

“Bạn có thể có dữ liệu mà không có thông tin, nhưng không thể có thông tin nếu không có dữ liệu.” — Daniel Keys Moran*
Các ước tính gần đây cho thấy trên internet có hơn 1,5 tỷ trang web, với khoảng 2 triệu bài viết mới được đăng mỗi ngày. Đại dương dữ liệu này chứa những insight giá trị để định hướng quyết định, nhưng có một vấn đề: khoảng 80% trong số đó là dữ liệu phi cấu trúc, nghĩa là cần xử lý thêm mới dùng được. Đó là lúc các công cụ web scraping phát huy tác dụng và trở thành thứ không thể thiếu với bất kỳ ai muốn khai thác dữ liệu trực tuyến.
Nếu bạn mới làm quen với web scraping, những khái niệm như web components và HTML có thể nghe hơi khó hiểu. Nhưng trong thời đại AI, những thách thức này đã dễ vượt qua hơn nhiều. Các công cụ scraping dùng AI ngày nay có thể giúp bạn bắt đầu mà không cần hiểu biết kỹ thuật quá sâu. Chúng cho phép thu thập và xử lý dữ liệu nhanh chóng, không cần kỹ năng lập trình.
Các công cụ & phần mềm web scraping tốt nhất
- Thunderbit cho một AI web scraper dễ dùng với kết quả tốt nhất
- Browse AI cho giám sát thời gian thực và trích xuất dữ liệu hàng loạt
- Bardeen AI cho tự động hóa no-code với tích hợp ứng dụng phong phú
- Web Scraper cho web scraping trực quan chuyên nghiệp hơn
- Octoparse cho scraping no-code mạnh mẽ, tránh chặn IP và phát hiện bot
- Diffbot cho API trích xuất dữ liệu bằng AI nâng cao và knowledge graph
Hãy thử dùng AI cho web scraping
Hãy thử nhé! Bạn có thể nhấp, khám phá và chạy quy trình trong lúc xem.
Web scraping hoạt động như thế nào?
Web scraping đơn giản là lấy dữ liệu từ các trang web. Bạn đưa cho một công cụ một bộ hướng dẫn, rồi nó sẽ đi lấy văn bản, hình ảnh hoặc bất cứ thứ gì bạn cần và đưa vào bảng từ một trang web. Việc này rất hữu ích trong nhiều tình huống, từ theo dõi giá trên các trang thương mại điện tử đến thu thập dữ liệu nghiên cứu, hay thậm chí chỉ để xây dựng một bảng Excel hoặc Google Sheets thật gọn gàng.
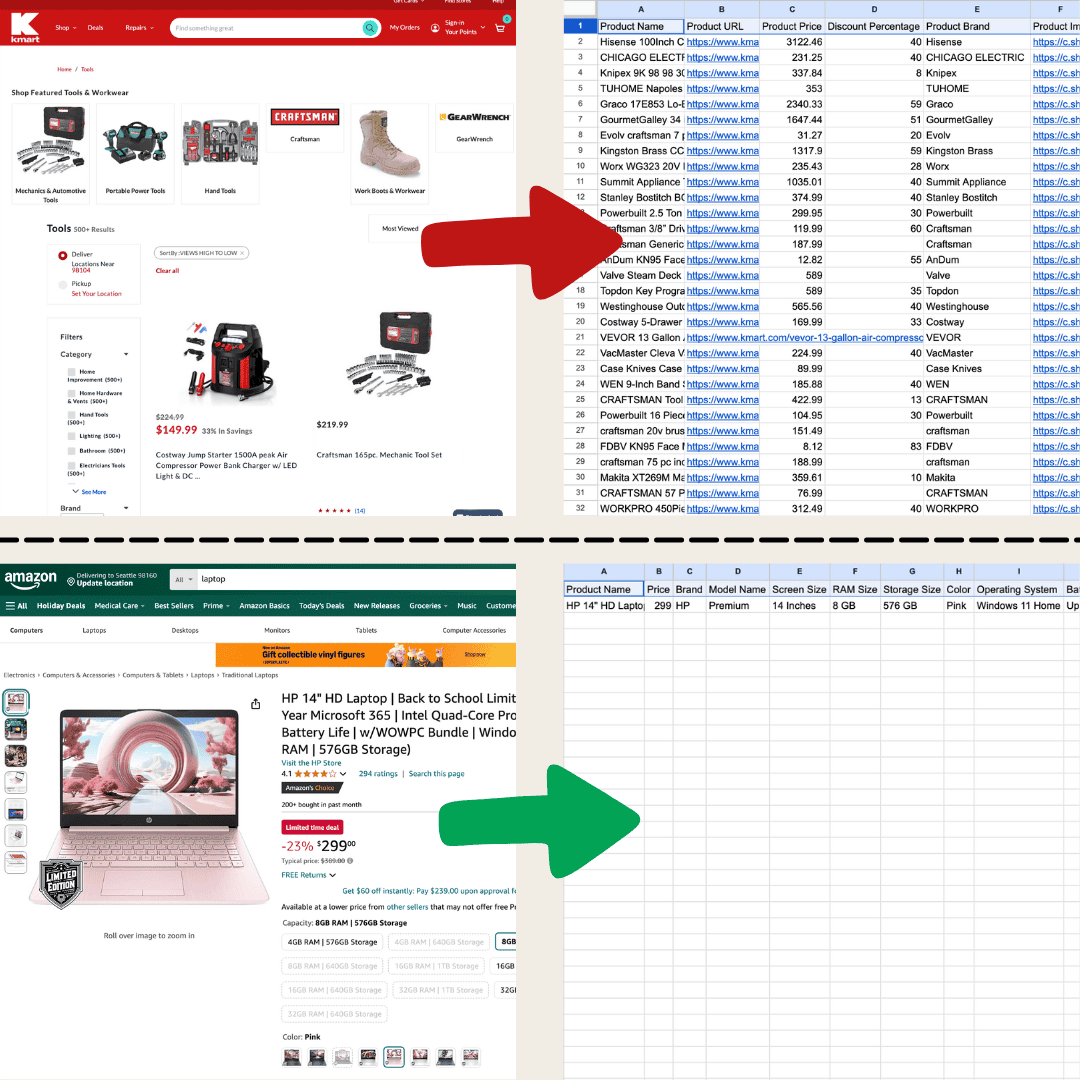 Tôi làm ảnh này bằng Thunderbit với AI Web Scraper.
Tôi làm ảnh này bằng Thunderbit với AI Web Scraper.
Có vài cách để làm việc này. Ở mức đơn giản nhất, bạn có thể tự copy và paste, nhưng sẽ rất mất công nếu dữ liệu quá nhiều. Vì vậy, đa số mọi người dùng một trong ba phương pháp: web scraper truyền thống, AI web scraper hoặc code tùy chỉnh.
Web scraper truyền thống hoạt động bằng cách đặt ra các quy tắc cụ thể về dữ liệu cần lấy dựa trên cấu trúc trang. Ví dụ, bạn có thể cấu hình để lấy tên sản phẩm hoặc giá từ những thẻ HTML nhất định. Cách này phù hợp nhất với những website ít thay đổi, vì chỉ cần bố cục đổi chút xíu là bạn phải vào chỉnh lại scraper.
 Dùng scraper truyền thống sẽ mất rất lâu để học, và có lẽ bạn sẽ phải nhấp hàng chục lần mới xong phần thiết lập.
Dùng scraper truyền thống sẽ mất rất lâu để học, và có lẽ bạn sẽ phải nhấp hàng chục lần mới xong phần thiết lập.
Thu thập dữ liệu từ bất kỳ website nào bằng AI Get Started Free
AI web scraper về cơ bản có nghĩa là: ChatGPT đọc toàn bộ website rồi trích xuất nội dung theo nhu cầu của bạn. Nó có thể xử lý trích xuất dữ liệu, dịch và tóm tắt cùng lúc. Chúng sử dụng xử lý ngôn ngữ tự nhiên để phân tích và hiểu bố cục website, nhờ đó thích ứng với thay đổi của trang mượt hơn. Ví dụ website chỉ sắp xếp lại các mục một chút — một AI web scraper có thể tự điều chỉnh mà bạn không cần viết lại gì. Vì vậy, chúng rất hợp với những website thường xuyên thay đổi hoặc có cấu trúc phức tạp hơn.
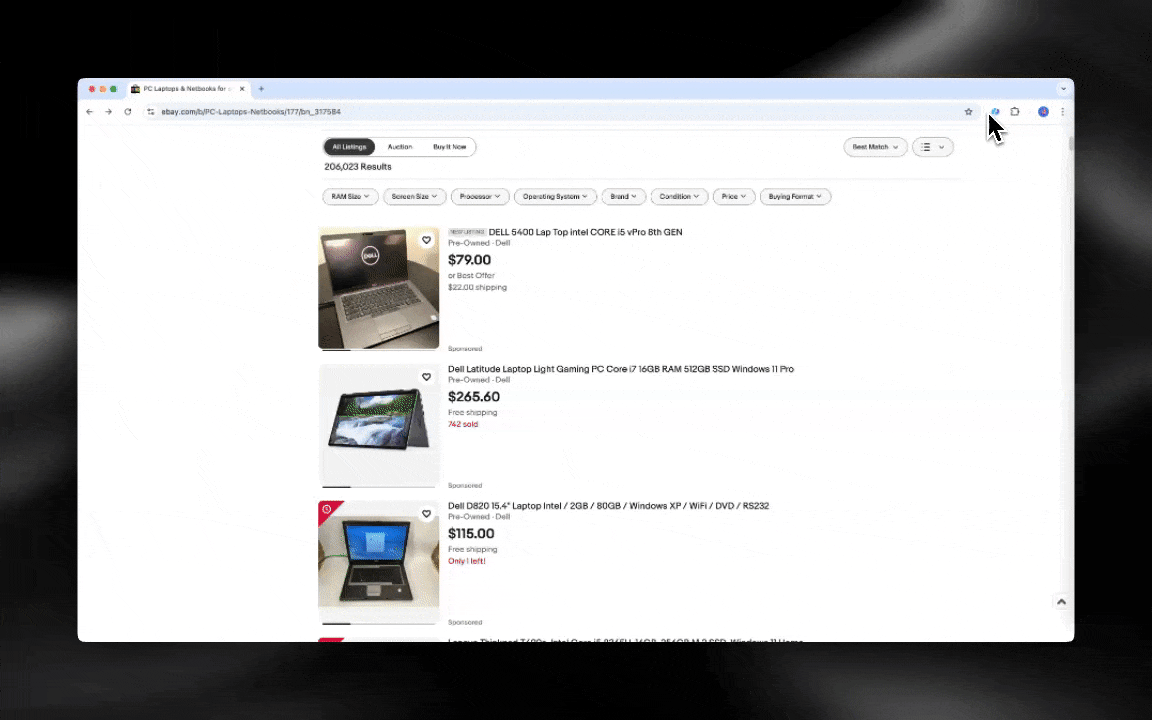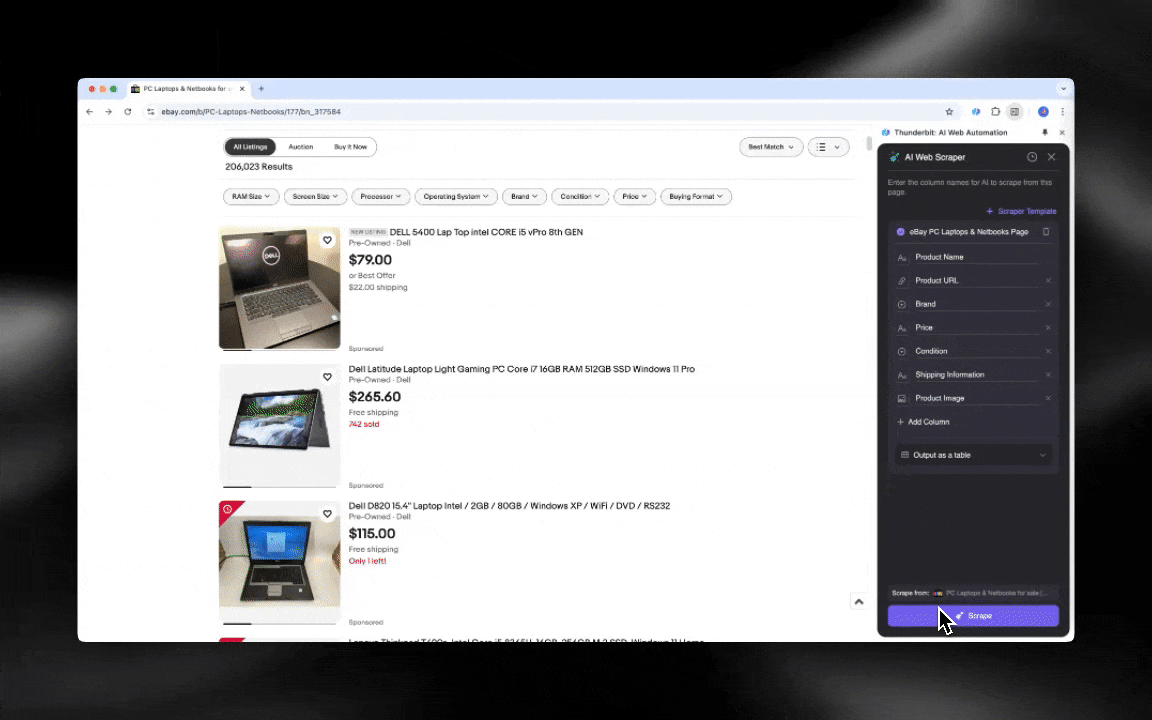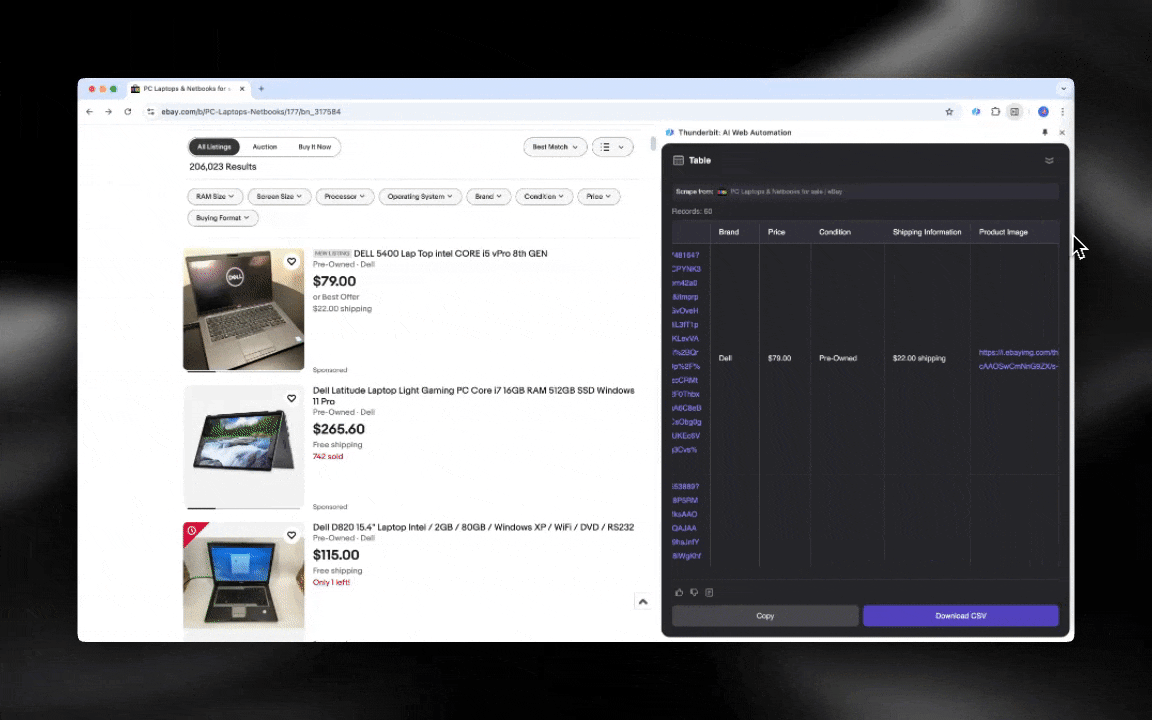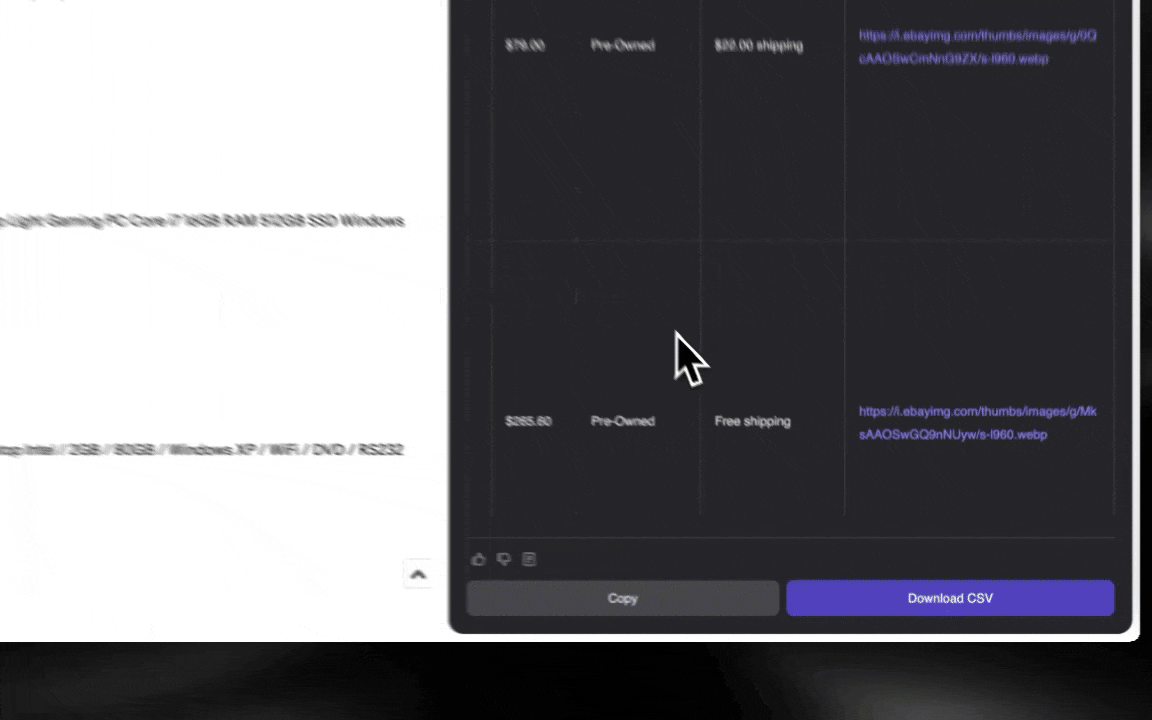 AI web scraper rất dễ bắt đầu và cho bạn dữ liệu chi tiết chỉ với vài cú nhấp!
AI web scraper rất dễ bắt đầu và cho bạn dữ liệu chi tiết chỉ với vài cú nhấp!
Nên chọn cái nào? Tùy trường hợp. Nếu bạn quen chỉnh sửa code hoặc cần thu thập khối lượng dữ liệu lớn từ một website phổ biến, scraper truyền thống có thể rất hiệu quả. Nhưng nếu bạn mới làm quen với web scraping hoặc muốn một công cụ có thể thích ứng với thay đổi của website, AI web scraper thường là lựa chọn tốt hơn. Xem bảng bên dưới để biết các tình huống cụ thể hơn!
| Tình huống | Lựa chọn tốt nhất |
|---|---|
| Scraping nhẹ trên các trang như danh bạ, website mua sắm, hoặc bất kỳ website nào có danh sách | AI Web Scraper |
| Trang có ít hơn 200 hàng dữ liệu, việc xây scraper bằng web scraper truyền thống quá mất thời gian | AI Web Scraper |
| Dữ liệu bạn cần scrape phải có định dạng nhất định để tải lên nơi khác. Ví dụ: scrape thông tin liên hệ để đưa lên HubSpot. | AI Web Scraper |
| Các website được dùng rất nhiều ở quy mô lớn, như hàng chục nghìn trang sản phẩm Amazon hoặc danh sách bất động sản Zillow. | Web Scraper truyền thống |
Các công cụ & phần mềm web scraping tốt nhất nhìn nhanh
| Công cụ | Giá | Tính năng chính | Ưu điểm | Nhược điểm |
|---|---|---|---|---|
| Thunderbit | Từ 9 USD/tháng, có gói miễn phí | AI web scraper, tự động phát hiện và định dạng dữ liệu, hỗ trợ nhiều định dạng, xuất một chạm, giao diện thân thiện. | Không cần code, có hỗ trợ AI, tích hợp với các ứng dụng như Google Sheets | Scraping quy mô lớn có thể chậm, tính năng nâng cao có thể tốn thêm chi phí |
| Browse AI | Từ 48,75 USD/tháng, có gói miễn phí | Giao diện no-code, giám sát thời gian thực, trích xuất dữ liệu hàng loạt, tích hợp workflow. | Dễ dùng, tích hợp với Google Sheets & Zapier | Trang phức tạp cần thiết lập thêm, scraping hàng loạt có thể bị timeout |
| Bardeen AI | Từ 60 USD/tháng, có gói miễn phí | Tự động hóa no-code, tích hợp với hơn 130 ứng dụng, MagicBox biến tác vụ thành workflow. | Tích hợp phong phú, mở rộng tốt cho doanh nghiệp | Người mới có thể mất thời gian làm quen, thiết lập ban đầu tốn công |
| Web Scraper | Miễn phí cho dùng cục bộ, 50 USD/tháng cho bản cloud | Tạo tác vụ trực quan, hỗ trợ website động (AJAX/JavaScript), scraping trên cloud. | Hoạt động tốt với website động | Cần kiến thức kỹ thuật để thiết lập tối ưu |
| Octoparse | Từ 119 USD/tháng, có gói miễn phí | Scraping no-code, tự động phát hiện phần tử trên trang, scraping trên cloud với tác vụ theo lịch, thư viện template cho các website phổ biến. | Tính năng mạnh cho website động, xử lý hạn chế tốt | Website phức tạp cần thời gian tìm hiểu |
| Diffbot | Từ 299 USD/tháng | API trích xuất dữ liệu, API không cần quy tắc, NLP cho văn bản phi cấu trúc, knowledge graph phong phú. | Trích xuất bằng AI mạnh, tích hợp API rộng, phù hợp scraping quy mô lớn | Người không chuyên kỹ thuật sẽ cần thời gian làm quen, mất thời gian thiết lập |
AI era web scraper tốt nhất
Thunderbit
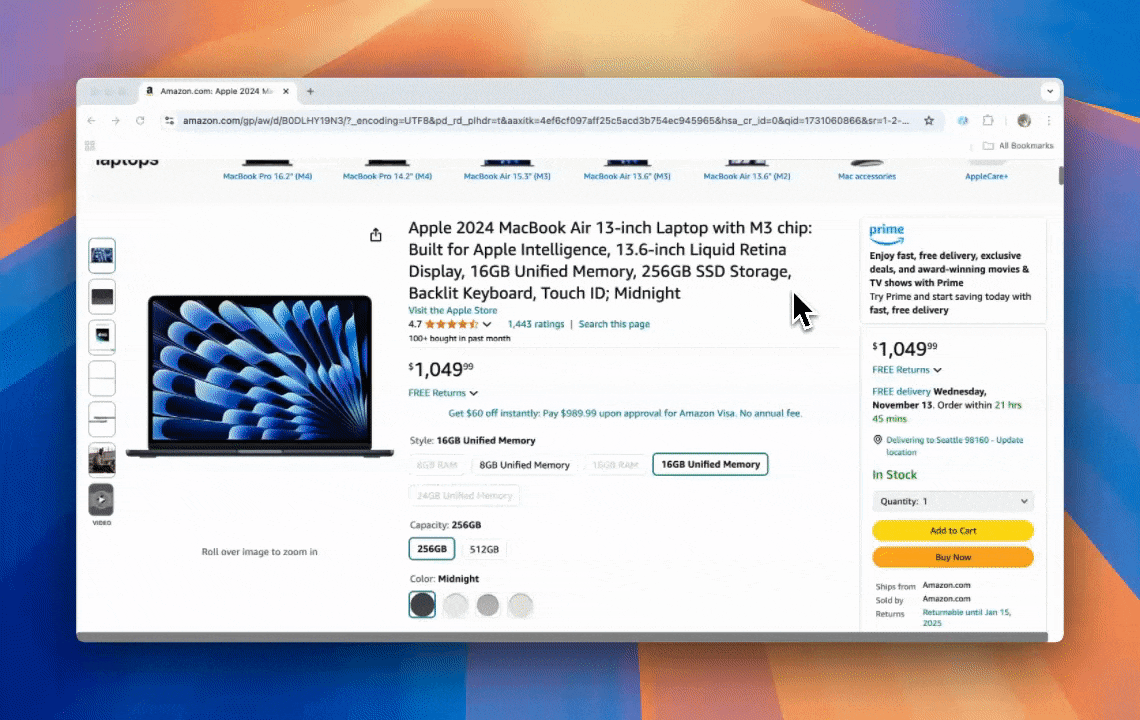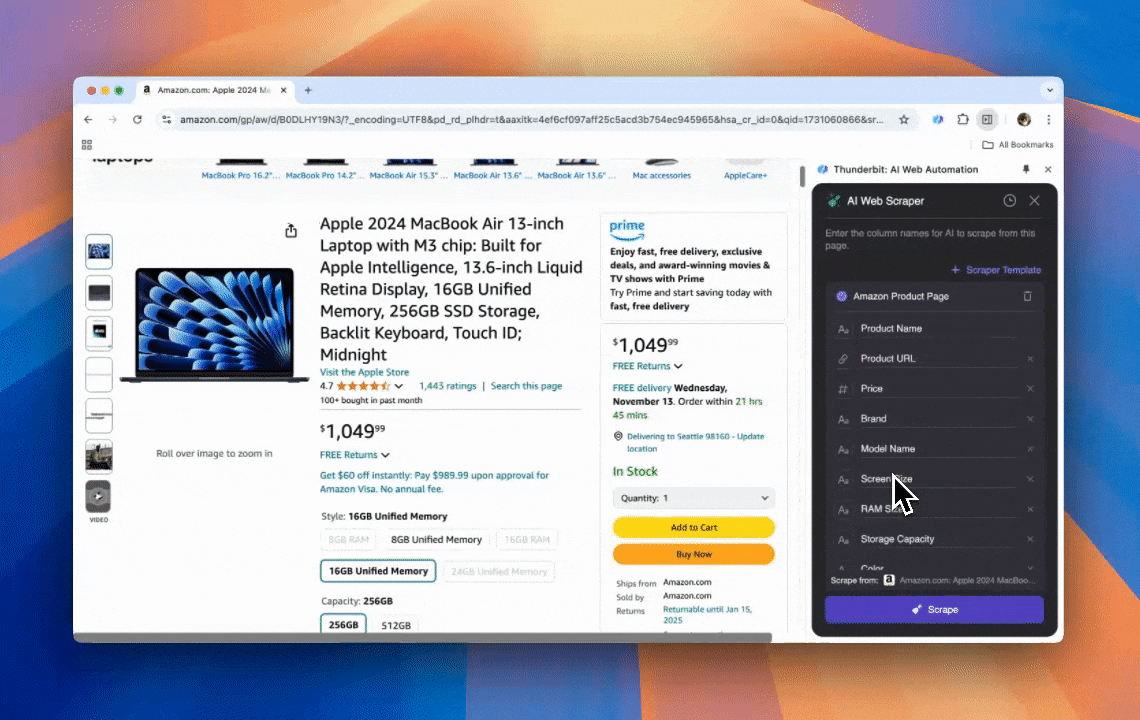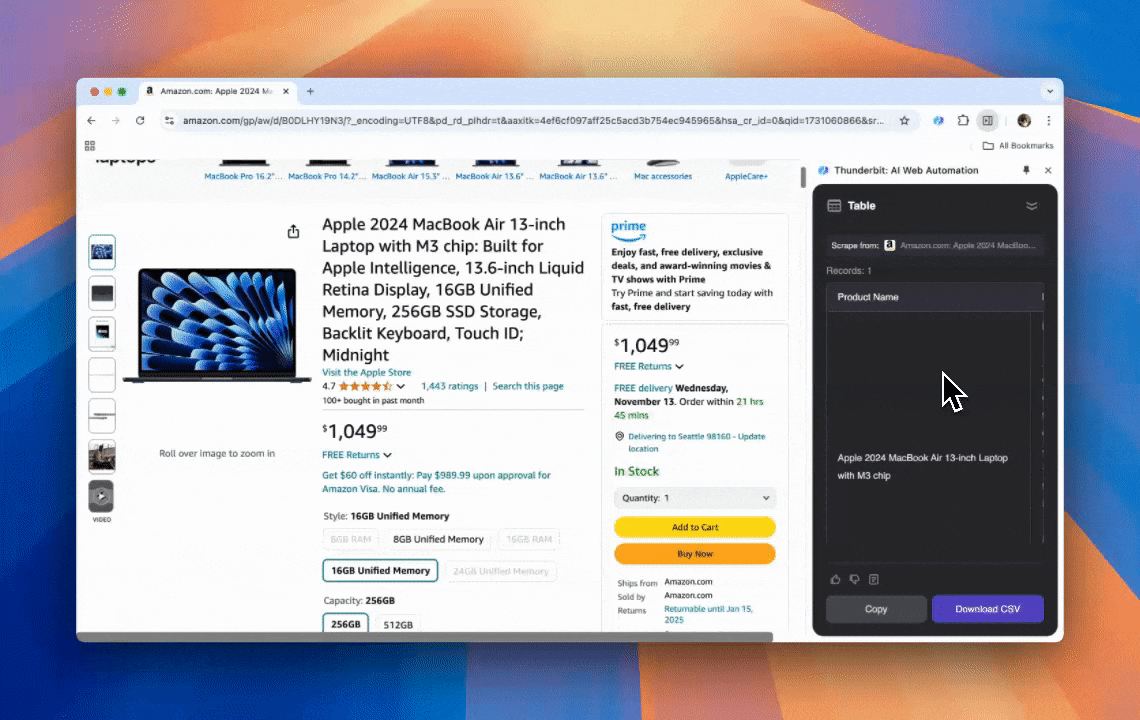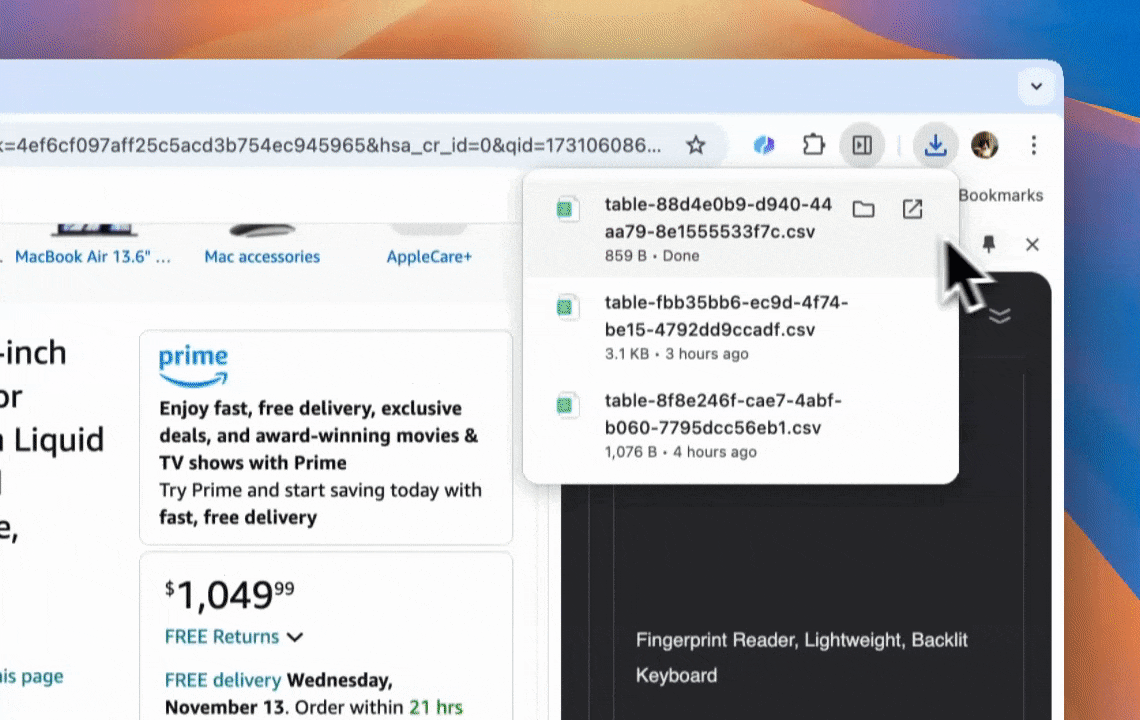
Thunderbit là một công cụ tự động hóa web dùng AI mạnh mẽ, thân thiện, cho phép người không biết lập trình có thể trích xuất và sắp xếp dữ liệu dễ dàng. Với tiện ích Chrome, AI Web Scraper của Thunderbit đơn giản hóa việc thu thập dữ liệu — người dùng có thể nhanh chóng kéo dữ liệu web mà không cần thao tác thủ công với các phần tử trên trang hay thiết lập từng scraper riêng cho từng bố cục trang khác nhau.
Tính năng chính
- Linh hoạt nhờ AI: AI Web Scraper của Thunderbit tự động phát hiện và định dạng dữ liệu web, loại bỏ nhu cầu dùng CSS selector.
- Trải nghiệm scraping dễ nhất: Tất cả những gì bạn cần làm là nhấp “AI suggest column” rồi nhấp “Scrape” trên trang muốn trích xuất. Chỉ vậy thôi.
- Hỗ trợ nhiều định dạng dữ liệu: Thunderbit có thể scrape URL, hình ảnh và hiển thị dữ liệu thu thập được ở nhiều định dạng.
- Xử lý dữ liệu tự động: AI của Thunderbit có thể định dạng lại dữ liệu ngay trong lúc chạy, bao gồm tóm tắt, phân loại và dịch sang định dạng cần dùng.
- Xuất dữ liệu dễ dàng: Xuất dữ liệu sang Google Sheets, Airtable hoặc Notion chỉ với một cú nhấp, giúp quản lý dữ liệu đơn giản hơn.
- Giao diện thân thiện: Giao diện trực quan giúp mọi người ở mọi mức độ kỹ năng đều có thể sử dụng.
Giá
Thunderbit có các gói theo bậc, bắt đầu từ 9 USD/tháng cho 5.000 credit. Gói cao nhất lên đến 199 USD cho 240.000 credit. Ngoài ra, với gói năm, bạn sẽ nhận toàn bộ credit ngay từ đầu.
Ưu điểm:
- Hỗ trợ AI mạnh giúp đơn giản hóa việc trích xuất và xử lý dữ liệu.
- Không cần code, phù hợp với người dùng ở mọi trình độ.
- Rất phù hợp cho scraping nhẹ như danh bạ, website mua sắm, v.v.
- Khả năng tích hợp tốt, xuất trực tiếp sang các ứng dụng phổ biến.
Nhược điểm:
- Scraping dữ liệu quy mô lớn có thể cần thêm thời gian để đảm bảo độ chính xác.
- Một số tính năng nâng cao có thể cần đăng ký trả phí.
Muốn biết thêm? Bắt đầu bằng cách cài đặt Thunderbit, hoặc khám phá cách scrape website dễ dàng với Thunderbit.
Công cụ web scraper tốt nhất cho giám sát dữ liệu và trích xuất hàng loạt
Browse AI
Browse AI là một công cụ scraping dữ liệu no-code mạnh mẽ, được thiết kế để giúp người dùng trích xuất và theo dõi dữ liệu mà không cần viết code. Browse AI có một số tính năng AI, nhưng chưa thật sự ở mức scraping hoàn toàn bằng AI. Dù vậy, nó vẫn giúp việc bắt đầu trở nên dễ hơn cho người dùng.
Tính năng chính
- Giao diện no-code: Cho phép người dùng tạo workflow tùy chỉnh chỉ bằng vài cú nhấp.
- Giám sát thời gian thực: Dùng bot để theo dõi thay đổi trên trang và cung cấp thông tin cập nhật.
- Trích xuất dữ liệu hàng loạt: Có thể xử lý tới 50.000 mục dữ liệu trong một lần.
- Tích hợp workflow: Kết nối nhiều bot cho các quy trình xử lý dữ liệu phức tạp hơn.
Giá
Bắt đầu từ 48,75 USD/tháng, đã bao gồm 2.000 credit. Có gói miễn phí, cung cấp 50 credit mỗi tháng để thử các tính năng cơ bản.
Ưu điểm:
- Có tích hợp với Google Sheets và Zapier.
- Bot dựng sẵn giúp đơn giản hóa các tác vụ trích xuất dữ liệu phổ biến.
Nhược điểm:
- Có thể cần cấu hình thêm cho các trang phức tạp.
- Tốc độ scraping hàng loạt có thể thay đổi, đôi khi dẫn đến timeout.
Công cụ web scraper tốt nhất cho tích hợp workflow
Bardeen AI
Bardeen AI là một công cụ tự động hóa no-code được thiết kế để tinh gọn quy trình làm việc bằng cách kết nối nhiều ứng dụng. Dù dùng AI để tạo tự động hóa tùy chỉnh, nó vẫn không linh hoạt bằng một công cụ AI Scraping đầy đủ.
Tính năng chính
- Tự động hóa no-code: Cho phép người dùng thiết lập workflow chỉ bằng cách nhấp.
- MagicBox: Mô tả tác vụ bằng ngôn ngữ tự nhiên, rồi Bardeen AI chuyển nó thành workflow.
- Tích hợp đa dạng: Tích hợp với hơn 130 ứng dụng, bao gồm Google Sheets, Slack và LinkedIn.
Giá
Bắt đầu từ 60 USD/tháng, với 1.500 credit (khoảng 1.500 hàng dữ liệu). Gói miễn phí cung cấp 100 credit mỗi tháng để thử các tính năng cơ bản.
Ưu điểm:
- Tùy chọn tích hợp phong phú, hỗ trợ nhiều nhu cầu kinh doanh khác nhau.
- Linh hoạt và mở rộng tốt cho doanh nghiệp ở mọi quy mô.
Nhược điểm:
- Người mới có thể cần thời gian để học toàn bộ nền tảng.
- Thiết lập ban đầu có thể tốn nhiều thời gian.
Công cụ web scraper trực quan tốt nhất cho người đã có kinh nghiệm
Web Scraper
Đúng vậy, bạn nghe không nhầm: công cụ này tên là "Web Scraper". Web Scraper là một tiện ích mở rộng trình duyệt phổ biến cho Chrome và Firefox, cho phép người dùng trích xuất dữ liệu không cần code, đồng thời cung cấp cách tạo tác vụ scraping theo kiểu trực quan. Tuy nhiên, bạn có thể sẽ phải dành vài ngày xem và học từ các video hướng dẫn ở trên để thật sự làm chủ công cụ này. Nếu bạn muốn việc scraping nhẹ đầu hơn, hãy chọn AI Web Scraper.
Tính năng chính
- Tạo tác vụ trực quan: Cho phép người dùng thiết lập tác vụ scraping bằng cách nhấp vào các phần tử web.
- Hỗ trợ website động: Có thể xử lý AJAX và JavaScript cho các website động.
- Scraping trên cloud: Lên lịch tác vụ qua Web Scraper Cloud cho các lần scraping định kỳ.
Giá
Miễn phí cho dùng cục bộ; các gói trả phí bắt đầu từ 50 USD/tháng cho tính năng cloud.
Ưu điểm:
- Hoạt động tốt với website động.
- Miễn phí khi dùng cục bộ.
Nhược điểm:
- Cần kiến thức kỹ thuật để thiết lập tối ưu.
- Cần test khá kỹ khi có thay đổi.
Công cụ web scraper tốt nhất để tránh chặn IP và phát hiện bot
Octoparse
Octoparse là một phần mềm linh hoạt dành cho người dùng có kỹ thuật hơn để thu thập và theo dõi dữ liệu web cụ thể mà không cần code, rất phù hợp cho nhu cầu dữ liệu quy mô lớn. Octoparse không dựa vào trình duyệt của người dùng để chạy; thay vào đó, nó dùng máy chủ cloud cho việc scraping dữ liệu. Vì vậy, nó có thể cung cấp nhiều cách để vượt qua chặn IP và một số cơ chế phát hiện bot của website.
Tính năng chính
- Vận hành no-code: Người dùng có thể tạo tác vụ scraping mà không cần viết code, nên phù hợp với nhiều mức độ kỹ năng kỹ thuật.
- Tự động phát hiện thông minh: Tự động phát hiện dữ liệu trên trang, nhanh chóng nhận diện các phần tử có thể scrape, giúp đơn giản hóa thiết lập.
- Scraping trên cloud: Hỗ trợ scraping dữ liệu cloud 24/7 với tác vụ theo lịch, linh hoạt khi lấy dữ liệu.
- Thư viện template phong phú: Cung cấp hàng trăm template dựng sẵn, giúp người dùng nhanh chóng truy cập dữ liệu từ các website phổ biến mà không cần thiết lập phức tạp.
Giá
Gói giá của Octoparse bắt đầu từ 119 USD/tháng, bao gồm 100 tác vụ. Cũng có gói miễn phí với 10 tác vụ mỗi tháng để thử các chức năng cơ bản.
Ưu điểm:
- Tính năng mạnh hỗ trợ scraping website động với khả năng thích ứng cao.
- Cung cấp giải pháp xử lý các hạn chế scraping và vấn đề nội dung động.
Nhược điểm:
- Cấu trúc website phức tạp có thể cần nhiều thời gian hơn để thiết lập.
- Người mới có thể cần thời gian để học cách sử dụng.
Công cụ web scraper tốt nhất cho API trích xuất dữ liệu bằng AI nâng cao
Diffbot
Diffbot là một công cụ trích xuất dữ liệu web nâng cao, dùng AI để biến nội dung web phi cấu trúc thành dữ liệu có cấu trúc. Với các API mạnh và knowledge graph, Diffbot giúp người dùng trích xuất, phân tích và quản lý thông tin từ web, phù hợp cho nhiều ngành và ứng dụng khác nhau.
Tính năng chính
- API trích xuất dữ liệu: Diffbot cung cấp API trích xuất dữ liệu không cần quy tắc, cho phép người dùng chỉ cần cung cấp URL để tự động trích xuất dữ liệu, không cần thiết lập quy tắc riêng cho từng website.
- API xử lý ngôn ngữ tự nhiên: Trích xuất thực thể có cấu trúc, quan hệ và cảm xúc từ văn bản phi cấu trúc, hỗ trợ người dùng xây dựng knowledge graph riêng.
- Knowledge graph: Diffbot sở hữu một trong những knowledge graph lớn nhất, kết nối lượng dữ liệu thực thể rất rộng, bao gồm thông tin về cá nhân và tổ chức.
Giá
Gói giá của Diffbot bắt đầu từ 299 USD/tháng, bao gồm 250.000 credit (tương đương khoảng 250.000 lượt trích xuất trang web qua API).
Ưu điểm:
- Khả năng trích xuất dữ liệu không cần quy tắc rất mạnh, thích ứng cao.
- Có nhiều tùy chọn tích hợp API, dễ kết nối với hệ thống sẵn có.
- Hỗ trợ scraping quy mô lớn, phù hợp cho ứng dụng cấp doanh nghiệp.
Nhược điểm:
- Thiết lập ban đầu có thể cần thời gian học cho người không chuyên kỹ thuật.
- Người dùng phải viết chương trình để gọi API mới sử dụng được.
Có thể dùng scraper để làm gì?
Nếu bạn mới làm quen với web scraping, dưới đây là vài trường hợp sử dụng phổ biến để giúp bạn bắt đầu. Nhiều người dùng scraper để lấy danh sách sản phẩm Amazon, kéo dữ liệu bất động sản từ Zillow, hoặc thu thập thông tin doanh nghiệp từ Google Maps. Nhưng đó mới chỉ là khởi đầu — bạn có thể dùng Thunderbit AI Web Scraper để thu thập dữ liệu từ hầu như bất kỳ website nào, tinh gọn công việc và tiết kiệm thời gian trong quy trình làm việc hằng ngày. Dù là để nghiên cứu, theo dõi giá hay xây dựng cơ sở dữ liệu, web scraping mở ra vô số cách để biến dữ liệu trên internet thành thứ phục vụ cho bạn.
Câu hỏi thường gặp
-
Web scraping có hợp pháp không?
Web scraping thường là hợp pháp, nhưng phải tuân theo điều khoản sử dụng của website và bản chất dữ liệu được truy cập. Luôn xem kỹ các chính sách liên quan và tuân thủ quy định pháp lý.
-
Tôi có cần kỹ năng lập trình để dùng các công cụ web scraping không?
Hầu hết các công cụ được giới thiệu ở đây không yêu cầu kỹ năng lập trình, nhưng những công cụ như Octoparse và Web Scraper có thể dùng tốt hơn nếu người dùng có hiểu biết cơ bản về cấu trúc web và tư duy lập trình.
-
Có công cụ web scraping miễn phí không?
Có, các công cụ miễn phí như BeautifulSoup, Scrapy và Web Scraper đều có sẵn, và một số công cụ khác cũng cung cấp gói miễn phí với tính năng giới hạn.
-
Những thách thức phổ biến trong web scraping là gì?
Các thách thức thường gặp gồm xử lý nội dung động, CAPTCHA, chặn IP và cấu trúc HTML phức tạp. Các công cụ và kỹ thuật nâng cao có thể giải quyết hiệu quả những vấn đề này.
Tìm hiểu thêm:
Dùng AI để làm việc gần như không cần nỗ lực. Get Started Free




