

Web năm 2026 là một bức tranh đầy biến động — hiện nay, một nửa lưu lượng internet đến từ bot, và các trình thu thập web mã nguồn mở chính là những “người hùng thầm lặng” đứng sau, vận hành mọi thứ từ theo dõi giá đến huấn luyện AI. Tôi đã làm việc nhiều năm trong SaaS và tự động hóa, và nếu có một điều tôi rút ra được, thì đó là: chọn đúng trình thu thập tự lưu trữ có thể giúp đội của bạn tiết kiệm hàng tháng trời đau đầu (và có lẽ là vài đêm thức trắng để gỡ lỗi). Dù bạn đang lấy dữ liệu từ vài trang sản phẩm hay thu thập hàng triệu URL cho nghiên cứu, các lựa chọn thay thế Firecrawl mã nguồn mở trong danh sách này đều có thể đáp ứng — bất kể quy mô, hệ công nghệ hay mức độ chấp nhận độ phức tạp của bạn.
Nhưng có một điều cần nói rõ: không có giải pháp nào phù hợp cho tất cả. Một số đội ngũ cần “sức mạnh cơ bắp” thô của Scrapy hay khả năng lưu trữ của Heritrix, trong khi những đội khác lại thấy việc duy trì các thư viện mã nguồn mở quá tốn kém. Vì vậy, hãy cùng phân tích 9 lựa chọn thay thế Firecrawl mã nguồn mở hàng đầu cho năm 2026, chỉ ra điểm mạnh của từng công cụ và giúp bạn ghép đúng công cụ với nhu cầu kinh doanh — mà không phải trải qua nỗi đau thử đi thử lại.
Cách chọn lựa chọn thay thế Firecrawl mã nguồn mở tốt nhất cho doanh nghiệp của bạn
Trước khi đi vào danh sách, hãy nói về chiến lược. Bức tranh thu thập web mã nguồn mở ngày nay đa dạng hơn bao giờ hết, và lựa chọn của bạn nên dựa trên một vài yếu tố then chốt:
- Dễ sử dụng: Bạn muốn giao diện kéo-thả hay thoải mái viết Python, Go hoặc JavaScript?
- Khả năng mở rộng: Bạn chỉ thu thập một trang web, hay cần thu thập hàng triệu trang trên hàng trăm tên miền?
- Loại nội dung: Trang mục tiêu của bạn là HTML tĩnh, hay phụ thuộc nhiều vào JavaScript và tải động?
- Nhu cầu tích hợp: Bạn muốn dùng dữ liệu thế nào — xuất sang Excel, đẩy vào cơ sở dữ liệu hay đưa vào luồng phân tích?
- Bảo trì: Bạn có đủ nguồn lực để duy trì mã tùy chỉnh, hay muốn một công cụ tự thích ứng khi website thay đổi?
Đây là bảng tóm tắt nhanh để bạn dễ quyết định:
| Tình huống | Công cụ phù hợp nhất |
|---|---|
| Không cần code, duyệt web ngoại tuyến | HTTrack |
| Thu thập quy mô lớn, đa miền | Scrapy, Apache Nutch, StormCrawler |
| Trang động / nặng JavaScript | Puppeteer |
| Cần tự động hóa biểu mẫu / đăng nhập | MechanicalSoup |
| Tải/lưu trữ trang tĩnh | Wget, HTTrack, Heritrix |
| Lập trình Go, hiệu năng cao | Colly |
Giờ thì cùng đi sâu vào 9 lựa chọn thay thế Firecrawl mã nguồn mở hàng đầu cho năm 2026.
1. Scrapy: Tốt nhất cho thu thập dữ liệu quy mô lớn bằng Python

Scrapy là “nhà vô địch hạng nặng” trong thế giới thu thập web mã nguồn mở. Được xây dựng bằng Python, đây là framework được lựa chọn cho các nhà phát triển cần thu thập ở quy mô lớn — nghĩ đến hàng triệu trang, cập nhật thường xuyên và logic website phức tạp.
Vì sao chọn Scrapy?
- Quy mô cực lớn: Scrapy có thể xử lý hàng nghìn yêu cầu mỗi giây, và được các công ty dùng để thu thập hàng tỷ trang mỗi tháng (Zyte).
- Mở rộng và mô-đun hóa: Viết spider tùy chỉnh, cắm middleware cho proxy, xử lý đăng nhập, và xuất ra JSON, CSV hoặc cơ sở dữ liệu.
- Cộng đồng rất năng động: Rất nhiều plugin, tài liệu và câu trả lời trên Stack Overflow.
- Đã được kiểm chứng thực tế: Được dùng trong môi trường sản xuất bởi các nhóm thương mại điện tử, tin tức và nghiên cứu trên toàn thế giới.
Hạn chế: Đường cong học tập khá dốc với người không phải lập trình viên, và bạn sẽ cần duy trì spider khi website thay đổi. Nhưng nếu bạn muốn toàn quyền kiểm soát và khả năng mở rộng, Scrapy rất khó bị đánh bại.
2. Apache Nutch: Tốt nhất cho công cụ tìm kiếm doanh nghiệp
Apache Nutch là “cụ tổ” của các trình thu thập mã nguồn mở, được thiết kế cho thu thập cấp doanh nghiệp ở quy mô internet. Nếu bạn mơ xây dựng công cụ tìm kiếm riêng hoặc thu thập hàng triệu miền, Nutch là người bạn đồng hành phù hợp.
Vì sao chọn Apache Nutch?
- Quy mô nhờ Hadoop: Được xây trên Hadoop, Nutch có thể thu thập hàng tỷ trang trên các cụm máy chủ (Common Crawl dùng nó để thu thập web công khai).
- Thu thập theo lô: Chỉ cần đưa vào danh sách URL khởi tạo rồi để nó chạy — rất phù hợp cho các tác vụ theo lịch ở quy mô lớn.
- Tích hợp tốt: Hoạt động với Solr, Elasticsearch và các pipeline dữ liệu lớn.
Hạn chế: Thiết lập phức tạp (kiểu cụm Hadoop, file cấu hình Java), và nó thiên về thu thập thô hơn là trích xuất dữ liệu có cấu trúc. Quá mức cần thiết cho dự án nhỏ, nhưng gần như không đối thủ ở quy mô web lớn.
3. Heritrix: Tốt nhất cho lưu trữ web và tuân thủ

Heritrix là trình thu thập do chính Internet Archive phát triển, được xây dựng chuyên cho lưu trữ web và bảo tồn số.
Vì sao chọn Heritrix?
- Độ đầy đủ ở cấp lưu trữ: Thu thập mọi trang, tài nguyên và liên kết — rất lý tưởng cho tuân thủ pháp lý hoặc lưu lại ảnh chụp lịch sử.
- Đầu ra WARC: Lưu mọi thứ trong file Web ARChive chuẩn hóa, sẵn sàng để phát lại hoặc phân tích.
- Quản trị qua web: Cấu hình và giám sát các phiên thu thập ngay trong giao diện trình duyệt.
Hạn chế: Nặng nề (cần nhiều dung lượng đĩa và bộ nhớ), không thực thi JavaScript, và xuất ra kho lưu trữ thô thay vì bảng dữ liệu có cấu trúc. Phù hợp nhất cho thư viện, kho lưu trữ hoặc ngành được quản lý chặt chẽ.
4. Colly: Tốt nhất cho nhà phát triển Go hiệu năng cao
Colly là công cụ được các lập trình viên Go yêu thích — nhanh, gọn nhẹ và có khả năng chạy đồng thời rất cao.
Vì sao chọn Colly?
- Rất nhanh: Khả năng đồng thời của Go giúp Colly thu thập hàng nghìn trang với mức tiêu thụ CPU/RAM tối thiểu (Oxylabs).
- API đơn giản: Định nghĩa callback cho các phần tử HTML, xử lý cookie và robots.txt tự động.
- Rất hợp với website tĩnh: Hoàn hảo cho trang render phía máy chủ, API, hoặc khi bạn muốn tích hợp thu thập dữ liệu vào backend Go.
Hạn chế: Không có sẵn render JavaScript (với site động, bạn sẽ cần ghép cùng công cụ như Chromedp), và bạn cần biết Go.
5. MechanicalSoup: Tốt nhất cho tự động hóa biểu mẫu đơn giản

MechanicalSoup là một thư viện Python lấp đầy khoảng trống giữa các yêu cầu HTTP đơn giản và tự động hóa trình duyệt đầy đủ.
Vì sao chọn MechanicalSoup?
- Tự động hóa biểu mẫu: Dễ dàng đăng nhập, điền form và duy trì phiên làm việc — rất tốt để thu thập dữ liệu sau lớp xác thực.
- Nhẹ: Dùng Requests và BeautifulSoup ở phía dưới, nên nhanh và dễ thiết lập.
- Lý tưởng cho website tương tác: Nếu bạn cần gửi form tìm kiếm hoặc lấy dữ liệu sau khi đăng nhập, MechanicalSoup là một lựa chọn rất tốt (Apify Blog).
Hạn chế: Không thực thi JavaScript, nên sẽ không hoạt động trên các site nặng JS. Phù hợp nhất cho trang tĩnh hoặc render phía máy chủ với tương tác đơn giản.
6. Puppeteer: Tốt nhất cho website động và nặng JavaScript
Puppeteer là “dao đa năng Thụy Sĩ” cho việc thu thập các website hiện đại, nặng JavaScript. Đây là thư viện Node.js cho phép bạn kiểm soát toàn bộ một trình duyệt Chrome không giao diện.
Vì sao chọn Puppeteer?
- Xử lý nội dung động: Thu thập SPA, cuộn vô hạn, và các trang tải dữ liệu qua AJAX (Browserless Guide).
- Mô phỏng người dùng: Bấm nút, điền form, chụp ảnh màn hình, thậm chí giải CAPTCHA (với plugin).
- Tự động hóa mạnh mẽ: Tuyệt vời cho kiểm thử, giám sát và thu thập bất cứ thứ gì người dùng thật có thể thấy.
Hạn chế: Ngốn tài nguyên (chạy các phiên Chrome đầy đủ), chậm hơn các trình thu thập chỉ dùng HTTP, và việc mở rộng cần phần cứng mạnh hoặc điều phối trên đám mây.
7. Wget: Tốt nhất cho tải nhanh qua dòng lệnh

Wget là công cụ dòng lệnh kinh điển để tải xuống website tĩnh và tệp tin.
Vì sao chọn Wget?
- Đơn giản: Tải toàn bộ website hoặc thư mục chỉ với một lệnh — không cần code.
- Nhanh: Được viết bằng C, nên nhanh và hiệu quả.
- Rất hợp với nội dung tĩnh: Hoàn hảo cho website tài liệu, blog hoặc tải hàng loạt tệp (HuggingFace Guide).
Hạn chế: Không thực thi JavaScript hay xử lý form, và nó tải về các trang thô chứ không phải dữ liệu có cấu trúc. Hãy xem nó như một “máy hút bụi kỹ thuật số” cho website tĩnh.
8. HTTrack: Tốt nhất cho duyệt web ngoại tuyến (không cần code)
HTTrack là “người anh em thân thiện” của Wget, cung cấp giao diện đồ họa để sao chép website.
Vì sao chọn HTTrack?
- GUI dễ dùng: Trình hướng dẫn từng bước giúp người không rành kỹ thuật cũng dùng được.
- Duyệt web ngoại tuyến: Điều chỉnh các liên kết để bạn có thể xem site đã sao chép ngay trên máy.
- Rất hợp để lưu trữ: Hoàn hảo cho nhà nghiên cứu, marketer hoặc bất kỳ ai muốn chụp lại một website mà không cần viết code (Reddit DataHoarder).
Hạn chế: Không hỗ trợ nội dung động, có thể chậm trên site lớn, và không được thiết kế để trích xuất dữ liệu có cấu trúc.
9. StormCrawler: Tốt nhất cho thu thập phân tán theo thời gian thực

StormCrawler là trình thu thập phân tán hiện đại dành cho các đội cần dữ liệu web quy mô lớn, liên tục và theo thời gian thực.
Vì sao chọn StormCrawler?
- Thu thập thời gian thực: Xây trên Apache Storm, nó xử lý dữ liệu theo luồng — rất hợp cho giám sát tin tức hoặc công cụ tìm kiếm (Wikipedia).
- Mô-đun hóa và mở rộng tốt: Thêm phân tích, lập chỉ mục và các bolt xử lý tùy chỉnh khi cần.
- Được Common Crawl sử dụng: Vận hành bộ dữ liệu tin tức cho một trong những kho lưu trữ web mở lớn nhất.
Hạn chế: Cần kỹ năng phát triển Java và cụm Storm, nên phù hợp nhất với đội có kinh nghiệm về hệ thống phân tán. Quá mức cần thiết cho dự án nhỏ.
So sánh các lựa chọn thay thế Firecrawl mã nguồn mở: Đối thủ miễn phí nào phù hợp với bạn?
Đây là cái nhìn so sánh 9 công cụ bên cạnh nhau:
| Công cụ | Trường hợp sử dụng tốt nhất | Ưu điểm chính | Nhược điểm | Ngôn ngữ / Thiết lập |
|---|---|---|---|---|
| Scrapy | Thu thập quy mô lớn, tần suất cao | Mạnh, mở rộng tốt, cộng đồng lớn | Đường cong học tập dốc, cần Python | Framework Python |
| Apache Nutch | Thu thập cấp doanh nghiệp, quy mô web | Nhờ Hadoop, đã được chứng minh ở quy mô lớn | Thiết lập phức tạp, thiên về xử lý theo lô | Java/Hadoop |
| Heritrix | Thu thập để lưu trữ, tuân thủ | Chụp trọn website, xuất WARC | Nặng, không JS, lưu trữ thô | Ứng dụng Java, giao diện web |
| Colly | Dev Go, thu thập hiệu năng cao | Nhanh, API đơn giản, đồng thời tốt | Không JS, cần Go | Thư viện Go |
| MechanicalSoup | Tự động hóa biểu mẫu, thu thập sau đăng nhập | Nhẹ, xử lý phiên làm việc | Không JS, quy mô hạn chế | Thư viện Python |
| Puppeteer | Website động / nặng JS | Kiểm soát trình duyệt đầy đủ, tự động hóa | Ngốn tài nguyên, cần Node.js | Thư viện Node.js |
| Wget | Tải site tĩnh, truy cập ngoại tuyến | Đơn giản, nhanh, CLI | Không JS, trang thô | Công cụ dòng lệnh |
| HTTrack | Người không rành kỹ thuật, lưu trữ website | GUI, duyệt ngoại tuyến dễ dàng | Không JS, chậm trên site lớn | Ứng dụng desktop (GUI) |
| StormCrawler | Thu thập phân tán, thời gian thực | Mở rộng tốt, mô-đun hóa, thời gian thực | Cần chuyên môn Java/Storm | Cụm Java/Storm |
Bạn nên tự xây hay dùng một lựa chọn thay thế Firecrawl mã nguồn mở có sẵn?
Sự thật là: tự xây dựng trình thu thập nghe có vẻ thú vị — cho đến khi bạn bị lún sâu vào bảo trì, proxy và những rắc rối chống bot. Các công cụ mã nguồn mở ở trên đã gói ghém nhiều năm kinh nghiệm và tri thức cộng đồng. Theo các báo cáo trong ngành, dùng giải pháp có sẵn là cách nhanh nhất, đáng tin cậy nhất để có kết quả và tránh phải “phát minh lại bánh xe” (IveerData).
- Nên dùng mã nguồn mở nếu: Nhu cầu của bạn khớp với những gì đã có, bạn muốn rút ngắn thời gian phát triển, và bạn coi trọng hỗ trợ từ cộng đồng.
- Nên tự xây nếu: Bạn có yêu cầu thật sự độc nhất, chuyên môn nội bộ sâu, và việc thu thập là lõi của doanh nghiệp.
Tuy nhiên, mã nguồn mở không hẳn là “miễn phí” nếu tính cả chi phí nhân sự kỹ thuật, bảo trì máy chủ, và cập nhật liên tục để đối phó với biện pháp chống thu thập. Nếu bạn muốn có lợi ích của một trình thu thập mạnh mà không phải viết code, vẫn còn một lựa chọn nữa.
Phần thưởng: Khi mã nguồn mở quá phức tạp, hãy thử Thunderbit
Dù những công cụ ở trên rất ấn tượng với nhà phát triển, chúng đều có những điểm hạn chế chung: cần biết lập trình, khó xử lý các cơ chế chống bot bằng AI động, và đòi hỏi bảo trì liên tục.
Thunderbit là lựa chọn tôi thường đề xuất cho bất kỳ ai cần vượt qua những giới hạn đó. Nó tạo cầu nối giữa khả năng thu thập mạnh mẽ và sự dễ dùng.
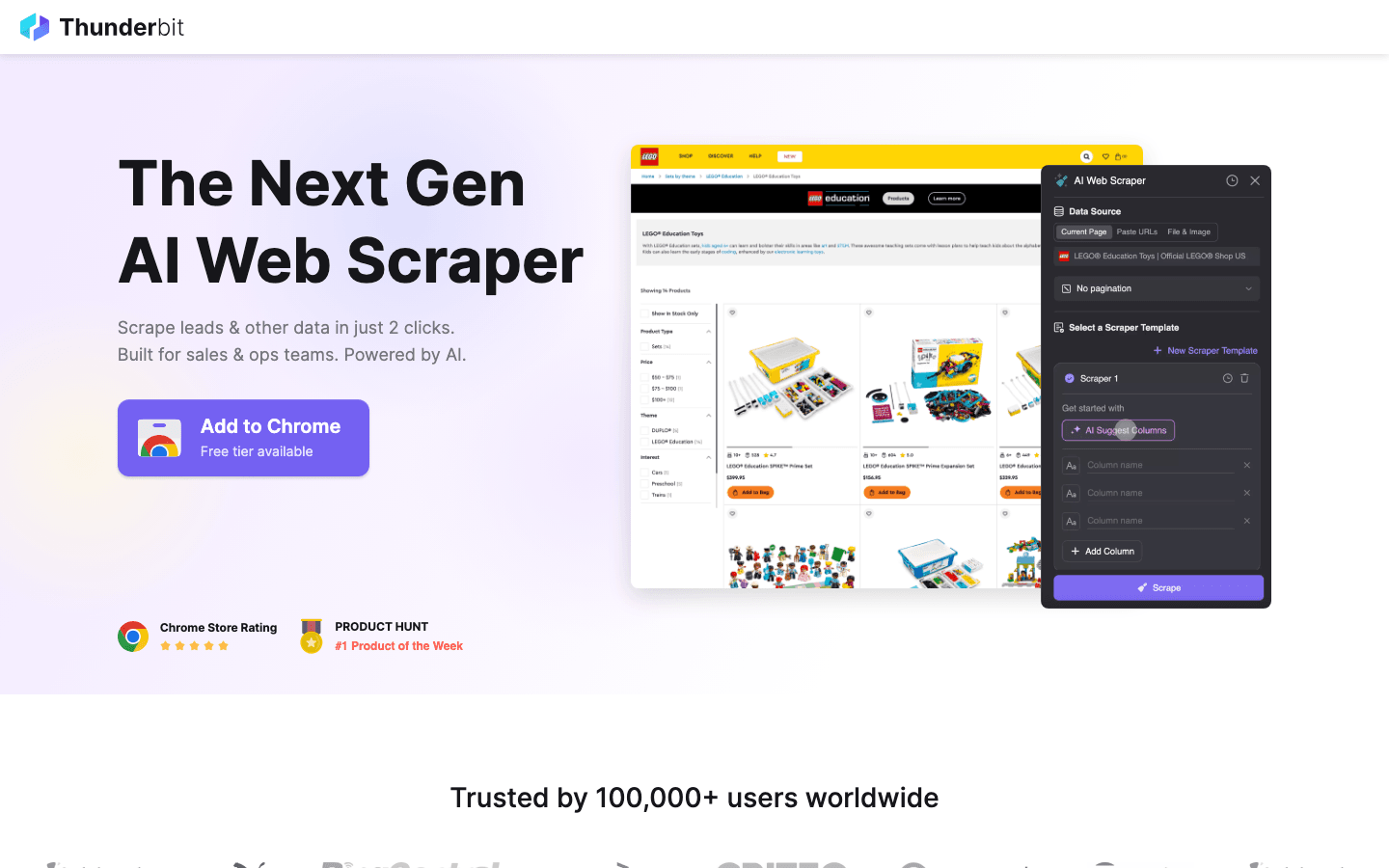
Vì sao nên chọn Thunderbit thay vì mã nguồn mở?
- Không cần viết code: Khác với Scrapy hay Puppeteer, Thunderbit là tiện ích Chrome chạy bằng AI. Bạn chỉ cần bấm “AI Suggest Fields”, và nó sẽ tự tạo trình thu thập cho bạn.
- Xử lý phần khó: Nội dung động, cuộn vô hạn và phân trang được AI xử lý tự động, giúp bạn tiết kiệm hàng giờ viết script tùy chỉnh.
- Xuất dữ liệu tức thì: Từ website đến Excel, Google Sheets hoặc Notion chỉ trong hai cú nhấp.
- Không cần bảo trì: Bạn không phải cập nhật code mỗi khi website thay đổi bố cục — AI của Thunderbit sẽ tự thích ứng.
Nếu bạn là nhân viên kinh doanh, marketer hoặc nhà nghiên cứu muốn có dữ liệu ngay bây giờ mà không cần học Python hay Go, Thunderbit là mảnh ghép hoàn hảo cho các công cụ mã nguồn mở trong danh sách này.
Muốn xem nó hoạt động ra sao? Tải tiện ích Chrome và tự mình trải nghiệm.
Dùng thử Thunderbit AI Web Scraper
Kết luận: Tìm trình thu thập web tự lưu trữ phù hợp cho năm 2026
Đọc thêm các hướng dẫn về thu thập web Get Started Free
Thế giới các lựa chọn thay thế Firecrawl mã nguồn mở hiện phong phú hơn bao giờ hết. Dù bạn cần quy mô thô của Scrapy hay Nutch, hay độ chính xác lưu trữ của Heritrix, đều có một giải pháp cho từng tình huống kinh doanh. Điều quan trọng là ghép đúng công cụ với nhu cầu của bạn — đừng “quá tay” nếu chỉ cần lấy dữ liệu nhanh, và cũng đừng đầu tư quá ít nếu bạn đang thu thập ở quy mô internet.
Và hãy nhớ: nếu con đường mã nguồn mở quá kỹ thuật hoặc tốn thời gian, các công cụ AI như Thunderbit luôn sẵn sàng san sẻ phần việc đó.
Sẵn sàng bắt đầu chưa? Hãy khởi chạy Scrapy cho dự án dữ liệu lớn tiếp theo của bạn, hoặc Dùng thử Thunderbit để thu thập dữ liệu đơn giản, có AI hỗ trợ. Nếu bạn muốn đọc thêm mẹo về thu thập web, hãy xem Thunderbit Blog để đọc các bài phân tích chuyên sâu và hướng dẫn.
Dùng thử Thunderbit cho thu thập web bằng AI
Câu hỏi thường gặp
1. Lợi thế chính của việc dùng các lựa chọn thay thế Firecrawl mã nguồn mở là gì? Các lựa chọn mã nguồn mở mang lại sự linh hoạt, tiết kiệm chi phí và khả năng tự lưu trữ, tùy chỉnh trình thu thập của bạn. Bạn tránh bị khóa vào một nhà cung cấp và được hưởng lợi từ hỗ trợ, cập nhật tích cực từ cộng đồng.
2. Công cụ nào tốt nhất cho người không rành kỹ thuật nhưng cần kết quả nhanh? HTTrack là một lựa chọn mã nguồn mở rất ổn cho duyệt web ngoại tuyến. Tuy nhiên, nếu cần trích xuất dữ liệu có cấu trúc (như bảng Excel), chúng tôi khuyên dùng công cụ bổ sung Thunderbit nhờ khả năng AI.
3. Làm sao xử lý các website động, nặng JavaScript? Puppeteer là lựa chọn tốt nhất — nó điều khiển trình duyệt thật, nên có thể thu thập mọi thứ người dùng nhìn thấy, bao gồm SPA và nội dung tải qua AJAX.
4. Khi nào nên dùng trình thu thập nặng như Apache Nutch hoặc StormCrawler? Nếu bạn cần thu thập hàng triệu trang trên nhiều miền, hoặc cần thu thập phân tán theo thời gian thực (như cho công cụ tìm kiếm hoặc giám sát tin tức), các công cụ này được xây để phục vụ quy mô lớn và độ tin cậy cao.
5. Tốt hơn là tự xây trình thu thập hay dùng giải pháp mã nguồn mở có sẵn? Với đa số đội ngũ, dùng và tùy chỉnh một công cụ mã nguồn mở có sẵn sẽ nhanh hơn, rẻ hơn và đáng tin cậy hơn. Chỉ nên tự xây nếu bạn có nhu cầu rất chuyên biệt và đủ nguồn lực để duy trì lâu dài.
Chúc bạn thu thập thuận lợi — và mong dữ liệu của bạn luôn tươi mới, có cấu trúc và sẵn sàng hành động.
Dùng thử miễn phí Thunderbit AI Web Scraper Get Started Free
Tìm hiểu thêm




