網路資料量真的在「爆炸式」成長,隨之而來的就是那種「不跟上就會被甩開」的壓力。我親眼看過不少銷售跟營運團隊,把大把時間都耗在整理試算表、從網站一段一段複製貼上資料,結果真正能拿來判斷策略、做決策的時間反而被壓縮。Salesforce 就指出,業務人員現在有;Asana 也提到,。講白了,就是大量工時被手動蒐集資料吃掉——那些時間本來可以拿去成交、推活動、做成長。
好消息是:網頁爬蟲早就不再是工程師的專利。Ruby 一直是自動化網頁資料擷取的熱門語言;而當你把 Ruby 跟新一代的人工智慧網頁爬蟲(例如 )搭在一起,就等於一次吃到兩種優勢——會寫程式的人可以保有彈性跟可控性,不會寫程式的人也能用免寫程式網頁爬蟲的方式快速搞定。無論你是行銷人員、電商營運,或只是受夠無止盡 Ctrl+C / Ctrl+V 的人,這篇指南會帶你用 Ruby 跟 AI 把網頁爬蟲玩起來——而且不必寫任何爬蟲程式碼。
什麼是 Ruby 網頁爬蟲?通往自動化資料的入口
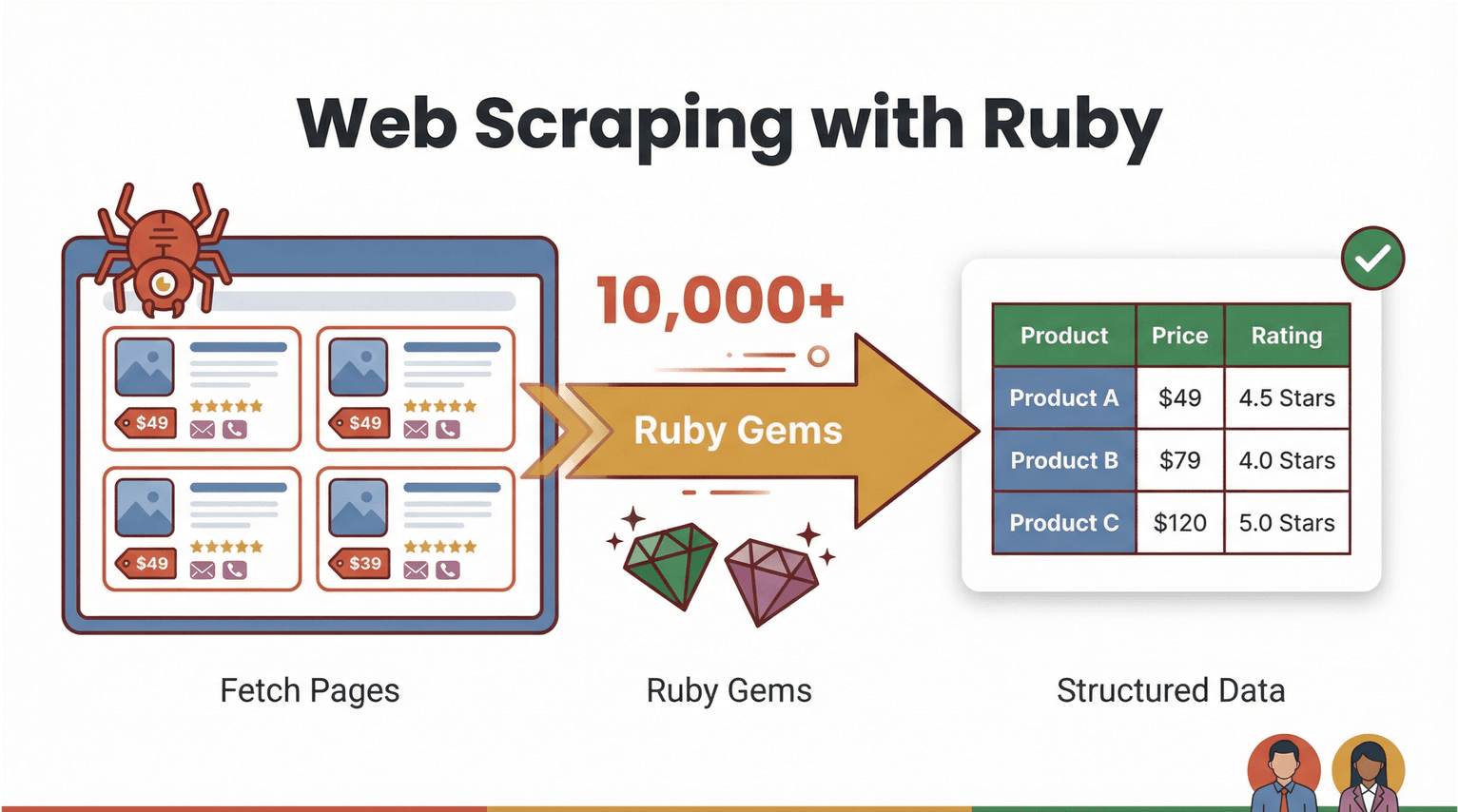
先把基本概念講清楚。網頁爬蟲就是用軟體去抓網頁內容,然後把你要的資訊(像商品價格、聯絡方式、評論等等)整理成結構化資料(例如 CSV 或 Excel)。用 Ruby 來做網頁爬蟲,強大又相對好上手:語法可讀性高,加上「gems」(函式庫)生態系很完整,做自動化會很順()。
那「Ruby 網頁爬蟲」實際跑起來會長怎樣?假設你想從某個電商網站抓出所有商品名稱跟價格,Ruby 腳本通常會做這幾件事:
- 下載網頁內容(例如用 )
- 解析 HTML 找到你要的欄位(用 )
- 匯出到試算表或資料庫
但更有意思的是:你其實不一定要寫程式。像 這種 AI 驅動、免寫程式的網頁爬蟲,現在可以直接幫你把苦工做掉——讀懂網頁、辨識欄位、輸出乾淨的資料表,基本上點幾下就完成。Ruby 依然很適合當作客製流程的「自動化黏著劑」,而 AI 網頁爬蟲則讓更多商務使用者也能輕鬆加入。
為什麼 Ruby 網頁爬蟲對商務團隊很重要

老實說,沒有人想把一整天都耗在複製貼上。自動化網頁資料擷取的需求飆升不是沒原因的。下面這些就是 Ruby 網頁爬蟲(再加上 AI 工具)怎麼直接改寫商務營運的方式:
- 名單開發: 從名錄網站或 LinkedIn 快速擷取聯絡資訊,直接灌進銷售漏斗。
- 競品價格監控: 追蹤上百個電商 SKU 的價格變動,不用每天人工巡站。
- 商品目錄建置: 批次彙整商品資訊與圖片,用於自家商店或平台上架。
- 市場研究: 收集評論、評分或新聞文章,做趨勢分析。
投資報酬其實很直觀:把網頁資料蒐集自動化後,團隊每週能省下好幾個小時、錯誤率也會下降,資料還更即時、更可靠。以製造業來說,就算資料量在短短兩年內翻倍,仍有——這就是自動化的超大機會點。
下面用一張表快速整理 Ruby 網頁爬蟲跟 AI 工具能帶來的價值:
| 使用情境 | 手動痛點 | 自動化帶來的好處 | 常見成果 |
|---|---|---|---|
| 名單開發 | 一筆一筆複製 Email | 幾分鐘抓取上千筆 | 名單量提升 10 倍、少做苦工 |
| 價格監控 | 每天人工檢查網站 | 排程自動抓取價格 | 即時掌握價格情報 |
| 商品目錄建置 | 手動輸入資料 | 批次擷取並自動整理格式 | 上架更快、錯誤更少 |
| 市場研究 | 人工逐則閱讀評論 | 大規模擷取並分析 | 洞察更深、更即時 |
而且不只是速度而已:自動化也能降低失誤、讓資料更一致——當時,這點真的超關鍵。
網頁爬蟲方案比較:Ruby 腳本 vs. AI 網頁爬蟲工具
那到底要自己寫 Ruby 腳本,還是直接用 AI 驅動的免寫程式網頁爬蟲?我們把兩個選項拆開來看。
Ruby 腳本:掌控度最高,但維護成本也更高
Ruby 生態系的 gems 很齊,幾乎各種爬蟲需求都能 cover:
- : 解析 HTML / XML 的首選。
- : 抓取網頁與 API。
- : 適合需要 cookies、表單與導覽流程的網站。
- / : 自動化真實瀏覽器(對 JavaScript 很重的網站特別有用)。
用 Ruby 腳本的優點是彈性超高:你可以塞客製邏輯、做資料清洗、跟內部系統整合。但代價就是維護:網站版型一改,你的腳本可能立刻壞掉;而且不熟程式的人也需要時間上手。
AI 網頁爬蟲與免寫程式工具:快速、好用、也更能適應變動
像 這類免寫程式網頁爬蟲,玩法完全不一樣。你不用寫程式,只要:
- 打開 Chrome 擴充功能
- 點「AI Suggest Fields」讓 AI 自動判斷要擷取哪些欄位
- 按「Scrape」並匯出資料
Thunderbit 的 AI 能更能適應網頁版型變動、支援子頁面(例如商品詳情頁),而且可以直接匯出到 Excel、Google Sheets、Airtable 或 Notion。對想要快速拿到結果的商務使用者來說,真的很對味。
下面是並排比較:
| 方式 | 優點 | 缺點 | 適合對象 |
|---|---|---|---|
| Ruby 腳本 | 掌控度高、可客製邏輯、彈性強 | 學習門檻較高、需要維護 | 開發者、進階使用者 |
| 人工智慧網頁爬蟲 | 免寫程式、設定快速、能適應網站變動 | 細節控制較少、可能有功能限制 | 商務使用者、營運團隊 |
趨勢其實很明顯:網站越來越複雜(也越來越防爬),AI 網頁爬蟲正在變成多數商務流程的首選。
入門:建立 Ruby 網頁爬蟲環境
如果你想試試 Ruby 腳本,先把環境弄好。好消息是:Ruby 安裝不難,Windows、macOS、Linux 都能跑。
第一步:安裝 Ruby
- Windows: 下載 並照指示安裝。記得勾選 MSYS2,方便編譯原生擴充(像 Nokogiri 這類 gem 會用到)。
- macOS/Linux: 建議用 管理版本。在 Terminal 執行:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(最新穩定版請以 為準。)
第二步:安裝 Bundler 與必要 gems
Bundler 是用來管理相依套件的:
1gem install bundler在專案裡建立 Gemfile:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'接著執行:
1bundle install這樣環境就會一致,隨時可以開爬。
第三步:測試安裝是否成功
在 IRB(Ruby 互動式環境)試跑:
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSION有看到版本號就代表 OK。
手把手:打造你的第一個 Ruby 網頁爬蟲
我們用一個實例走一遍——從 擷取商品資料,這網站就是專門給人練爬蟲用的。
下面是一段簡單 Ruby 程式,用來抓書名、價格跟庫存狀態:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"這段程式會逐頁抓取、解析 HTML、擷取資料,最後寫進 CSV。你可以用 Excel 或 Google Sheets 打開 books.csv。
常見踩雷點:
- 如果跳出缺少 gem 的錯誤,先檢查 Gemfile,然後再跑一次
bundle install。 - 如果網站資料是 JavaScript 動態載入,通常就得用 Selenium 或 Watir 這種瀏覽器自動化工具。
用 Thunderbit 強化 Ruby:人工智慧網頁爬蟲實戰
接著聊聊怎麼用 把效率再往上推——而且全程免寫程式。
Thunderbit 是一款 ,基本上兩次點擊就能從任何網站擷取結構化資料。流程是這樣:
- 在你要擷取的頁面打開 Thunderbit 擴充功能。
- 點 「AI Suggest Fields」:Thunderbit 的 AI 會掃描頁面並建議最適合的欄位(例如「商品名稱」「價格」「庫存」)。
- 點 「Scrape」:Thunderbit 會擷取資料、處理分頁,必要時也能自動跟進子頁面抓更多細節。
- 匯出資料:可直接輸出到 Excel、Google Sheets、Airtable 或 Notion。
Thunderbit 最香的地方在於它能處理複雜、動態的網頁——不用脆弱的 selector,也不用寫程式。你如果想做混合流程,也可以先用 Thunderbit 把資料抓出來,再用 Ruby 腳本做後續處理或加值。
小技巧: Thunderbit 的子頁面擷取對電商跟房地產團隊超好用。先抓商品列表的連結,再讓 Thunderbit 自動一個個進詳情頁擷取規格、圖片或評論,資料表會自動被「補齊」跟「加深」。
真實案例:用 Ruby + Thunderbit 擷取電商商品與價格
我們用一個電商團隊很常見的流程,把兩者串起來。
情境: 你想監控競品上百個 SKU 的價格與商品資訊。
步驟 1:用 Thunderbit 擷取商品列表
- 打開競品的商品列表頁。
- 啟動 Thunderbit,點「AI Suggest Fields」(例如商品名稱、價格、URL)。
- 點「Scrape」並匯出成 CSV。
步驟 2:用子頁面擷取補齊資料
- 在 Thunderbit 使用「Scrape Subpages」功能,逐一進入每個商品詳情頁,擷取更多欄位(例如描述、庫存、圖片)。
- 匯出加值後的資料表。
步驟 3:用 Ruby 做清理或分析
- 用 Ruby 腳本再做清洗、轉換或分析。例如:
- 把價格換算成統一幣別
- 過濾缺貨商品
- 產出摘要統計
下面是一段簡單 Ruby 程式,用來篩出有庫存的商品:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6end成果:
你可以從原始網頁一路走到乾淨、可行動的資料表,用於價格分析、庫存規劃或行銷活動,而且整個擷取過程不必寫任何爬蟲程式碼。
免寫程式也沒問題:讓每個人都能自動化擷取網頁資料
我很喜歡 Thunderbit 的一點是:它真的讓非技術使用者也能做出成果。你不需要懂 Ruby、HTML 或 CSS——只要打開擴充功能,讓 AI 自動判斷並匯出資料就好。
上手成本: Ruby 腳本需要理解程式跟網頁結構;Thunderbit 從設定到出結果通常幾分鐘就搞定。
整合性: Thunderbit 可直接匯出到商務團隊常用工具——Excel、Google Sheets、Airtable、Notion;也能排程定期擷取,做長期監控。
使用回饋: 我看過行銷、銷售營運跟電商團隊用 Thunderbit 自動化名單建置、價格追蹤等工作,全程不必找 IT 支援。
最佳實務:Ruby + 人工智慧網頁爬蟲,打造可擴展的自動化
想把流程做得更穩、更可擴展?下面是我會建議你注意的點:
- 應對網站改版: Thunderbit 這類 AI 網頁爬蟲比較能自動適應;如果用 Ruby 腳本,網站一改版就要準備更新 selector。
- 排程擷取: 用 Thunderbit 的排程功能定期抓取;Ruby 則可用 cron 或系統排程器。
- 批次處理: 資料量大時分批抓取,降低被封鎖風險,也避免系統負載過高。
- 資料格式化: 分析前務必清理與驗證資料;Thunderbit 匯出已結構化,但自寫 Ruby 腳本可能需要更多檢查。
- 合規: 只擷取公開資料、尊重
robots.txt,並留意隱私法規(尤其是歐盟——)。 - 備援策略: 如果網站太複雜或反爬很兇,優先考慮官方 API 或替代資料來源。
什麼時候用哪個?
- 需要高度掌控、客製邏輯或跟內部系統深度整合:用 Ruby 腳本。
- 追求速度、易用性與適應性(一次性或定期的商務任務):用 Thunderbit。
- 進階混合流程:用 Thunderbit 負責擷取,再用 Ruby 做加值、品管或整合。
結語與重點整理
Ruby 網頁爬蟲一直都是自動化資料蒐集的強力武器;而現在有了像 Thunderbit 這樣的 AI 網頁爬蟲,這份能力也終於能讓每個人都用得上。無論你是想保有彈性的開發者,或只是想快速拿到結果的商務使用者,都能把網頁資料擷取自動化、省下大量手動工時,並做出更快、更好的決策。
希望你帶走的重點是:
- Ruby 是做網頁爬蟲與自動化的好工具——搭配 Nokogiri、HTTParty 等 gems 更是如虎添翼。
- Thunderbit 這類 AI 網頁爬蟲讓不寫程式的人也能輕鬆擷取資料,例如「AI Suggest Fields」與子頁面擷取。
- Ruby + Thunderbit 的組合能兼顧兩者優勢: 免寫程式快速擷取 + 客製自動化與分析。
- 對銷售、行銷與電商團隊而言,自動化網頁資料蒐集是關鍵策略——減少手動、提升準確度、挖掘更多洞察。
準備開始了嗎?先,再試跑一段簡單的 Ruby 程式,看看你能省下多少時間。想更深入,也可以到 參考更多指南、技巧與實戰案例。
常見問題(FAQs)
1. 使用 Thunderbit 做網頁爬蟲需要會寫程式嗎?
不需要。Thunderbit 是為非技術使用者設計的:打開擴充功能、點「AI Suggest Fields」,其餘交給 AI。資料可匯出到 Excel、Google Sheets、Airtable 或 Notion,全程免寫程式。
2. 用 Ruby 做網頁爬蟲的主要優勢是什麼?
Ruby 有 Nokogiri、HTTParty 等強大函式庫,能打造彈性高、可客製的擷取流程。很適合想要完整掌控、加入自訂邏輯並與其他系統整合的開發者。
3. Thunderbit 的「AI Suggest Fields」是怎麼運作的?
Thunderbit 的 AI 會掃描網頁內容,辨識最相關的資料欄位(例如商品名稱、價格、Email),並自動建議一張結構化表格。你也可以在擷取前自行調整欄位。
4. 可以把 Thunderbit 和 Ruby 腳本結合做更進階的流程嗎?
當然可以。很多團隊會用 Thunderbit 先擷取資料(特別是複雜或動態網站),再用 Ruby 做後續處理或分析。這種混合方式很適合客製報表或資料加值。
5. 企業使用網頁爬蟲是否合法、安全嗎?
在擷取公開資料、遵守網站服務條款與隱私法規的前提下,網頁爬蟲通常是合法的。請務必查看 robots.txt,並避免在未取得適當同意的情況下擷取個資——尤其是歐盟使用者需特別留意 GDPR。
想看看網頁爬蟲如何改造你的工作流程?現在就試試 Thunderbit 的免費方案,或用 Ruby 腳本做個小實驗。如果卡關, 與 也有大量教學與技巧,帶你把網頁資料自動化做到「免寫程式也能搞定」。
延伸閱讀