我的第一個爬取專案,是靠手寫的 Python 腳本、共享代理和一點祈禱完成的。平均每三天就壞一次。
到了 2026 年,爬取 API 會把最麻煩的部分——代理、渲染、CAPTCHA、重試——全都包辦好,讓你不用親自操心。它們是從價格監控到 AI 訓練資料管線等各種應用的核心基礎。
但這裡有個轉折:像 這類 AI 驅動工具,正在讓很多非開發者原本非得靠 API 才能完成的工作,變得沒那麼必要了。下面我會進一步說明。
以下是我用過或評估過的 10 個爬取 API——各自擅長什麼、有哪些不足,以及什麼時候你其實根本不需要 API。
為什麼要考慮 Thunderbit AI,而不是傳統網頁爬取 API?
在進入 API 清單之前,先談談大家心裡那個大哉問:AI 驅動自動化。我花了很多年幫團隊把那些繁瑣工作自動化,而我可以很肯定地說——越來越多企業跳過程式碼重的 API,直接用像 Thunderbit 這樣的 AI agent,背後是有原因的。
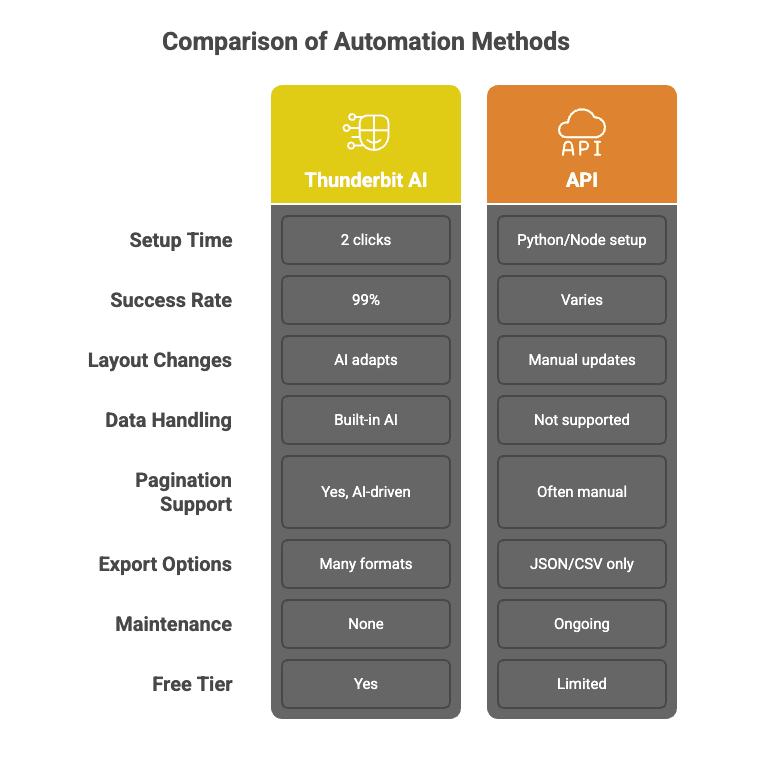
以下是 Thunderbit 和傳統網頁爬取 API 的差異:
-
瀑布式 API 呼叫,成功率高達 99%
Thunderbit 的 AI 不會只呼叫一個 API 就祈禱它成功。它採用瀑布模式——會根據每個任務自動選擇最合適的爬取方式,必要時重試,並保證 99% 的成功率。你拿到的是資料,不是麻煩。
-
免程式碼、兩步驟設定
不用再寫 Python 腳本,也不用對著 API 文件反覆摸索。用 Thunderbit,您只要按一下「AI 建議欄位」和「爬取」就完成了。就這麼簡單。連我媽都能用(雖然她到現在還以為「雲端」只是壞天氣)。
-
批次爬取:快速又準確
Thunderbit 的 AI 模型可以同時處理成千上萬個不同網站,並即時適應各種版面配置。就像你有一大票實習生——只不過他們不會一直要喝咖啡休息。
-
免維護
網站一直都在變。傳統 API 呢?它們會壞。Thunderbit 則是每次都重新讀取頁面,所以當網站調整版面或新增按鈕時,您不必更新程式碼。
-
個人化資料擷取與後處理
需要把資料清理、標記、翻譯或摘要嗎?Thunderbit 可以在擷取時一併完成——就像把 10,000 個網頁丟進 ChatGPT,然後拿回一份結構完美的資料集。
-
子頁面與分頁爬取
Thunderbit 的 AI 可以跟著連結走、處理分頁,甚至把子頁面的資料補進您的表格裡——全程都不需要客製化程式碼。
-
免費資料匯出與整合
可匯出到 Excel、Google Sheets、Airtable、Notion,或下載為 CSV/JSON——沒有付費牆,沒有花招。
先看一個快速比較,讓你更直觀地感受差異:
想看實際效果嗎?可以看看 。
什麼是資料爬取 API?
我們先回到基礎概念。資料爬取 API 是一種讓你能以程式化方式從網站擷取資料的工具——不必從零開始自己打造爬蟲。你可以把它想像成一個你派出去抓最新價格、評論或列表的機器人,然後它會把資料用整齊、結構化的格式帶回來(通常是 JSON 或 CSV)。
它們怎麼運作?多數爬取 API 會處理那些麻煩事——輪換代理、解 CAPTCHA、渲染 JavaScript——讓您能專注在真正需要的東西:資料本身。您送出請求(通常包含 URL 和一些參數),API 就會回傳內容,讓您直接接到業務流程裡。
主要優點:
- 速度: API 每分鐘可以爬取數千個頁面。
- 擴展性: 需要監控 10,000 個產品?沒問題。
- 整合性: 幾乎不用費什麼力氣,就能接到你的 CRM、BI 工具或資料倉儲。
但正如我們接下來會看到的,不是每個 API 都一樣好用——也不是每個都像它們宣稱的那樣「設定一次就能放著不管」。
我是如何評估這些 API 的
我花了很多時間在第一線——測試、搞壞,還有偶爾不小心把自己的伺服器 DDoS 掉(千萬別告訴我以前的 IT 團隊)。這份名單中,我主要看重的是:
- 可靠性: 在棘手網站上也真的能運作嗎?
- 速度: 在大規模情境下,結果交付有多快?
- 價格: 新創負擔得起嗎?企業規模下是否能持續擴張?
- 擴展性: 能處理數百萬次請求,還是到 100 就當機?
- 開發者友善度: 文件清楚嗎?有 SDK 和程式碼範例嗎?
- 支援: 當事情出包時(而且一定會),有沒有人能幫忙?
- 使用者回饋: 真實世界的評論,不只是行銷話術。
我也大量參考了實測、評論分析,以及 Thunderbit 社群的回饋(我們這群人眼光很挑)。
2026 年值得考慮的 10 個 API
準備看重頭戲了嗎?以下是我最新整理的 2026 年最佳網頁爬取 API 與平台清單,適合商務使用者和開發者。
1. Oxylabs
 概覽:
概覽:
Oxylabs 是企業級網頁資料擷取的重量級王者。如果你需要的是超大規模代理池,以及從 SERP 到電商等各種用途的專用 API,這就是 Fortune 500 企業和所有重視穩定性的人的首選。
主要功能:
- 超大型代理網路(住宅、資料中心、行動、ISP),覆蓋 195+ 國家
- 具備反機器人、CAPTCHA 解決與無頭瀏覽器渲染的爬取 API
- 地理定位、會話持續性,以及高資料準確度(成功率 95%+)
- OxyCopilot:可自動生成解析程式碼與 API 查詢的 AI 助手
價格:
單一 API 起價約每月 49 美元,整合方案每月 149 美元。包含 7 天免費試用,最高可用 5,000 次請求。
使用者回饋:
在 ,以穩定性和支援品質受到好評。主要缺點?價格不便宜,但一分錢一分貨。
2. ScrapingBee
 概覽:
概覽:
ScrapingBee 是開發者的好朋友——簡單、實惠、重點明確。您只要送出 URL,它就會處理無頭 Chrome、代理和 CAPTCHA,然後回傳渲染後的頁面,或是您需要的資料。
主要功能:
- 無頭瀏覽器渲染(支援 JavaScript)
- 自動 IP 輪換與 CAPTCHA 解決
- 用於困難網站的 stealth 代理池
- 設定極簡——只要一次 API 呼叫
價格:
免費方案每月約 1,000 次呼叫。付費方案起價約每月 29 美元,可用 5,000 次請求。
使用者回饋:
一向有 的高評價。開發者很喜歡它的簡潔;但不寫程式的人可能會覺得功能有點太精簡。
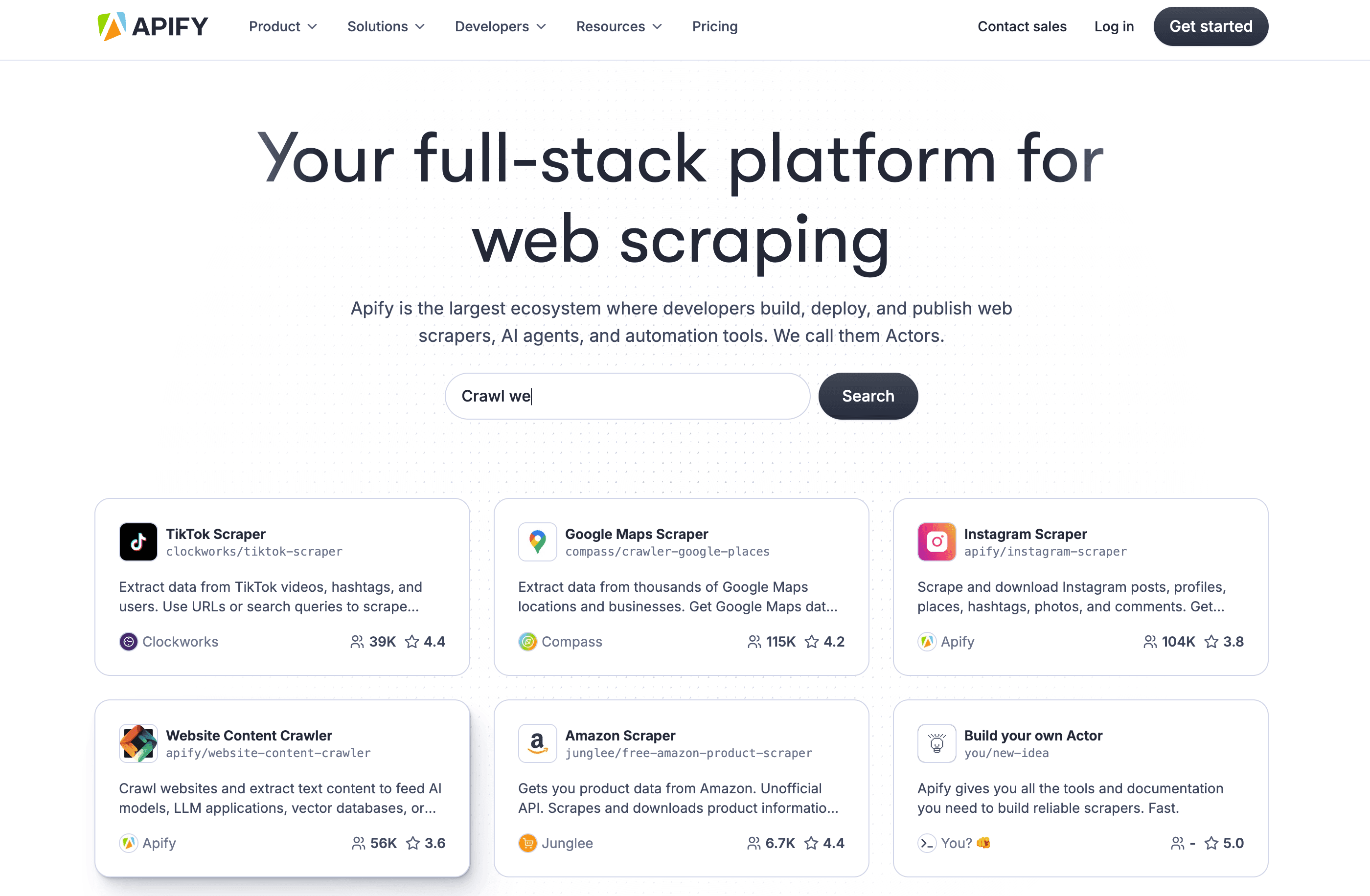
3. Apify
 概覽:
概覽:
Apify 是網頁爬取界的瑞士刀。您可以用 JavaScript 或 Python 建立客製化爬蟲(稱為「Actors」),也可以直接使用他們龐大的預建 actors 程式庫,抓取熱門網站。它的彈性幾乎可以滿足所有需求。
主要功能:
- 幾乎任何網站都能用的客製與預建爬蟲(Actors)
- 內建雲端基礎架構、排程與代理管理
- 可匯出為 JSON、CSV、Excel、Google Sheets 等多種格式
- 活躍社群與 Discord 支援
價格:
永久免費方案,另含每月 5 美元額度。付費方案從每月 39 美元起。
使用者回饋:
在 。開發者很愛它的彈性;新手則會需要一段學習曲線。
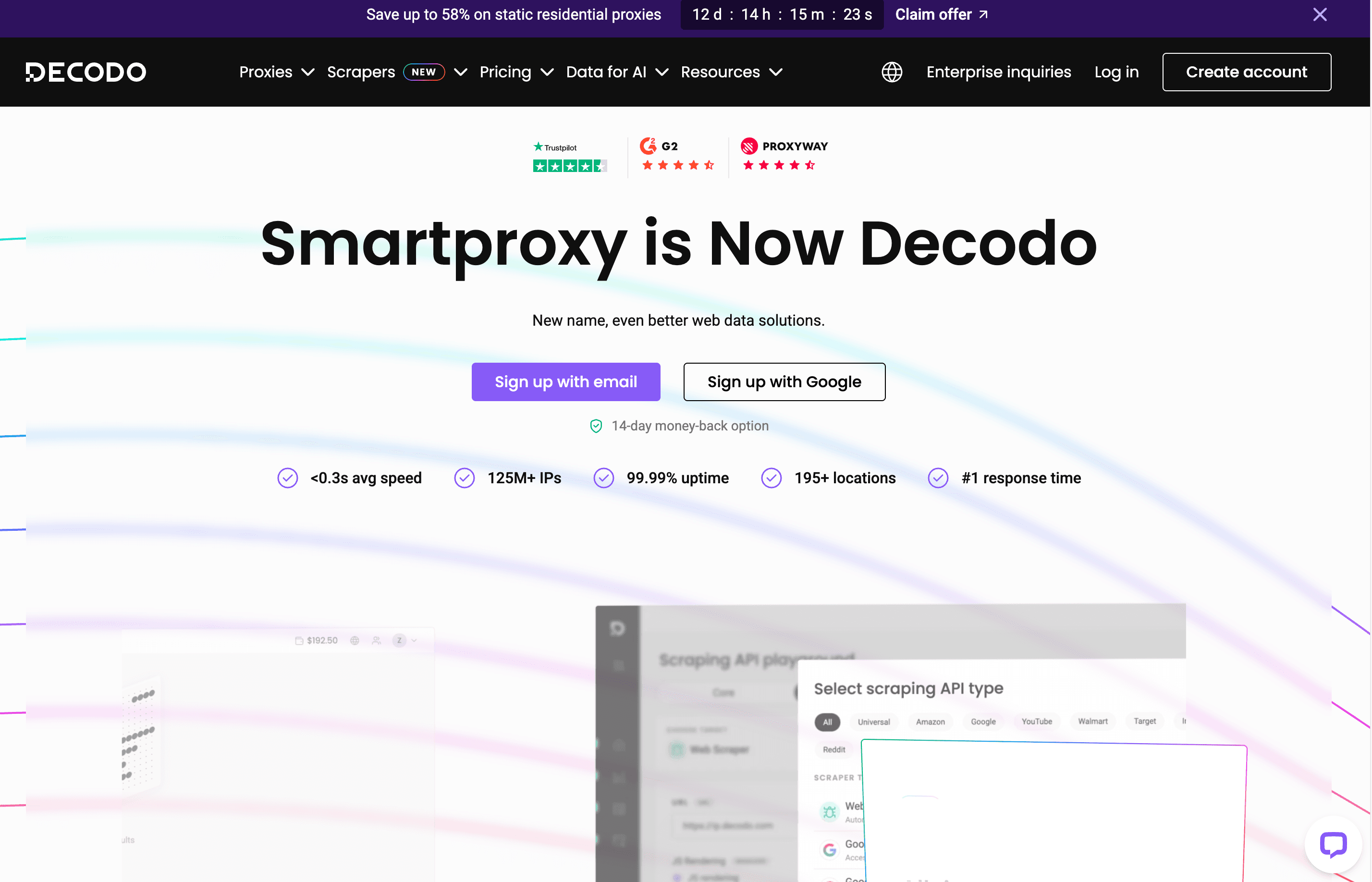
4. Decodo(前身為 Smartproxy)
 概覽:
概覽:
Decodo(由 Smartproxy 更名而來)主打高 CP 值與易用性。它把穩健的代理基礎架構與網頁、SERP、電商、社群媒體等爬取 API 結合在一起,而且全都包含在同一個訂閱裡。
主要功能:
- 所有端點共用的統一爬取 API(不再需要另外加購)
- 針對 Google、Amazon、TikTok 等的專用爬蟲
- 友善的儀表板,內建 playground 與程式碼生成器
- 24/7 即時聊天支援
價格:
每月約 50 美元起,可用 25,000 次請求。7 天免費試用包含 1,000 次請求。
使用者回饋:
以「超高性價比」和即時支援受到稱讚。在 。
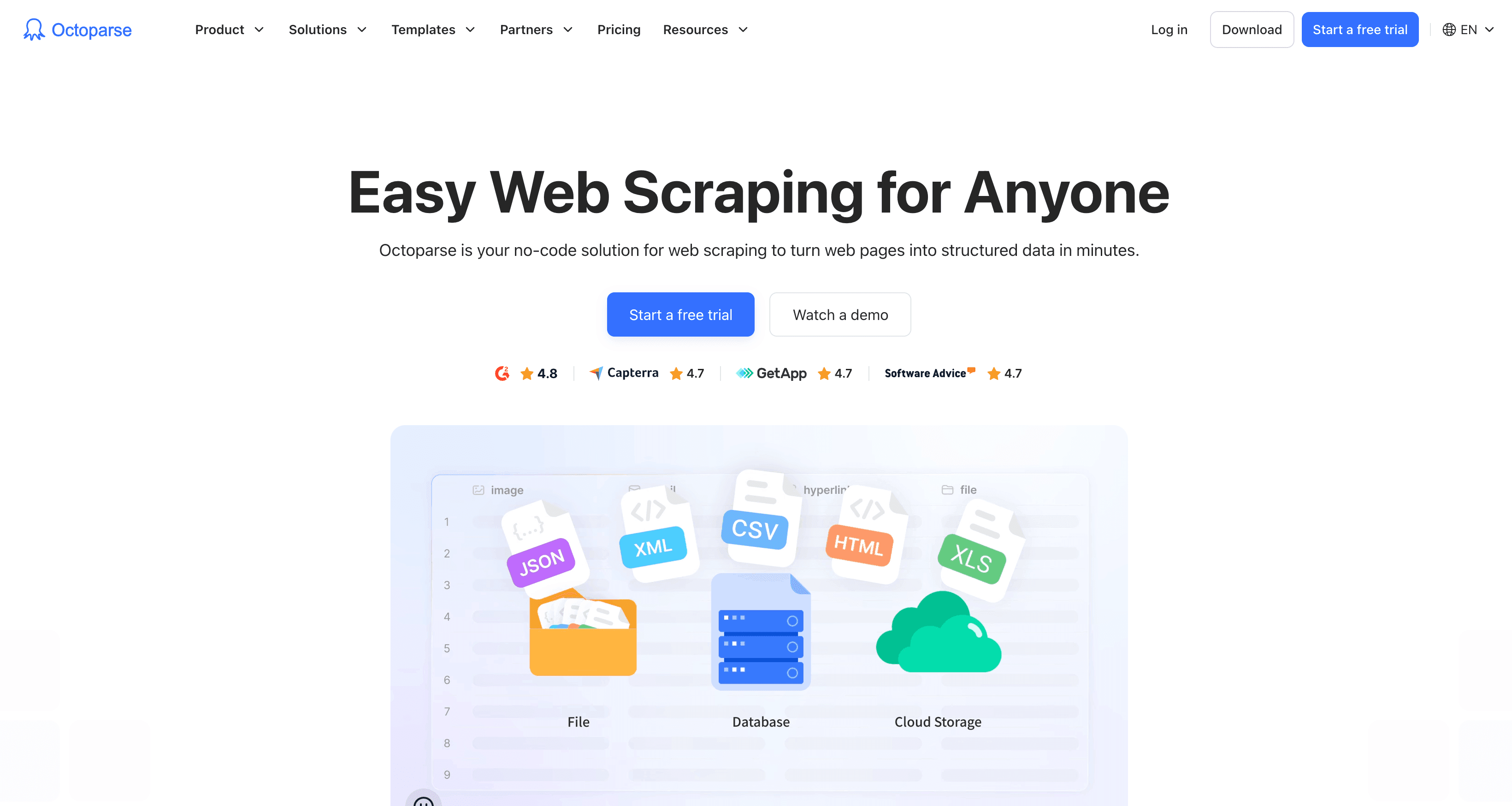
5. Octoparse
 概覽:
概覽:
Octoparse 是免程式碼領域的冠軍。如果您討厭寫程式,但喜歡資料,這個具備雲端功能的點選式桌面應用程式,可以讓您用視覺化方式建立爬蟲,並在本機或雲端執行。
主要功能:
- 視覺化工作流程建構器——只要點選就能選擇資料欄位
- 雲端擷取、排程與自動 IP 輪換
- 熱門網站範本,以及客製化爬蟲市集
- Octoparse AI:整合 RPA 與 ChatGPT,用於資料清理與工作流程自動化
價格:
免費方案最多可建立 10 個本機任務。付費方案起價每月 119 美元(含雲端功能、無限任務)。高級功能提供 14 天免費試用。
使用者回饋:
在 。不寫程式的人很愛,但進階使用者可能會碰到限制。
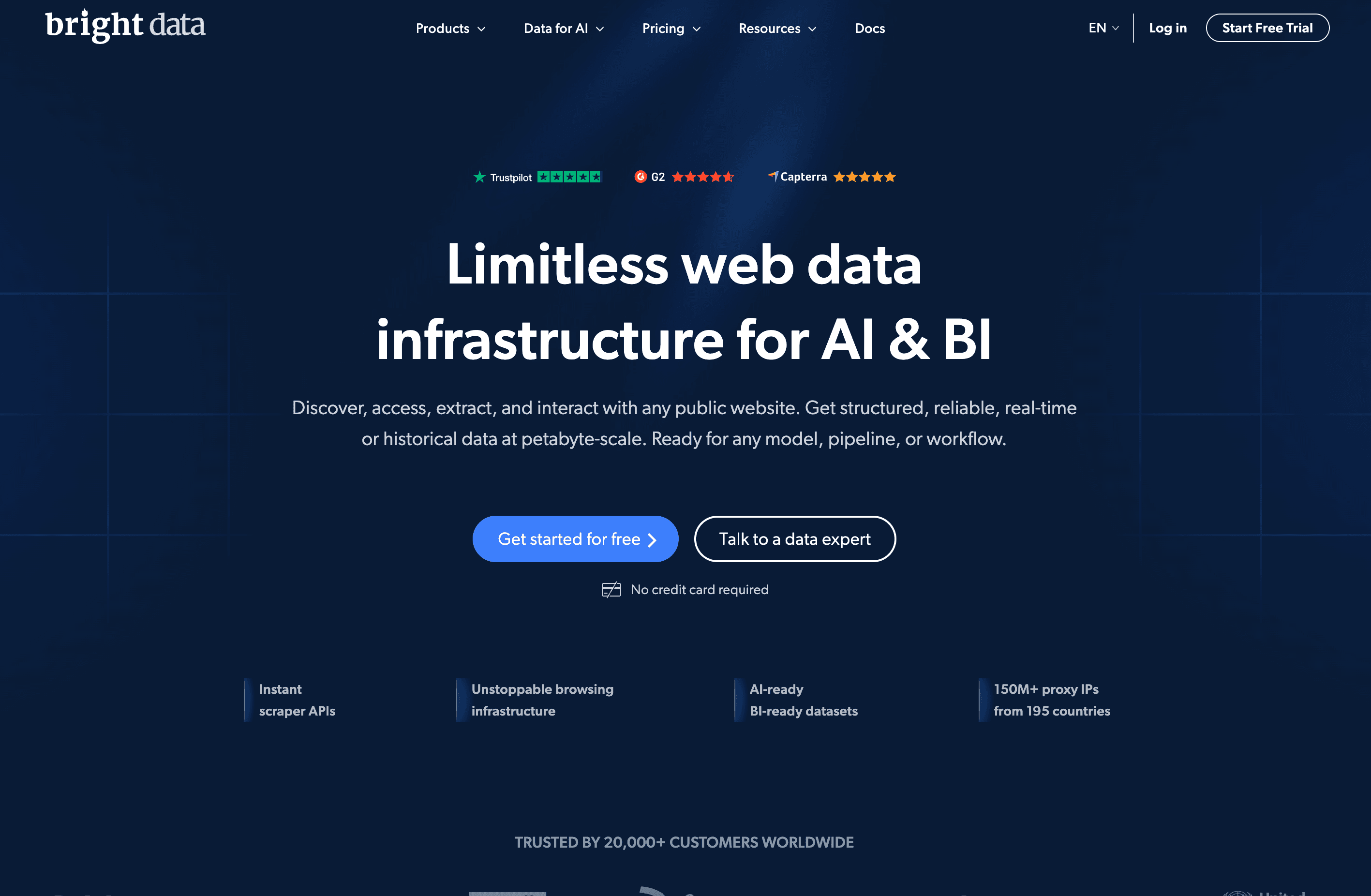
6. Bright Data
 概覽:
概覽:
Bright Data 是大咖中的大咖——如果你需要規模、速度,以及你想得到的所有功能,這就是你的平台。憑藉全球最大的代理網路與強大的爬取 IDE,它就是為企業打造的。
主要功能:
- 1.5 億+ IP(住宅、行動、ISP、資料中心)
- 網頁爬蟲 IDE、預建資料收集器,以及可直接購買的資料集
- 進階反機器人、CAPTCHA 解決與無頭瀏覽器支援
- 重視合規與法務(Ethical Web Data initiative)
價格:
按量付費:每 1,000 次請求約 1.05 美元,代理價格從每 GB 3–15 美元不等。大多數產品提供免費試用。
使用者回饋:
在效能與功能方面備受讚賞,但對小型團隊來說,價格與複雜度可能會是門檻。
7. WebAutomation
 概覽:
概覽:
WebAutomation 是一個專為非開發者設計的雲端平台。它有預建擷取器市集與免程式碼建構器,非常適合只想要資料、不想碰程式碼的商務使用者。
主要功能:
- 針對熱門網站的預建擷取器(Amazon、Zillow 等)
- 免程式碼擷取器建構器,採點選式介面
- 內建雲端排程、資料交付與維護
- 以列數計費(按你擷取的資料量付費)
價格:
專案方案每月 74 美元(約每年 40 萬列),按量付費為每 1,000 列 1 美元。14 天免費試用,含 1,000 萬點數。
使用者回饋:
使用者很喜歡它的易用性與透明定價。支援服務也很到位,維護則由團隊直接處理。
8. ScrapeHero
 概覽:
概覽:
ScrapeHero 一開始是客製化爬取顧問公司,現在則提供自助式雲端平台。您可以使用熱門網站的預建爬蟲,或直接委託他們進行全代管專案。
主要功能:
- ScrapeHero Cloud:提供 Amazon、Google Maps、LinkedIn 等預建爬蟲
- 免程式碼操作、排程與雲端交付
- 針對特殊需求的客製化解決方案
- 提供 API 以便程式化整合
價格:
雲端方案最低每月 5 美元起。客製專案每個網站起價 550 美元(一次性)。
使用者回饋:
以穩定性、資料品質與支援受到好評。非常適合從 DIY 擴展到代管方案。
9. Sequentum
 概覽:
概覽:
Sequentum 是企業級的瑞士刀——專為合規、可稽核性與大規模需求打造。如果您需要 SOC-2 認證、稽核軌跡與團隊協作,這就是您的工具。
主要功能:
- 低程式碼 agent 設計工具(點選式加上腳本)
- 雲端 SaaS 或地端部署
- 內建代理管理、CAPTCHA 解決與無頭瀏覽器
- 稽核軌跡、角色權限與 SOC-2 合規
價格:
按量付費(執行時間每小時 6 美元、匯出每 GB 0.25 美元),Starter 方案每月 199 美元。註冊即送 5 美元免費額度。
使用者回饋:
企業很喜歡它的合規功能與擴展性。雖然需要一些學習曲線,但支援與培訓品質都很高。
10. Grepsr
 概覽:
概覽:
Grepsr 是一項代管資料擷取服務——您只要告訴他們需要什麼,他們就會替您建立、執行並維護爬蟲。對於想要資料、但不想被技術細節拖累的企業來說,這非常完美。
主要功能:
- 代管擷取(「Grepsr Concierge」)——他們會幫您完成全部設定與維護
- 雲端儀表板可用於排程、監控與下載資料
- 多種輸出格式與整合(Dropbox、S3、Google Drive)
- 依資料筆數計費(不是按請求次數)
價格:
Starter pack 為 350 美元(一次性擷取),長期訂閱則採客製報價。
使用者回饋:
客戶很喜歡完全不用自己動手的體驗,以及快速回應的支援。非常適合非技術團隊與重視時間勝過反覆調整的人。
網頁爬取 API 頂尖平台快速比較表
這裡是 10 個平台的速查表:
| 平台 | 支援的資料類型 | 起始價格 | 免費試用 | 易用性 | 支援 | 特色功能 |
|---|---|---|---|---|---|---|
| Oxylabs | 網頁、SERP、電商、房地產 | $49/月 | 7 天/5k 請求 | 偏開發者 | 24/7、企業級 | OxyCopilot AI、超大代理池、地理定位 |
| ScrapingBee | 一般網頁、JS、CAPTCHA | $29/月 | 1k 次呼叫/月 | 簡單 API | Email、論壇 | 無頭 Chrome、stealth 代理 |
| Apify | 任何網頁、預建/客製 | 免費/$39/月 | 永久免費 | 彈性高、較複雜 | 社群、Discord | Actor 市集、雲端基礎架構、整合 |
| Decodo | 網頁、SERP、電商、社群 | $50/月 | 7 天/1k 請求 | 友善易用 | 24/7 即時聊天 | 統一 API、程式碼 playground、高 CP 值 |
| Octoparse | 任何網頁、免程式碼 | 免費/$119/月 | 14 天 | 視覺化、免程式碼 | Email、論壇 | 點選式介面、雲端、Octoparse AI |
| Bright Data | 全類型網頁、資料集 | $1.05/1k 請求 | 有 | 強大、複雜 | 24/7、企業級 | 全球最大代理網、IDE、現成資料集 |
| WebAutomation | 結構化資料、電商、房地產 | $74/月 | 14 天/1,000 萬列 | 免程式碼、範本 | Email、聊天 | 預建擷取器、按列計費 |
| ScrapeHero | 電商、地圖、職缺、客製 | $5/月 | 有 | 免程式碼、代管 | Email、工單 | 雲端爬蟲、客製專案、Dropbox 交付 |
| Sequentum | 任何網頁、企業級 | $0/$199/月 | $5 額度 | 低程式碼、視覺化 | 高接觸支援 | 稽核軌跡、SOC-2、地端/雲端 |
| Grepsr | 任何結構化資料、代管 | $350 一次性 | 範例執行 | 全代管 | 專屬代表 | Concierge 設定、依資料計費、整合 |
為你的企業選擇合適的網頁爬取工具
那麼,你該選哪一個?以下是我幫我所諮詢團隊拆解的方式:
-
如果你想要免程式碼、立即出結果,還要 AI 幫你清理資料:
選 。它是從「我需要資料」到「我拿到資料」最快的路徑——而且你不用一直盯著腳本或 API。
-
如果你是喜歡掌控與彈性的開發者:
試試 Apify、ScrapingBee 或 Oxylabs。這些工具給你的能力最多,但你也得處理一些設定與維護。
-
如果你是想用視覺化工具的商務使用者:
WebAutomation 很適合點選式爬取,尤其是電商和名單開發場景。
-
如果你需要合規、可稽核性或企業功能:
Sequentum 就是為你打造的。價格較高,但對受監管產業來說很值得。
-
如果你只想讓別人全包:
Grepsr 或 ScrapeHero 的代管服務就是正解。你會多付一點錢,但你的血壓會感謝你。
如果你還是不確定,多數平台都有免費試用——那就先試試看吧!
重點整理
- 網頁爬取 API 如今已是資料驅動企業的必備工具——市場規模預計到 2030 年將達到 。
- 手動爬取已經過時——在反機器人技術、代理與網站變動之間,API 和 AI 工具才是可擴展的唯一解法。
- 每個 API/平台各有強項:
- Oxylabs 與 Bright Data:規模與穩定性
- Apify:彈性
- Decodo:高 CP 值
- WebAutomation:免程式碼
- Sequentum:合規
- Grepsr:全代管、免動手的資料服務
- AI 驅動自動化(像 Thunderbit)正在改變遊戲規則——提供更高成功率、零維護,以及傳統 API 做不到的內建資料處理。
- 最好的工具,就是最符合您的工作流程、預算與技術能力的工具。 別害怕嘗試!
如果你已經準備好告別壞掉的腳本與無止盡的除錯,試試 ,或到 看更多指南,深入了解如何爬取 Amazon、Google、PDF 等內容。
也別忘了:在網頁資料的世界裡,變化最快的不只是網站本身,還有我們用來爬取它們的技術。保持好奇、持續自動化,願您的代理永遠不會被封鎖。