
如果你有試過要從那種要一直滑動才會顯示內容、把價格藏在登入後面,或是三不五時就大改版的網站抓資料,你一定懂那種卡關的感覺。傳統的靜態爬蟲早就不夠用了。其實,現在有超過都靠網頁爬蟲來拿到替代性數據,也都自動化監控競爭對手價格。但重點來了:這些資料大多都藏在動態網站裡,由 JavaScript 載入,還要經過一堆互動才能看到。這時候,無頭瀏覽器自動化工具——像 Puppeteer 這種——就超級有用。
我自己長期在開發自動化跟人工智慧工具,也幫過不少銷售和營運團隊爬網站,深刻體會到 Puppeteer 能解鎖很多傳統爬蟲抓不到的資料。不過,對商業用戶來說,寫程式這件事常常讓人卻步。所以這篇文章會帶你認識什麼是 Puppeteer 爬蟲、怎麼用它抓網頁資料,以及什麼時候你可以選擇更簡單的方式——像我們的 ,一款 AI 驅動、完全免寫程式的網頁爬蟲。
什麼是 Puppeteer 爬蟲?快速認識
 先從基本的說起。 是 Google 推出的開源 Node.js 函式庫,讓你可以用 JavaScript 操控無頭版的 Chrome 或 Chromium 瀏覽器。簡單來說,它就像一個機器人,可以自動開網頁、點按鈕、填表單、滑動頁面,最厲害的是——完全不用顯示畫面就能抓資料。
先從基本的說起。 是 Google 推出的開源 Node.js 函式庫,讓你可以用 JavaScript 操控無頭版的 Chrome 或 Chromium 瀏覽器。簡單來說,它就像一個機器人,可以自動開網頁、點按鈕、填表單、滑動頁面,最厲害的是——完全不用顯示畫面就能抓資料。
Puppeteer 有什麼厲害的地方?
- 能渲染動態內容——會等 JavaScript 載入完,跟真人操作一樣。
- 可以模擬用戶行為:點擊、輸入、滑動,連彈窗都能處理。
- 超適合抓那種互動後才會顯示資料的網站,像電商列表、社群動態牆或儀表板。
跟其他工具比起來怎樣?
- Selenium:自動化瀏覽器的老大哥,支援多種瀏覽器和語言,但比較笨重、操作也比較舊。適合跨瀏覽器測試,但如果你只想專注 Chrome/Node.js,Puppeteer 會更輕巧。
- Thunderbit:這我最推薦。Thunderbit 是一款免寫程式、AI 驅動的網頁爬蟲,直接在瀏覽器裡用。你只要點「AI 建議欄位」,AI 就會自動判斷要抓哪些資料。很適合想快點拿到結果、不想寫程式的商業用戶(後面會詳細介紹)。
簡單說:Puppeteer = 超高自訂(適合會寫程式的人);Thunderbit = 極致方便(適合不想寫程式的人)。
為什麼 Puppeteer 網頁爬蟲對商業用戶很重要
老實說,網頁爬蟲早就不是駭客或資料科學家的專利。現在,銷售、營運、行銷,甚至房仲團隊都靠網路資料搶快。隨著越來越多重要資訊被鎖在動態網站裡,Puppeteer 常常就是打開這些資料的鑰匙。
來看幾個實際應用場景:
別忘了:每週有四分之一的時間都在做重複性資料收集。自動化這些流程,不只是提升效率,更是企業競爭力的關鍵。
快速上手:Puppeteer 爬蟲環境設定
準備動手了嗎?以下是 10 分鐘內讓 Puppeteer 跑起來的步驟(要有基本 JavaScript 概念):
1. 安裝 Node.js
Puppeteer 需要 Node.js 執行。到 下載最新版 LTS。
2. 建新專案資料夾
打開終端機,輸入:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. 安裝 Puppeteer
1npm install puppeteer這會自動下載相容的 Chromium(大約 100MB)。
4. 寫第一支腳本
建立一個叫 scrape.js 的檔案:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();執行:
1node scrape.js如果看到 “Page title: Example Domain”,恭喜你,已經自動化 Chrome 了!
建立你的第一個 Puppeteer 網頁爬蟲腳本
來點實戰吧。假設你想從 (一個爬蟲練習網站)抓名言。
步驟 1:前往目標頁面
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });步驟 2:擷取資料
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);步驟 3:處理分頁
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // 如上方擷取 quotes
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}步驟 4:儲存為 JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));這樣就完成了一個能自動瀏覽、擷取、分頁並儲存資料的基本 Puppeteer 爬蟲。
進階技巧:處理動態內容
現實中的網站通常比靜態列表複雜,這裡有幾個常見挑戰的解法:
1. 等待動態元素載入
1await page.waitForSelector('.product-list-item');確保你要抓的內容已經出現在頁面上。
2. 模擬用戶操作
- 點擊按鈕:
await page.click('#load-more'); - 輸入文字:
await page.type('#search', 'laptop'); - 無限滾動:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. 處理登入流程
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. 處理 AJAX 載入的資料 有時候資料不是直接在網頁上,而是透過 API 載入。你可以攔截網路回應:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // 處理資料
5 }
6});實戰範例:抓取電商網站商品資料
綜合以上技巧,假設你想在登入後抓某電商網站的商品名稱、價格和圖片。
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // 步驟 1:登入
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // 步驟 2:前往分類頁
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // 步驟 3:擷取商品
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // 步驟 4:儲存為 JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();這支腳本會自動登入、瀏覽、擷取並儲存資料。要更進階也可以加分頁或點每個商品進一步抓細節。
Thunderbit:用 AI 讓 Puppeteer 爬蟲更簡單
如果你看到這裡,心裡想「這很酷,但我真的不想每次都寫程式」,你絕對不是唯一這樣想的人。這就是我們打造 的原因。
Thunderbit 有什麼優勢?
- 完全免寫程式:只要安裝 ,打開你想抓的網頁,點「AI 建議欄位」就好。
- AI 智慧欄位偵測:Thunderbit 會自動分析頁面,推薦最適合擷取的欄位,像「商品名稱」、「價格」、「圖片」等。
- 動態內容全自動處理:無限滾動、彈窗、子頁面?Thunderbit 的 AI 都能自動點分頁,甚至進每個商品頁補資料。
- 一鍵匯出:資料可直接匯出到 Excel、Google Sheets、Notion 或 Airtable,完全不用額外付費。
- 熱門網站範本:想抓 Amazon、Zillow 或 LinkedIn?Thunderbit 內建範本,直接用就好。
- 雲端或本地爬取:大規模需求時,Thunderbit 可在雲端同時抓 50 頁以上。
我親眼看過用戶從「我想要這些資料」到「這是我的試算表」不到五分鐘。最棒的是,網站改版也不用怕腳本壞掉——Thunderbit 的 AI 會自動適應。
Puppeteer vs. Thunderbit:怎麼選適合你的網頁爬蟲工具
那到底該選哪一個?我通常這樣建議團隊:
| 比較項目 | Puppeteer(需寫程式) | Thunderbit(免寫程式、AI) |
|---|---|---|
| 易用性 | 需懂 JavaScript 與 DOM 操作 | 點選操作,AI 自動建議欄位 |
| 設定速度 | 複雜任務需數小時到數天 | 幾分鐘內完成,安裝即用 |
| 彈性/自訂 | 最高:可寫任何自訂邏輯,整合其他程式 | 標準情境彈性高,極度複雜流程較不適合 |
| 動態內容處理 | 需手動寫等待、點擊、滾動等腳本 | AI 內建自動處理動態內容、分頁、子頁面 |
| 維護成本 | 腳本需自行維護,網站改版時需更新 | AI 自動適應版面變動,使用者維護負擔低 |
| 資料匯出 | 需自行撰寫匯出程式 | 一鍵匯出到 Excel、Sheets、Notion、Airtable、CSV、JSON |
| 適合對象 | 開發者、需高度自訂或大規模爬取 | 商業用戶、快速專案、非技術團隊 |
| 費用 | 免費(但需投入時間與基礎設施) | 有免費方案,付費依點數計價(詳見 Thunderbit 價格) |
總結:
- 需要高度自訂、會寫程式或要整合進大型系統時,選 Puppeteer。
- 想要快速拿到結果、不想寫程式或要讓非技術同事也能用,選 Thunderbit。
其實,很多團隊會兩者一起用:Thunderbit 拿來快速驗證和做原型,Puppeteer 則負責深度整合或特殊需求。
專案成功清單:Puppeteer 網頁爬蟲實戰步驟
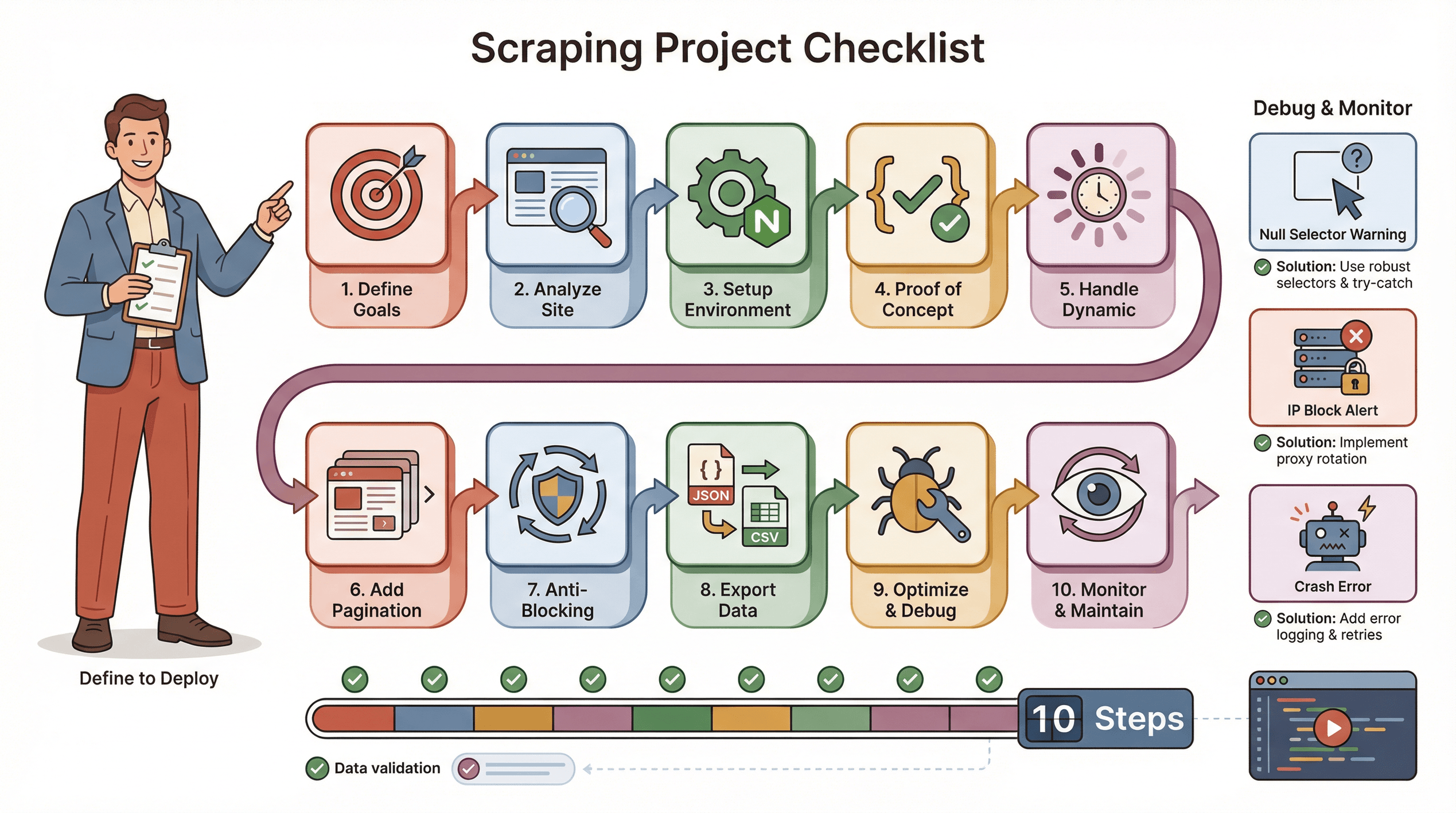 這是我推薦的 Puppeteer 爬蟲專案流程檢查表:
這是我推薦的 Puppeteer 爬蟲專案流程檢查表:
- 明確目標:你需要哪些資料?在哪些網站?
- 分析網站:是動態還是靜態?需不需要登入?有沒有反爬蟲機制?
- 環境建置:安裝 Node.js、Puppeteer 及輔助函式庫。
- 先做小型驗證:先抓一頁,確認選擇器正確。
- 處理動態內容:用
waitForSelector、模擬點擊/滾動等互動。 - 加上分頁或迴圈:確保能抓到所有頁面。
- 反封鎖策略:隨機延遲、設定真實 User-Agent、必要時用代理伺服器。
- 資料匯出與驗證:存成 JSON/CSV,檢查完整性。
- 優化與錯誤處理:加上 try/catch、記錄進度、處理缺漏資料。
- 持續監控與維護:網站會變,腳本也要隨時更新。
常見問題排解:
- 選擇器抓不到資料時,請檢查 HTML 結構並加上等待。
- 被封鎖時,請降低速度、換 IP 或加裝隱身外掛。
- 腳本當機時,檢查是否有記憶體洩漏或未處理的例外。
結論與重點整理
網頁爬蟲已經是數據驅動團隊的必備技能。Puppeteer 讓你能從最複雜、JavaScript 密集的網站抓資料,但需要一定的程式能力和維護成本。對想省去寫程式、直接拿到資料的商業用戶,Thunderbit 則提供 AI 驅動、免寫程式的高效選擇,靈活又強大。
我的建議:
- 如果你有技術底、需要高度自訂,建議從 Puppeteer 開始。
- 如果你重視速度、簡單、低維護,推薦試試 ( 很適合入門)。
- 多數團隊兩者搭配用,幾乎能滿足 99% 的網頁資料需求。
想看更多教學?歡迎到 ,獲取更多 AI 網頁爬蟲的實用技巧與比較。
常見問答
1. 什麼是 Puppeteer 爬蟲?為什麼適合網頁爬取?
Puppeteer 是一個 Node.js 函式庫,能用 JavaScript 操控無頭 Chrome 瀏覽器。它能載入動態內容、模擬用戶操作,抓傳統爬蟲無法處理的網站資料。
2. Puppeteer、Selenium 和 Thunderbit 有什麼不同?
Selenium 支援多瀏覽器和多語言,但比較笨重。Puppeteer 專為 Chrome/Node.js 設計,速度較快。Thunderbit 則是免寫程式、AI 驅動的工具,讓非技術用戶也能輕鬆抓資料。
3. Puppeteer 網頁爬蟲對企業有什麼好處?
自動化資料收集能省時間、減少錯誤,還能讓銷售、行銷、營運等部門即時掌握市場。應用範圍包括名單開發、價格監控、市場調查等。
4. 使用 Puppeteer 爬蟲最大的挑戰是什麼?
最大挑戰在於處理動態內容、避免被封鎖,以及網站改版時腳本維護。你需要寫程式來管理等待、模擬互動和錯誤處理。
5. 什麼時候該用 Thunderbit 取代 Puppeteer?
如果你不想寫程式、需要快速拿到結果,或想讓非技術同事也能用,Thunderbit 是理想選擇。它適合標準爬取、快速專案,或需要一鍵匯出到 Excel、Google Sheets 的情境。
想體驗更聰明的爬蟲方式?,或到 深入學更多教學。祝你爬蟲順利!
延伸閱讀