Capterra 爬虫

ได้รับความไว้วางใจจากมืออาชีพในบริษัทชั้นนำ














ดึงข้อมูล Capterra ได้อย่างง่ายดายด้วย Thunderbit
ปรับตัวตามการเปลี่ยนแปลงของเลย์เอาต์ Capterra ได้
เบื่อไหมที่ตัวสแครปล่มทุกครั้งที่ Capterra ปรับดีไซน์? Thunderbit เข้าใจโครงสร้างของหน้า ไม่ได้ยึดแค่ selector ตายตัว นั่นหมายความว่ามันปรับตามการเปลี่ยนเลย์เอาต์ได้อัตโนมัติ คุณจึงดึงชื่อสินค้า คะแนน และคำอธิบายต่อไปได้โดยไม่ต้องคอยดูแลแก้ไขตลอด
เครื่องมือเดียวสำหรับทุกแหล่งข้อมูล
ไม่ต้องสลับไปมาระหว่างสแครปเปอร์หลายตัวสำหรับหลายเว็บไซต์ Thunderbit ใช้งานกับ Capterra ได้ทันทีตั้งแต่แกะกล่อง และยังมีเทมเพลตสำเร็จรูปกว่า 50 แบบสำหรับแพลตฟอร์มยอดนิยมอื่น ๆ ไม่ว่าข้อมูลจะมาจากเว็บไหน Thunderbit ก็จัดการให้ได้
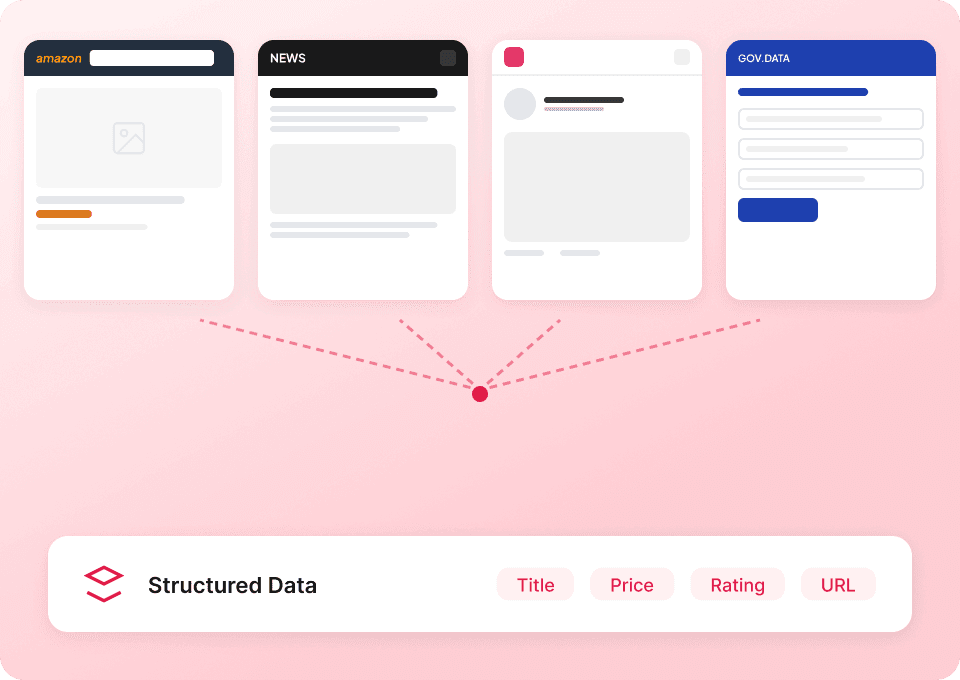
เก็บภาพรวมของ Capterra ได้ครบกว่าเดิม
อย่าหยุดแค่ข้อมูลจากหน้ารายการสินค้า Thunderbit สามารถเข้าไปยังซับเพจของแต่ละสินค้าใน Capterra แล้วดึงข้อมูลเชิงลึกออกมาได้โดยอัตโนมัติ รับคำอธิบายแบบละเอียด ราคาเริ่มต้น และอื่น ๆ เพิ่มเป็นคอลัมน์ใหม่ในรูปแบบที่คุณต้องการ

还在为无法高效抓取 Capterra 而烦恼吗?
看看 Thunderbit 如何简化 Capterra 数据提取,即使面对复杂版面也不在话下。
传统爬虫
过去常见的做法Thunderbit
更聪明的方式อย่าเพิ่งเชื่อแค่คำเราบอก
ดูว่าผู้ใช้พูดถึง Thunderbit ว่าอย่างไร






คำถามที่พบบ่อย
ที่เกี่ยวข้อง กรณีใช้งาน
สำรวจกรณีใช้งานเพิ่มเติมของเว็บสแครปเปอร์ Thunderbit
Elgiganten Scraper
ดึงชื่อสินค้า ราคา และข้อมูลความพร้อมจำหน่ายจาก Elgiganten ได้ในแค่ 2 คลิก — ที่เหลือให้ AI ของ Thunderbit จัดการให้หมด
เรียนรู้เพิ่มเติม ->
PubMed Scraper
PubMed Scraper ของ Thunderbit ช่วยดึงข้อมูลแบบมีโครงสร้างจากหน้าผลการค้นหาและหน้าบทความบน PubMed ด้วยพลัง AI เก็บข้อมูลงานวิจัยการแพทย์ที่กำลังมาแรง หลักฐานจากการทดลองทางคลินิก บทคัดย่อ ผู้เขียน สังกัด วันที่เผยแพร่ และลิงก์ต่าง ๆ แล้วส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion ได้ทันที
เรียนรู้เพิ่มเติม ->
HKTVmall Scraper
ดึงชื่อสินค้า ราคา และแม้แต่คะแนนรีวิวจากรายการสินค้า HKTVmall ได้ในไม่กี่คลิก — ไม่ต้องตั้งค่าอะไรซับซ้อน
เรียนรู้เพิ่มเติม ->สแครปเปอร์ Substack
ดึงจำนวนผู้ติดตาม Substack ชื่อบทความ และคำอธิบายของสิ่งพิมพ์ลงในสเปรดชีตที่สะอาดเรียบร้อย — ไม่ต้องเขียนโค้ด AI จัดโครงสร้างให้
เรียนรู้เพิ่มเติม ->
Craigslist Phone Number Scraper
Craigslist Phone Number Scraper ของ Thunderbit ช่วยดึงเบอร์โทรและรายละเอียดประกาศจากผลการค้นหาใน Craigslist ด้วย AI โดยสามารถเก็บข้อมูลจากหน้ารวมรายการ แล้วให้ระบบเข้าไปเปิดแต่ละโพสต์เพื่อดึงข้อมูลติดต่อและฟิลด์เพิ่มเติม จากนั้นส่งออกไปยัง Excel, Google Sheets, Airtable, Notion, CSV หรือ JSON ได้ทันที
เรียนรู้เพิ่มเติม ->
Spokeo Scraper
หยุดคัดลอกข้อมูลจาก Spokeo ด้วยตัวเอง — ใช้ Thunderbit ดึงชื่อ อายุ ที่อยู่ และอื่น ๆ ได้ในแค่ไม่กี่คลิก
เรียนรู้เพิ่มเติม ->พร้อมยกระดับการดึงข้อมูลให้แรงขึ้นหรือยัง?
เข้าร่วมกับมืออาชีพกว่า 100,000 คนที่ใช้ Thunderbit เพื่อทำเวิร์กโฟลว์เว็บสแครปปิงให้อัตโนมัติ
ทดลองใช้ฟรีพร้อมเครดิตไม่จำกัดสำหรับ 8 เว็บเพจ