

Nhu cầu về dữ liệu được gán nhãn chất lượng cao trong machine learning chưa bao giờ lớn như lúc này. Mỗi lần tôi nói chuyện với các đội đang xây dựng mô hình AI mới — dù là dự báo doanh số, gợi ý sản phẩm hay phân tích cảm xúc khách hàng — tôi lại nghe đi nghe lại những “nỗi đau” rất quen: gán nhãn dữ liệu thủ công thì chậm, tốn kém, và nói thật là khá bào mòn tinh thần. Tôi đã thấy không ít dự án bị đình trệ hàng tuần, thậm chí hàng tháng, chỉ vì chờ đủ dữ liệu đã gán nhãn để huấn luyện một mô hình ra hồn. Còn khi nhãn không nhất quán thì sao? Nói ngắn gọn, dự đoán của mô hình đôi khi cũng đáng tin chẳng kém những lần tôi cố đỗ xe song song.
Nhưng tin vui là: gán nhãn dữ liệu tự động bằng machine learning đang thay đổi cuộc chơi. Khi để AI gánh phần việc nặng, doanh nghiệp không chỉ tăng tốc quy trình gán nhãn mà còn cải thiện độ chính xác và tính nhất quán — hai yếu tố có thể quyết định thành bại của một dự án ML. Trong bài hướng dẫn này, tôi sẽ cùng bạn đi qua cách gán nhãn dữ liệu tự động hoạt động ra sao, vì sao nó cực kỳ quan trọng để xây dựng mô hình vững chắc, và cách bạn có thể dùng các công cụ như Thunderbit để thiết lập quy trình gán nhãn tự động của riêng mình — không cần biết code.
Gán nhãn dữ liệu tự động bằng machine learning là gì?
Hãy tách nó ra cho dễ hiểu. Gán nhãn dữ liệu tự động bằng machine learning là việc dùng thuật toán và công cụ AI để gán nhãn (như “spam” hoặc “không spam”, “mèo” hoặc “chó”, “tích cực” hoặc “tiêu cực”) cho dữ liệu thô của bạn — mà không cần con người phải bấm chọn từng mẫu một. Hãy tưởng tượng sự khác biệt giữa việc tự tay gắn thẻ hàng nghìn bức ảnh du lịch, với việc dùng nhận diện khuôn mặt để tự động phân loại chúng theo người, địa điểm, hay thậm chí là tâm trạng.
Gán nhãn thủ công truyền thống đúng như tên gọi: con người xem từng mục dữ liệu rồi gán nhãn phù hợp. Cách này có độ chính xác cao (đôi khi), nhưng chậm, tốn kém và khó mở rộng. Ngược lại, gán nhãn tự động dùng các mô hình machine learning — được huấn luyện trên một tập nhỏ dữ liệu đã gán nhãn thủ công — để dự đoán nhãn cho phần còn lại của bộ dữ liệu. Kết quả là gì? Quy trình gán nhãn nhanh hơn, nhất quán hơn và mở rộng tốt hơn (GeeksforGeeks).
Với người dùng doanh nghiệp, điều này đồng nghĩa bạn có thể xây dựng mô hình tốt hơn, nhanh hơn, và ít phải làm việc thủ công nặng nhọc hơn. Trong thế giới vận hành dựa trên dữ liệu ngày nay, đó là một lợi thế cạnh tranh rất lớn.
Tự động gán nhãn dữ liệu với Thunderbit Dùng AI web scraper của Thunderbit để tự động hóa quy trình gán nhãn dữ liệu — không cần code. Get Started Free
Vì sao gán nhãn dữ liệu tự động là chìa khóa cho mô hình machine learning chất lượng cao
Có một điều rất rõ: chất lượng dữ liệu được gán nhãn ảnh hưởng trực tiếp đến hiệu suất của mô hình machine learning. Như câu nói quen thuộc: “rác vào, rác ra”. Nếu nhãn không nhất quán hoặc sai, mô hình sẽ học sai mẫu — và dự đoán của nó cũng sẽ kém đi (DataCamp).
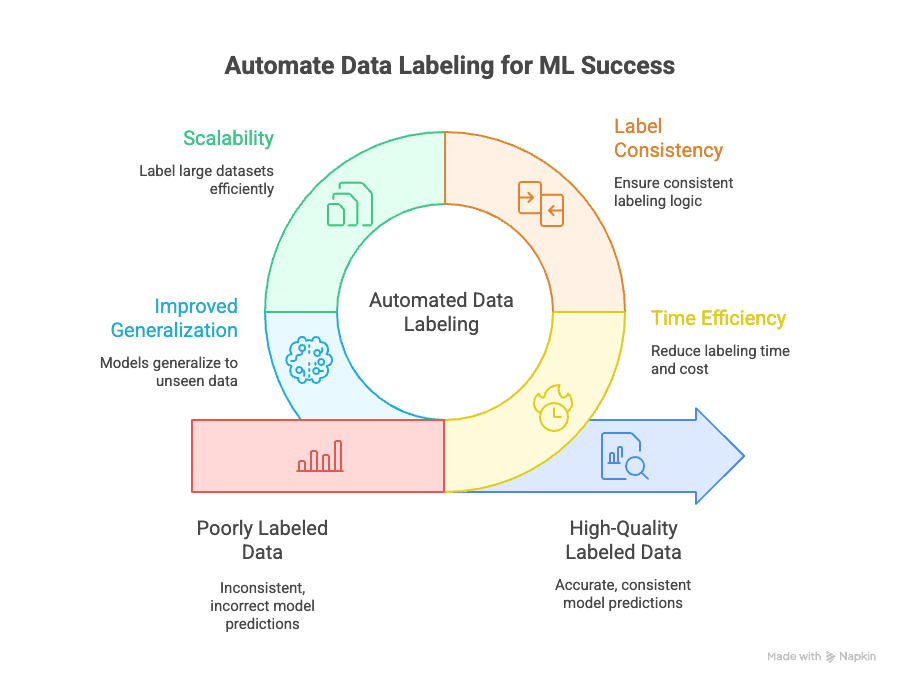
Gán nhãn dữ liệu tự động giải quyết nhiều thách thức quan trọng:
- Tiết kiệm thời gian: Gán nhãn thủ công có thể ngốn tới 70% tổng thời gian và chi phí của một dự án ML. Tự động hóa kéo con số này xuống chỉ còn một phần nhỏ, giúp bạn thử nghiệm và triển khai mô hình nhanh hơn.
- Tính nhất quán của nhãn: Máy không mệt và không bị phân tâm. Gán nhãn tự động đảm bảo mọi điểm dữ liệu đều được gán theo cùng một logic, giảm lỗi và thiên lệch từ con người (GeeksforGeeks).
- Khả năng mở rộng: Cần gán nhãn 10.000, 100.000 hay thậm chí 1 triệu điểm dữ liệu? Tự động hóa giúp làm được điều đó mà không cần thuê cả một đội ngũ annotator (Keylabs).
- Khả năng khái quát tốt hơn: Nhãn nhất quán, chất lượng cao giúp mô hình khái quát tốt hơn với dữ liệu mới chưa từng thấy — và đó mới là mục tiêu cuối cùng của machine learning (Kili Technology).
Tác động kinh doanh là rất thật: Keylabs cho biết các quy trình lai kết hợp gán nhãn hỗ trợ bởi AI với rà soát của con người có thể nâng độ chính xác gán nhãn lên tới 80% so với quy trình hoàn toàn thủ công, và điều đó chuyển hóa trực tiếp thành khả năng lặp mô hình nhanh hơn cùng dự đoán đầu ra đáng tin cậy hơn.
So sánh gán nhãn thủ công và gán nhãn tự động
Hãy đặt chúng cạnh nhau:
| Yếu tố | Gán nhãn thủ công | Gán nhãn tự động bằng ML |
|---|---|---|
| Tốc độ | Chậm (vài tuần/vài tháng với bộ dữ liệu lớn) | Nhanh (vài phút/vài giờ với bộ dữ liệu lớn) |
| Độ chính xác | Cao, nhưng dễ gặp lỗi và thiếu nhất quán do con người | Cao, với logic nhất quán và ít lỗi hơn |
| Khả năng mở rộng | Bị giới hạn bởi nguồn lực con người | Dễ dàng mở rộng đến hàng triệu điểm dữ liệu |
| Chi phí | Tốn kém (nhiều công sức nhân sự) | Chi phí dài hạn thấp hơn (Keylabs) |
| Phù hợp nhất cho | Bộ dữ liệu nhỏ, phức tạp hoặc mơ hồ | Bộ dữ liệu lớn, lặp lại nhiều hoặc có cấu trúc rõ ràng |
Gán nhãn thủ công vẫn có chỗ đứng riêng — đặc biệt với các trường hợp biên hoặc dữ liệu mơ hồ — nhưng với hầu hết ứng dụng doanh nghiệp, tự động hóa vẫn là hướng đi nên chọn.
Các bước cơ bản của gán nhãn dữ liệu tự động bằng machine learning
Vậy thực tế gán nhãn dữ liệu tự động diễn ra như thế nào? Đây là quy trình đầu-cuối mà tôi khuyên dùng (và cũng thường tự áp dụng):
- Thu thập và tiền xử lý dữ liệu
- Trích xuất và chuẩn bị đặc trưng
- Gán nhãn tự động bằng machine learning
- Đảm bảo chất lượng và rà soát bởi con người
Hãy cùng bóc tách từng bước.
Bước 1: Thu thập và tiền xử lý dữ liệu
Trước khi gán nhãn bất kỳ thứ gì, bạn cần thu thập và làm sạch dữ liệu. Việc này có thể là scrape danh sách sản phẩm từ website, xuất đánh giá khách hàng, hoặc thu thập hình ảnh từ cơ sở dữ liệu nội bộ. Điểm mấu chốt ở đây là chất lượng: dữ liệu tồi sẽ dẫn đến nhãn tồi, rồi kéo theo mô hình tồi (Snorkel AI).
Thực hành tốt nhất:
- Loại bỏ dữ liệu trùng lặp và các mục không liên quan
- Chuẩn hóa định dạng (ngày tháng, tiền tệ, v.v.)
- Xử lý dữ liệu thiếu hoặc chưa hoàn chỉnh
Bước 2: Trích xuất và chuẩn bị đặc trưng
Tiếp theo, bạn xác định những đặc trưng quan trọng cho bài toán gán nhãn. Ví dụ, nếu đang gán nhãn danh sách sản phẩm, bạn có thể trích xuất các thuộc tính như giá, thương hiệu, danh mục và mô tả. Trong bán hàng hoặc marketing, điều này có thể là lấy tên công ty, thông tin liên hệ hoặc cảm xúc trong email.
Ví dụ doanh nghiệp: Dùng Thunderbit, bạn có thể scrape dữ liệu có cấu trúc từ trang web — như thông số sản phẩm, đánh giá hoặc thông tin liên hệ — mà không cần viết một dòng code nào.
Bước 3: Gán nhãn tự động bằng machine learning
Đây là lúc “phép màu” xảy ra. Bạn dùng các mô hình machine learning (được huấn luyện trên một tập dữ liệu nhỏ đã gán nhãn thủ công) để dự đoán nhãn cho phần dữ liệu còn lại. Các kỹ thuật phổ biến gồm:
- Mô hình có giám sát: Huấn luyện một bộ phân loại trên các ví dụ đã gán nhãn, rồi dùng nó để gán nhãn dữ liệu mới.
- Gán nhãn theo luật: Dùng các quy tắc định sẵn (ví dụ: “nếu giá > 1000 USD thì gán là ‘cao cấp’”) cho các trường hợp đơn giản.
- Học chủ động: Mô hình sẽ hỏi con người ở những trường hợp chưa chắc chắn, và cải thiện dần theo thời gian (GeeksforGeeks).
- Học chuyển giao: Dùng các mô hình đã được huấn luyện sẵn để khởi động nhanh việc gán nhãn ở miền dữ liệu mới (GeeksforGeeks).
Kết quả là gì? Nhãn nhất quán, chất lượng cao — ở quy mô lớn.
Bước 4: Đảm bảo chất lượng và rà soát bởi con người
Ngay cả mô hình tốt nhất cũng cần được kiểm tra lại. Việc rà soát định kỳ bởi con người giúp phát hiện các trường hợp biên, dữ liệu mơ hồ hoặc hiện tượng model drift. Một vài bước QA thực tế gồm:
- Lấy mẫu ngẫu nhiên dữ liệu đã gán nhãn để kiểm tra thủ công
- So sánh nhãn tự động với một tập “gold standard”
- Dùng các chỉ số đồng thuận giữa các annotator để đo độ nhất quán (Kili Technology)
Cách dùng Thunderbit cho gán nhãn dữ liệu tự động bằng machine learning
Giờ thì đến phần thực hành. Thunderbit là một AI web scraper kiêm công cụ gán nhãn dữ liệu được thiết kế cho người dùng doanh nghiệp — không cần code. Đây là cách bạn có thể dùng nó để tự động hóa quy trình gán nhãn:
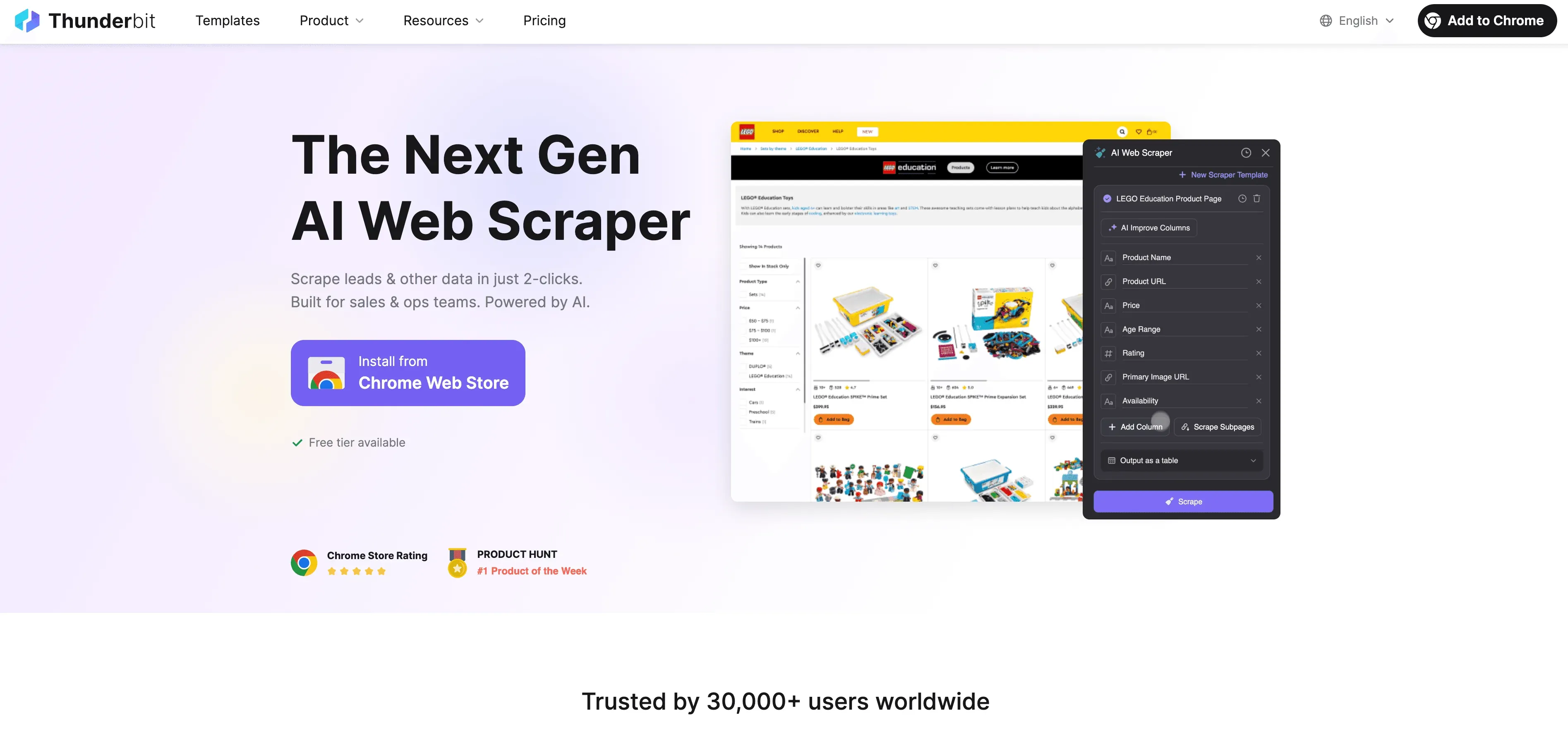
Hướng dẫn từng bước
- Thu thập dữ liệu từ website: Dùng Thunderbit Chrome Extension để lấy dữ liệu có cấu trúc từ bất kỳ website nào. Chỉ cần mở tiện ích, chọn nguồn dữ liệu của bạn, rồi để AI của Thunderbit gợi ý những trường tốt nhất cần trích xuất.
- Xác định hướng dẫn gán nhãn: Dùng các prompt ngôn ngữ tự nhiên của Thunderbit để nói cho AI biết cách gán nhãn dữ liệu. Ví dụ: “Gán ‘premium’ cho tất cả sản phẩm trên 500 USD” hoặc “Gắn nhãn các đánh giá có cảm xúc tích cực”.
- Áp dụng gán nhãn tự động: Tính năng Field AI Prompt của Thunderbit cho phép bạn tùy chỉnh và tinh chỉnh cách nhãn được gán — rất phù hợp cho các bài toán gán nhãn nhiều trường hoặc phức tạp.
- Xuất dữ liệu đã gán nhãn: Sau khi dữ liệu đã được gán nhãn, hãy xuất trực tiếp sang Excel, Google Sheets, Airtable hoặc Notion — sẵn sàng cho huấn luyện mô hình hoặc phân tích.
Điểm hay nhất là gì? Thunderbit được xây dựng cho người dùng không chuyên kỹ thuật trong bán hàng, marketing, vận hành và nhiều lĩnh vực khác. Bạn không cần viết một dòng code nào hay phải vật lộn với những template phức tạp.
Dùng thử Thunderbit để gán nhãn dữ liệu tự động
Prompt ngôn ngữ tự nhiên và các tính năng Field AI của Thunderbit
Một trong những tính năng tôi thích nhất là khả năng định nghĩa logic gán nhãn bằng tiếng Anh đơn giản. Bạn muốn phân loại lead theo khu vực, gắn thẻ sản phẩm theo danh mục, hay đánh dấu email có ngôn ngữ khẩn cấp? Chỉ cần mô tả điều bạn muốn, AI của Thunderbit sẽ lo phần còn lại.
Ví dụ prompt:
- “Gán tất cả liên hệ có email ‘.edu’ vào phân khúc ‘Giáo dục’.”
- “Nếu đánh giá nhắc đến ‘giao hàng nhanh’, gắn nhãn ‘Trải nghiệm giao hàng tích cực’.”
- “Nhóm sản phẩm theo thương hiệu và khoảng giá.”
Field AI Prompt của Thunderbit còn cho phép bạn đi sâu hơn nữa — tùy chỉnh logic gán nhãn cho từng cột, kết hợp nhiều quy tắc, hoặc thậm chí dịch nhãn sang nhiều ngôn ngữ.
Scrape trang con và gán nhãn nhiều trường
Cấu trúc dữ liệu phức tạp ư? Không sao. Tính năng subpage scraping của Thunderbit cho phép bạn trích xuất và gán nhãn dữ liệu từ các trang lồng nhau (như chi tiết sản phẩm hoặc tiểu sử tác giả) rồi hợp nhất tất cả vào một bảng có cấu trúc duy nhất. Bạn có thể gán nhãn nhiều trường cùng lúc — tiết kiệm thêm rất nhiều thời gian.
Trường hợp thực tế: Scrape danh sách sản phẩm từ một trang thương mại điện tử, sau đó lần theo từng link sản phẩm để trích xuất và gán nhãn thông số, đánh giá và thông tin người bán — tất cả trong cùng một quy trình.
Tích hợp nhiều công cụ gán nhãn dữ liệu để tăng độ chính xác và hiệu quả
Dù Thunderbit đã xử lý được rất nhiều phần việc, đôi khi bạn vẫn cần các công cụ chuyên biệt cho một số loại dữ liệu nhất định — như chú thích hình ảnh hoặc gán nhãn video. Đó là lúc các nền tảng như Label Studio hoặc Supervisely phát huy tác dụng.
Mẹo hay: Dùng Thunderbit để xử lý việc trích xuất dữ liệu web và gán nhãn ban đầu, sau đó xuất dữ liệu sang Label Studio hoặc Supervisely để chú thích nâng cao (như vẽ bounding box trên ảnh hoặc gắn thẻ video theo từng khung hình). Cách làm đa công cụ này giúp bạn tận dụng thế mạnh của từng nền tảng, từ đó tăng cả độ chính xác lẫn hiệu quả (GeeksforGeeks).
Khi nào nên dùng công cụ chuyên biệt cùng Thunderbit
- Chú thích hình ảnh: Với các bài toán như phát hiện đối tượng hoặc phân đoạn ảnh, hãy dùng Supervisely hoặc Label Studio.
- Gán nhãn video: Công cụ video chuyên dụng sẽ hỗ trợ chú thích theo từng khung hình và theo dõi đối tượng.
- Bài toán nhiều nhãn phức tạp: Kết hợp trích xuất dữ liệu có cấu trúc từ Thunderbit với công cụ chú thích nâng cao để đạt kết quả tốt nhất.
Thực hành tốt nhất: Bắt đầu với Thunderbit để gán nhãn nhanh, có thể mở rộng cho dữ liệu có cấu trúc và bán cấu trúc, rồi bổ sung công cụ chuyên dụng khi cần chú thích sâu hơn.
Cách scrape dữ liệu từ PDF bằng AI Tìm hiểu cách trích xuất và gán nhãn dữ liệu từ PDF bằng các công cụ AI của Thunderbit. Get Started Free
Thực hành tốt nhất cho gán nhãn dữ liệu tự động bằng machine learning
Muốn tận dụng tối đa quy trình gán nhãn tự động của bạn? Đây là những mẹo hàng đầu của tôi:
- Đặt hướng dẫn gán nhãn thật rõ ràng: Nhãn mơ hồ sẽ dẫn đến dữ liệu thiếu nhất quán — hãy cụ thể về ý nghĩa của từng nhãn.
- Bắt đầu với một tập hạt giống chất lượng cao: Tự tay gán nhãn một mẫu nhỏ, đại diện để huấn luyện mô hình ban đầu.
- Lặp và cải thiện: Dùng học chủ động để tinh chỉnh mô hình theo thời gian, tập trung rà soát của con người vào các trường hợp khó nhất.
- Kiểm tra định kỳ: Thường xuyên xem lại một mẫu ngẫu nhiên của dữ liệu đã gán nhãn để phát hiện lỗi hoặc drift.
- Tích hợp và tự động hóa: Dùng các công cụ như Thunderbit để nối liền thu thập dữ liệu, gán nhãn và xuất dữ liệu trong một quy trình duy nhất.
Những thách thức phổ biến và cách vượt qua
Gán nhãn dữ liệu tự động không phải lúc nào cũng suôn sẻ. Đây là cách xử lý những vấn đề thường gặp nhất:
- Dữ liệu mơ hồ: Dùng định nghĩa nhãn rõ ràng, chi tiết và cung cấp ví dụ cho các trường hợp biên.
- Model drift: Huấn luyện lại mô hình gán nhãn thường xuyên với dữ liệu mới đã được con người rà soát.
- Trường hợp biên: Thiết lập quy trình để con người kiểm tra những điểm dữ liệu không chắc chắn hoặc mới lạ.
- Vấn đề tích hợp: Chọn các công cụ (như Thunderbit) có khả năng xuất dữ liệu dễ dàng sang nền tảng bạn muốn dùng.
Kết luận và những điểm chính cần nhớ
Gán nhãn dữ liệu tự động bằng machine learning chính là “vũ khí bí mật” đứng sau những mô hình AI hiệu quả nhất ngày nay. Nó tiết kiệm thời gian, giảm chi phí và quan trọng nhất là mang lại những nhãn nhất quán, chất lượng cao mà mô hình cần để đạt hiệu suất tốt nhất. Bằng cách kết hợp các công cụ như Thunderbit với những nền tảng chú thích chuyên biệt, bạn có thể xây dựng một quy trình gán nhãn nhanh, chính xác và có thể mở rộng — bất kể nền tảng kỹ thuật của bạn là gì.
Sẵn sàng tự mình thấy sự khác biệt chưa? Tải Thunderbit, thử gán nhãn tự động cho dự án tiếp theo của bạn, và xem các mô hình machine learning trở nên thông minh hơn, nhanh hơn. Và nếu bạn muốn đọc thêm mẹo và thực hành tốt nhất, hãy xem Thunderbit Blog để đọc các bài phân tích sâu và hướng dẫn chi tiết.
Tự động gán nhãn dữ liệu với Thunderbit
Câu hỏi thường gặp
1. Gán nhãn dữ liệu tự động bằng machine learning là gì?
Đó là quá trình dùng AI và các mô hình ML để tự động gán nhãn cho dữ liệu, thay vì để con người làm thủ công. Cách này giúp tăng tốc gán nhãn, cải thiện tính nhất quán và mở rộng tốt cho các bộ dữ liệu lớn.
2. Vì sao chất lượng gán nhãn lại quan trọng với machine learning?
Mô hình chỉ học những mẫu mà nhãn của nó thể hiện, nên nhãn không nhất quán hoặc sai sẽ dạy cho mô hình điều sai. Các bài viết ngành từ những nhà cung cấp gán nhãn như Keylabs cho thấy quy trình lai giữa AI và con người có thể nâng độ chính xác gán nhãn lên tới 80% so với quy trình hoàn toàn thủ công — và mức cải thiện đó đi thẳng vào hiệu suất mô hình.
3. Thunderbit hỗ trợ gán nhãn dữ liệu tự động như thế nào?
Thunderbit cho phép bạn scrape và gán nhãn dữ liệu web bằng AI, với prompt ngôn ngữ tự nhiên và logic trường có thể tùy chỉnh — không cần code. Đây là lựa chọn lý tưởng cho người dùng doanh nghiệp trong bán hàng, marketing và vận hành.
4. Tôi có thể kết hợp Thunderbit với công cụ gán nhãn khác không?
Hoàn toàn có thể. Hãy dùng Thunderbit để trích xuất dữ liệu có cấu trúc và gán nhãn ban đầu, rồi xuất sang các công cụ như Label Studio hoặc Supervisely để chú thích ảnh hay video nâng cao.
5. Thực hành tốt nhất cho gán nhãn dữ liệu tự động là gì?
Hãy đặt hướng dẫn gán nhãn rõ ràng, bắt đầu bằng một tập hạt giống chất lượng, lặp cải thiện bằng học chủ động, kiểm tra định kỳ và dùng các công cụ tích hợp để tinh gọn quy trình.
Sẵn sàng tự động hóa việc gán nhãn dữ liệu và tăng tốc các dự án machine learning của bạn chưa? Hãy thử Thunderbit và xem bạn tiết kiệm được bao nhiêu thời gian — và bớt đi bao nhiêu bực bội.
Tìm hiểu thêm:
- Cách scrape dữ liệu từ PDF bằng AI
- Data Scraping là gì và cách thực hiện năm 2025
- List Crawling là gì và cách thực hiện bằng AI
- Cách scrape bất kỳ website nào bằng AI
Thử AI Web Scraper để gán nhãn dữ liệu tự động Get Started Free




