
数据驱动着这个世界。到了 2026 年,把网页数据转化为商业洞察的需求,比以往任何时候都更强。我亲眼见过销售、运营和营销团队争分夺秒地自动化调研、监控竞品,并搭建更智能的数据管道——而这一切背后,网页爬虫都在发力。但问题是:掌握网页爬虫,可不是看几篇教程就够了。你得真正卷起袖子,在真实网站上练手,而且有些网站还相当棘手。
找到合适的网页爬虫测试网站,常常像在干草堆里找针。有些网站太简单,有些网站布满反爬防线,还有一些网站纯粹就是“奇葩”。所以我整理了这份最适合练习网页爬虫的 10 个样本网站清单——从入门基础到高级的动态数据处理,帮你一步步提升实战能力。不管你是想抓取电商商品列表、论坛内容,还是电影评论,这篇指南都能帮你升级技能,避开爬虫挫败感带来的“404 错误”。
为什么要在样本网站上练习网页爬虫?
说到底,网页爬虫就是一项动手活。没错,你可以把 YouTube 教程看个遍,但在真正碰到 HTML、动态内容,还有偶尔冒出来的 CAPTCHA 之前,你其实都不算真正入门。在网页爬虫测试网站上练习,是最好的方式,可以帮助你:
- 理解不同的数据结构: 从简单表格到嵌套列表,再到 AJAX 加载内容,每个网站都是一道新题。
- 测试工具和技能: 看看你的爬虫(或者你最喜欢的工具,比如 )如何处理分页、子页面和反爬技巧。
- 为业务场景做准备: 真实世界里的爬取工作,正在为各行各业的公司提供能力。
数据也能证明这一点:全球网页爬虫市场在,而近都表示,数据驱动决策对成功至关重要。但真正的秘诀是什么?最好的爬虫工程师不只是会写代码的人——他们还是永远在测试的人,会不断在新网站上打磨自己的技能。
我们是如何挑选最佳网页爬虫练习网站的
并不是所有网页爬虫样本网站都一样。为了这份清单,我重点选择了这些网站:
- 提供多种数据类型: 文本、数字、图片、评分、评论等等。
- 复杂度各不相同: 从静态 HTML 到动态、JavaScript 密集型页面。
- 合法且安全可抓取: 要么就是专门为练习而建,要么是公开的非登录页面。
- 模拟真实业务场景: 电商、论坛、评论站等。
- 能让你接触反爬措施: 因为在真实环境里,你一定会遇到 CAPTCHA、限流和 AJAX。
我也特别确保这些网站既适合测试传统的代码型爬虫,也适合测试像 Thunderbit 这样现代、无代码的工具。准备好开始了吗?走起。
1. Thunderbit:一站式网页爬虫测试平台
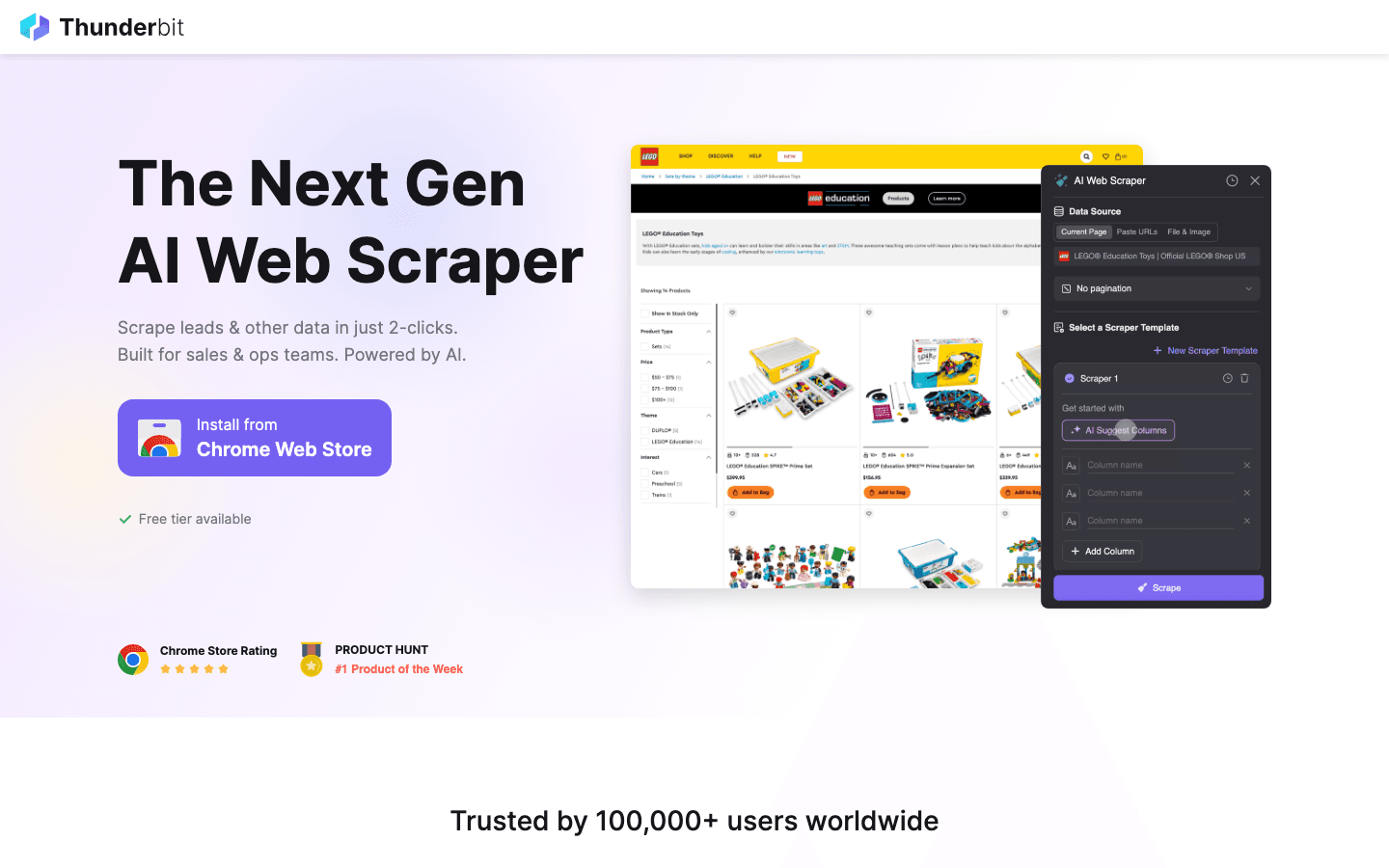
不只是一个工具——它还是任何认真练习网页爬虫的人都能上手的试验场。作为一个多年做过、也拆过爬虫的人,我可以很明确地说:从简单列表到复杂得要命的动态电商网站,Thunderbit 都是我测试时的首选。
Thunderbit 为什么突出:
- AI 驱动的爬取: 只要点一下“AI Suggest Fields”,Thunderbit 就会读取页面,判断最合适的字段,甚至帮你写好提取逻辑。无需编程,也不用跟选择器死磕。
- 复杂网站也能处理: Thunderbit 在棘手的 HTML、动态内容,以及带子页面或无限滚动的网站上表现出色。它就像网页爬虫界的瑞士军刀。
- 支持子页面与分页: 想先抓商品列表,再逐个进入详情页补充信息?Thunderbit 的子页面抓取让这件事变得轻松很多。
- 即时导出数据: 结果可以直接导出到 Excel、Google Sheets、Airtable 或 Notion——免费且不限量。
- 免费提取器: 一键提取邮箱、电话号码和图片,特别适合销售和线索生成练习。
- 热门网站模板: Amazon、Zillow、Shopify 等模板应有尽有——选一个就能开干。
- 对新手友好: 非技术用户都很喜欢它,因为“几乎不用学什么就能开始”()。
练习场景:
- 抓取电商商品列表(比如 Amazon 或 eBay),并补充子页面信息。
- 从商业目录中提取联系方式。
- 自动化市场调研中重复的数据采集任务。
Thunderbit 是这份清单里唯一一个既能练爬取、又能练工作流自动化的网站。是的,它可以免费试用——你很快就会明白,为什么它是我给所有水平用户的首选。
2. Codeforces:练习抓取结构化编程数据
 是练习抓取结构化、表格化数据的宝库。这个竞技编程网站包含:
是练习抓取结构化、表格化数据的宝库。这个竞技编程网站包含:
- 比赛列表: 以表格形式展示比赛名称、日期和链接。
- 题目集: 带有题目名称、标签和难度评分的嵌套表格。
- 用户排名: 含有积分和统计数据的排行榜与用户主页。
为什么它很适合练习:
- 能让你练习解析 HTML 表格、嵌套列表和多页结果。
- 大部分数据都是静态 HTML——不用处理登录或 JavaScript 麻烦。
- 能模拟抓取招聘网站或学术结果这类真实场景。
小建议:试着把某场比赛里的所有题目都提取出来,或者搭一个高分用户排行榜。你会很快学会如何处理结构化数据和分页。
3. Books to Scrape:经典网页爬虫练习网站
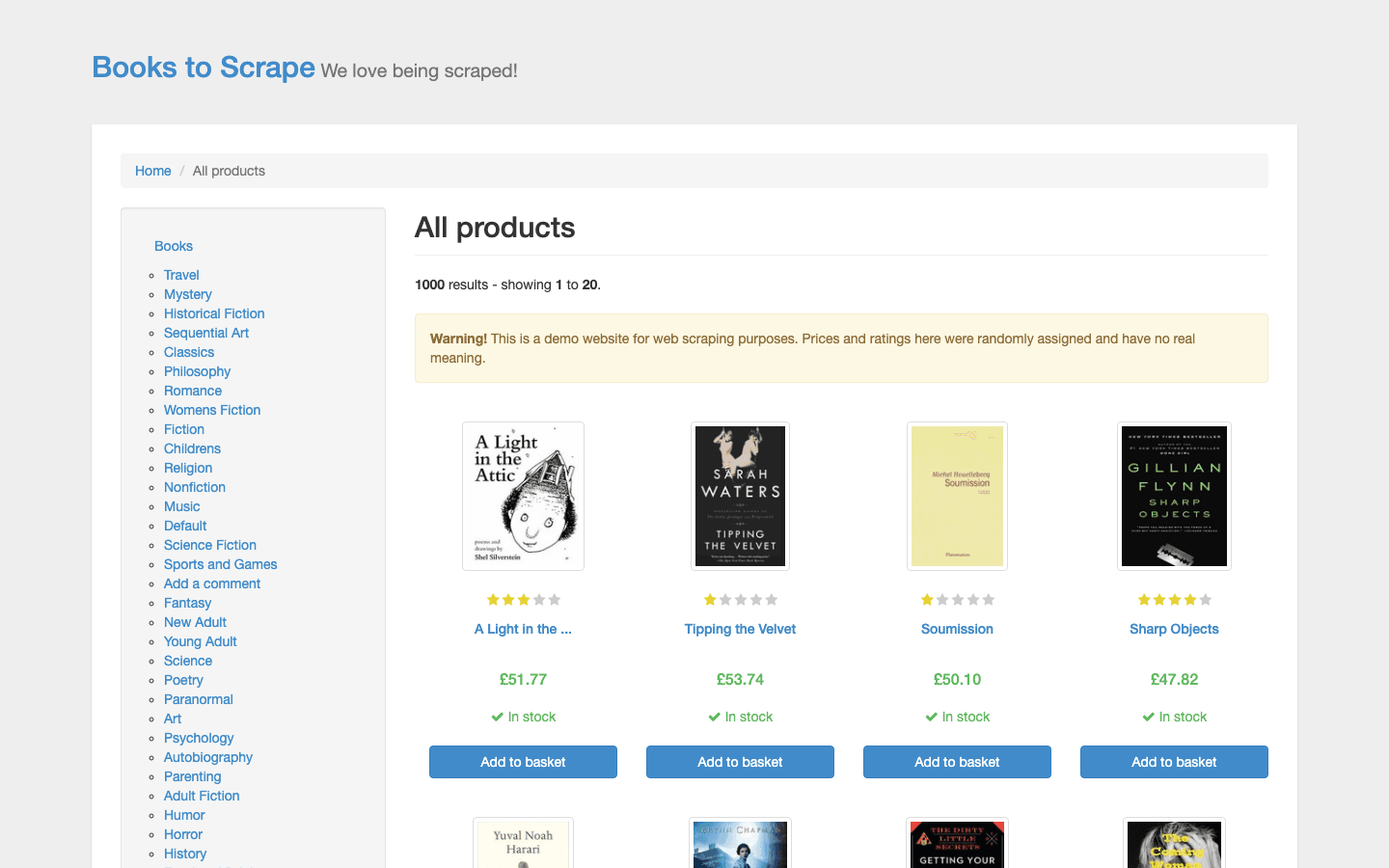 可以说是网页爬虫里的“hello world”。这个虚构的在线书店是专门为新手设计的,但别被它骗了——它也是掌握基础的绝佳地方。
可以说是网页爬虫里的“hello world”。这个虚构的在线书店是专门为新手设计的,但别被它骗了——它也是掌握基础的绝佳地方。
你会看到什么:
- 静态 HTML 商品列表: 标题、价格、评分和分类。
- 分页: 练习跨多个页面抓取。
- 结构统一: 非常适合学习选择器和循环。
练习任务:
- 提取所有书名和价格。
- 抓取评分和库存状态。
- 处理分页,拿到完整目录。
这个网站之所以在教程里这么常见,是因为它安全、可预测,而且在你去挑战真实互联网之前,特别适合用来建立信心()。
4. HackerRank:适合练习文本和算法数据的网页爬虫网站
 才是真正“有味道”的地方。这个编程挑战平台充满了:
才是真正“有味道”的地方。这个编程挑战平台充满了:
- 动态内容: 题目描述、测试用例和排行榜。
- 用户主页: 统计数据、徽章和排名。
- 登录/认证: 很多页面都需要用户会话。
为什么它是很好的测试网站:
- 能教你处理登录流程和会话 cookie。
- 会让你接触 JavaScript 渲染内容和 AJAX。
- 非常适合练习抓取编程题、用户统计或比赛结果。
如果你想学会怎么抓取那些不会乖乖配合普通 HTTP 请求的网站,HackerRank 就是你的实战场。
5. Web Scraper Test:专门设计的网页爬虫测试网站
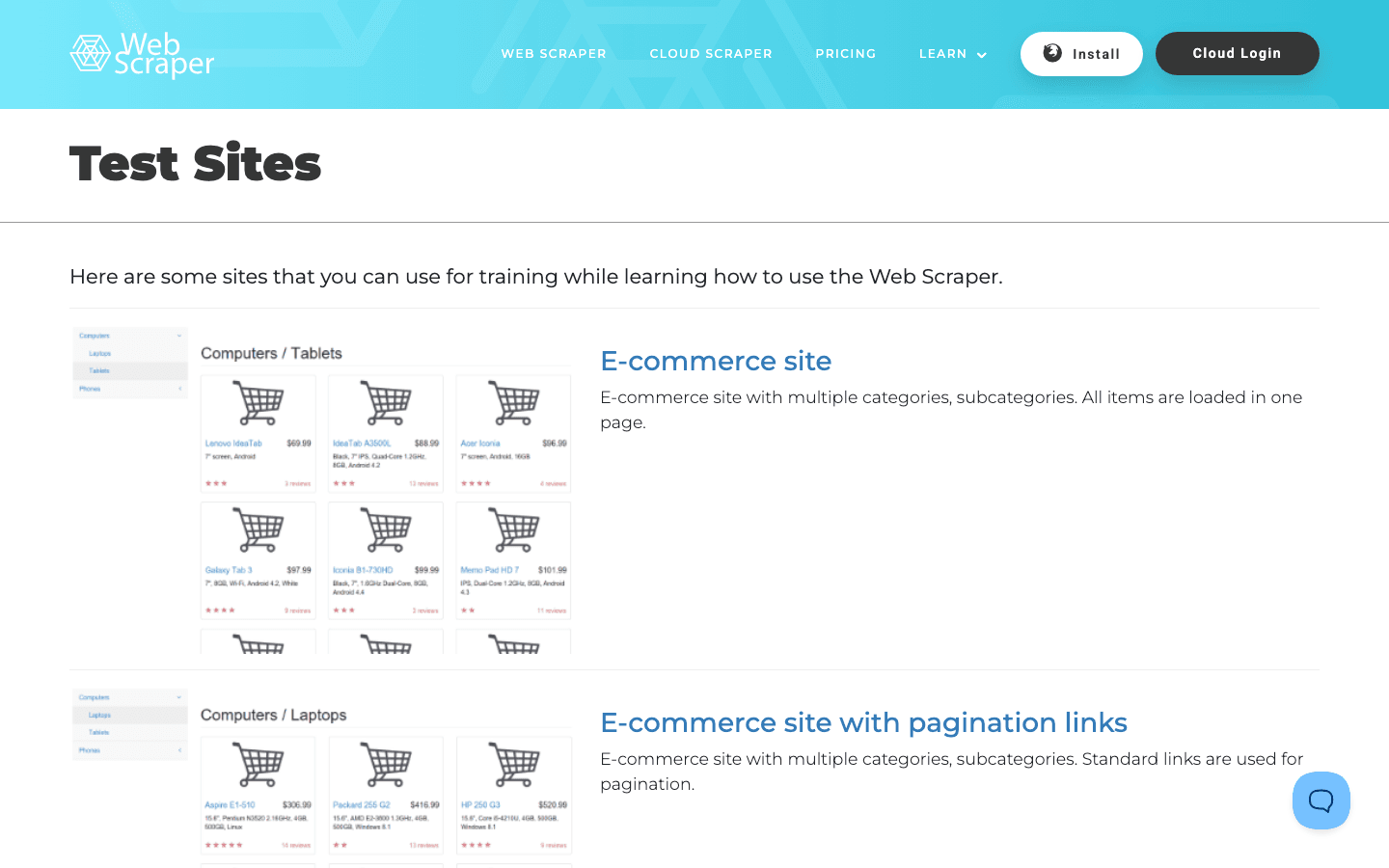 就是专门为我们这类人打造的——给那些想在专门场景里练习的爬虫爱好者用。
就是专门为我们这类人打造的——给那些想在专门场景里练习的爬虫爱好者用。
里面有什么:
- 电商页面: 既有静态页面,也有 AJAX 驱动页面。
- 表格和嵌套分类: 从简单列表到多级菜单。
- 动态内容: 用来测试你的爬虫处理 JavaScript 的能力。
为什么它很棒:
- 没有反爬机制——放心大胆抓。
- 能让你对比工具在静态页和动态页上的表现。
- 很适合比较 Thunderbit 和其他爬虫如何处理不同类型的网站()。
如果你想要一个安全的沙盒,把你的爬虫逼到极限,这里就是最佳选择。
6. eBay:真实世界的电商网页爬虫练习
 让网页爬虫真正走进现实世界。这里有数百万个商品列表,是练习以下内容的热门场所:
让网页爬虫真正走进现实世界。这里有数百万个商品列表,是练习以下内容的热门场所:
- 商品数据提取: 标题、价格、图片、卖家信息。
- 分页和筛选: 跨分类或搜索结果抓取。
- 动态内容: AJAX 加载的列表和评论。
挑战:
- eBay 会使用 CAPTCHA、限流和动态 HTML 来阻止机器人()。
- 你需要学习代理、User-Agent 和有分寸的抓取方式。
商业用途:
- 价格监控、竞品分析和市场调研。
如果你能抓 eBay,那你基本就准备好应对几乎任何电商挑战了。
7. Amazon:终极电商网页爬虫测试网站
 是网页爬虫的终极大关。这里有超过 1200 万件商品,还有地球上最强硬的一批反爬防线,是任何爬虫的终极考验。
是网页爬虫的终极大关。这里有超过 1200 万件商品,还有地球上最强硬的一批反爬防线,是任何爬虫的终极考验。
练习任务:
- 提取商品详情、价格、评分和评论。
- 处理无限滚动、动态元素和嵌套数据。
- 应对反爬措施:IP 封禁、请求指纹识别等等()。
为什么值得折腾?
- 抓 Amazon 能教你轮换代理、浏览器自动化等高级技巧。
- 这是练习真实电商项目的最佳方式——只要记得负责任地抓取,并遵守 Amazon 的条款。
8. Yelp:练习抓取商家列表和评论
 是任何对本地商家数据、评论和评分感兴趣的人都不该错过的宝库。
是任何对本地商家数据、评论和评分感兴趣的人都不该错过的宝库。
你可以抓取什么:
- 商家名称、分类、评分和地址。
- 用户评论(文本、日期、评分)。
- 图片和价格等级。
挑战:
- Yelp 已经加强了反爬防御,包括 CAPTCHA 和 API 限流()。
- 更适合练习工具配置和有礼貌的抓取方式。
商业价值:
- 本地市场调研、线索生成和情感分析。
9. Stack Overflow:抓取问答内容和开发者洞察
 是全球最大的开发者问答网站,也是绝佳的网页爬虫测试网站。
是全球最大的开发者问答网站,也是绝佳的网页爬虫测试网站。
练习机会:
- 抓取问题、答案、标签和用户主页。
- 处理分页和嵌套评论。
- 使用公开 API,合规地获取数据。
为什么它有用:
- 教你如何抓取论坛和社区类网站。
- 非常适合构建用于趋势分析或知识挖掘的数据集。
Stack Overflow 的 HTML 大多是静态的,所以新手也能上手,但它的规模和结构又会带来不少高级挑战。
10. Rotten Tomatoes:抓取电影评论和评分
 是获取电影评分、影评和观众分数的首选网站。
是获取电影评分、影评和观众分数的首选网站。
你会发现:
- 电影标题、影评人/观众评分和评论摘要。
- 动态的、AJAX 加载的内容和隐藏 API。
- 某些功能需要登录,或者需要更高级的爬取技巧()。
练习任务:
- 提取电影评分和评论摘要。
- 逆向分析 API 调用,获取 JSON 数据。
- 处理动态内容和反爬措施。
Rotten Tomatoes 是一个“毕业答辩级”挑战——如果你能抓它,那你基本就准备好应对几乎任何数据提取项目了。
对比表:一眼看懂网页爬虫练习网站
| 网站 | 数据类型 | 复杂度 | 反爬情况 | 最佳使用场景 |
|---|---|---|---|---|
| Thunderbit | 任何类型(文本、图片、邮箱、电话等) | 所有级别 | 不适用(工具,不是网站) | 在任何网站上练习、测试工作流 |
| Codeforces | 表格、排名、用户统计 | 中等 | 低 | 解析结构化数据、比赛内容 |
| Books to Scrape | 标题、价格、评分、分类 | 低 | 无 | 新手电商爬取 |
| HackerRank | 挑战、用户主页、排行榜 | 高 | 登录、JS 密集 | 动态内容、身份认证 |
| Web Scraper Test | 商品、表格、嵌套页面 | 可变 | 无 | 工具性能测试、静态/动态页面 |
| eBay | 列表、价格、图片、卖家信息 | 高 | CAPTCHA、限流 | 真实电商、价格追踪 |
| Amazon | 商品、评论、图片、价格 | 非常高 | IP 封禁、指纹识别 | 高级电商爬取 |
| Yelp | 商家、评论、评分、图片 | 高 | CAPTCHA、API 限制 | 本地商家数据、评论 |
| Stack Overflow | 问答、标签、用户统计 | 中等 | 低,支持 API | 论坛抓取、开发者洞察 |
| Rotten Tomatoes | 电影、评分、评论、影评人 | 高 | AJAX、隐藏 API | 评论分析、动态内容 |
结语:用合适的网页爬虫练习网站提升技能
如果你想真正把网页爬虫学好,没有什么能替代动手练习。上面这些网站提供了一条清晰的进阶路径:从适合新手的沙盒,一路走到充满反爬对抗的真实战场。你可以先从 Books to Scrape 这样的简单网站开始,再逐步挑战 Amazon 或 Rotten Tomatoes 这类动态巨头。
别忘了:你使用的工具和你练习的网站一样重要。 是我给商务用户,以及所有想要快速推进、自动化工作流并处理最乱网站的人的首选。但无论你选什么工具,都要不断试验、持续学习,并且始终负责任地抓取——尊重 robots.txt、限流和隐私。
想更深入了解?可以去看看 的更多指南,或者加入网页爬虫社区,交流技巧和挑战。网络就是你的游乐场——去抓点厉害的东西吧。
常见问题
1. 为什么我应该在样本网站上练习网页爬虫,而不是直接抓真实业务网站?
样本网站是为安全、合法练习而设计的。它们让你在不承担封禁或法律风险的前提下,建立技能、测试工具和做实验。等你更有把握后,再去处理真实项目会更稳妥。
2. Thunderbit 为什么适合作为网页爬虫测试网站?
Thunderbit 不只是一个测试网站——它还是一个 AI 驱动的工具,让你能在任何网站上练习抓取,从简单到复杂都可以。它的 AI 字段建议、子页面抓取和即时导出等功能,让新手和高级用户都很适合用。
3. 遇到 eBay 或 Amazon 这类网站的反爬措施,该怎么处理?
先从尊重限流和 robots.txt 开始。对于更难搞的网站,你可能需要使用代理、轮换 User-Agent,或者模拟浏览器行为。在这些网站上练习,能帮你学会如何调整自己的策略。
4. 网页爬虫有法律风险吗?
一定要查看网站的服务条款和 robots.txt。练习时尽量只抓公开的非登录页面,避免抓取个人或敏感数据。拿不准时,就使用样本网站或官方 API。
5. 提升网页爬虫技能的最佳方式是什么?
先从 Books to Scrape 这类入门网站开始,再逐步过渡到结构化数据(Codeforces)、动态内容(HackerRank)和真实挑战(Amazon、Yelp)。用 Thunderbit 这样的工具来自动化和简化工作流,并持续向社区学习。
祝你抓取顺利——愿你的数据永远干净、结构清晰,并且随时可用。
了解更多