
Jag ska avslöja en liten hemlighet: webben är i praktiken världens största bibliotek – men många av böckerna är typ fastklistrade. Varje dag snackar jag med företagare, marknadsförare och säljteam som vet att det finns guld i webbsidorna – produktspecifikationer, konkurrentpriser, kundrecensioner, kontaktuppgifter – men att få ut själva texten? Det är där det ofta tar stopp. Jag har jobbat i SaaS- och automationsvärlden i åratal och sett allt från “copy‑paste-maraton” till “gör‑det‑själv‑Python‑äventyr”. Den goda nyheten: att extrahera text från webbplats är enklare (och mycket mindre plågsamt) än någonsin, tack vare nya ai web scraper-verktyg och smartare webbläsartillägg.
I den här guiden går jag igenom alla praktiska metoder jag känner till – från klassisk kopiera/klistra in till mer avancerade AI-drivna lösningar som Thunderbit (ja, det är vårt verktyg, men jag är transparent med både för- och nackdelar). Oavsett om du är ett kalkylbladsproffs, en utvecklare som gillar att koda, eller bara less på att kisa på webbsidor, hittar du en steg-för-steg-metod som passar. Nu öppnar vi de digitala böckerna och plockar ut texten du behöver.
Vad innebär det att extrahera text från en webbplats?
När vi pratar om att “extrahera text från en webbplats” menar vi egentligen att plocka ut informationen du ser (och ibland inte ser) på en webbsida och få den i ett format du faktiskt kan jobba med – som ett kalkylark, en databas eller ett rent Word-dokument. Men all webbplatstext är inte samma typ av innehåll:
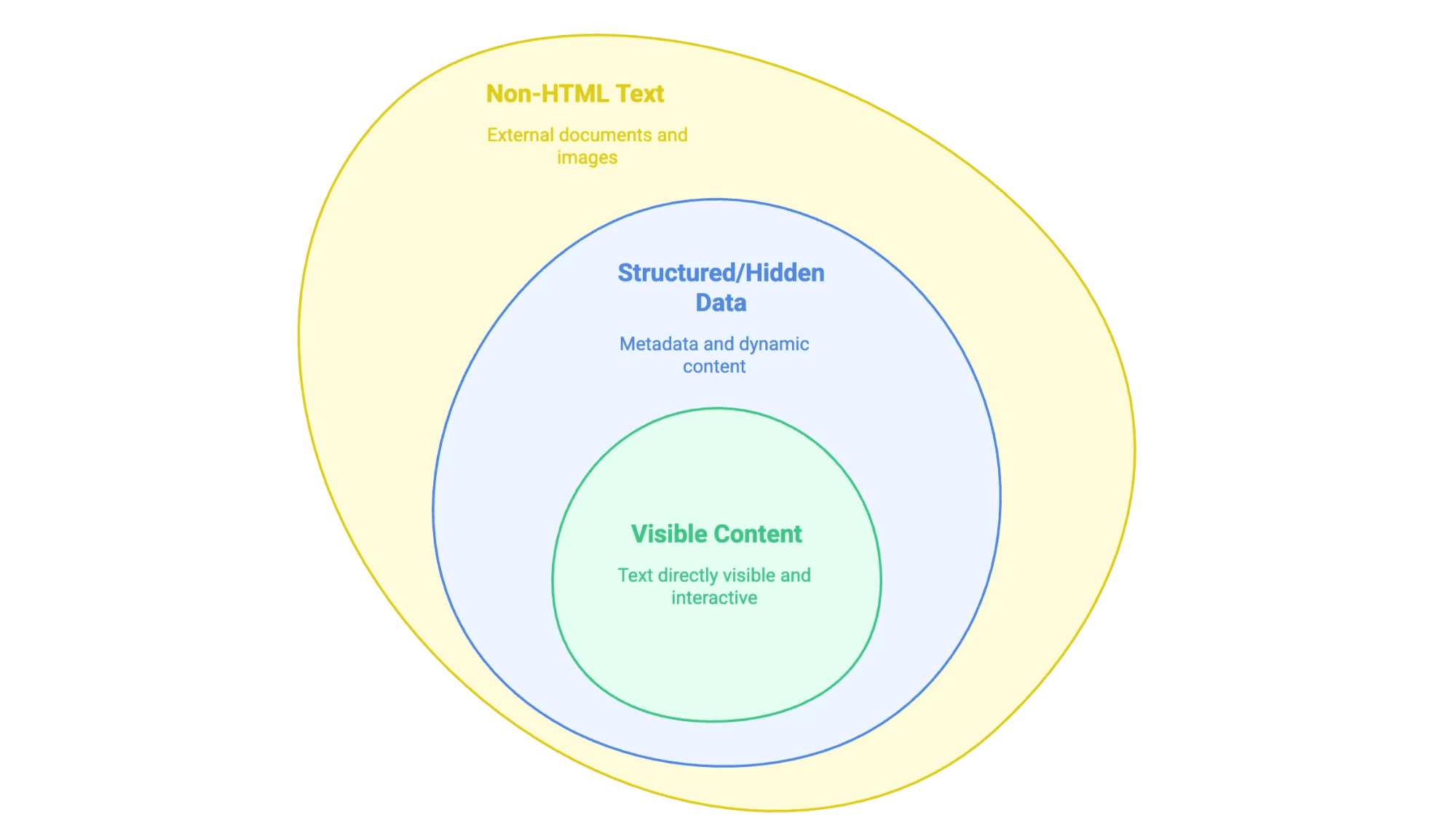
- Synligt innehåll: Det du kan markera med musen – brödtext, rubriker, listor, tabeller, produktbeskrivningar, blogginlägg osv.
- Strukturerad eller dold data: Till exempel metadata i
<meta>-taggar, JSON-LD-skript eller information som laddas via JavaScript och inte syns förrän du klickar eller scrollar. - Icke-HTML-text: PDF:er, Word-dokument och även bilder med text (som inskannade avtal eller infografik) som är länkade eller inbäddade på webbplatsen.
Nyckeln är att veta vilken typ du är ute efter – eftersom varje typ kräver sin egen metod.
Varför extrahera text från en webbplats? Affärsnytta och användningsområden
Om vi ska vara ärliga: ingen extraherar text från webbplatser “bara för att” (om du inte har väldigt udda hobbies). Företag gör det för att avkastningen är glasklar. Marknaden för web scraping-programvara passerade 1 miljard dollar 2024 och fortsätter växa. Här är varför:
| Team | Exempel på användning | Nytta |
|---|---|---|
| Sälj | Skrapa kataloger för leads och kontaktuppgifter | Snabbare och mer träffsäker prospektering |
| Marknad | Extrahera konkurrenters blogginlägg och SEO-data | Hitta innehållsgap, upptäcka trender |
| Drift/Operations | Bevaka produktpriser på e-handelssajter | Dynamisk prissättning, lagerbevakning |
| Fastigheter | Samla annonser och objektsdetaljer | Marknadsanalys, leadsgenerering |
| Support | Samla kundrecensioner och forumfrågor/svar | Sentimentanalys, tidig upptäckt av problem |
Några konkreta exempel:

- Leadsgenerering: Ett företag inom restaurangutrustning byggde prospektlistor på minuter i stället för dagar.
- Konkurrentbevakning: Återförsäljare som John Lewis ökade försäljningen med 4 % med hjälp av skrapad prisdata.
- SEO-analys: Team extraherar meta-taggar och nyckelord för att styra strategin.
Med AI-drivna verktyg sparar företag dessutom 30–40 % av tiden för datainsamling jämfört med traditionella metoder.
Manuella metoder: grunderna i att kopiera och klistra in webbplatstext
Vi börjar basic. Ibland behöver du bara fånga en kort textbit – utan verktyg och utan krångel.
Så extraherar du text manuellt
- Kopiera och klistra in: Öppna sidan, markera texten och tryck Ctrl+C (eller högerklicka > Kopiera). Klistra sedan in i dokumentet eller kalkylarket.
- Spara sidan som: I webbläsaren: Arkiv > Spara sida som. Spara som “Webbsida, endast HTML” för att få rå HTML, eller ibland som .txt för enbart text.
- Skriv ut till PDF: Använd webbläsarens utskriftsdialog och välj “Spara som PDF”. Öppna sedan PDF:en och kopiera texten (eller använd PDF-läsarens funktion för att spara som text).
- Utvecklarverktyg: Högerklicka > Inspektera eller tryck F12 för att öppna DevTools. Där kan du se HTML-källan, hitta meta-taggar eller dold JSON och kopiera det du behöver.
Begränsningar
Manuell extrahering funkar för enstaka behov, men blir snabbt ohållbart i större skala. Det är tidskrävande, lätt att göra fel och går inte att skala. Jag har sett praktikanter lägga dagar på att kopiera tabeller rad för rad – ingen vill ha det jobbet.
Använd webbläsartillägg och onlinetjänster för att extrahera text från webbplatser
Vill du ta nästa steg? Webbläsartillägg och onlinetjänster är ofta den bästa sweet spoten för de flesta: ingen kod, inget drama – bara peka och klicka.
Varför använda sådana verktyg?

- Snabbare än manuell kopiera/klistra in
- Ingen programmering krävs
- Klarar tabeller, listor och ibland även filer
- Export till Excel, Google Sheets, CSV m.m.
Här är de vanligaste alternativen.
Thunderbit: AI Web Scraper för snabb och korrekt textextrahering
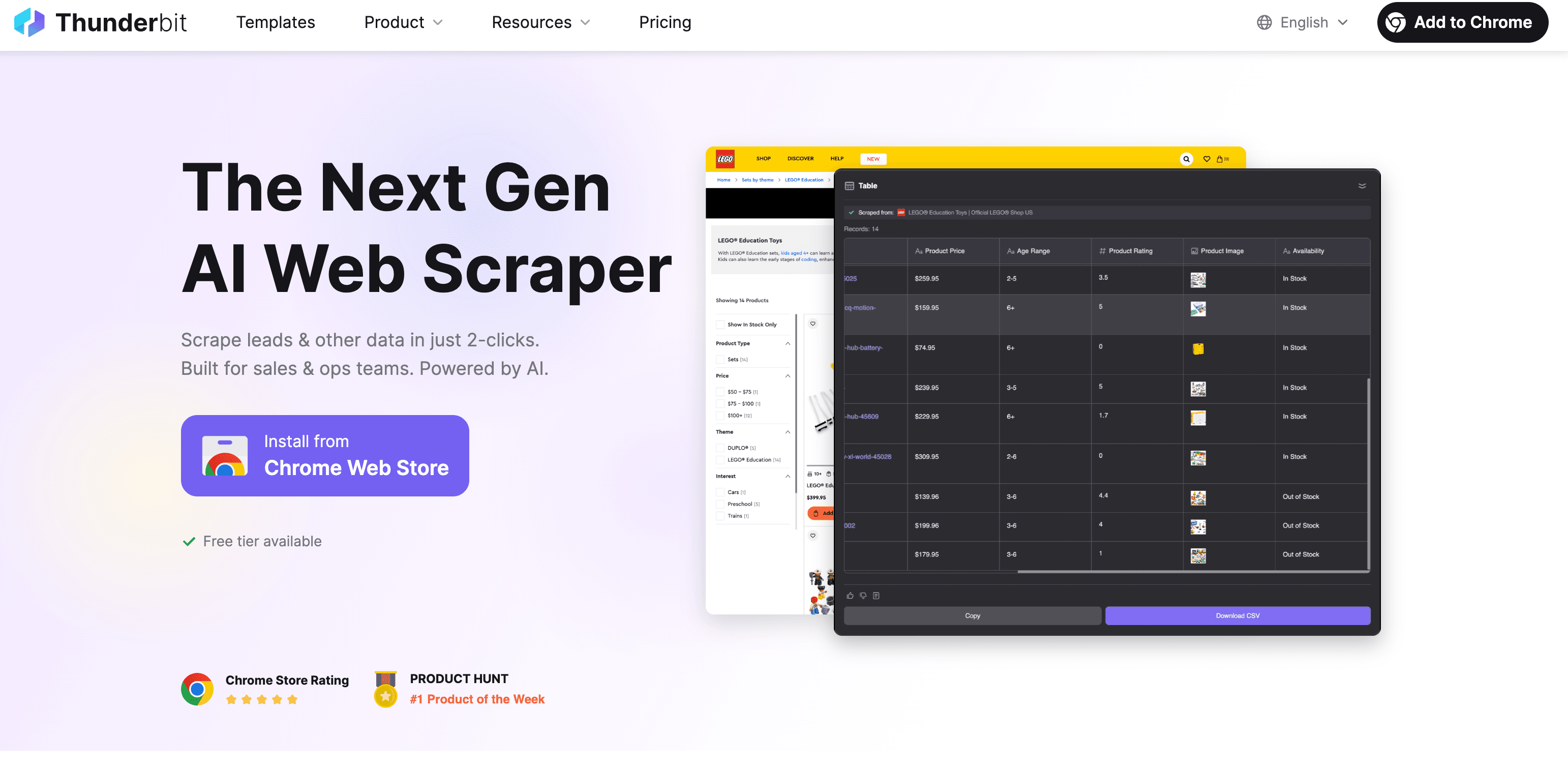
Okej, jag är lite partisk – men Thunderbit är faktiskt byggt för att göra textextrahering från webben lika enkelt som att beställa hämtmat. Så här funkar det:
Steg för steg: extrahera text med Thunderbit
- Installera Chrome-tillägget: Ladda ner Thunderbit från Chrome Web Store.
- Öppna webbplatsen: Gå till sidan du vill extrahera text från.
- Klicka på “AI Suggest Fields”: Thunderbits AI skannar sidan och föreslår vilka fält (kolumner) som är relevanta – t.ex. produktnamn, pris, beskrivning osv.
- Granska och justera: Finjustera förslagen eller lägg till egna fält.
- Klicka på “Scrape”: Thunderbit hämtar datan – även från undersidor eller paginerade listor vid behov.
- Exportera: Ladda ner till Excel, Google Sheets, Airtable, Notion eller som CSV/JSON. Ingen extra kostnad för export.
Extrahera webbplatstext med Thunderbit
Vad gör Thunderbit annorlunda?
- AI-drivna fältförslag: Du slipper selectors och kod – AI:n listar det som är viktigast på sidan.
- Hanterar undersidor och paginering: Behöver du detaljer från varje produktsida i en kategori? Thunderbit kan klicka sig igenom automatiskt.
- Extraherar från PDF:er, bilder och dokument: Har du en PDF-manual eller en bild med produktspec? Thunderbits inbyggda OCR kan plocka ut texten även där.
- Stöd för flera språk: Fungerar på 34 språk (jag väntar fortfarande på klingonska, men vi jobbar på det).
- Gratis dataexport: Ingen betalvägg för att få ut din data.
- Användningsområden: Produktbeskrivningar, kontaktuppgifter, blogginnehåll, leadlistor – you name it.
Så skrapar du Amazon-produkter och recensioner 2025 med AI Get Started Free
Vill du se det i praktiken? Kika in på vår Thunderbit Blog för guider som How to Scrape Amazon Products and Reviews in 2025 using AI.
Andra webbläsartillägg och onlinetjänster
Här är några andra verktyg du sannolikt kommer springa på:
- Web Scraper (webscraper.io): Gratis och klickbaserat, men kräver lite inkörning. Bra för tekniskt lagda analytiker, men du behöver sätta upp “sitemaps” och selectors. Klarar paginering, men inte PDF:er eller bilder. Mer info här.
- CopyTables: Superenkelt – kopierar HTML-tabeller till urklipp eller Excel. Perfekt för snabba engångsjobb, men funkar bara sida för sida och endast för tabeller. Se hur det funkar.
- ScraperAPI (ScraperAPI Pricing): För utvecklare. Du skickar en URL och får tillbaka HTML (hanterar proxies, blockeringar osv.), men du måste fortfarande själv parsa och extrahera texten. Läs mer.
När ska du använda vilket verktyg?
- Thunderbit: När du vill ha fart, AI-hjälp och stöd för flera format (inkl. PDF/bilder).
- Web Scraper: När du gillar att pilla och vill ha mer kontroll.
- CopyTables: När du bara behöver en tabell – snabbt.
- ScraperAPI: När du bygger din egen scraper i kod.
Automatiserad web scraping: programmeringslösningar för att extrahera webbplatstext
Om du är utvecklare (eller har en till hands) ger en egen scraper maximal kontroll. Grundflödet ser ut så här:
- Skicka HTTP-förfrågan: Använd Pythons
requestseller liknande för att hämta sidan. - Parsa HTML: Använd
BeautifulSoup,lxmlellerScrapyför att hitta texten du vill åt. - Extrahera och exportera: Plocka ut texten, städa den och spara som CSV, JSON eller i en databas.
Exempel: Python + Beautiful Soup
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
for qt in quotes:
print(qt)
För- och nackdelar
- Fördelar: Maximal flexibilitet, kan hantera i princip vilken webbplats eller datatyp som helst, lätt att integrera i egna system.
- Nackdelar: Kräver programmeringskunskap, löpande underhåll och hantering av anti-bot-skydd.
När passar det här bäst?
- Du behöver skrapa tusentals (eller miljontals) sidor.
- Webbplatsen är komplex (inloggning, flerstegsformulär).
- Du vill bygga in skrapningen direkt i din app eller process.
Extrahera text från icke-HTML-format: PDF:er, Word-dokument och bilder
Webbplatser består inte bara av HTML – de är fulla av PDF:er, Word-dokument och bilder med värdefull text. Så här kommer du åt den:
PDF:er
- Textbaserade PDF:er: Använd verktyg som Adobe Acrobat eller bibliotek som
PDFMinerellerPyPDF2för att extrahera text. - Skannade PDF:er: Använd OCR (Optical Character Recognition) som Tesseract, Google Cloud Vision API eller AWS Textract.
Word/Excel-dokument
- Word: Använd
python-docxför att läsa .docx-filer. - Excel: Använd
openpyxlellerpandasför .xlsx-filer.
Bilder
- OCR-verktyg: Tesseract som open source, eller molntjänster för högre precision. Bäst resultat får du med bra bildkvalitet (150–300 DPI).
Thunderbits sätt
Med “Image/Document Parser” kan du ladda upp eller länka till en PDF, bild eller ett dokument, och AI:n extraherar texten (och kan till och med föreslå kolumner om den hittar en tabell). Du slipper hoppa mellan flera verktyg – behandla filer som vilken webbsida som helst.
Jämförelse av metoder: vilken lösning passar dig?
Här är en snabb jämförelse för att göra valet enklare:
| Metod | Enkelhet | Skalbarhet | Teknisk nivå | Datatyper som stöds | Passar bäst för |
|---|---|---|---|---|---|
| Manuell (kopiera/klistra in) | Mycket enkel | Låg | Ingen | Endast synlig text | Engångsjobb, små uppgifter |
| Webbläsartillägg/verktyg | Enkel–medel | Medel | Låg–medel | HTML, vissa tabeller | Icke-tekniska användare, små–medelstora jobb |
| AI-verktyg (Thunderbit) | Mycket enkel | Hög | Ingen | HTML, PDF:er, bilder, mer | Affärsanvändare, blandat innehåll |
| Programmering (kod) | Svår | Mycket hög | Hög | Allt (med rätt bibliotek) | Utvecklare, storskaliga projekt |
| Icke-HTML-extrahering (OCR) | Medel | Låg–medel | Medel | PDF:er, bilder, dokument | När filer/bilder är centrala |
Vill du ha snabbast möjliga väg med hög flexibilitet och minimalt krångel – särskilt i affärssammanhang – är AI-verktyg som Thunderbit svåra att slå. Men om du behöver total kontroll eller skrapar i enorm skala kan egen kod vara rätt.
Viktigaste slutsatserna: börja extrahera text från webbplatser idag
- Webben är full av värdefull textdata, men den är inte alltid helt lätt att komma åt.
- Manuella metoder fungerar för små uppgifter, men skalar dåligt.
- Webbläsartillägg och AI Web Scraper-verktyg som Thunderbit gör textextrahering snabb, korrekt och tillgänglig för alla – utan kod.
- För icke-HTML-innehåll (PDF:er, bilder) bör du välja verktyg med inbyggd OCR och dokumenttolkning.
- Välj metod utifrån teamets kompetens, projektets storlek och vilka datatyper du behöver.
Testa Thunderbit AI Web Scraper gratis
Lycka till med skrapandet – och må dina Ctrl+C-dagar bli få. Med rätt verktyg kan webbdatasamling bli en smidig, automatiserad process som frigör tid till mer värdeskapande arbete. Inga fler oändliga timmar av kopiera och klistra in – bara smarta, effektiva lösningar nära till hands. Dags att lämna det manuella slitjobbet och kliva in i en mer produktiv framtid.
Vanliga frågor
Q1: Kan jag skrapa data från vilken webbplats som helst?
A1: Inte alltid. Vissa webbplatser blockerar scrapers eller har användarvillkor som förbjuder skrapning. Kontrollera alltid webbplatsens policy först.
Q2: Hur träffsäkra är AI-drivna web scrapers?
A2: AI-drivna scrapers som Thunderbit är mycket träffsäkra, men kan behöva justeras för komplexa eller mycket dynamiska sidor.
Q3: Behöver jag kunna koda för att använda web scraping-verktyg?
A3: Nej. Verktyg som Thunderbit och andra webbläsartillägg är byggda för icke-tekniska användare och kräver inga kodkunskaper.
Q4: Vilken typ av data kan jag extrahera från PDF:er eller bilder?
A4: OCR-verktyg kan extrahera text, tabeller och även dold information från skannade PDF:er och bilder, vilket gör datainsamlingen mer flexibel.
Läs mer
- The definitive guide to text scraping
- How to Scrape Any Website Using AI
- Learn How to Use AI for Web Scraping
Testa AI Web Scraper Get Started Free




