
“คุณมีข้อมูลได้โดยไม่มีสารสนเทศ แต่คุณจะมีสารสนเทศไม่ได้หากไม่มีข้อมูล” — *
จากการประเมินล่าสุด คาดว่ามีเว็บไซต์บนอินเทอร์เน็ตมากกว่า เว็บไซต์ และมีโพสต์ใหม่ราว 2 ล้านโพสต์ถูกเผยแพร่ทุกวัน มหาสมุทรของข้อมูลนี้เต็มไปด้วยอินไซต์ที่มีคุณค่าสำหรับใช้ประกอบการตัดสินใจ แต่มีข้อแม้อยู่คือประมาณ เป็นข้อมูลที่ไม่มีโครงสร้าง ซึ่งต้องผ่านการประมวลผลเพิ่มเติมก่อนจึงจะนำไปใช้ได้ นี่คือจุดที่เครื่องมือดึงข้อมูลเว็บเข้ามามีบทบาท และกลายเป็นสิ่งจำเป็นสำหรับทุกคนที่ต้องการเข้าถึงข้อมูลออนไลน์
ถ้าคุณเพิ่งเริ่มต้นกับ web scraping คำอย่าง และ อาจฟังดูน่ากลัวไปหน่อย แต่ในยุคของ AI ความท้าทายเหล่านี้จัดการได้ง่ายขึ้นมาก เครื่องมือดึงข้อมูลที่ขับเคลื่อนด้วย AI ในปัจจุบันช่วยให้คุณเริ่มต้นได้โดยไม่ต้องมีความรู้เชิงเทคนิคลึก ๆ เครื่องมือเหล่านี้ทำให้การเก็บและประมวลผลข้อมูลเป็นเรื่องรวดเร็ว โดยไม่ต้องเขียนโค้ด
เครื่องมือและซอฟต์แวร์ดึงข้อมูลเว็บที่ดีที่สุด
- สำหรับ AI web scraper ที่ใช้งานง่ายและให้ผลลัพธ์ดีที่สุด
- สำหรับการติดตามแบบเรียลไทม์และการดึงข้อมูลจำนวนมาก
- สำหรับระบบอัตโนมัติแบบไม่ต้องเขียนโค้ดที่เชื่อมต่อแอปได้หลากหลาย
- สำหรับการดึงข้อมูลเว็บแบบภาพที่ดูเป็นมืออาชีพมากขึ้น
- สำหรับการดึงข้อมูลแบบไม่ต้องเขียนโค้ดที่ทรงพลัง พร้อมหลีกเลี่ยงการบล็อก IP และการตรวจจับบอท
- สำหรับ API ดึงข้อมูลด้วย AI ขั้นสูงและกราฟความรู้
ลองใช้ AI กับการดึงข้อมูลเว็บ
ลองเลย! คุณสามารถคลิก สำรวจ และรันเวิร์กโฟลว์ไปพร้อมกับที่ดูได้
การดึงข้อมูลเว็บทำงานอย่างไร?
Web scraping คือการดึงข้อมูลจากเว็บไซต์ คุณให้ชุดคำสั่งกับเครื่องมือ แล้วมันจะไปดึงข้อความ รูปภาพ หรือข้อมูลที่คุณต้องการใส่ลงในตารางจากหน้าเว็บ วิธีนี้มีประโยชน์มากตั้งแต่การติดตามราคาบนเว็บอีคอมเมิร์ซ ไปจนถึงการรวบรวมข้อมูลวิจัย หรือแม้แต่การสร้างสเปรดชีต Excel หรือ Google Sheets ให้พร้อมใช้งาน
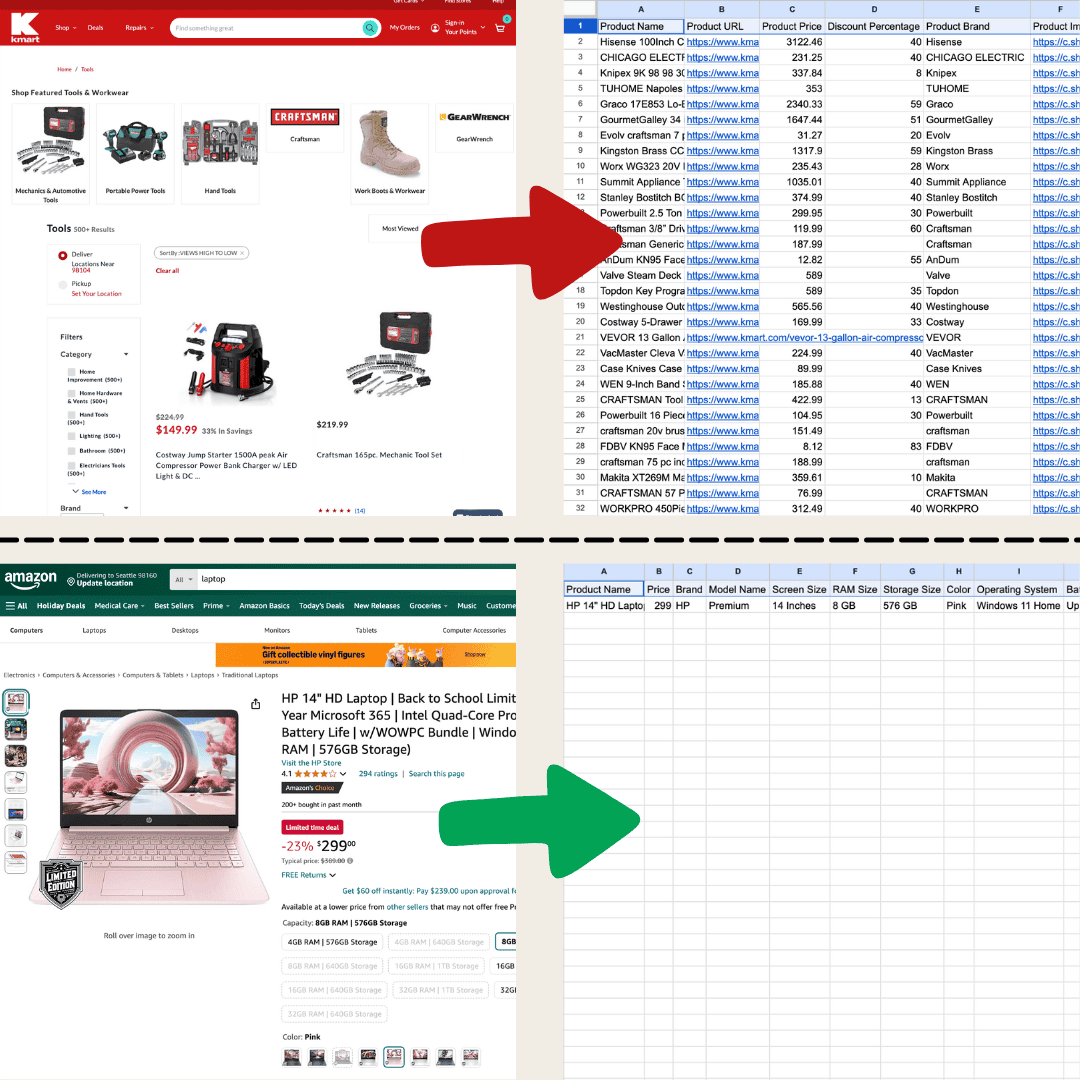 ฉันทำภาพนี้ด้วย Thunderbit โดยใช้ AI Web Scraper
ฉันทำภาพนี้ด้วย Thunderbit โดยใช้ AI Web Scraper
มีหลายวิธีในการทำเรื่องนี้ ในระดับพื้นฐานที่สุด คุณอาจคัดลอกและวางเองก็ได้ แต่ถ้ามีข้อมูลเยอะ วิธีนั้นจะเสียเวลามาก ดังนั้นคนส่วนใหญ่จึงใช้หนึ่งในสามวิธีนี้: traditional web scrapers, AI web scrapers หรือโค้ดที่เขียนขึ้นเอง
traditional web scrapers ทำงานโดยกำหนดกฎเฉพาะว่าข้อมูลอะไรควรถูกดึงออกมาตามโครงสร้างของหน้าเว็บ เช่น คุณสามารถตั้งให้ดึงชื่อสินค้า หรือราคาจากแท็ก HTML บางตัวได้ วิธีนี้เหมาะที่สุดกับเว็บไซต์ที่แทบไม่เปลี่ยนแปลงบ่อย เพราะถ้าเลย์เอาต์มีการปรับนิดเดียว คุณก็ต้องกลับไปแก้ scraper ของคุณใหม่
 การใช้ scraper แบบดั้งเดิมต้องใช้เวลาเรียนรู้นาน และอาจต้องคลิกหลายสิบครั้งกว่าจะตั้งค่าเสร็จ
การใช้ scraper แบบดั้งเดิมต้องใช้เวลาเรียนรู้นาน และอาจต้องคลิกหลายสิบครั้งกว่าจะตั้งค่าเสร็จ
AI web scrapers พูดแบบง่าย ๆ ก็คือ ChatGPT อ่านทั้งเว็บไซต์ แล้วค่อยดึงเนื้อหาตามที่คุณต้องการ มันสามารถจัดการการดึงข้อมูล การแปล และการสรุปได้ในเวลาเดียวกัน โดยใช้การประมวลผลภาษาธรรมชาติวิเคราะห์และเข้าใจโครงสร้างของเว็บไซต์ ซึ่งทำให้รับมือกับการเปลี่ยนแปลงของเว็บไซต์ได้ลื่นกว่า สมมติว่าเว็บไซต์จัดเรียงบางส่วนใหม่เล็กน้อย AI web scraper ก็อาจปรับตัวได้โดยที่คุณไม่ต้องเขียนอะไรใหม่เลย ดังนั้นมันจึงเหมาะมากกับเว็บไซต์ที่ต้องดูแลบ่อย หรือเว็บไซต์ที่มีโครงสร้างซับซ้อน
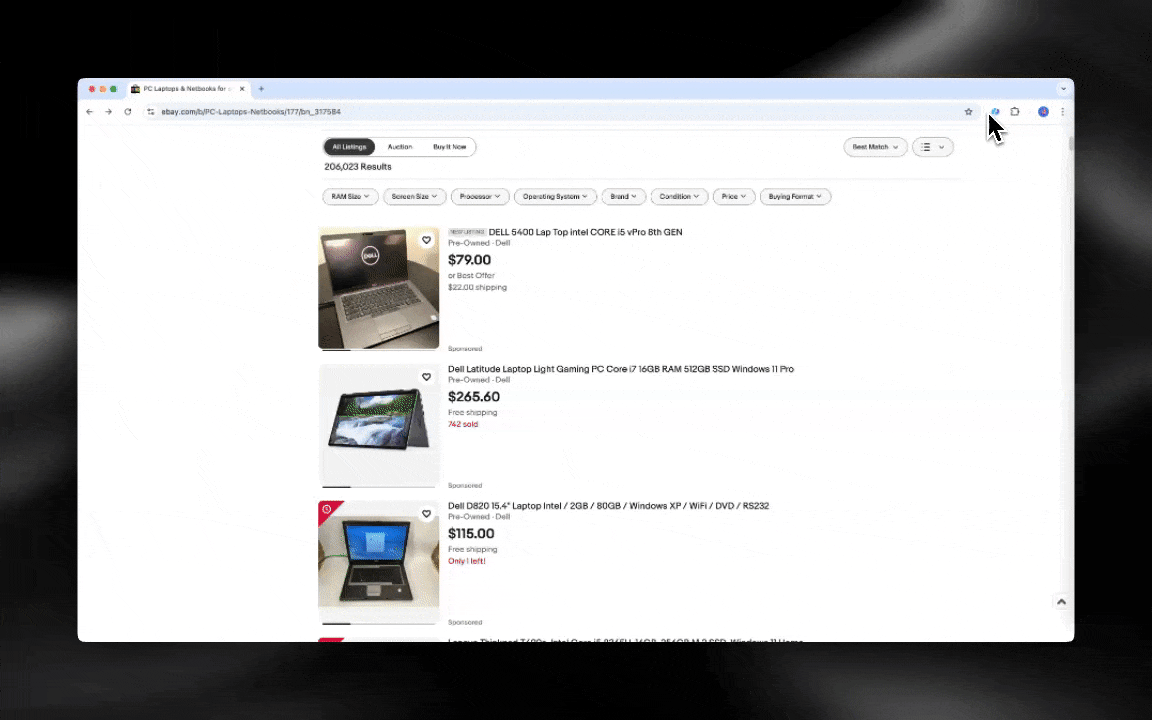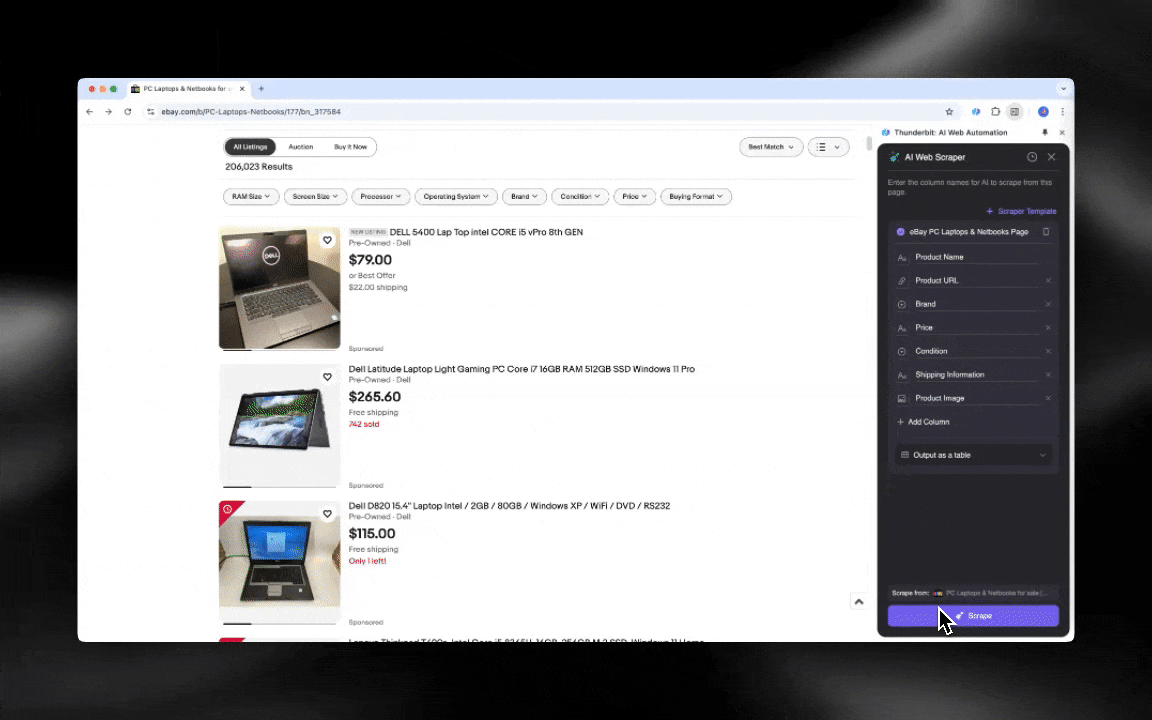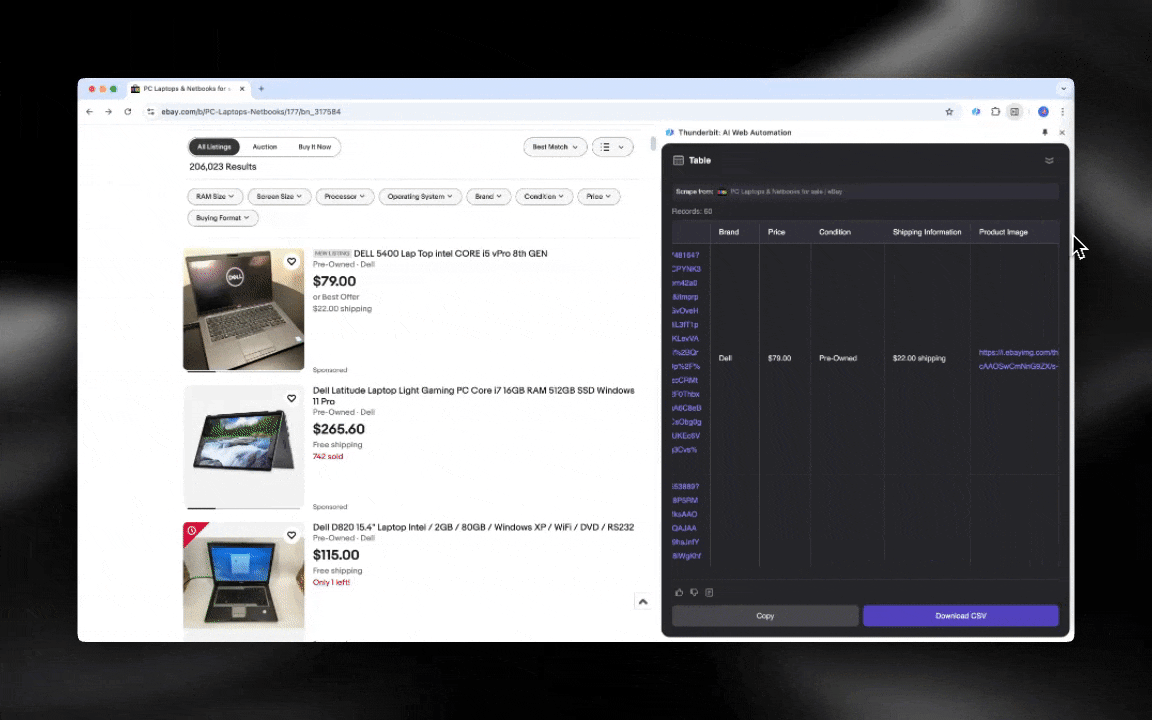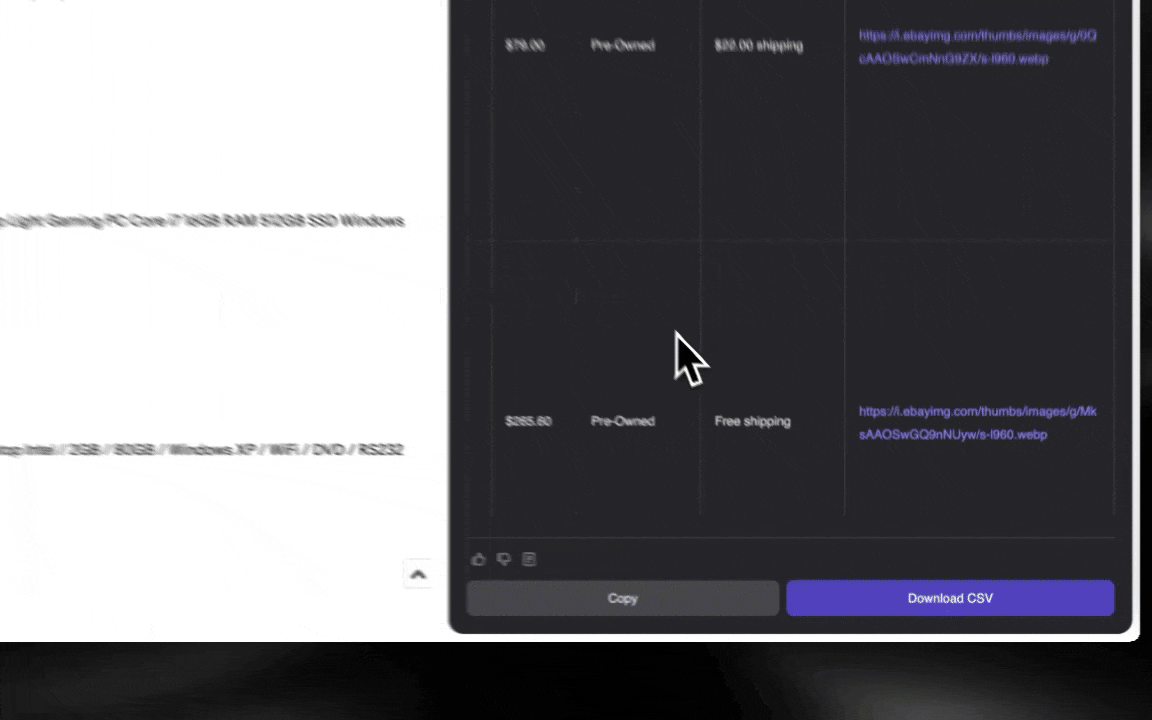 AI web scraper เริ่มต้นใช้งานง่าย และให้ข้อมูลละเอียดได้ในไม่กี่คลิก!
AI web scraper เริ่มต้นใช้งานง่าย และให้ข้อมูลละเอียดได้ในไม่กี่คลิก!
ควรเลือกแบบไหน? ขึ้นอยู่กับสถานการณ์ ถ้าคุณถนัดปรับแต่งโค้ดเอง หรือต้องเก็บข้อมูลจำนวนมากจากเว็บไซต์ยอดนิยม traditional scrapers อาจมีประสิทธิภาพมาก แต่ถ้าคุณเพิ่งเริ่มกับ web scraping หรืออยากได้เครื่องมือที่รับมือกับการอัปเดตของเว็บไซต์ได้ AI web scrapers มักจะเป็นตัวเลือกที่ดีกว่า ดูตารางด้านล่างเพื่อดูสถานการณ์ที่ละเอียดขึ้นได้เลย
| สถานการณ์ | ตัวเลือกที่ดีที่สุด |
|---|---|
| การดึงข้อมูลแบบเบา ๆ บนหน้าที่เป็นไดเรกทอรี เว็บไซต์ช้อปปิ้ง หรือเว็บไซต์ที่มีรายการข้อมูล | AI Web Scraper |
| หน้ามีข้อมูลน้อยกว่า 200 แถว และการสร้าง scraper ด้วย traditional web scraper ใช้เวลานานเกินไป | AI Web Scraper |
| ข้อมูลที่ต้องดึงมีรูปแบบเฉพาะเพื่ออัปโหลดไปยังที่อื่น เช่น ดึงข้อมูลติดต่อเพื่ออัปโหลดเข้า HubSpot | AI Web Scraper |
| เว็บไซต์ที่ใช้งานกันอย่างแพร่หลายและมีสเกลใหญ่ เช่น หน้าสินค้าบน Amazon หลายหมื่นหน้า หรือรายการอสังหาริมทรัพย์บน Zillow | Traditional Web Scraper |
ภาพรวมเครื่องมือและซอฟต์แวร์ดึงข้อมูลเว็บที่ดีที่สุด
| เครื่องมือ | ราคา | ฟีเจอร์เด่น | ข้อดี | ข้อเสีย |
|---|---|---|---|---|
| Thunderbit | เริ่มต้นที่ $9/เดือน มีแพ็กเกจใช้ฟรี | AI web scraper, ตรวจจับและจัดรูปแบบข้อมูลอัตโนมัติ, รองรับหลายรูปแบบ, ส่งออกได้ในคลิกเดียว, อินเทอร์เฟซใช้งานง่าย | ไม่ต้องเขียนโค้ด, รองรับ AI, เชื่อมต่อกับแอปอย่าง Google Sheets ได้ | การดึงข้อมูลขนาดใหญ่อาจช้า ฟีเจอร์ขั้นสูงอาจมีค่าใช้จ่ายเพิ่ม |
| Browse AI | เริ่มต้นที่ $48.75/เดือน มีแพ็กเกจใช้ฟรี | อินเทอร์เฟซแบบไม่ต้องเขียนโค้ด, ติดตามแบบเรียลไทม์, ดึงข้อมูลจำนวนมาก, เชื่อมต่อเวิร์กโฟลว์ | ใช้งานง่าย, เชื่อมต่อกับ Google Sheets และ Zapier ได้ | หน้าซับซ้อนต้องตั้งค่าเพิ่ม, ดึงข้อมูลจำนวนมากอาจทำให้หมดเวลา |
| Bardeen AI | เริ่มต้นที่ $60/เดือน มีแพ็กเกจใช้ฟรี | ระบบอัตโนมัติแบบไม่ต้องเขียนโค้ด, เชื่อมต่อได้มากกว่า 130 แอป, MagicBox แปลงงานเป็นเวิร์กโฟลว์ | การเชื่อมต่อหลากหลาย, ขยายการใช้งานได้ดีสำหรับธุรกิจ | ผู้ใช้ใหม่อาจต้องใช้เวลาเรียนรู้, ตั้งค่าเริ่มต้นใช้เวลาพอสมควร |
| Web Scraper | ใช้ในเครื่องฟรี, คลาวด์เริ่มต้นที่ $50/เดือน | สร้างงานแบบภาพ, รองรับเว็บไซต์ไดนามิก (AJAX/JavaScript), ดึงข้อมูลบนคลาวด์ | ทำงานได้ดีกับเว็บไซต์ไดนามิก | ต้องมีความรู้ทางเทคนิคเพื่อให้ตั้งค่าได้ดีที่สุด |
| Octoparse | เริ่มต้นที่ $119/เดือน มีแพ็กเกจใช้ฟรี | ดึงข้อมูลแบบไม่ต้องเขียนโค้ด, ตรวจจับองค์ประกอบหน้าอัตโนมัติ, ดึงข้อมูลบนคลาวด์พร้อมงานตามกำหนดเวลา, ไลบรารีเทมเพลตสำหรับเว็บไซต์ทั่วไป | ฟีเจอร์ทรงพลังสำหรับเว็บไซต์ไดนามิก, รับมือข้อจำกัดได้ดี | เว็บไซต์ที่ซับซ้อนต้องใช้เวลาเรียนรู้ |
| Diffbot | เริ่มต้นที่ $299/เดือน | API ดึงข้อมูล, API แบบไม่ต้องมีกฎ, NLP สำหรับข้อความที่ไม่มีโครงสร้าง, กราฟความรู้ขนาดใหญ่ | การดึงข้อมูลด้วย AI แข็งแกร่ง, เชื่อมต่อ API ได้หลากหลาย, รองรับการดึงข้อมูลขนาดใหญ่ | ผู้ใช้ที่ไม่ใช่สายเทคนิคต้องใช้เวลาเรียนรู้, ใช้เวลาตั้งค่า |
เครื่องมือดึงข้อมูลเว็บที่ดีที่สุดในยุค AI
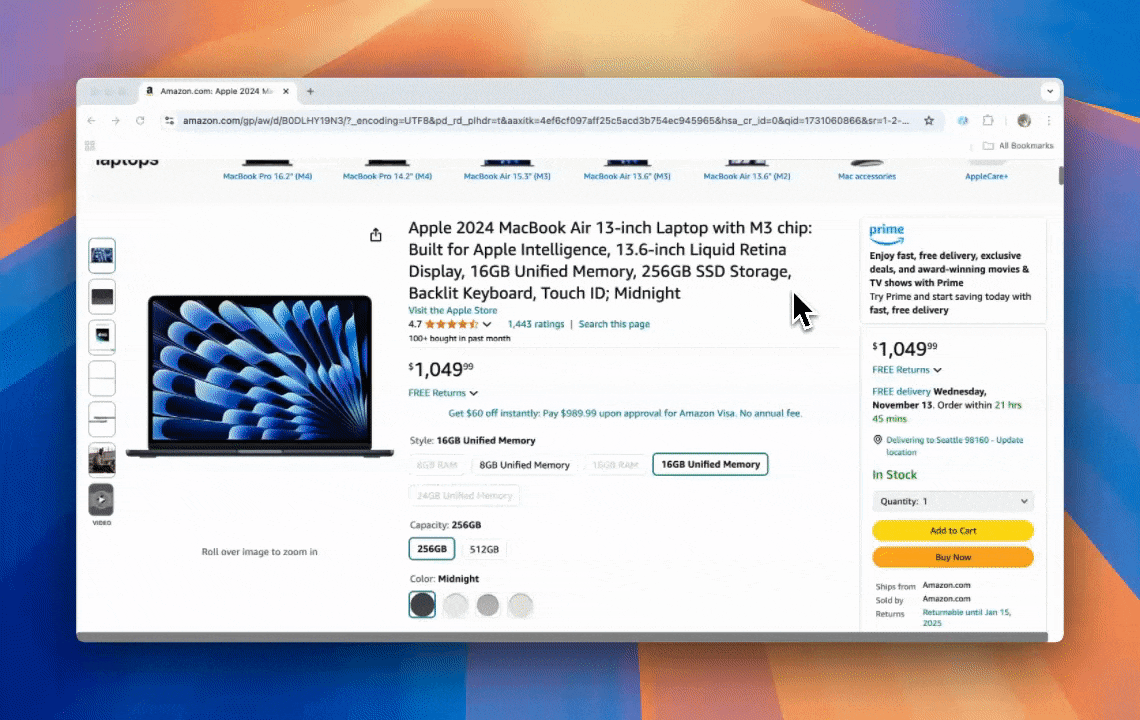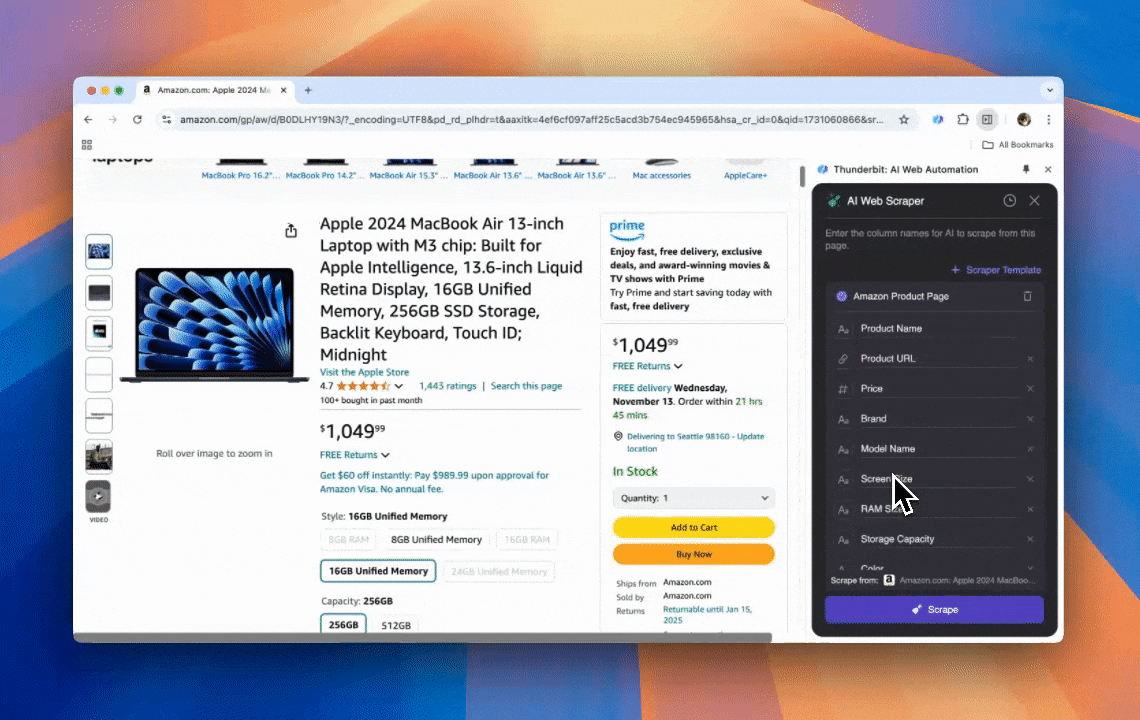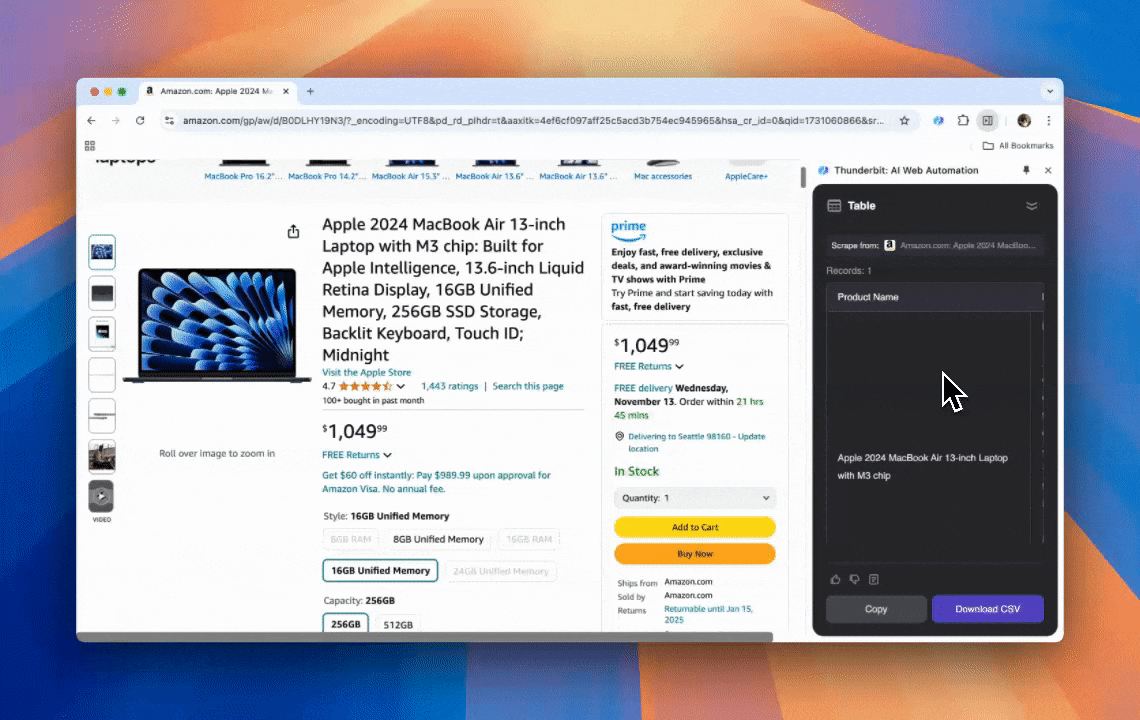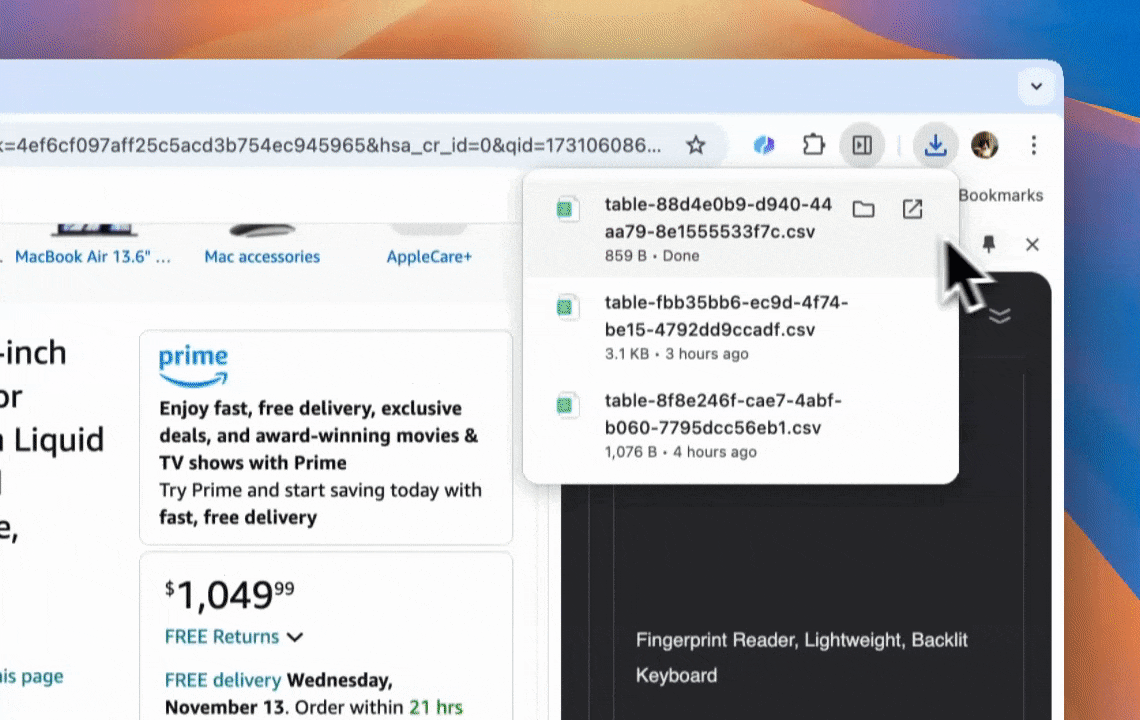
Thunderbit คือเครื่องมืออัตโนมัติบนเว็บด้วย AI ที่ทรงพลังและใช้งานง่าย ช่วยให้ผู้ใช้ที่ไม่ต้องเขียนโค้ดสามารถดึงและจัดระเบียบข้อมูลได้อย่างสะดวก ด้วย ของ Thunderbit ช่วยให้การดึงข้อมูลเป็นเรื่องง่าย—ผู้ใช้สามารถดึงข้อมูลจากเว็บได้อย่างรวดเร็วโดยไม่ต้องโต้ตอบกับองค์ประกอบของหน้าเว็บทีละจุด หรือสร้าง scraper แยกต่างหากสำหรับเลย์เอาต์แต่ละแบบ
ฟีเจอร์เด่น
- ความยืดหยุ่นที่ขับเคลื่อนด้วย AI: AI Web Scraper ของ Thunderbit ตรวจจับและจัดรูปแบบข้อมูลเว็บให้อัตโนมัติ จึงไม่จำเป็นต้องใช้ CSS selector
- ประสบการณ์การดึงข้อมูลที่ง่ายที่สุด: แค่คลิก “AI suggest column” แล้วกด “Scrape” บนหน้าที่ต้องการดึงข้อมูล แค่นั้นก็เสร็จ
- รองรับรูปแบบข้อมูลหลากหลาย: Thunderbit สามารถดึง URL, รูปภาพ และแสดงข้อมูลที่จับมาได้ในหลายรูปแบบ
- ประมวลผลข้อมูลอัตโนมัติ: AI ของ Thunderbit สามารถจัดรูปแบบข้อมูลระหว่างทางได้ รวมถึงสรุป จัดหมวดหมู่ และแปลให้อยู่ในรูปแบบที่ต้องการ
- ส่งออกข้อมูลได้ง่าย: ส่งออกไปยัง Google Sheets, Airtable หรือ Notion ได้ในคลิกเดียว ช่วยให้จัดการข้อมูลง่ายขึ้น
- อินเทอร์เฟซใช้งานง่าย: หน้าตาโปรแกรมที่เข้าใจง่าย ทำให้ผู้ใช้ทุกระดับใช้งานได้
ราคา
Thunderbit มีแพ็กเกจแบบแบ่งระดับ เริ่มต้นที่ $9 ต่อเดือนสำหรับ 5,000 credits และสูงสุดถึง $199 สำหรับ 240,000 credits นอกจากนี้ สำหรับแพ็กเกจรายปี คุณจะได้รับ credits ทั้งหมดล่วงหน้าเลย
ข้อดี:
- การรองรับ AI ที่แข็งแกร่งช่วยให้การดึงและประมวลผลข้อมูลง่ายขึ้น
- ไม่ต้องเขียนโค้ด เข้าถึงได้สำหรับผู้ใช้ทุกระดับ
- เหมาะมากกับการดึงข้อมูลแบบเบา ๆ เช่น ไดเรกทอรี เว็บไซต์ช้อปปิ้ง เป็นต้น
- เชื่อมต่อและส่งออกไปยังแอปยอดนิยมได้ดีมาก
ข้อเสีย:
- การดึงข้อมูลขนาดใหญ่อาจใช้เวลาพอสมควรเพื่อให้มั่นใจว่าข้อมูลแม่นยำ
- ฟีเจอร์ขั้นสูงบางอย่างอาจต้องสมัครแพ็กเกจแบบชำระเงิน
อยากได้ข้อมูลเพิ่มเติมไหม? เริ่มจาก หรือดู ด้วย Thunderbit
เครื่องมือดึงข้อมูลเว็บที่ดีที่สุดสำหรับการติดตามข้อมูลและการดึงข้อมูลจำนวนมาก
Browse AI
Browse AI คือเครื่องมือดึงข้อมูลแบบไม่ต้องเขียนโค้ดที่แข็งแรง ออกแบบมาเพื่อช่วยให้ผู้ใช้ดึงและติดตามข้อมูลได้โดยไม่ต้องเขียนโค้ดเลย Browse AI มีฟีเจอร์ AI บ้าง แต่ยังไม่ถึงระดับของการดึงข้อมูลด้วย AI แบบเต็มตัว ถึงอย่างนั้นก็ช่วยให้ผู้ใช้เริ่มต้นใช้งานได้ง่ายขึ้น
ฟีเจอร์เด่น
- อินเทอร์เฟซแบบไม่ต้องเขียนโค้ด: ช่วยให้ผู้ใช้สร้างเวิร์กโฟลว์แบบกำหนดเองได้ด้วยการคลิกง่าย ๆ
- การติดตามแบบเรียลไทม์: ใช้บอทติดตามการเปลี่ยนแปลงของหน้าเว็บและส่งข้อมูลที่อัปเดตให้
- การดึงข้อมูลจำนวนมาก: รองรับข้อมูลได้สูงสุดถึง 50,000 รายการในครั้งเดียว
- การเชื่อมต่อเวิร์กโฟลว์: เชื่อมบอทหลายตัวเข้าด้วยกันเพื่อประมวลผลข้อมูลที่ซับซ้อนขึ้น
ราคา
เริ่มต้นที่ $48.75 ต่อเดือน รวม 2,000 credits มีแพ็กเกจใช้ฟรีให้ทดลองฟีเจอร์พื้นฐานได้ 50 credits ต่อเดือน
ข้อดี:
- มีการเชื่อมต่อกับ Google Sheets และ Zapier
- บอทสำเร็จรูปช่วยให้งานดึงข้อมูลทั่วไปง่ายขึ้น
ข้อเสีย:
- หน้าซับซ้อนอาจต้องตั้งค่าเพิ่มเติม
- ความเร็วในการดึงข้อมูลจำนวนมากอาจไม่คงที่ และบางครั้งอาจทำให้หมดเวลา
เครื่องมือดึงข้อมูลเว็บที่ดีที่สุดสำหรับการเชื่อมต่อเวิร์กโฟลว์
Bardeen AI
Bardeen AI คือเครื่องมืออัตโนมัติแบบไม่ต้องเขียนโค้ดที่ออกแบบมาเพื่อทำให้เวิร์กโฟลว์ลื่นขึ้นด้วยการเชื่อมต่อแอปต่าง ๆ แม้จะใช้ AI ในการสร้างระบบอัตโนมัติแบบกำหนดเอง แต่ก็ยังขาดความยืดหยุ่นแบบเครื่องมือ AI Scraping เต็มรูปแบบ
ฟีเจอร์เด่น
- ระบบอัตโนมัติแบบไม่ต้องเขียนโค้ด: ให้ผู้ใช้ตั้งค่าเวิร์กโฟลว์ได้ด้วยการคลิก
- MagicBox: อธิบายงานเป็นภาษาธรรมดา แล้ว Bardeen AI จะแปลงเป็นเวิร์กโฟลว์ให้
- ตัวเลือกการเชื่อมต่อที่ครอบคลุม: เชื่อมต่อได้กับกว่า 130 แอป รวมถึง Google Sheets, Slack และ LinkedIn
ราคา
เริ่มต้นที่ $60 ต่อเดือน พร้อม 1,500 credits (ประมาณ 1,500 แถวข้อมูล) มีแพ็กเกจใช้ฟรีให้ 100 credits ต่อเดือนสำหรับลองใช้ฟีเจอร์พื้นฐาน
ข้อดี:
- ตัวเลือกการเชื่อมต่อที่หลากหลาย รองรับความต้องการทางธุรกิจได้หลายแบบ
- ยืดหยุ่นและขยายการใช้งานได้ดีสำหรับธุรกิจทุกขนาด
ข้อเสีย:
- ผู้ใช้ใหม่อาจต้องใช้เวลาเรียนรู้แพลตฟอร์มทั้งหมด
- การตั้งค่าเริ่มต้นอาจใช้เวลาพอสมควร
เครื่องมือดึงข้อมูลเว็บแบบภาพที่ดีที่สุดสำหรับคนที่มีประสบการณ์
Web Scraper
ใช่แล้ว ชื่อเครื่องมือนี้คือ "Web Scraper" จริง ๆ Web Scraper เป็นส่วนขยายเบราว์เซอร์ยอดนิยมสำหรับ Chrome และ Firefox ที่ช่วยให้ผู้ใช้ดึงข้อมูลโดยไม่ต้องเขียนโค้ด พร้อมวิธีสร้างงานดึงข้อมูลแบบเห็นภาพ อย่างไรก็ตาม คุณอาจต้องใช้เวลาหลายวันดูและเรียนรู้จากบทแนะนำด้านบนเพื่อใช้งานเครื่องมือนี้ให้คล่องจริง ๆ ถ้าคุณอยากให้การดึงข้อมูลง่ายกับสมองของคุณ เลือก AI Web Scraper ดีกว่า
ฟีเจอร์เด่น
- สร้างงานแบบเห็นภาพ: ให้ผู้ใช้ตั้งค่างานดึงข้อมูลโดยการคลิกองค์ประกอบบนหน้าเว็บ
- รองรับเว็บไซต์ไดนามิก: จัดการคำขอ AJAX และ JavaScript สำหรับเว็บไซต์ไดนามิกได้
- ดึงข้อมูลบนคลาวด์: ตั้งเวลางานผ่าน Web Scraper Cloud สำหรับการดึงข้อมูลเป็นรอบ ๆ
ราคา
ใช้งานในเครื่องได้ฟรี; แพ็กเกจแบบชำระเงินเริ่มต้นที่ $50/เดือนสำหรับฟีเจอร์คลาวด์
ข้อดี:
- ทำงานได้ดีกับเว็บไซต์ไดนามิก
- ใช้งานในเครื่องได้ฟรี
ข้อเสีย:
- ต้องมีความรู้ทางเทคนิคเพื่อให้ตั้งค่าได้เหมาะสมที่สุด
- ต้องทดสอบหลายขั้นตอนเมื่อมีการเปลี่ยนแปลง
เครื่องมือดึงข้อมูลเว็บที่ดีที่สุดเพื่อหลีกเลี่ยงการบล็อก IP และการตรวจจับบอท
Octoparse
Octoparse เป็นซอฟต์แวร์อเนกประสงค์สำหรับผู้ใช้ที่มีพื้นฐานเชิงเทคนิคมากขึ้น เพื่อเก็บและติดตามข้อมูลเว็บเฉพาะทางโดยไม่ต้องเขียนโค้ด เหมาะอย่างยิ่งสำหรับความต้องการข้อมูลขนาดใหญ่ Octoparse ไม่ได้อาศัยเบราว์เซอร์ของผู้ใช้ในการทำงาน แต่ใช้เซิร์ฟเวอร์คลาวด์ในการดึงข้อมูล ดังนั้นจึงมีหลายวิธีในการหลีกเลี่ยงการบล็อก IP และการตรวจจับบอทของบางเว็บไซต์
ฟีเจอร์เด่น
- การทำงานแบบไม่ต้องเขียนโค้ด: ผู้ใช้สามารถสร้างงานดึงข้อมูลได้โดยไม่ต้องเขียนโค้ด ทำให้เข้าถึงได้สำหรับผู้ใช้ที่มีทักษะทางเทคนิคต่างระดับกัน
- ตรวจจับอัตโนมัติอัจฉริยะ: ตรวจจับข้อมูลบนหน้าเว็บอัตโนมัติ ระบุองค์ประกอบที่ดึงได้อย่างรวดเร็ว ช่วยให้ตั้งค่าง่ายขึ้น
- ดึงข้อมูลบนคลาวด์: รองรับการดึงข้อมูลบนคลาวด์ตลอด 24/7 พร้อมงานดึงข้อมูลตามกำหนดเวลา เพื่อการดึงข้อมูลที่ยืดหยุ่น
- ไลบรารีเทมเพลตจำนวนมาก: มีเทมเพลตสำเร็จรูปหลายร้อยแบบ ให้ผู้ใช้เข้าถึงข้อมูลจากเว็บไซต์ยอดนิยมได้อย่างรวดเร็วโดยไม่ต้องตั้งค่าซับซ้อน
ราคา
แพ็กเกจของ Octoparse เริ่มต้นที่ $119 ต่อเดือน รวม 100 งาน นอกจากนี้ยังมีแพ็กเกจใช้ฟรีที่มี 10 งานต่อเดือนให้ทดลองความสามารถพื้นฐาน
ข้อดี:
- ฟีเจอร์ทรงพลัง รองรับการดึงข้อมูลจากเว็บไซต์ไดนามิกได้อย่างยืดหยุ่นสูง
- มีแนวทางสำหรับจัดการข้อจำกัดในการดึงข้อมูลและปัญหาเนื้อหาแบบไดนามิก
ข้อเสีย:
- โครงสร้างเว็บไซต์ที่ซับซ้อนอาจต้องใช้เวลาตั้งค่านานขึ้น
- ผู้ใช้ใหม่อาจต้องใช้เวลาเรียนรู้เทคนิคการใช้งาน
เครื่องมือดึงข้อมูลเว็บที่ดีที่สุดสำหรับ API ดึงข้อมูลด้วย AI ขั้นสูง
Diffbot
Diffbot เป็นเครื่องมือดึงข้อมูลเว็บขั้นสูงที่ใช้ AI เพื่อแปลงเนื้อหาเว็บที่ไม่มีโครงสร้างให้กลายเป็นข้อมูลที่มีโครงสร้าง ด้วย API อันทรงพลังและ knowledge graph Diffbot ช่วยให้ผู้ใช้ดึง วิเคราะห์ และจัดการข้อมูลจากเว็บได้ เหมาะสำหรับหลากหลายอุตสาหกรรมและการใช้งาน
ฟีเจอร์เด่น
- Data Extraction API: Diffbot มี API ดึงข้อมูลแบบไม่ต้องมีกฎ ให้ผู้ใช้เพียงส่ง URL เข้าไปก็สามารถดึงข้อมูลอัตโนมัติได้ ไม่ต้องตั้งกฎเฉพาะสำหรับแต่ละเว็บไซต์
- Natural Language Processing API: ดึงเอนทิตี ความสัมพันธ์ และอารมณ์ความรู้สึกจากข้อความที่ไม่มีโครงสร้าง ช่วยให้ผู้ใช้สร้าง knowledge graph ของตัวเองได้
- Knowledge Graph: Diffbot มี knowledge graph ขนาดใหญ่มากแห่งหนึ่ง เชื่อมโยงข้อมูลเอนทิตีจำนวนมาก รวมถึงรายละเอียดของบุคคลและองค์กร
ราคา
แพ็กเกจของ Diffbot เริ่มต้นที่ $299 ต่อเดือน รวม 250,000 credits (เทียบเท่าการดึงหน้าเว็บด้วย API ประมาณ 250,000 ครั้ง)
ข้อดี:
- ความสามารถดึงข้อมูลแบบไม่ต้องมีกฎแข็งแกร่งและปรับตัวได้ดี
- มีตัวเลือกการเชื่อมต่อ API มากมาย เชื่อมกับระบบที่มีอยู่ได้ง่าย
- รองรับการดึงข้อมูลขนาดใหญ่ เหมาะสำหรับการใช้งานระดับองค์กร
ข้อเสีย:
- การตั้งค่าเริ่มต้นอาจต้องใช้เวลาเรียนรู้สำหรับผู้ใช้ที่ไม่ใช่สายเทคนิค
- ผู้ใช้ต้องเขียนโปรแกรมเพื่อเรียกใช้งาน API
ใช้ scraper ทำอะไรได้บ้าง?
ถ้าคุณเพิ่งเริ่มกับ web scraping ต่อไปนี้คือกรณีใช้งานยอดนิยมบางส่วนที่จะช่วยให้เริ่มต้นได้ง่ายขึ้น หลายคนใช้ scraper เพื่อดึงรายการสินค้าบน Amazon, ดึงข้อมูลอสังหาริมทรัพย์จาก Zillow หรือรวบรวมรายละเอียดธุรกิจจาก Google Maps แต่ยังมีอีกมาก—คุณสามารถใช้ Thunderbit เพื่อเก็บข้อมูลจากแทบทุกเว็บไซต์ ช่วยให้งานต่าง ๆ ลื่นขึ้นและประหยัดเวลาในเวิร์กโฟลว์ประจำวันของคุณ ไม่ว่าจะเพื่อการวิจัย การติดตามราคา หรือการสร้างฐานข้อมูล การดึงข้อมูลเว็บเปิดโอกาสให้คุณใช้ประโยชน์จากข้อมูลบนอินเทอร์เน็ตได้หลากหลายมาก
คำถามที่พบบ่อย
-
การดึงข้อมูลเว็บผิดกฎหมายหรือไม่?
โดยทั่วไปการดึงข้อมูลเว็บไม่ผิดกฎหมาย แต่ต้องปฏิบัติตามเงื่อนไขการใช้งานของเว็บไซต์และลักษณะของข้อมูลที่เข้าถึง ควรตรวจสอบนโยบายที่เกี่ยวข้องและปฏิบัติตามแนวทางทางกฎหมายเสมอ
-
จำเป็นต้องมีทักษะการเขียนโปรแกรมเพื่อใช้เครื่องมือดึงข้อมูลเว็บไหม?
เครื่องมือส่วนใหญ่ที่แนะนำในบทความนี้ไม่จำเป็นต้องมีทักษะการเขียนโปรแกรม แต่เครื่องมืออย่าง Octoparse และ Web Scraper อาจได้ประโยชน์มากขึ้นหากผู้ใช้มีความรู้พื้นฐานเรื่องโครงสร้างเว็บและมีแนวคิดแบบโปรแกรมเมอร์เพื่อใช้งานได้ดีที่สุด
-
มีเครื่องมือดึงข้อมูลเว็บฟรีไหม?
มี เช่น BeautifulSoup, Scrapy และ Web Scraper รวมถึงบางเครื่องมือที่มีแพ็กเกจใช้ฟรีแบบจำกัดฟีเจอร์
-
ความท้าทายที่พบบ่อยในการดึงข้อมูลเว็บมีอะไรบ้าง?
ความท้าทายที่พบบ่อยได้แก่การจัดการเนื้อหาแบบไดนามิก, CAPTCHAs, การบล็อก IP และโครงสร้าง HTML ที่ซับซ้อน เครื่องมือและเทคนิคขั้นสูงสามารถรับมือกับปัญหาเหล่านี้ได้อย่างมีประสิทธิภาพ
เรียนรู้เพิ่มเติม:
-
ใช้ AI ทำงานแบบไม่ต้องออกแรง