IDCrawl Scraper
Được các chuyên gia tại những công ty hàng đầu tin dùng














Dữ liệu IDCrawl vẫn dùng tốt
Dùng IDCrawl để trích xuất dữ liệu nhanh hơn, sạch hơn và ở quy mô lớn với Thunderbit.
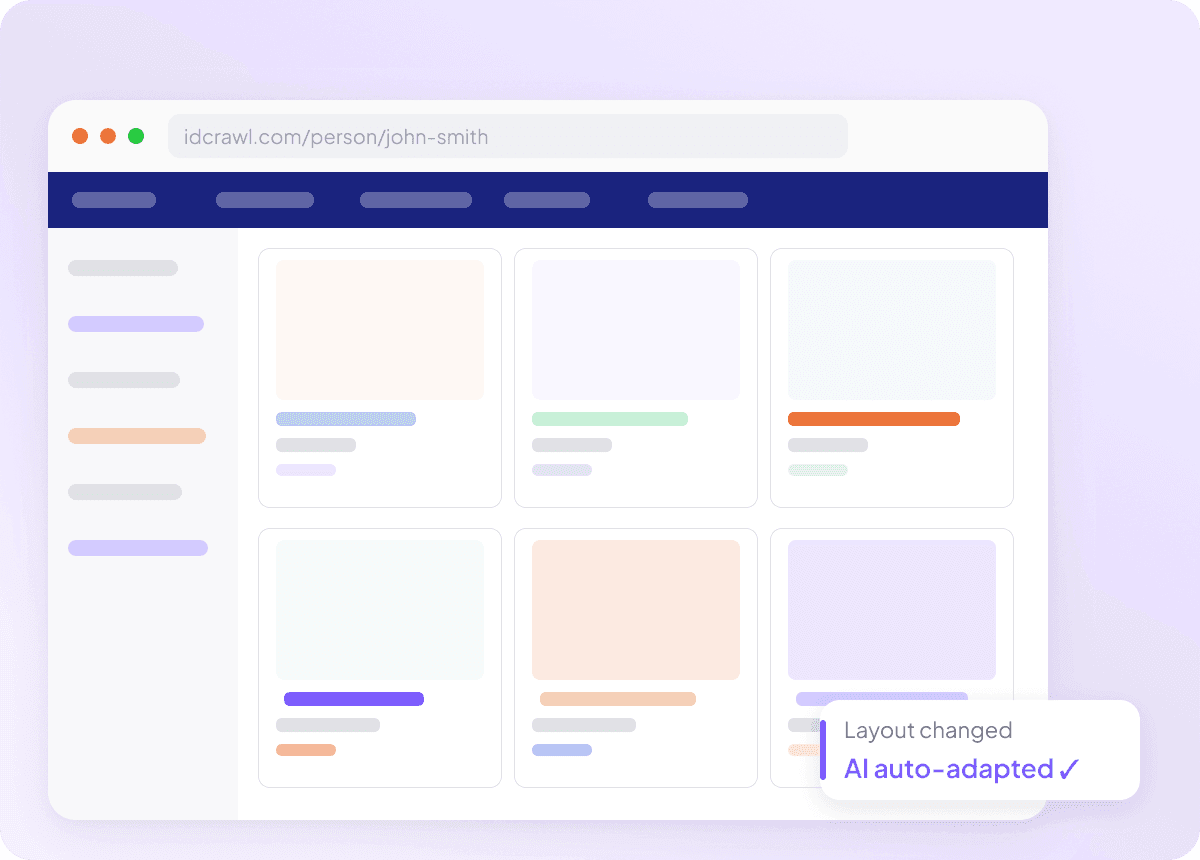
Thích ứng khi IDCrawl thay đổi
Những công cụ thu thập bị hỏng sau mỗi lần trang web cập nhật thì vô dụng, nhất là khi bạn đang cố lấy họ tên đầy đủ, chức danh, tên công ty, email, số điện thoại và hồ sơ LinkedIn từ IDCrawl. Thunderbit đọc trang theo ngữ nghĩa, không dựa vào bộ chọn cố định, nên có thể thích ứng khi bố cục thay đổi. Bạn sẽ dành ít thời gian sửa công cụ hơn và có thêm thời gian để lấy dữ liệu mình cần.
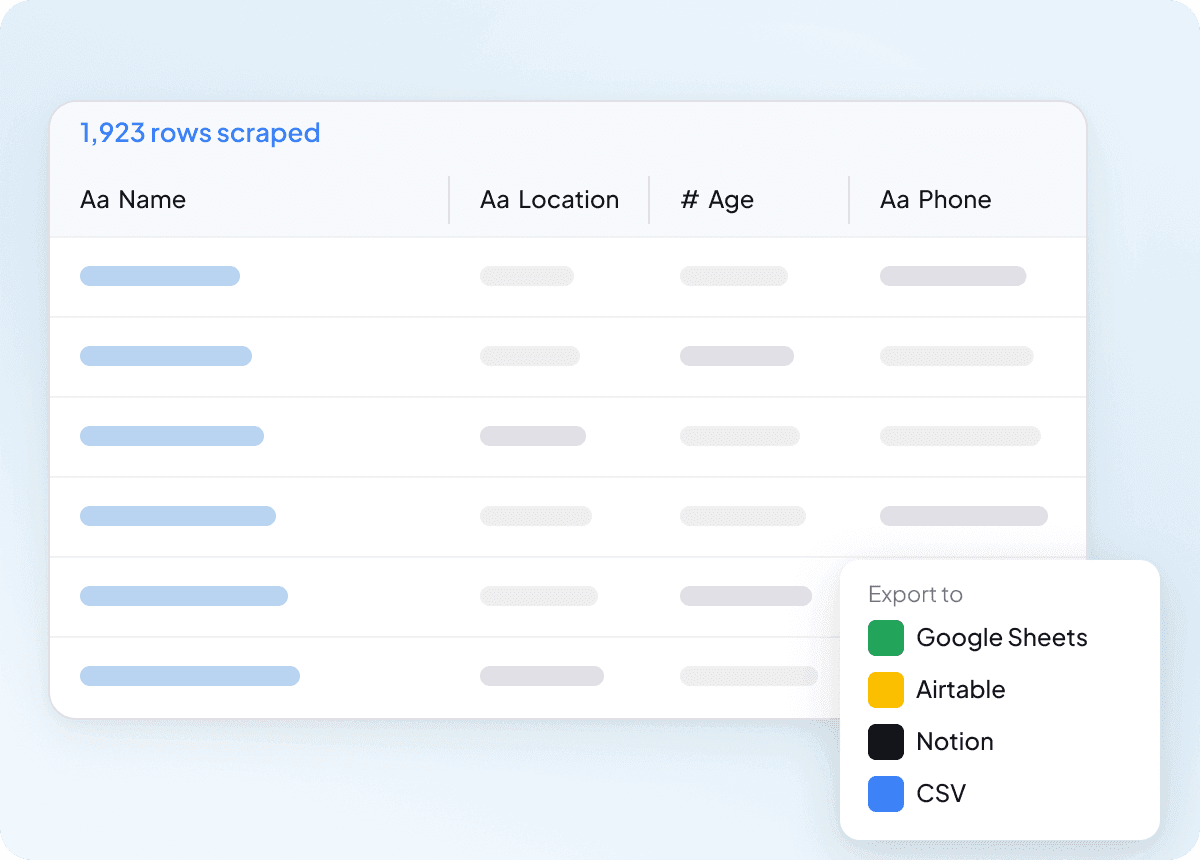
Dữ liệu sạch ngay từ đầu
Dữ liệu thô chỉ là bước đầu của công việc thực sự, và kết quả từ IDCrawl thường cần dọn dẹp trước khi dùng được. Thunderbit cấu trúc và định dạng dữ liệu ngay trong quá trình trích xuất, nên thứ bạn xuất ra đã sạch và sẵn sàng sử dụng. Điều đó đồng nghĩa ít phải sắp xếp hơn, ít làm lại hơn, và bàn giao cho đội nhóm cũng mượt hơn.
Thu thập hàng loạt IDCrawl chỉ trong một lần
Thu thập từng trang IDCrawl một không thể mở rộng khi bạn cần một danh sách liên hệ dài. Thunderbit có thể thu thập hàng loạt hàng trăm trang chỉ trong một lần, nên bạn chỉ cần đưa cho nó danh sách URL và trích xuất họ tên đầy đủ, chức danh, tên công ty, email, số điện thoại và hồ sơ LinkedIn trên tất cả các trang đó. Đây là cách dễ hơn nhiều để biến danh sách lớn thành dữ liệu có thể sử dụng.

Vì sao Thunderbit khác với các công cụ thu thập IDCrawl truyền thống?
Một cách đơn giản hơn để trích xuất dữ liệu IDCrawl mà không phải sửa liên tục.
Các công cụ thu thập truyền thống
Cách làm cũThunderbit AI
Cách tiếp cận thông minh hơnĐừng chỉ nghe chúng tôi nói
Xem người dùng nói gì về Thunderbit.






Các câu hỏi thường gặp
Liên quan trường hợp sử dụng
Khám phá thêm các trường hợp sử dụng của web scraper Thunderbit.
Elgiganten Scraper
Chỉ với hai cú nhấp chuột, bạn đã có thể lấy tên sản phẩm, giá và tình trạng còn hàng từ Elgiganten — phần việc nặng nhọc cứ để AI của Thunderbit lo.
Tìm hiểu thêm ->
PlayStation Scraper
Chỉ với vài cú nhấp chuột, bạn có thể lấy dữ liệu game PlayStation như tên game, thể loại và giá đang giảm — không còn phải sao chép thủ công rồi dán lại nữa.
Tìm hiểu thêm ->Công cụ lấy giá Amazon
Đưa giá Amazon, xếp hạng và ASIN vào Google Sheets bằng thao tác trỏ và nhấp — không cần thiết lập phức tạp.
Tìm hiểu thêm ->
Công cụ thu thập dữ liệu Trivago
Thu thập tên khách sạn, giá và xếp hạng từ Trivago chỉ với vài cú nhấp — không cần lập trình hay thiết lập.
Tìm hiểu thêm ->
PubMed Scraper
PubMed Scraper của Thunderbit giúp bạn trích xuất dữ liệu có cấu trúc từ trang kết quả tìm kiếm và trang bài viết trên PubMed bằng AI. Thu thập các nghiên cứu y khoa đang thịnh hành, bằng chứng thử nghiệm lâm sàng, tóm tắt (abstract), tác giả, cơ quan/đơn vị (affiliations), ngày xuất bản và liên kết, rồi xuất sang Excel, Google Sheets, Airtable hoặc Notion.
Tìm hiểu thêm ->
Sports Direct Scraper
Chạm để lấy tên sản phẩm, giá bán và phần trăm giảm giá từ Sports Direct bằng AI của Thunderbit — không cần cài đặt phức tạp hay viết mã.
Tìm hiểu thêm ->Sẵn sàng tăng tốc trích xuất dữ liệu chưa?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Dùng thử miễn phí với tín dụng không giới hạn cho 8 trang web.