IDCrawl Scraper
Trusted by professionals at leading companies














Idcrawl data that stays usable
Use idcrawl to extract data faster, cleaner, and at scale with Thunderbit.
Adapts when Idcrawl changes
Scrapers that break after every site update are useless, especially when you’re trying to pull full name, job title, company name, email address, phone number, and linkedin profile from idcrawl. Thunderbit reads the page by meaning, not by fixed selectors, so it can adapt when the layout shifts. You spend less time fixing scrapers and more time getting the data you need.
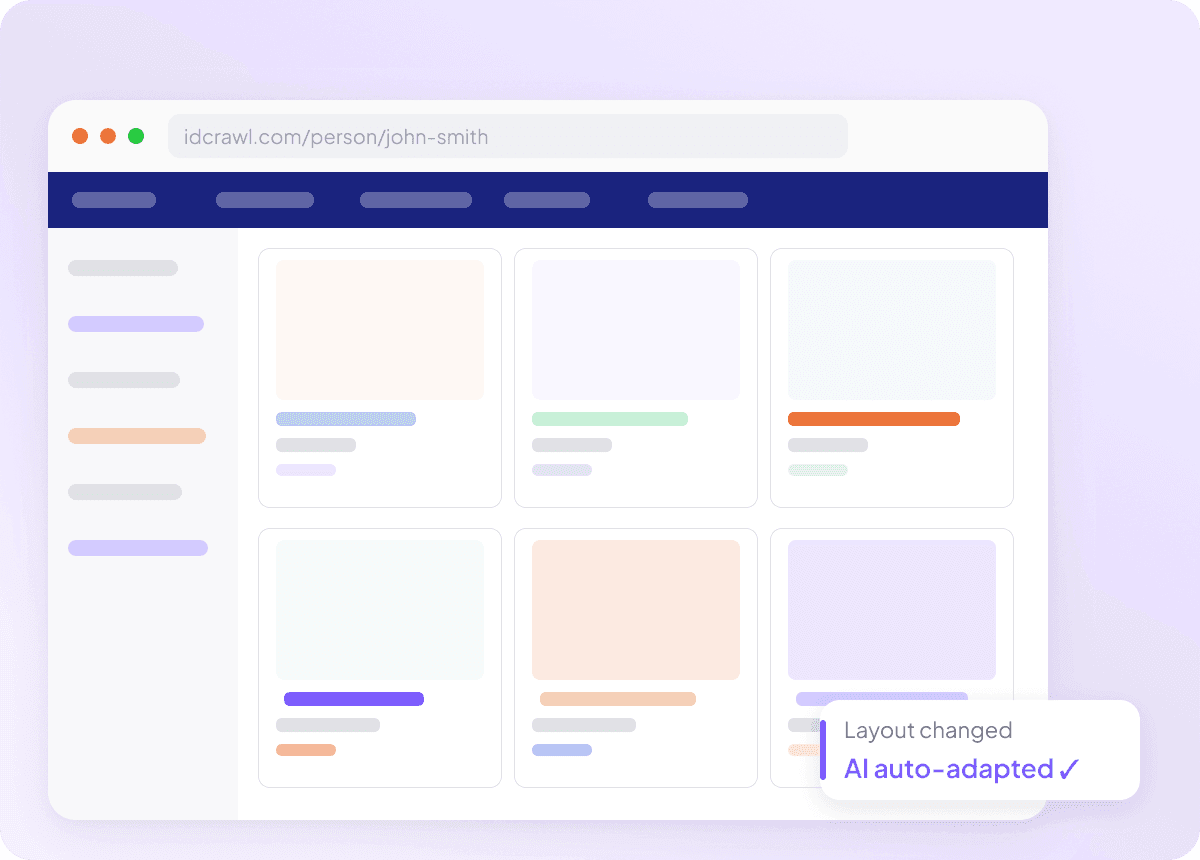
Clean data from the start
Raw data is just the start of the real work, and idcrawl results often need cleanup before they’re useful. Thunderbit structures and formats the data during extraction, so what you export is already clean and ready to use. That means less sorting, less rework, and a smoother handoff to your team.
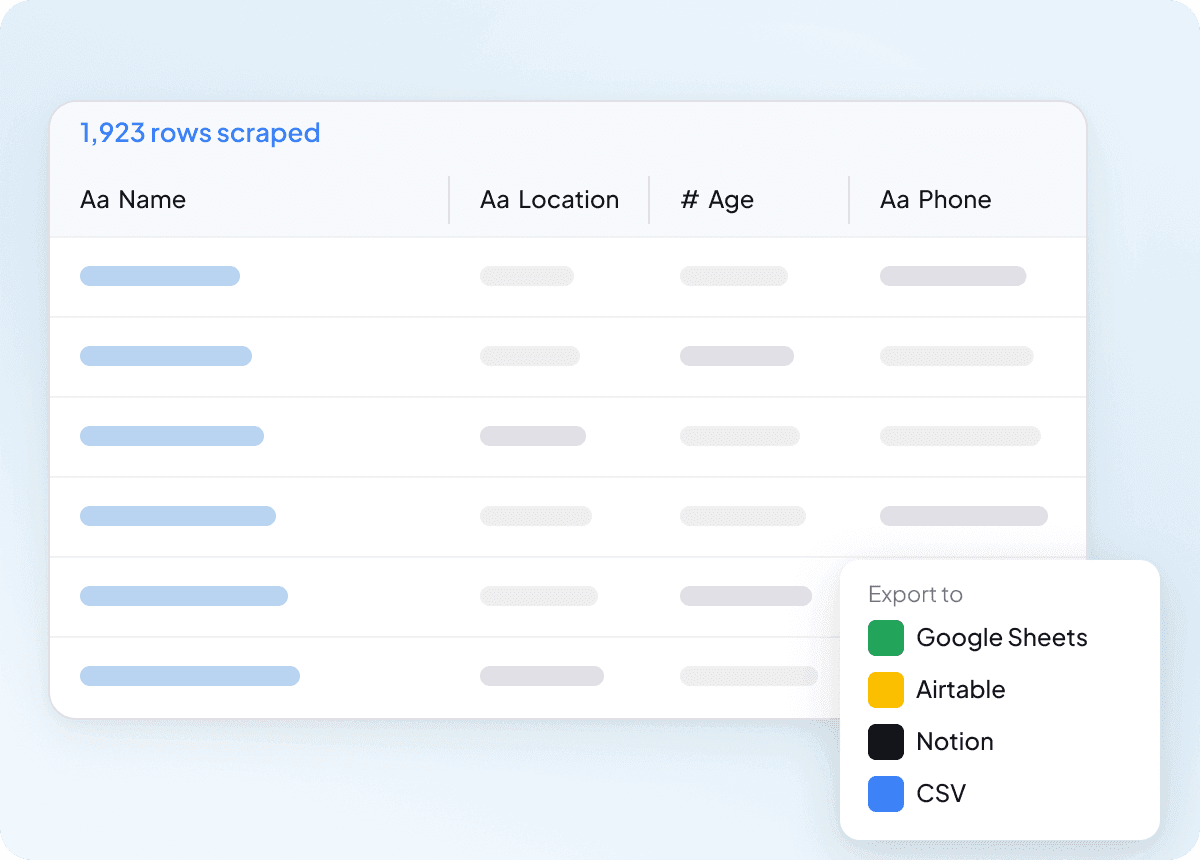
Bulk scrape Idcrawl in one go
Scraping one idcrawl page at a time doesn’t scale when you need a long list of contacts. Thunderbit can bulk-scrape hundreds of pages in one go, so you can feed it a list of URLs and extract full name, job title, company name, email address, phone number, and linkedin profile across them all. It’s a much easier way to turn a big list into usable data.

Why is Thunderbit different from traditional idcrawl scrapers?
A simpler way to extract idcrawl data without constant fixes.
Traditional scrapers
The old way of doing thingsThunderbit AI
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.






Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

UNIQLO Scraper
Harvest Uniqlo product data like names, prices, and available sizes with just 2 clicks, thanks to Thunderbit's Chrome extension.
Learn more ->
Amarillas.com Scraper
The Thunderbit Amarillas.com Scraper lets you extract structured data from Amarillas.com, including motels and restaurant listings. Use AI-powered field suggestions to quickly gather business names, locations, contact numbers, ratings, and reviews for research, marketing, or lead generation.
Learn more ->
Rakuten Travel Scraper
The Thunderbit Rakuten Travel Scraper lets you extract data from Rakuten Travel hotel listings and details pages. Use AI-powered field suggestions to quickly gather hotel names, prices, ratings, room types, and amenities for research or travel planning. Ideal for travel agents, researchers, and businesses seeking structured travel data.
Learn more ->Tradera Scraper
The Thunderbit Tradera Scraper lets you extract data from Tradera listings and product pages with ease. Use AI-powered field suggestions to gather product names, prices, categories, images, and descriptions for analysis or inventory management. Ideal for e-commerce sellers, collectors, and researchers seeking structured Tradera data.
Learn more ->
UpCity Scraper
The Thunderbit UpCity Scraper lets you extract data from UpCity's advertising agency listings and provider reviews. Use AI-powered field suggestions to quickly gather agency names, locations, ratings, contact info, and detailed review content for analysis or research. Ideal for marketers, researchers, and business owners seeking structured UpCity data.
Learn more ->
United Airlines scraper
Point and click to collect United Airlines flight data like flight number, arrival time, and departure airport — Thunderbit AI handles the rest.
Learn more ->Ready to supercharge your data extraction?
Join 100,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.