬取資料,風險就高得多。
- 把工具設定成合規模式。 設定爬取延遲、遵守 robots.txt,只用收集必要資料的範本。
- 盡量保留在內部使用。 內部使用爬取資料通常比重新發布安全。
- 教育您的團隊。 確保每個人都了解規則與最佳實務。
- 善用內建合規功能。 Thunderbit 會提醒使用者注意風險網站、以類似真人的速度抓取,而且不會把您的資料儲存在它的伺服器上。
- 不要硬來。 如果工具無法抓某個網站,就不要硬拗繞過。不是所有資料都能在沒有風險的情況下取得。
Thunderbit 的做法:讓合規的 AI 網頁爬蟲成為可能
在 Thunderbit,我們花了很多時間思考合規問題。以下是我們的 AI 網頁爬蟲如何幫助使用者站在法律正確的一邊:
- 只抓取您看得到的內容。 Thunderbit 在您的瀏覽器工作階段中運作,因此它無法存取您無法手動複製的資料。
- 用警示引導使用者。 如果您嘗試抓取有嚴格反爬政策的網站,Thunderbit 會提醒您。
- 類似真人的抓取速度。 不論您是在本機還是雲端抓取,Thunderbit 都不會狂轟伺服器。
- 可自訂的資料選擇。 我們的 AI 會建議相關欄位,幫助您只蒐集需要的內容。
- 子頁與分頁處理。 Thunderbit 會像真人使用者一樣瀏覽網站,尊重其結構。
- 隱私與安全。 您的資料只屬於您自己——Thunderbit 不會儲存或重複使用它。
- 適合合規的匯出。 可直接匯出到 Google Sheets、Airtable、Notion 或 CSV,方便安全地在內部使用。
- 排程與自動化。 您可以設定合理間隔的定期爬取。
- 多語言支援。 Thunderbit 的介面支援 34 種語言,讓全球都能更容易落實合規。
- 定期更新範本。 我們針對熱門網站提供的即時範本,會持續跟上法律與技術變化。
透過把合規直接內建到產品裡,Thunderbit 幫助團隊取得需要的資料,同時避免法律麻煩。
保持領先:因應網頁爬蟲的法律與技術變化
探索更多網頁爬蟲指南 Get Started Free
網頁爬蟲不是「設定好就放著」的遊戲。法規與網站結構都在不斷演進。以下是保持領先的方法:
- 追蹤法律動態。 2024–2026 的變化速度明顯加快——請關注科技法律新聞、監管更新與產業部落格(像 Thunderbit 的部落格)。留意歐盟 AI 法案的執法時間(2026 年 8 月)、美國新的州級隱私法,以及持續進行中的 AI 著作權案件。
- 因應技術變化。 網站會一直更新版面與反機器人防禦。主要平台(Amazon、X、Google)在 2025–2026 年都大幅加強了防禦。Thunderbit 的 AI 與範本設計,就是為了自動適應這些變化。
- 有官方 API 就優先採用。 如果網站改成收費 API 模式,請考慮切換,兼顧穩定性與合規性。
- 定期稽核您的爬取流程。 記錄來源、檢查 ToS 或政策是否變更,並視情況調整策略。
- 善用 Thunderbit 的範本更新。 我們團隊會持續更新範本,您就不必擔心破壞性變更或新的合規要求。
- 保持彈性。 如果某個資料來源風險太高,就轉向別的來源,或尋求合作夥伴關係。
只要工具與思維都對,您就能讓資料管道持續運作——而不用踩到法律地雷。
結論:如何在網頁爬蟲的法律環境中前進
網頁爬蟲本身並不違法——它是商業、研究與創新的強大工具。但就像任何工具一樣,它也有規則。關鍵在於理解您抓什麼、怎麼抓,以及您會如何使用這些資料。尊重當地法律、遵守網站政策,並使用像 Thunderbit 這類重視合規的工具,讓您的作業站得住腳。
2024–2026 的法院判決(Meta v. Bright Data、X Corp v. Bright Data)強化了抓取公開資料的立場,但 AI 訓練資料、著作權主張與歐盟 AI 法案帶來了新的風險。不同平台的政策差異也很大——Google、Amazon、LinkedIn、Meta 和 X 的執法方式各不相同——所以在爬取之前,先了解整體情勢非常重要。
如果您不確定,請尋求法律建議——尤其是大型或敏感專案。也別忘了:法律環境一直在變,所以請保持資訊更新與行動彈性。
想進一步了解網頁爬蟲、合規與自動化嗎?歡迎查看 Thunderbit 部落格 的更多指南,或親自試用 Thunderbit Chrome 擴充功能。
常見問題
1. 網頁爬蟲在所有地方都違法嗎?
不。網頁爬蟲本身不違法,但是否合法取決於您抓什麼、怎麼抓,以及您在哪裡。一般來說,在多數地區,抓取公開、非個人資料供內部使用是允許的;但抓取個資或受著作權保護的資料,或違反網站條款,就可能違法 (oxylabs.io)。
2. 如果我忽略 robots.txt,會讓爬取變成違法嗎?
robots.txt 不具法律約束力,但最佳實務仍是尊重它。忽略 robots.txt 本身不會直接讓您被告,但若發生爭議,它可能讓您看起來像「不良行為者」 (promptcloud.com)。
3. 我可以抓 Google、Amazon 或 LinkedIn 嗎?
這很複雜。這三家都在 ToS 中禁止爬取,但法院已裁定,ToS 未必能約束從未登入的使用者(見 2024 年的 Meta v. Bright Data 與 X Corp v. Bright Data)。抓取公開可見的資料(商品價格、商家列表、公開個人檔案)在美國通常較有法律防禦空間。不過,各平台執法方式不同:Amazon 的法律行動最強硬(它在 2025 年 11 月起訴 Perplexity AI);LinkedIn 主要依賴技術阻擋與合約主張;Google 則越來越常使用 DMCA 執法。請務必負責任地爬取,並預期會有技術反制。
4. 我可以抓 Facebook 或 Instagram 嗎?
在 Meta v. Bright Data(2024)之後,未登入狀態下抓取 Facebook 和 Instagram 的公開資料,法律基礎更強。法院裁定 Meta 的 ToS 不適用於非使用者。但絕不要建立假帳號或抓取登入牆後的資料——那就越線了。
5. 我可以抓 X(Twitter)嗎?
X 在 2023 年更新 ToS,禁止未經書面同意的所有爬取,並部署了強力技術防禦(Cloudflare Turnstile、每小時 300 次請求的速率限制、IP 信譽評分)。不過,Bright Data 在類似案件中贏得了官司——未建立帳號而抓取的公開資料,不受 X 的 ToS 約束。從技術角度來看,X 是 2026 年最難抓的平台之一。
6. 把資料抓來訓練 AI 模型合法嗎?
這是 2026 年最大的不確定問題。重大訴訟(NYT v. OpenAI、Anthropic 的 15 億美元和解)顯示風險相當高。歐盟 AI 法案要求揭露訓練資料來源並尊重著作權退出機制。提案中的《出版者 AI 責任法案》也要求事先取得許可並支付費用。如果您是要抓資料來訓練 AI,請先諮詢法律意見再行動。
7. 使用 Thunderbit 這類網頁爬蟲工具,最安全的方法是什麼?
只抓公開資料、尊重網站條款、避免個資,除非您有合法依據,並把資料用於內部。Thunderbit 的設計就是幫您維持合規:只抓瀏覽器中看得到的內容,並提醒風險網站 (thunderbit.com)。
8. 我可以把爬來的資料用於商業用途嗎?
要看情況。將爬來的資料用於內部分析或研究通常較安全。若要重發布或出售爬來的資料,尤其是受著作權保護或涉及個資的資料,風險會高很多,可能需要許可或授權。
9. 如何跟上網頁爬蟲的法律與技術變化?
追蹤科技法律新聞、監控目標網站的 ToS 或政策變化,並使用像 Thunderbit 這種會定期更新範本與合規功能的工具。2026 年需要特別注意:歐盟 AI 法案執法(8 月)、持續進行的 AI 著作權案件,以及美國新的州級隱私法。拿不準時,請諮詢法律專業人士。
試用 AI 網頁爬蟲 Get Started Free




