Pixiv Scraper
Trusted by professionals at leading companies














Pixiv data scraping made simple
Extract pixiv data like headlines, authors, and section details without manual copy-paste.
Bulk scrape Pixiv data at scale
Manually collecting pixiv data page by page gets slow fast, especially when you need dozens or hundreds of headlines, article summaries, authors, publication dates, news sources, and sections. Thunderbit lets you scrape a list of URLs in one go, so you can move from a few pages to a large set of pixiv records without wasting time on repetitive work.

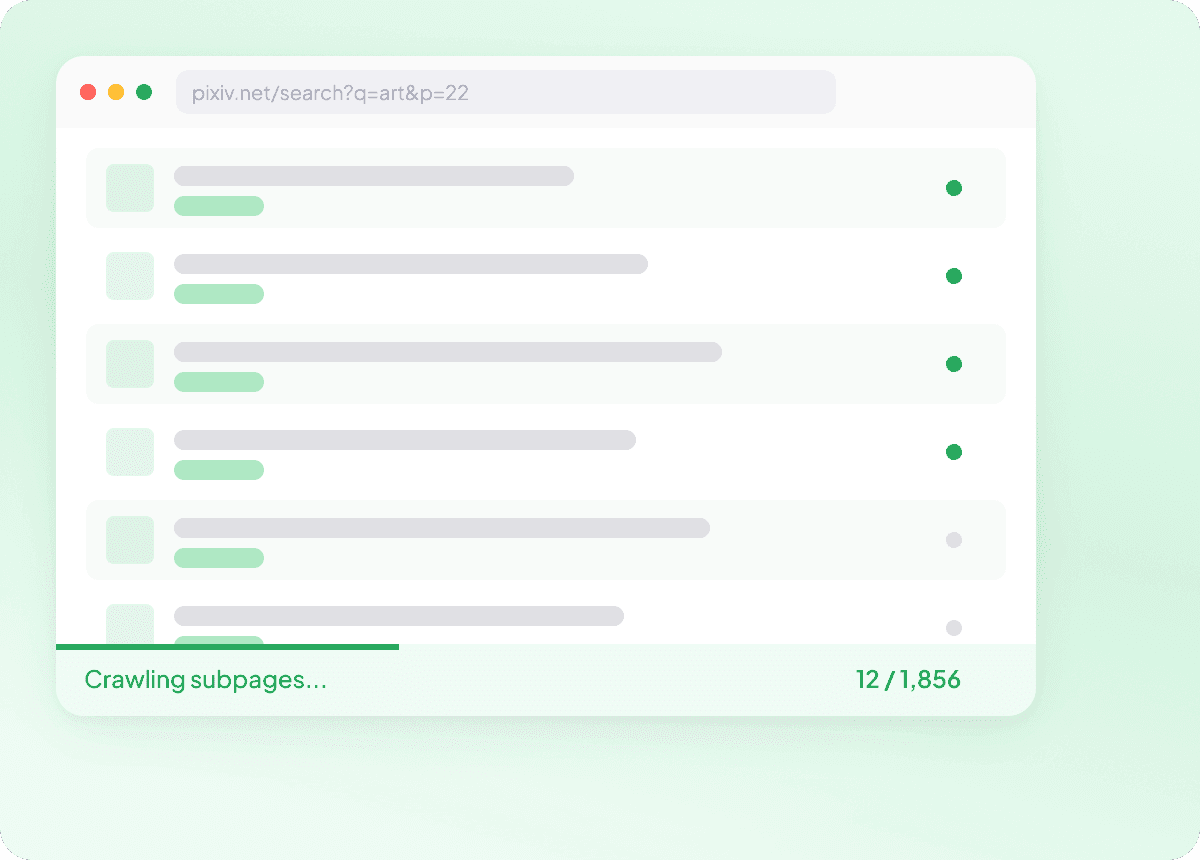
Capture full Pixiv subpage details
Listing pages on pixiv often only show the basics, while the real details live inside each article or post subpage. Thunderbit visits every linked subpage and pulls back the full picture, giving you richer data like the article summary, author, publication date, news source, and section in a clean structure.
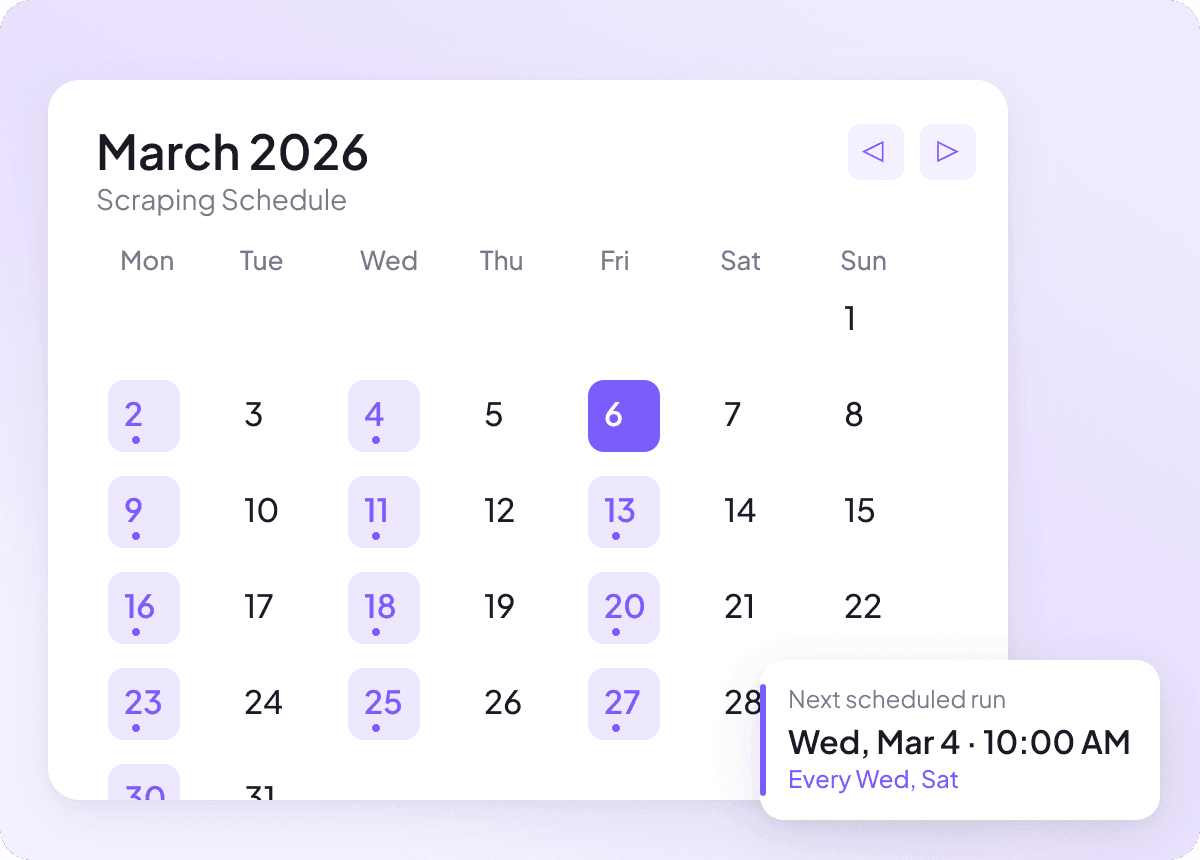
Keep Pixiv data fresh on autopilot
Pixiv content can change daily, and keeping up manually means checking the same pages over and over. With scheduled scraping, Thunderbit runs on autopilot and delivers fresh pixiv data to your spreadsheet on a recurring basis, so your headline, author, and section tracking stays current without lifting a finger.
Why is Thunderbit different from traditional pixiv scrapers?
A simpler way to scrape Pixiv without brittle selectors or cleanup.
Traditional scrapers
The old way of doing thingsThunderbit AI
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.






Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

Herold Scraper
The Thunderbit Herold Scraper lets you extract data from Herold's business and people search results in just 2 clicks. Use AI-powered field suggestions to gather business names, addresses, phone numbers, emails, and more for lead generation, research, or marketing. Ideal for sales teams, marketers, and researchers seeking structured Herold data.
Learn more ->
ReverseAustralia Scraper
The Thunderbit ReverseAustralia Scraper lets you extract data from ReverseAustralia complaint and comment pages. Use AI-powered field suggestions to quickly gather phone numbers, complaint descriptions, comment texts, user names, and more for analysis or research. Ideal for marketers, researchers, and businesses seeking structured feedback data.
Learn more ->
Tieba Scraper
The Thunderbit Tieba Scraper enables you to extract data from Baidu Tieba, including trending topics and forum categories. Use AI-powered field suggestions to quickly gather topic names, URLs, post counts, and user activity for research, marketing, or content creation. Ideal for analyzing social media trends and discussions on Tieba.
Learn more ->
TripAdvisor Business Listings Scraper
The Thunderbit TripAdvisor Business Listings Scraper lets you extract data from TripAdvisor's business listings, resource hub, and owners forum. Use AI-powered field suggestions to quickly gather resource names, URLs, descriptions, forum topics, authors, and post content for research, marketing, or analysis.
Learn more ->
White Pages Scraper
The Thunderbit White Pages Scraper lets you extract data from White Pages phone and business listings with AI-powered field suggestions. Gather names, phone numbers, addresses, and website URLs for lead generation, marketing, or research in just a few clicks.
Learn more ->On the Beach Scraper
The Thunderbit On the Beach Scraper lets you extract holiday and hotel listings, prices, ratings, and more from On the Beach in just two clicks. Use AI-powered field suggestions to quickly collect and organize travel data for analysis, comparison, or planning. Ideal for travel professionals, analysts, and vacation planners.
Learn more ->Ready to supercharge your data extraction?
Join 100,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.