

我需要追蹤 200 多個新聞來源,掌握熱門文章。人工來做?那幾乎等於一份全職工作。傳統爬蟲呢?只要網站版面一改,就會立刻失效。
後來我試了 AI 文章爬蟲。只要按一下,就能拿到乾淨的資料,還不用自己寫 CSS 選擇器。差別真的非常大。
如果你是記者、SEO 專家,或需要大規模抓取文章的研究人員,這篇比較應該能幫你省下不少試錯時間。我測試了傳統無程式碼爬蟲和 AI 驅動的工具,以下是實際好用的選擇。
用 AI 抓取任何網站 Get Started Free
TL;DR
| 優點 | 缺點 | 最適合 | |
|---|---|---|---|
| AI 文章爬蟲 | - 可高準確度抓取多個網站 - 自動去除雜訊 - 能因應網站結構變動 - 支援動態內容載入 - 資料清理成本低 | - 運算成本較高 - 處理時間較長 - 部分頁面可能需要人工介入 - 可能觸發反爬機制 | - 抓取複雜或動態內容網站(例如新聞入口、社群媒體) - 大規模資料蒐集 |
| 傳統無程式碼文章爬蟲 | - 執行速度快 - 成本較低 - 伺服器與本機資源占用低 - 可控性高 | - 網站結構變動後需要頻繁維護 - 無法同時抓取多個網站 - 無法處理動態內容 - 資料清理成本高 | - 快速、大規模抓取簡單靜態網頁 - 運算資源有限、預算受限 |
什麼是文章爬蟲?為什麼 AI 文章爬蟲很重要?
文章爬蟲 是一種 網頁爬蟲,能從新聞網站中找出並擷取標題、作者、發佈日期、內容、關鍵字、圖片和影片等資訊,並整理成 JSON、CSV 或 Excel 這類結構化格式。
傳統無程式碼文章爬蟲 依賴 CSS 選擇器,根據網頁的 HTML 結構來擷取內容。不過這種做法也有幾個缺點:
- 通用性不足: 不同網站結構不同,每個網站都要用特定的 CSS 選擇器,而且網站結構一變就可能失效,得頻繁更新。
- 無法處理動態內容: 很多網站會用 AJAX 或 JavaScript 載入內容,這是 CSS 選擇器 無法直接抓取的。
- 資料處理能力有限: CSS 選擇器 只能擷取 HTML 片段,無法直接完成後續的資料清理、格式化、語意分析或情緒分析。
 接著就是 AI 文章爬蟲。
接著就是 AI 文章爬蟲。
-
這項技術會使用 LLM 理解網頁內容,帶來以下能力:
- 智慧辨識: 辨認標題、作者、摘要與主要內容。
- 自動去除雜訊: 區分主要內容、導覽列、廣告與相關文章,提升資料品質與抓取效率。
- 適應網站變化: 即使網站結構或樣式改變,AI 仍可透過語意理解與視覺特徵持續抓取。
- 跨站泛化能力: 不像 傳統爬蟲,AI 爬蟲可直接套用到不同網站,無需手動調整。
- 結合 NLP 與深度學習: 可完成翻譯、摘要與情緒分析等任務。
2026 年什麼樣的文章爬蟲才算最佳?
一款頂尖的文章爬蟲,必須在效能、成本、易用性、彈性與擴充性之間取得平衡。以下是挑選 2026 年最佳文章爬蟲的標準:

- 易用性: 介面直覺,不需要寫程式。
- 文章擷取準確度: 能精準辨識相關資訊,不會把廣告或導覽列一起抓進來。
- 網站變動適應性: 能自動因應網站結構或樣式變化,不必頻繁維護。
- 不同網站適應性: 可跨多種網站結構運作。
- 動態內容處理: 支援 JavaScript 或 AJAX 動態載入內容。
- 多媒體處理: 能辨識圖片、影片與音訊。
- 反爬處理: 使用 IP 輪替、CAPTCHA 解法與代理伺服器繞過反爬機制。
- 資源使用平衡: 不會過度消耗記憶體與運算資源。
一眼看懂最佳文章與新聞爬蟲
| 工具 | 主要功能 | 最適合 | 價格 |
|---|---|---|---|
| Thunderbit | AI 驅動爬蟲;預建範本;支援 pdf、圖片與文件抓取;進階資料處理能力 | 沒有技術背景、需要抓取多個利基網站的使用者 | 7 天免費試用,年繳方案每月 $9 起 |
| WebScraper.io | 瀏覽器擴充功能;支援動態內容;缺少代理整合 | 不需要處理複雜網頁或進階功能的使用者 | 7 天免費試用,年繳方案每月 $40 起 |
| Browse.ai | 無程式碼網頁爬蟲與監控;預建機器人;虛擬瀏覽器;多種分頁方法;強大整合能力 | 需要大規模抓取複雜網站的企業 | 年繳方案每月 $19 |
| Octoparse | 基於 CSS 選擇器的無程式碼爬蟲;可自動偵測並產生抓取流程;預建文章爬蟲範本;虛擬瀏覽器;反反爬機制 | 需要抓取複雜網站的企業 | 年繳方案每月 $99 起 |
| Bardeen | 全方位網頁自動化能力;預建範本;無程式碼爬蟲;可與工作區無縫整合 | 將文章抓取嵌入既有工作流程的 GTM 團隊 | 7 天免費試用,年繳方案每月 $99 起 |
| PandaExtract | 介面友善;自動偵測與標記 | 需要快速、單擊即可擷取,且不想設定太複雜的使用者 | $49 一次買斷 |
商業用戶最強大的 AI 文章爬蟲
- 優點:
- 缺點:
- 目前僅提供 Chrome 擴充功能
- 不適合大規模資料抓取
- 多頁抓取速度較慢,但可在背景執行以加快結果產出
適合企業使用的 AI 驅動文章爬蟲
Browse.ai
- 優點:
- 無程式碼文章爬蟲與監控工具
- 支援虛擬瀏覽器操作,避免觸發反爬機制
- 內建大量文章抓取機器人,可一鍵抓取 Google 新聞、Medium、Hacker News 等網站
- 與 Zapier 和 Make 等平台深度整合,方便串接工具
- 缺點:
- 使用深度擷取時需要建立兩個機器人,流程較複雜
- CSS 選擇器對利基網站的精準度不足
- 價格偏高,更適合大規模、持續性的資料抓取任務
適合小規模資料擷取的無程式碼爬蟲
PandaExtract
- 優點:
- 介面友善,可自動辨識文章列表與詳細內容
- 可擷取清單、詳情、電子郵件與圖片,適合小規模結構化資料抓取
- 一次付費,終身使用
- 缺點:
- 只有瀏覽器擴充功能版本,無法在雲端執行
- 免費版只支援複製,不支援匯出成 CSV、JSON 等格式
開箱即用、適合組織的文章爬蟲
Octoparse
- 優點:
- 無程式碼文章爬蟲,具備自動偵測功能,可識別網站結構並產生抓取流程
- 提供大量預建文章爬蟲範本,可直接使用
- 使用虛擬瀏覽器搭配 IP 輪替、CAPTCHA 解法與代理伺服器,繞過反爬機制
- 缺點:
- 自動偵測仍依賴 CSS 選擇器邏輯,準確度一般
- 進階功能需要學習與技術能力
- 大規模資料抓取成本高
GTM 團隊最完整的自動化工具
Bardeen
- 優點:
- 以 LLM 驅動的一鍵自動化無程式碼文章爬蟲
- 可與超過 100 種應用整合,包括 Google 試算表、Slack 與 Zoom
- 強大的網頁自動化工具,可在資料抓取後進行 AI 分析
- 非常適合將資料抓取嵌入既有工作流程
- 缺點:
- 高度依賴預建 playbook,自訂流程需要反覆試錯
- 雖然是無程式碼平台,但對非技術使用者來說,理解並設定複雜自動化仍可能需要學習時間
- 子頁面擷取設定複雜
- 非常昂貴
即時資料擷取的輕量級文章爬蟲
Webscraper.io
- 優點:
- 具備點選式介面的無程式碼爬蟲
- 支援動態內容載入
- 雲端作業
- 可整合 Dropbox、Google 試算表 與 Amazon
- 缺點:
- 沒有預建範本,需要自行建立 sitemap
- 不熟悉 CSS 選擇器的使用者會有學習門檻
- 分頁與子頁面擷取設定較複雜
- 雲端版本價格偏高
給工程師的進階方案
如果你有技術背景,市面上也有 文章爬蟲 API 可用。這類方案提供:
- 彈性: 可直接透過 API 呼叫進行自訂抓取,支援動態渲染與 IP 輪替
- 擴充性: 可整合進自訂資料管線,滿足企業級高頻率、大規模資料需求
- 低維護成本: 不必自行管理代理池或反爬策略,節省營運時間
API 方案一眼看懂
| API | 優點 | 缺點 |
|---|---|---|
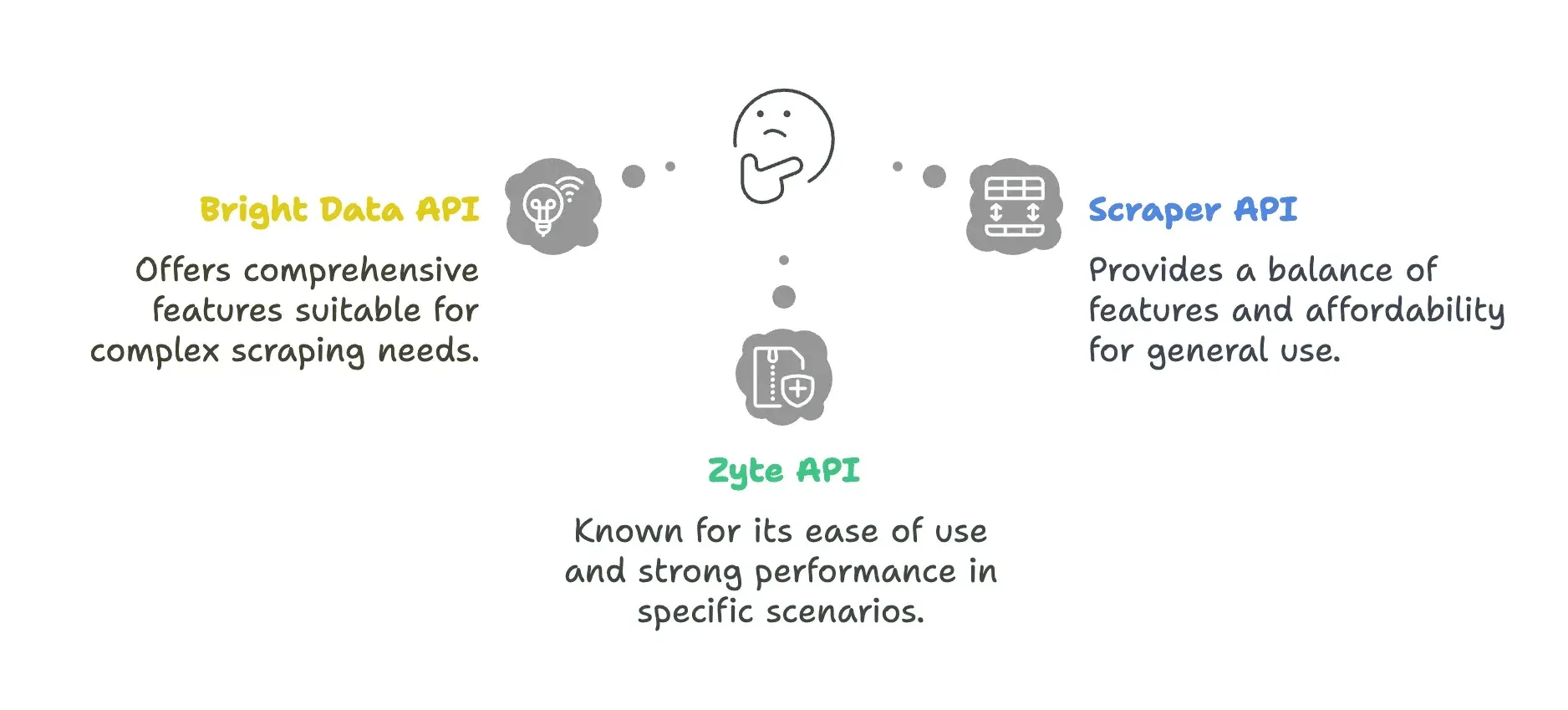
| Bright Data API | - 廣泛的代理網路(195 個國家、超過 7,200 萬個 IP) - 進階地理定位可精細到城市/郵遞區號層級 - 強大的 Proxy Manager,可進行 IP 輪替 | - 回應時間較慢(平均 22.08 秒) - 價格較高,不適合小團隊 - 設定門檻較高 |
| ScraperAPI | - 入門價格低,從 $49 起 - Autoparse 可自動擷取資料 - 提供 Web UI 播放器供測試 | - 被封鎖的請求仍可能計費 - JavaScript 渲染功能有限 - 加上進階參數後成本可能快速上升 |
| Zyte API | - 具備 AI 解析能力 - 失敗請求不收費 | - 前期成本較高(每月約 $450) - 點數不會跨月累積 |
- Bright Data Web Scraper API
- Scraper API
- 優點:
- 提供全球 4,000 萬個代理,自動切換資料中心/住宅 IP,可繞過 Cloudflare 驗證,並整合第三方 CAPTCHA 解法(例如 2Captcha)
- 有結構化端點與非同步爬蟲,抓取速度更快
- 缺點:
- 動態頁面渲染需額外收費,對複雜 AJAX 網站支援有限
- 優點:
- Zyte API
- 優點:
- 以 AI 驅動的自動網頁資料擷取,不需要為每個網站開發與維護擷取規則
- 彈性的按量計費方案
- 缺點:
- 進階功能(例如 session 處理、可程式化瀏覽器)需要學習
- 優點:
如何選擇你的文章與新聞爬蟲?
挑選文章與新聞爬蟲時,請考慮你的業務需求、技術背景與預算。

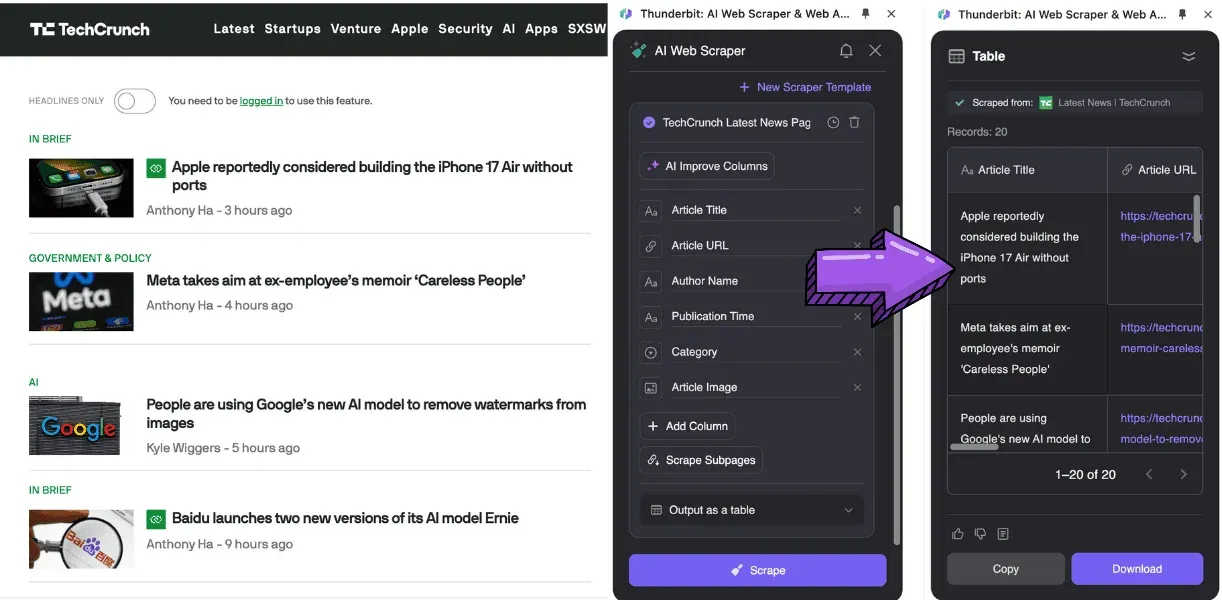
- 如果你需要抓取多個利基網站,又不想為每個頁面各自建立一個爬蟲,而且預算充足,Thunderbit 會是最佳選擇。它不依賴 CSS 選擇器,而是用 AI 分析網頁結構,還能在資料抓取後進一步做 AI 分析。對 Thunderbit AI 來說,所有網站都一樣,能準確抓取整篇文章。
- 如果你要抓取像 華爾街日報 或 Google 新聞 這類大型網站的新聞與文章,你需要具備強大反爬機制與預建範本的文章爬蟲,例如 Browse.ai 或 Octoparse。不過,最佳選擇其實是像 Thunderbit 這樣的 Chrome 擴充功能:資料抓取流程模擬個人瀏覽與複製,因此可直接帶入登入資訊,不需要複雜設定。
- 如果你需要大規模、持續性的資料抓取,像 Octoparse 這種具備排程功能的工具會更合適。
- 如果你想讓團隊使用,並無縫整合進既有工作流程,Bardeen 是理想選擇,因為它除了文章抓取外,還提供多種網頁自動化工具。
- 如果你想找一款輕量級文章爬蟲,用於小量資料擷取,又不想花時間學習,那就選擇像 PandaExtract 這種點選式文章爬蟲。
- 如果你有技術背景,或正在打造企業級文章爬蟲,除了這些 無程式碼爬蟲 之外,也可以考慮 API 工具或自行開發爬蟲。
結論
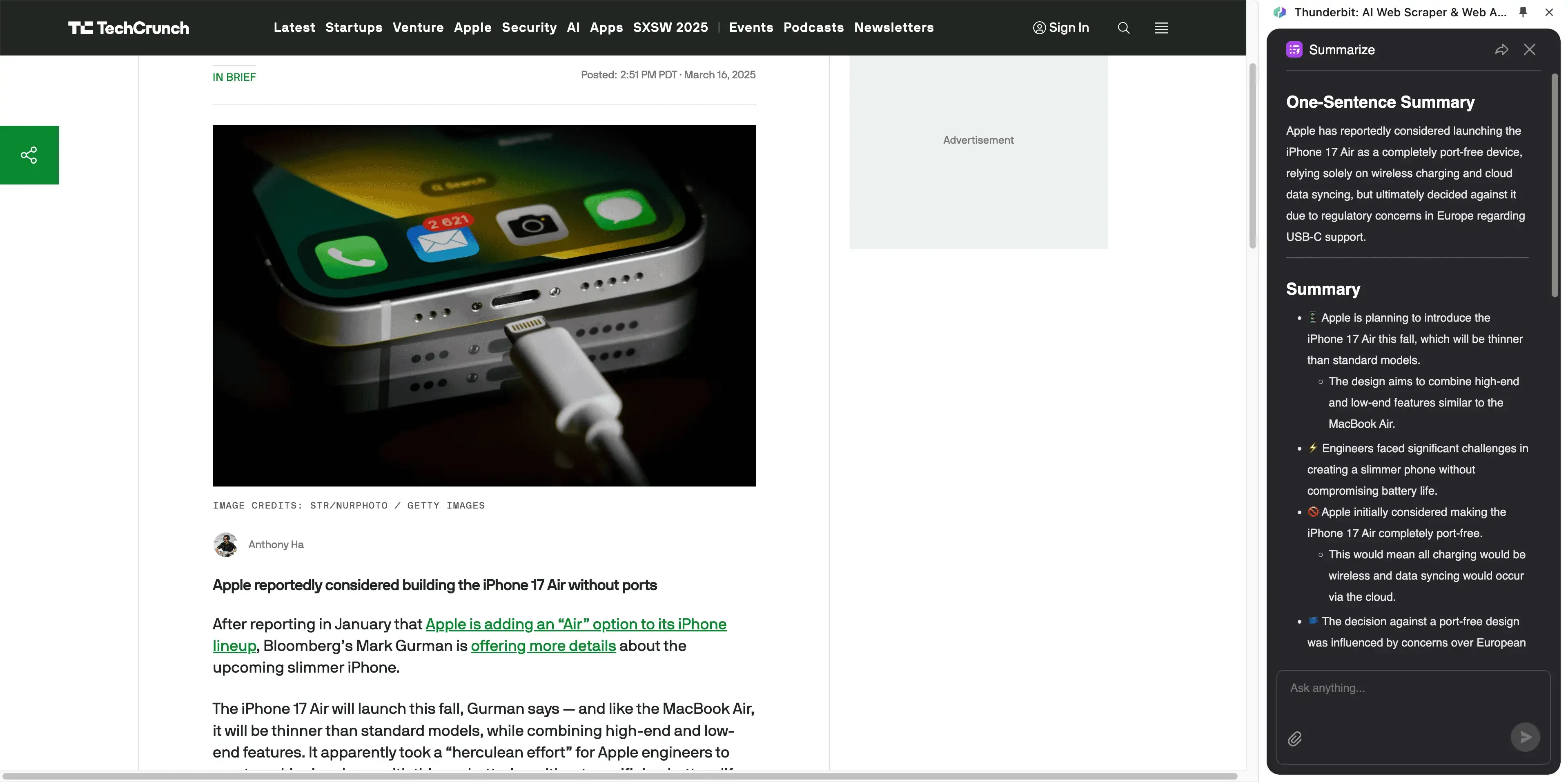
本文介紹了文章與新聞爬蟲的概念與商業應用情境。傳統爬蟲 建立在 CSS 選擇器 之上,因此需要具備一些網頁 HTML 與 CSS 的知識,尤其在進階操作時更是如此。新一代的 AI 驅動文章爬蟲 則完全仰賴 AI 的語意理解與視覺辨識能力,在適應網站結構變動、跨站泛化、處理動態內容,以及後續資料清理與分析等方面,都優於 傳統爬蟲。
本文也列出了六款實用的文章與新聞爬蟲及給開發者使用的 API 工具,並比較它們的優缺點、適合的資料規模、網站特性與目標使用者。當你考慮文章與新聞抓取時,請選擇最符合業務需求、同時兼顧效能與成本的方案。
常見問題
1. 什麼是 AI 文章爬蟲,它是如何運作的?
- 使用 AI 分析並擷取網頁內容,不需要 CSS 選擇器。
- 能高準確度辨識標題、作者、發佈日期與主要內容。
- 會自動移除廣告、導覽列與其他無關元素。
- 可因應網站結構變化,並跨不同網站運作。
2. 與傳統爬蟲相比,使用 AI 驅動的文章爬蟲有什麼好處?
- 可用單一工具從多個網站擷取內容。
- 能處理動態內容,包括 JavaScript 與 AJAX 載入的頁面。
- 與基於 CSS 的爬蟲相比,需要更少手動設定與維護。
- 還提供摘要、翻譯與情緒分析等額外功能。
3. 我沒有程式基礎,也能用 Thunderbit 進行 AI 文章抓取嗎?
- 可以,Thunderbit 是為非技術使用者設計,介面簡單、無程式碼。
- 使用 AI 自動偵測並擷取文章內容。
- 提供預建範本,可快速且有效率地抓取。
- 可將資料匯出為 CSV、JSON 與 Google 試算表等多種格式。
延伸閱讀:
試用 AI 網頁爬蟲 Get Started Free




