สแครปเปอร์ Substack

ได้รับความไว้วางใจจากมืออาชีพในบริษัทชั้นนำ














ปลดล็อกข้อมูล Substack ด้วย Thunderbit
ส่งข้อมูล Substack ไปยังแอปของคุณโดยตรง
หยุดการคัดลอกและวางรายละเอียดสิ่งพิมพ์ Substack อย่างชื่อผู้เขียน ชื่อบทความ และจำนวนผู้ติดตามด้วยมือได้แล้ว ด้วย Thunderbit แค่คลิกเดียวก็ส่งข้อมูลที่ดึงออกไปยัง Google Sheets, Notion หรือ Airtable ได้โดยตรง วิเคราะห์แนวโน้มของสิ่งพิมพ์และประสิทธิภาพของเนื้อหาได้โดยไม่ต้องเสียเวลาทำงานซ้ำ ๆ ด้วยตนเอง
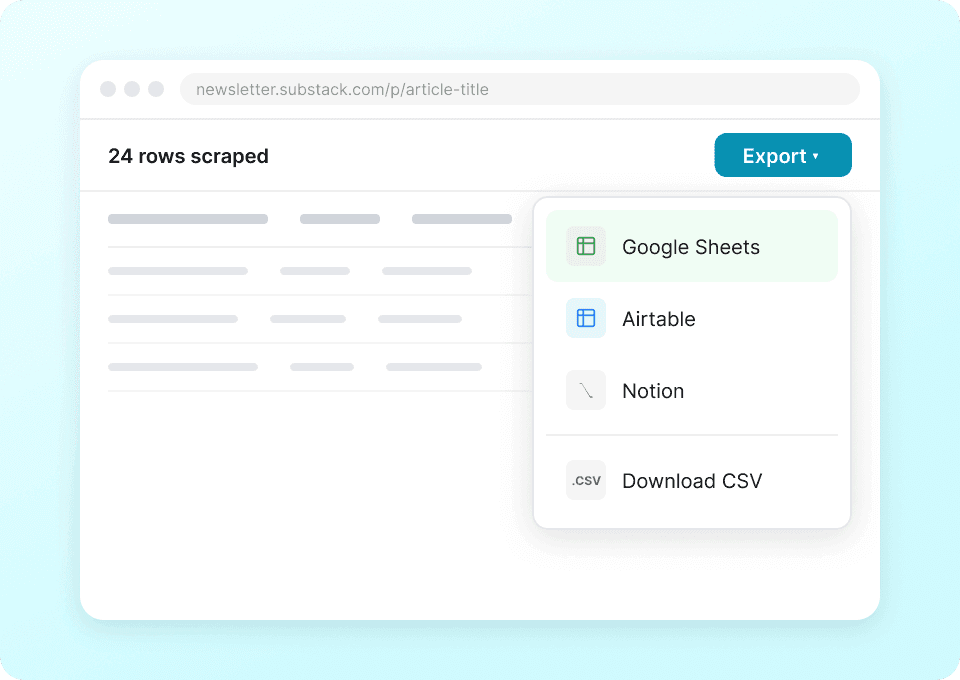
เห็นภาพ Substack แบบครบถ้วน
หน้ารายการสิ่งพิมพ์ของ Substack แสดงเพียงสรุป Thunderbit จะเข้าไปยังหน้าบทความย่อยแต่ละหน้าโดยอัตโนมัติเพื่อดึงเนื้อหาเต็ม ทำให้คุณได้ชุดข้อมูลที่ครบถ้วน เก็บชื่อบทความ ชื่อผู้เขียน ชื่อสิ่งพิมพ์ และเนื้อหาบทความได้ในครั้งเดียว
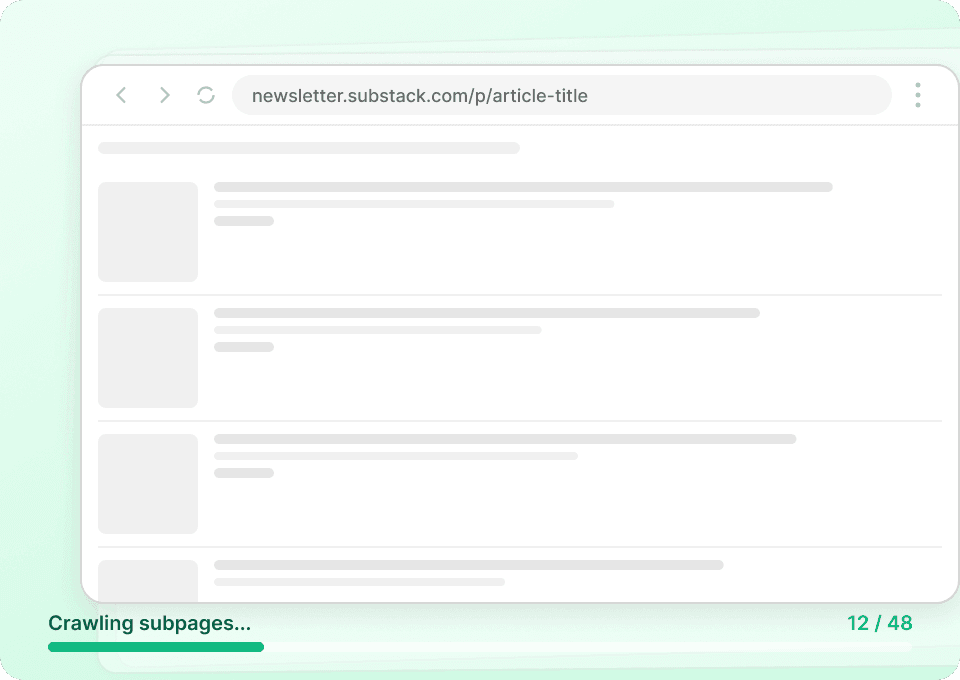
กำลังดึงข้อมูล Substack ให้ได้ผลอยู่ใช่ไหม?
ดูว่าทำไม Thunderbit ถึงเหนือกว่าสแครปเปอร์แบบดั้งเดิมสำหรับข้อมูล Substack
สแครปเปอร์แบบดั้งเดิม
วิธีแบบเดิมThunderbit
แนวทางที่ชาญฉลาดกว่าไม่ต้องเชื่อเราอย่างเดียว
ดูว่าผู้ใช้ของเราพูดถึง Thunderbit ว่าอย่างไร







คำถามที่พบบ่อย
เกี่ยวข้อง การใช้งาน
สำรวจการใช้งาน Thunderbit web scraper เพิ่มเติม

Craigslist Phone Number Scraper
Craigslist Phone Number Scraper ของ Thunderbit ช่วยดึงเบอร์โทรและรายละเอียดประกาศจากผลการค้นหาใน Craigslist ด้วย AI โดยสามารถเก็บข้อมูลจากหน้ารวมรายการ แล้วให้ระบบเข้าไปเปิดแต่ละโพสต์เพื่อดึงข้อมูลติดต่อและฟิลด์เพิ่มเติม จากนั้นส่งออกไปยัง Excel, Google Sheets, Airtable, Notion, CSV หรือ JSON ได้ทันที
ดูเพิ่มเติม ->
PlayStation Scraper
ปลดล็อกข้อมูลเกม PlayStation เช่น ชื่อเกม ประเภทเกม และราคาที่ลดแล้วได้ในไม่กี่คลิก ไม่ต้องคัดลอกวางเองให้เสียเวลาอีกต่อไป
ดูเพิ่มเติม ->
เครื่องมือดึงข้อมูล Priceline
ใช้ Thunderbit AI ดึงชื่อโรงแรม ราคา และคะแนนรีวิวจาก Priceline ได้ในไม่กี่คลิก
ดูเพิ่มเติม ->
United Airlines Scraper
คลิกเพียงไม่กี่ครั้งเพื่อดึงข้อมูลเที่ยวบินของ United Airlines เช่น เลขเที่ยวบิน เวลาเดินทางถึง และสนามบินต้นทาง — ที่เหลือให้ Thunderbit AI จัดการให้หมด
ดูเพิ่มเติม ->
เครื่องมือดึงข้อมูล Trivago
ดึงชื่อโรงแรม ราคา และคะแนนจาก Trivago ได้ในไม่กี่คลิก — ไม่ต้องเขียนโค้ดหรือตั้งค่าใด ๆ
ดูเพิ่มเติม ->
Sports Direct Scraper
ดึงชื่อสินค้า ราคา และเปอร์เซ็นต์ส่วนลดจาก Sports Direct ด้วย AI ของ Thunderbit — ไม่ต้องตั้งค่าให้ยุ่งยากและไม่ต้องเขียนโค้ด
ดูเพิ่มเติม ->พร้อมยกระดับการดึงข้อมูลของคุณแล้วหรือยัง?
เข้าร่วมกับมืออาชีพกว่า 100,000 คนที่ใช้ Thunderbit เพื่อทำเวิร์กโฟลว์เว็บสแครปปิ้งอัตโนมัติ
ทดลองใช้ฟรีพร้อมเครดิตไม่จำกัดสำหรับ 8 เว็บเพจ