

PubMed Scraper ของ Thunderbit ช่วยเปลี่ยนหน้า PubMed ให้กลายเป็นชุดข้อมูลที่สะอาดและเป็นระบบด้วย AI คุณสามารถดึงข้อมูลงานวิจัยการแพทย์ที่กำลังเป็นกระแส หลักฐานจากการทดลองทางคลินิก บทคัดย่อ ผู้เขียน สังกัด วันที่เผยแพร่ PMID และลิงก์บทความ จากนั้นส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion ได้ง่าย ๆ แค่เปิด PubMed บน Chrome ให้ AI แนะนำคอลัมน์ที่เหมาะที่สุด แล้วกดสแครป
🧬 PubMed Scraper คืออะไร
PubMed Scraper คือ AI Web Scraper ที่สร้างมาเพื่อใช้งานกับ โดยใช้ (ส่วนขยาย Chrome สำหรับ AI web scraper) คุณเพียงเข้าไปที่หน้าผลลัพธ์ของ PubMed กด AI Suggest Columns แล้วกด Scrape ก็ได้ข้อมูลแบบมีโครงสร้างโดยไม่ต้องเขียนโค้ด
🔎 PubMed สแครปอะไรได้บ้าง
PubMed มีเมทาดาต้าด้านชีวการแพทย์ที่มีมูลค่าสูงจำนวนมาก แต่ข้อมูลมักยังไม่พร้อมสำหรับการวิเคราะห์ทันที Thunderbit’s AI Web Scraper (https://thunderbit.com/) ช่วยรวบรวมและจัดโครงสร้างรายการจาก PubMed และยังต่อยอดรายละเอียดระดับบทความด้วย Subpage Scraping (เปิดหน้าบทความแต่ละรายการแล้วเติมฟิลด์อย่างบทคัดย่อ สังกัด DOI และอื่น ๆ)
ด้านล่างคือ 2 เวิร์กโฟลว์ยอดนิยมที่ทำได้ภายในไม่กี่นาที
📈 สแครปหน้า PubMed Trending เพื่อติดตามงานวิจัยที่กำลังมาแรง
เวิร์กโฟลว์นี้เหมาะสำหรับติดตามเทรนด์งานวิจัยการแพทย์จากหน้า Trending ของ PubMed ใช้ได้ทั้งเพื่ออัปเดตความเคลื่อนไหว ทำสรุปภายในองค์กร ติดตามงานตีพิมพ์ของคู่แข่ง หรือป้อนข้อมูลเข้าระบบติดตามวรรณกรรม (literature monitoring)
ตัวอย่างหน้าปลายทาง:
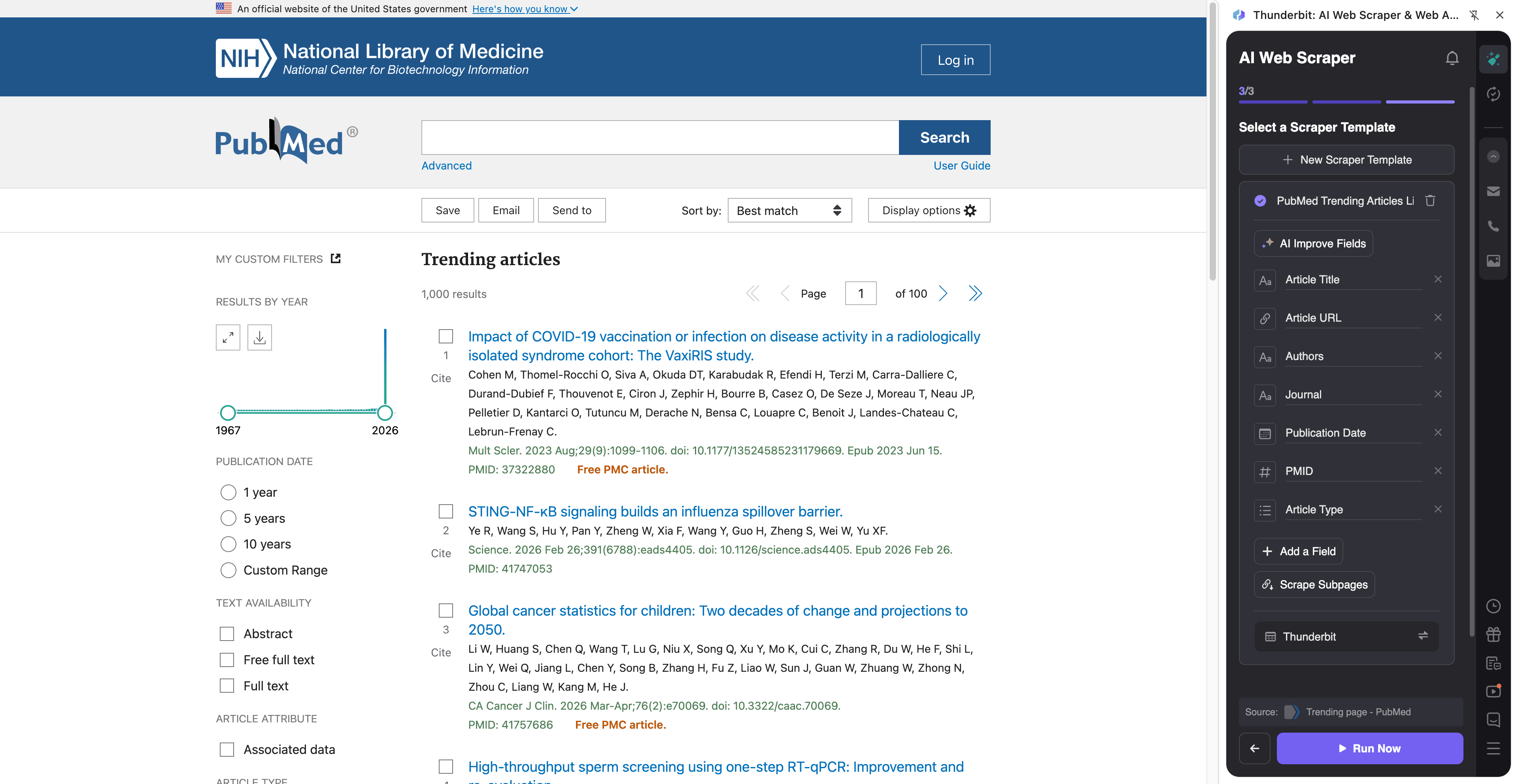
ขั้นตอน:
- ติดตั้ง และสมัครบัญชี
- ไปที่หน้าปลายทาง เช่น:
- กด AI Suggest Columns เพื่อให้ AI แนะนำชื่อคอลัมน์และชนิดข้อมูลที่เหมาะสม
- กด Scrape เพื่อดึงข้อมูล แล้วส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion
ชื่อคอลัมน์
| คอลัมน์ | คำอธิบาย |
|---|---|
| 🧾 ชื่อบทความ (Article Title) | ชื่อบทความที่กำลังเป็นเทรนด์บน PubMed |
| 🔗 ลิงก์บทความ (Article URL) | ลิงก์ตรงไปยังหน้าระเบียนของ PubMed |
| 🆔 PMID | รหัสระบุของ PubMed สำหรับระเบียนนั้น (เหมาะใช้เป็นคีย์อ้างอิงที่คงที่) |
| 🏛️ วารสาร (Journal) | ชื่อวารสารที่ตีพิมพ์บทความ |
| 📅 วันที่เผยแพร่ (Publication Date) | วันที่เผยแพร่ที่แสดงในรายการ |
| ✍️ ผู้เขียน (Authors) | รายชื่อผู้เขียนที่แสดงบนการ์ดผลลัพธ์ |
| 🧪 ประเภทบทความ (Article Type) | ประเภทสิ่งพิมพ์เมื่อมีให้ (เช่น Review, Clinical Trial) |
| 🏷️ คีย์เวิร์ด/หัวข้อ (Keywords / Topics) | แท็กหัวข้อหรือคีย์เวิร์ดที่มองเห็นได้ในรายการ (ถ้ามี) |
| 📝 ข้อความย่อ/สรุป (Snippet / Summary) | ข้อความสั้น ๆ ที่แสดงในรายการ (ถ้ามี) |
| 🧷 DOI | DOI เมื่อมีให้ (มักเก็บได้แม่นยำขึ้นด้วยการสแครปซับเพจ) |
| 🧑🔬 สังกัด (Affiliations) | สังกัดของผู้เขียน (โดยมากดึงจากการสแครปซับเพจ) |
| 📄 บทคัดย่อ (Abstract) | ข้อความบทคัดย่อ (โดยมากดึงจากการสแครปซับเพจ) |
🧫 สแครป PubMed เพื่อดึงหลักฐานจากงานทดลองทางคลินิก (Clinical Trial)
เวิร์กโฟลว์นี้ใช้ดึงหลักฐานที่เกี่ยวข้องกับการทดลองทางคลินิกจากผลการค้นหา PubMed แล้วค่อยเสริมข้อมูลรายแถวด้วยการเข้าไปที่หน้าบทความเพื่อเก็บบทคัดย่อ สัญญาณ/คีย์เวิร์ดของการทดลอง และเมทาดาต้าที่จำเป็นต่อการรีวิว
ตัวอย่างหน้าปลายทาง:
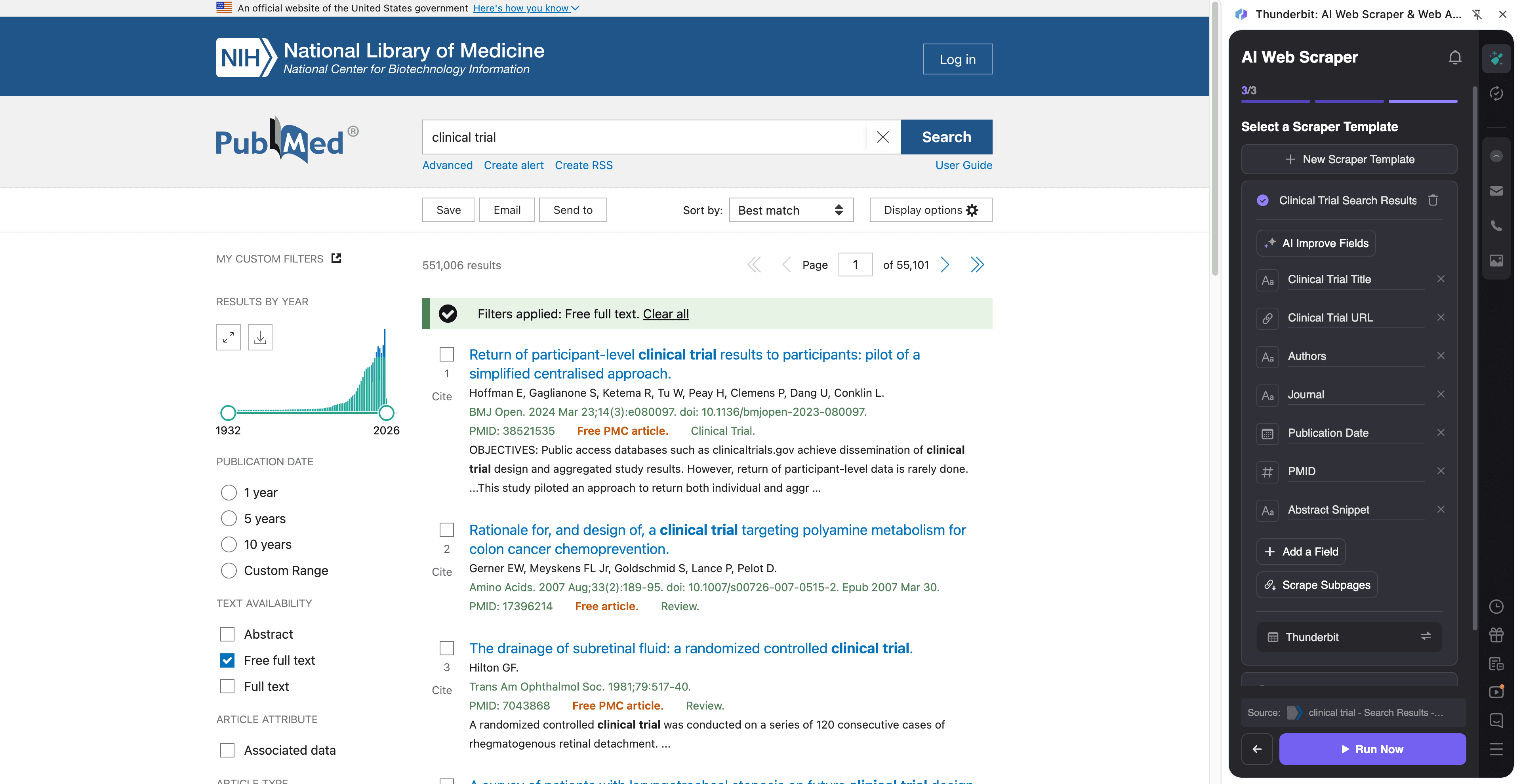
ขั้นตอน:
- ติดตั้ง และสมัครบัญชี
- ไปที่หน้าปลายทาง เช่น:
- กด AI Suggest Columns เพื่อให้ระบบสร้างฟิลด์แนะนำ (คุณสามารถเปลี่ยนชื่อหรือเพิ่มคอลัมน์เองได้)
- กด Scrape เพื่อเก็บผลลัพธ์ จากนั้นใช้ Scrape Subpages เพื่อเติมข้อมูลรายแถว เช่น บทคัดย่อ สังกัด DOI และอื่น ๆ
ชื่อคอลัมน์
| คอลัมน์ | คำอธิบาย |
|---|---|
| 🧾 ชื่อเรื่อง (Title) | ชื่อบทความจากหน้าผลการค้นหา |
| 🔗 ลิงก์ PubMed (PubMed URL) | ลิงก์ไปยังหน้าบทความบน PubMed เพื่อใช้เสริมข้อมูลจากซับเพจ |
| 🆔 PMID | รหัส PubMed สำหรับตัดข้อมูลซ้ำและใช้อ้างอิง |
| 🧑⚕️ ผู้เขียน (Authors) | รายชื่อผู้เขียนที่แสดงในสไนเป็ตของผลลัพธ์ |
| 🏛️ วารสาร (Journal) | ชื่อวารสารและข้อมูลการอ้างอิงที่แสดงในผลลัพธ์ |
| 📅 วันที่ (Date) | วันที่เผยแพร่ (หรือ ePub) ที่แสดงในรายการ |
| 🧪 ประเภทสิ่งพิมพ์ (Publication Type) | สัญญาณอย่าง Clinical Trial, Randomized Controlled Trial, Meta-Analysis (มักชัดเจนกว่าในหน้าบทความ) |
| 🧾 บทคัดย่อ (Abstract) | ข้อความบทคัดย่อแบบเต็ม (เหมาะดึงผ่านการสแครปซับเพจ) |
| 🧬 MeSH Terms | Medical Subject Headings เมื่อมีให้ (มักอยู่ในหน้าบทความ) |
| 🧷 DOI | DOI สำหรับเชื่อมไปยังหน้า publisher และเครื่องมือจัดการบรรณานุกรม |
| 🏥 สังกัด (Affiliations) | สังกัดผู้เขียนเพื่อวิเคราะห์สถาบัน (สแครปซับเพจ) |
| 🌍 ประเทศ/สถาบัน (Country / Institution) | แยกจากสังกัดด้วย Field AI Prompts (ตัวเลือกเสริม) |
| 🔍 คีย์เวิร์ดสัญญาณการทดลอง (Clinical Trial Keywords) | ธงที่ AI ติดป้าย เช่น “randomized”, “double-blind”, “placebo” (ทำได้ผ่าน Field AI Prompt) |
| 📎 ลิงก์ฉบับเต็ม (Full Text Links) | ลิงก์ออกไปยัง publisher หรือฉบับเต็มฟรีเมื่อมีให้ |
🎯 ทำไมควรใช้เครื่องมือ PubMed
การสแครป PubMed คือการเพิ่มความเร็ว ความสม่ำเสมอ และทำให้ข้อมูลวิจัยนำไปใช้ต่อได้จริง แทนที่จะคัดลอกการอ้างอิงทีละรายการ คุณสามารถสร้างชุดข้อมูลที่กรอง ติดแท็ก และแชร์ต่อได้ทันที
เหตุผลที่ทีมต่าง ๆ มักสแครป PubMed:
- ทีม medical affairs & pharma: ติดตามงานตีพิมพ์ใหม่ใน therapeutic area เฝ้าดูการทดลองของคู่แข่ง และทำตารางหลักฐานสำหรับรีวิวภายใน
- ทีม biotech & clinical operations: รวบรวมงานตีพิมพ์ที่เกี่ยวกับการทดลอง ทำแผนที่สถาบัน/ผู้วิจัย และดูแลบรรณานุกรมแบบอัปเดตตลอดเวลา
- ทีมการตลาดสุขภาพ & คอนเทนต์: หาเทรนด์ หาวารสารที่มีอิทธิพล และคีย์เวิร์ดใหม่ ๆ เพื่อวางแผนคอนเทนต์
- นักวิจัยและบรรณารักษ์: สร้างชุดข้อมูลสำหรับ literature review ตัดซ้ำด้วย PMID และส่งออกไปสเปรดชีตเพื่อคัดกรอง
- ทีมข้อมูล (Data teams): สร้างอินพุตแบบมีโครงสร้างสำหรับการวิเคราะห์ต่อ แดชบอร์ด หรือคลังความรู้ภายใน
Thunderbit จะยิ่งมีประโยชน์เมื่อคุณต้องการมากกว่าข้อมูลในหน้ารายการ เพราะ Subpage Scraping ช่วยดึงบทคัดย่อ สังกัด DOI MeSH terms และลิงก์ฉบับเต็มได้ในปริมาณมาก
🧩 วิธีใช้ PubMed Chrome Extension
- ติดตั้ง Thunderbit Chrome Extension: ดาวน์โหลดจาก และสร้างบัญชี
- เข้าไปที่หน้า PubMed: เปิด หน้าเทรนด์อย่าง หรือหน้าค้นหาเช่น
- เปิดใช้งานตัวสแครปด้วย AI: กด AI Suggest Columns เพื่อสร้างฟิลด์ ปรับชนิดข้อมูล (text/date/url) และเพิ่ม Field AI Prompts ได้ตามต้องการ (เพื่อจัดหมวดหมู่ จัดรูปแบบ หรือดึงสัญญาณการทดลอง)
- สแครปและส่งออก: กด Scrape หากต้องการบทคัดย่อ/สังกัด/MeSH ให้รัน Scrape Subpages เพื่อเติมข้อมูลให้ครบในตารางเดียว แล้วส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion
บทความแนะนำสำหรับคนที่ต้องการทำเวิร์กโฟลว์ให้ทำซ้ำได้:
💳 ราคา PubMed
Thunderbit ใช้ระบบเครดิตที่เข้าใจง่าย:
- 1 เครดิต = 1 แถวผลลัพธ์ ในตาราง (เช่น 1 ระเบียน PubMed)
- การส่งออกข้อมูลฟรี: ดาวน์โหลดเป็น CSV/JSON หรือส่งไปยัง Excel, Google Sheets, Airtable หรือ Notion
เริ่มต้นได้ด้วย:
- Free tier: สแครปได้ 6 หน้า/เดือน (โควตาแบบนับเป็นหน้าในแพ็กเกจฟรี)
- Free trial: สแครปได้ 10 หน้า ฟรี เหมาะสำหรับทดสอบหน้า Trending และหน้าผลลัพธ์ clinical trial บางส่วน
หากคุณสแครปเป็นประจำ (ติดตามรายสัปดาห์ อัปเดตหลักฐาน หรือคิวรีขนาดใหญ่) แพ็กเกจแบบชำระเงินจะให้เครดิตมากขึ้น โดยทั่วไปแพ็กเกจรายปีคุ้มกว่ารายเดือน เพราะมีส่วนลดเมื่อเทียบกับการจ่ายเดือนต่อเดือน
ดูรายละเอียดได้ที่
❓ คำถามที่พบบ่อย (FAQ)
-
AI Powered PubMed Scraper คืออะไร?
AI Powered PubMed Scraper คือเวิร์กโฟลว์ใน Thunderbit สำหรับดึงข้อมูลแบบมีโครงสร้างจากผลการค้นหาและหน้าบทความของ PubMed คุณสามารถให้ AI แนะนำคอลัมน์ สแครปรายการ และเสริมข้อมูลรายแถวด้วยการเข้าไปที่ซับเพจของบทความเพื่อเก็บบทคัดย่อ สังกัด DOI และอื่น ๆ -
Thunderbit คืออะไร?
คือส่วนขยาย Chrome แบบ AI web scraper ที่ออกแบบมาสำหรับงานธุรกิจและงานวิจัยที่ต้องการข้อมูลแบบมีโครงสร้างจากเว็บไซต์ ช่วยดึงข้อมูล ติดป้ายกำกับ และส่งออกได้รวดเร็ว โดยไม่ต้องสร้างหรือดูแลสคริปต์สแครป -
สแครปหน้า PubMed Trending และผลการค้นหาปกติได้ไหม?
ได้ คุณสามารถสแครปหน้า การค้นหาด้วยคีย์เวิร์ดทั่วไป และหน้าผลลัพธ์ที่มีตัวกรอง (เช่น คิวรีที่โฟกัส clinical trial) AI ของ Thunderbit จะอ่านโครงหน้าและเสนอฟิลด์ให้เหมาะกับเลย์เอาต์ที่ต่างกัน -
Thunderbit ดึงบทคัดย่อ สังกัด และ MeSH terms ได้ไหม?
ได้ และนี่คือจุดที่ Subpage Scraping ช่วยได้มากที่สุด คุณสามารถสแครปหน้ารายการก่อน แล้วให้ Thunderbit เปิดหน้าระเบียน PubMed ทีละรายการเพื่อดึงบทคัดย่อ สังกัด MeSH terms DOI และเมทาดาต้าอื่น ๆ เข้ามาในตารางเดียวกัน -
การแบ่งหน้า (pagination) และ infinite scroll บน PubMed ทำงานอย่างไร?
Thunderbit รองรับการสแครปแบบแบ่งหน้า รวมถึงการนำทางแบบ “หน้าถัดไป” หาก PubMed เปลี่ยนวิธีโหลดผลลัพธ์ การดึงข้อมูลด้วย AI มักยืดหยุ่นกว่าการใช้ตัวเลือกแบบตายตัว เพราะระบบจะอ่านโครงสร้างหน้าใหม่ทุกครั้งที่รัน -
ส่งออกข้อมูล PubMed ได้เป็นรูปแบบไหนบ้าง?
ส่งออกเป็น CSV หรือ JSON ได้ หรือส่งชุดข้อมูลไปยัง Excel, Google Sheets, Airtable หรือ Notion เหมาะสำหรับงานคัดกรอง (screening) ตารางหลักฐาน แดชบอร์ด และการแชร์กับผู้ร่วมงาน -
สแครประเบียน PubMed ได้ฟรีกี่รายการ?
ใน Free tier คุณสแครปได้ 6 หน้า/เดือน ซึ่งมักพอสำหรับงานติดตามขนาดเล็ก ส่วน Free trial ให้สแครปได้ 10 หน้า ฟรี เพื่อยืนยันการตั้งค่าคอลัมน์และกลยุทธ์การเสริมข้อมูลจากซับเพจ -
ปรับคอลัมน์ให้ตรงกับงานดึงหลักฐานเฉพาะทางได้ไหม?
ได้ คุณสามารถเปลี่ยนชื่อคอลัมน์ ตั้งชนิดข้อมูล (text/date/url) และเพิ่ม Field AI Prompts เพื่อดึง/ติดป้ายข้อมูล เช่น คีย์เวิร์ดรูปแบบการทดลอง (trial design) ประชากร (population) การรักษา (intervention) ตัวเปรียบเทียบ (comparator) ผลลัพธ์ (outcomes) หรือประเทศจากสังกัด ช่วยให้ไปไกลกว่าการสแครปดิบ ๆ สู่การเตรียมหลักฐานแบบมีโครงสร้าง -
สแครป PubMed ได้ไหม ถือว่าโอเคหรือเปล่า?
PubMed เป็นแหล่งข้อมูลสาธารณะ และหลายทีมเก็บเมทาดาต้าบรรณานุกรมเพื่อการวิจัยและการวิเคราะห์ อย่างไรก็ตาม คุณควรปฏิบัติตามกฎหมายที่เกี่ยวข้อง เคารพเงื่อนไขการใช้งานของเว็บไซต์ และสแครปอย่างรับผิดชอบ โดยเฉพาะเมื่อรันงานขนาดใหญ่หรือถี่มาก
📚 อ่านเพิ่มเติม
- ดาวน์โหลดส่วนขยาย:
- ดูคู่มือทั้งหมดที่:
- เรียนรู้พื้นฐาน:
- ทำเวิร์กโฟลว์แบบลิสต์:
- ส่งออกไปสเปรดชีต:
- ถ้าคุณต้องสแครป PDF ในงาน research ops ด้วย: