Goodreads scraper
Trusted by professionals at leading companies














Extract Goodreads data in seconds, not hours
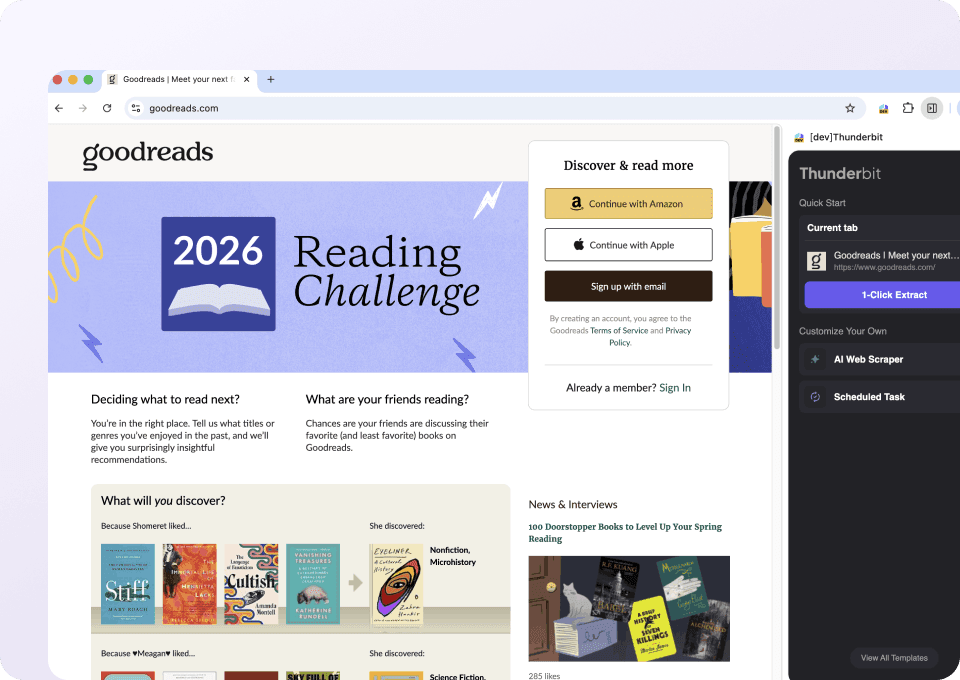
Two clicks to scrape Goodreads data
Tired of manually copying book titles, author names, ratings, and page counts from Goodreads? Thunderbit lets you extract data in just two clicks. No coding or complicated setup needed. Simply point at the data you want, and our AI automatically detects the fields and extracts them.
Clean Goodreads data, ready to use
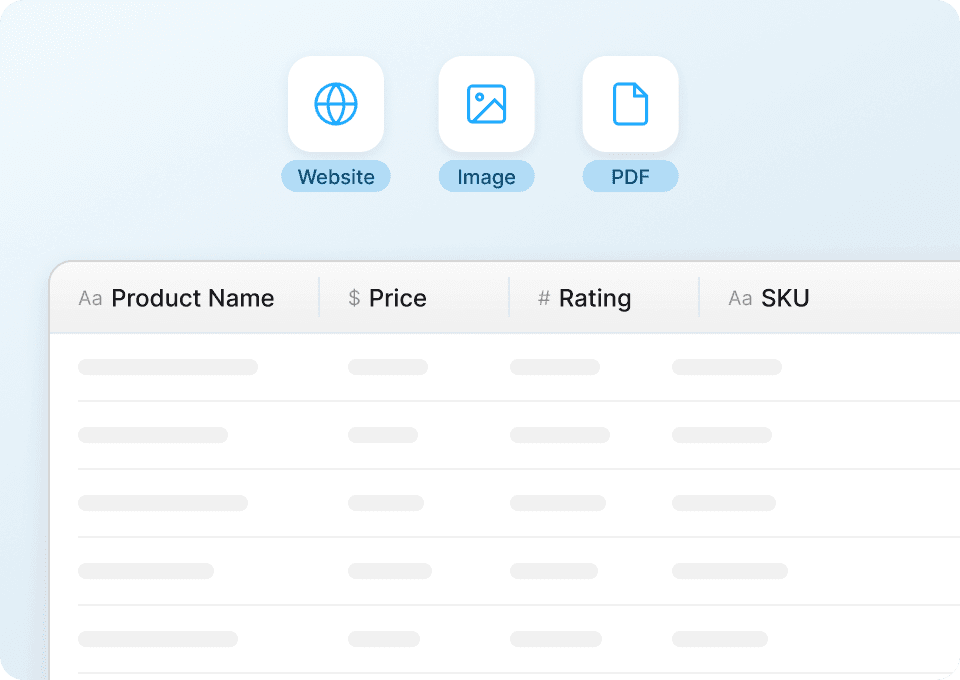
Goodreads data can be messy. Thunderbit automatically cleans and structures the data as it extracts it. Imagine getting a perfectly formatted Google Sheet with book titles, authors, average rating, review count, and number of pages, all ready for your analysis – no more manual cleanup.
Scrape hundreds of Goodreads pages
Manually scraping Goodreads, one page at a time, is tedious and time-consuming. Thunderbit can automatically scrape hundreds of Goodreads pages at once. Just give it a list of URLs and it will extract book data, authors, or any other info you need, quickly and efficiently.

Goodreads scraping got you down?
See how Thunderbit simplifies data extraction from Goodreads.
Traditional scrapers
The old way of doing thingsThunderbit
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.





Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.
PeopleWhiz scraper
The Thunderbit PeopleWhiz Scraper lets you extract data from PeopleWhiz search results and profiles with AI-powered field suggestions. Gather names, contact details, locations, and more for research, marketing, or lead generation. Transform PeopleWhiz data into structured datasets quickly and efficiently.
Learn more ->Substack scraper
Get Substack subscriber counts, article titles, and publication descriptions into a clean spreadsheet — no code, the AI does the structuring.
Learn more ->
Amarillas.com Scraper
The Thunderbit Amarillas.com Scraper lets you extract structured data from Amarillas.com, including motels and restaurant listings. Use AI-powered field suggestions to quickly gather business names, locations, contact numbers, ratings, and reviews for research, marketing, or lead generation.
Learn more ->
iBegin Scraper
The Thunderbit iBegin Scraper lets you extract business search results and detailed business information from the iBegin website. Use AI-powered field suggestions to quickly gather business names, contact details, addresses, ratings, and more for lead generation, research, or marketing analysis.
Learn more ->
TripAdvisor Business Listings Scraper
The Thunderbit TripAdvisor Business Listings Scraper lets you extract data from TripAdvisor's business listings, resource hub, and owners forum. Use AI-powered field suggestions to quickly gather resource names, URLs, descriptions, forum topics, authors, and post content for research, marketing, or analysis.
Learn more ->
People-Search Scraper
The Thunderbit People-Search Scraper lets you extract structured data from People-Search profiles and reverse phone lookup pages. Use AI-powered field suggestions to quickly gather names, locations, phone numbers, emails, and more for research, marketing, or lead generation. Ideal for marketers, researchers, and businesses seeking public records and contact details.
Learn more ->Ready to supercharge your data extraction?
Join 100,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.