

För tre veckor sedan satte jag mig ner för att undersöka säljare av ”personalized pet portrait” på Etsy. Fyrtiosju webbläsarflikar, två timmars copy-paste och ett mycket rörigt kalkylblad senare hade jag fortfarande ingen tydlig bild av prissättning, recensioner eller vem som körde annonser jämfört med vem som rankade organiskt. Den upplevelsen satte igång hela det här projektet.
Etsy har nu över 100 miljoner varor till försäljning, 5,6 miljoner aktiva säljare och 86,5 miljoner aktiva köpare. Det är en enorm och stökig marknadsplats — och om du är säljare, marknadsförare eller e-handelsspanare som försöker förstå vad som fungerar i din nisch behöver du strukturerad data, inte en vägg av öppna flikar. Problemet? Etsys anti-bot-försvar har blivit riktigt sofistikerat år 2026. Med dynamiska sidstrukturer, TLS-fingerprinting, CAPTCHAs och beteendeanalys är tiden då man kunde skriva ett snabbt Python-skript och vara klar i princip över.
De senaste veckorna har jag testat sex Etsy-skrapare sida vid sida — från no-code AI-verktyg till utvecklar-API:er — och jag ska gå igenom exakt vad som fungerade, vad som inte gjorde det och vilket verktyg som passar vilken typ av användare. Jag går också igenom vilken data du faktiskt kan extrahera (och vad du inte kan), debatten om Etsy API kontra skrapning, verkliga användningsfall och hur du verifierar dina resultat så att du inte fattar beslut på dålig data.
Varför det är svårare att skrapa Etsy än du tror
Om du någonsin har försökt skrapa Etsy och kört fast är du långt ifrån ensam. Etsy är inte en statisk katalog — det är en dynamisk, personaliserad marknadsplats. Sökresultat, annonser, märken, fraktinformation och till och med sidans CSS-klassnamn kan ändras mellan sessioner, enheter och länder.
Här är den korta versionen av vad som gör Etsy knepigt:
- Dynamisk sidstruktur: Etsys frontend ändras ofta. Selektorer som fungerade igår kanske ger tomma resultat idag. Det är som att Etsy byter lås på sina dörrar varannan timme — sidan ser fortfarande bekant ut för en besökare, men de datakrokar som en skrapare är beroende av kan ändras utan förvarning.
- Bot-hanteringssystem: Skrapleverantörer som Apify påpekar öppet att Etsy använder ”aggressive anti-bot protection” och att sessioner kan blockeras. Vissa Actorsidor nämner URL-mönster för att undvika DataDome och imitation av Chrome TLS-fingeravtryck. Mer generellt visade Impervas 2026 Bad Bot Report att automatiserad trafik stod för 53 % av all webbtrafik år 2025, och Akamai rapporterade att bottar utgjorde 42,1 % av all webbtrafik — e-handelssajter är ett primärt mål.
- CAPTCHAs och hastighetsbegränsning: Skrapning i hög volym kan trigga CAPTCHA eller direkta blockeringar. Octoparses Etsy-mall noterar till och med att om en CAPTCHA dyker upp kan användaren pausa uppgiften och lösa den manuellt.
- Sponsrade resultat och personalisering: Etsys sökresultat blandar organiska och betalda listningar, och Etsy säger att annonser visas i särskilda annonsytor i sökresultaten. Om du inte håller koll på vilka resultat som är annonser kan din konkurrensanalys bli rejält missvisande.
Inget av detta betyder att det är omöjligt att skrapa Etsy. Det betyder att verktyget du väljer spelar mycket större roll än förr.

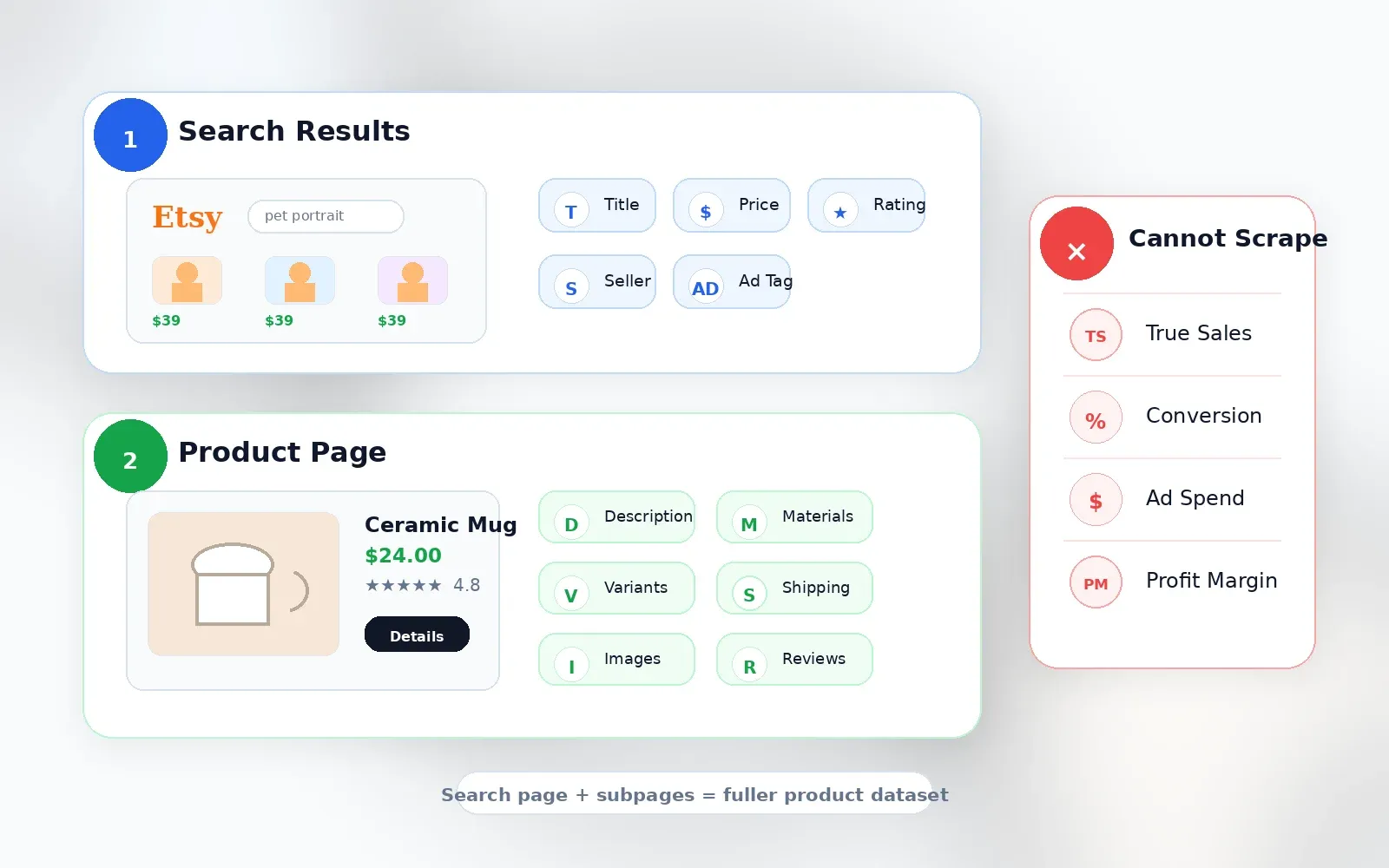
Vilken data kan du faktiskt skrapa från Etsy?
Det här är avsnittet jag önskar att varje konkurrentartikel tog med — men nästan ingen gör det. Innan du väljer verktyg behöver du veta vad som faktiskt är möjligt.
Data du kan få från Etsys sökresultat
Sökresultatsidor ger dig bredd. Här är vad du vanligtvis kan extrahera från rutnätet:
- Produktnamn
- Pris (aktuellt, på rea, ursprungligt när det syns)
- Valuta
- URL till huvudbild
- Listing-URL / listing-ID
- Butiksnamn (när det syns — annonser visar ibland ”Ad by Etsy Seller”)
- Betyg
- Antal recensioner
- Fri frakt-märke
- Märken för bästsäljare / Etsy's Pick / Star Seller
- Sponsor-/annonsmärkning
- Sidnummer och position
- Metadata för sökfras, filter, sortering och land/session
Apifys Automation Lab Etsy-Actor exponerar till exempel fält som listingId, name, url, imageUrl, shop, shopId, price, originalPrice, currency, onSale, freeShipping, rating, availability, position, query, page och scrapedAt — en användbar bekräftelse på vad som faktiskt går att extrahera pålitligt.
Data som kräver att du besöker varje produktsida (subpageskrapning)
Sök-korten är medvetet kompakta. Om du gör seriös produktresearch behöver du fälten som gömmer sig ett klick djupare:
- Fullständig beskrivning
- Fullt bildgalleri och videolänkar
- Variationer och personaliseringsalternativ
- Varudetaljer (material, attribut, mått)
- Bearbetningstid
- Fraktinformation och leveransestimat
- Säljar-/butiksprofil och policyer
- Utdrag ur recensioner eller fullständiga recensioner
- Relaterade varor
Etsys egna dokument om listningsskapande bekräftar att säljare anger titel, kategori, attribut, pris, variationer, personalisering, beskrivning, fraktprofil, bearbetnings-/fraktdetaljer samt mått/vikt — så fälten finns där, men du måste besöka sidan för att få fram dem.
Det är här subpage-skrapning blir genuint användbart. Med Thunderbit kan du till exempel skrapa en Etsy-sökresultatsida för titlar, priser och betyg, och sedan klicka på ”Skrapa undersidor” så att AI besöker varje enskild listing och berikar tabellen med taggar, material, fraktdetaljer och säljarinfo — utan någon extra konfiguration. Thunderbits Field AI Prompt låter dig dessutom lägga till egna instruktioner per kolumn (t.ex. ”kategorisera denna produkt i Jewelry / Home Decor / Clothing”).
Testa Thunderbit för skrapning av Etsy-undersidor
Vad skrapning inte kan tala om för dig
Jag vill vara tydlig med detta, för det är här många verktyg tappar trovärdighet:
| Datapunkt | Tillgänglig via skrapning? | Kommentarer |
|---|---|---|
| Faktisk försäljning per listing | Nej | Etsy visar inte offentligt exakt försäljning för varje listing. Butiksnivåns försäljning kan vara synlig, men inte listing-nivåns. |
| Konverteringsgrad | Nej | Endast säljaranalys, inte offentligt. |
| Verklig sökvolym för nyckelord | Nej | Etsy Marketplace Insights visar 30-dagarsdata i säljarverktyg, men detta är inte ett offentligt skrapfält. |
| Annonsutgift / buddata | Nej | Exponeras inte som offentlig listing-data. |
| Vinstmarginal | Nej | Pris och frakt syns; produktionskostnad, avgifter och returer gör det inte. |
Alla verktyg som påstår sig kunna visa exakt Etsy-försäljning för konkurrentlistningar uppskattar siffran, inte skrapar en offentlig fakta. Verktyg som EverBee, eRank och Alura beskriver öppet att de använder uppskattningsalgoritmer, inte direkt dataåtkomst.
Etsy API kontra skrapning: vad behöver du egentligen?
Det här är en fråga jag ser hela tiden i forum: ”Eftersom Etsy API inte tillhandahåller nyckelordsdata antar jag att de skrapar.” Förvirringen är verklig, så här är en tydlig genomgång.
| Dimension | Etsys officiella API | Webbskrapning |
|---|---|---|
| Bästa användningsfall | Hantera din egen butik, listningar, lager, order och betalningar | Konkurrensresearch, sökövervakning, prisintelligens, berikning av undersidor |
| Listningar | Aktiva sök- och detaljendpoints för listningar | Alla offentliga sök-, listnings-, butik- och recensionssidor |
| Försäljning/order i egen butik | Ja, med auktorisering/scopes | Inte nödvändigt; använd API/Shop Manager |
| Exakt konkurrentförsäljning | Nej | Nej (bara uppskattningar) |
| Sökvolym för nyckelord | Inte exponerad som offentlig Open API-endpoint | Inte direkt; Marketplace Insights är säljar-UI |
| Hastighetsbegränsningar | App-specifik QPS/QPD; 429-hantering | Beror på verktyg/plattform |
| TOS-hållning | Officiell väg när den används inom villkoren | Etsys villkor begränsar skrapning utan auktorisation |
| Utdata | JSON-svar från API | CSV/Sheets/JSON/HTML beroende på verktyg |
Slutsatsen: om du behöver hantera din egen butik ska du använda API:t. Om du behöver förstå konkurrenterna, övervaka priser eller undersöka en nisch är skrapning den praktiska vägen. Verktyg som eRank och Alura kombinerar sannolikt API-åtkomst med skrapning och uppskattning — nu vet du varför.
No-code kontra kod: hur du väljer bästa Etsy-skraparen
De flesta som söker efter ”bästa Etsy-skrapare” är inte utvecklare som bygger infrastruktur. De är säljare, marknadsförare, virtuella assistenter eller e-handelsforskare som vill ha en användbar tabell. Ändå fokuserar många konkurrerande artiklar på API-verktyg eller Python-bibliotek. Det är ett glapp.
Här är min beslutsmodell:
| Om du är... | Välj... | Varför |
|---|---|---|
| Icke-teknisk säljare eller marknadsförare | Thunderbit | AI-förslag för fält, Chrome-tillägg, skrapning av undersidor, direkt export, schemalagd skrapning |
| Icke-teknisk men gillar visuella arbetsflöden | Octoparse | Visuell desktop-byggare, mallar, autodetektering, molnläge |
| Frilansare eller liten byrå som bygger återkommande Etsy-jobb | Apify | Cloud Actors, schemaläggare, API, pay-per-result-alternativ |
| Utvecklare som bygger en intern pipeline | ScrapingBee eller ZenRows | API-transport, JS-rendering, proxy-/CAPTCHA-hantering; du styr parser och lagring |
| Data-team på företagsnivå | Bright Data | Hanterad scraper API/dataset, leveransalternativ, driftsäkerhets-/complianceprofil |
”No-code” för den här målgruppen betyder: ingen proxy-inställning, inga CSS-selektorer, inga terminalkommandon, ingen hantering av headless-webbläsare, ingen egen retry-logik och ingen databasuppsättning. Du exporterar direkt till ett kalkylblad eller ett arbetsverktyg, och berikning av undersidor kräver inte att du bygger klickloopar.
Hur jag utvärderade dessa 6 Etsy-skrapare
Jag körde varje verktyg mot samma uppsättning uppgifter: en Etsy-sökfråga (”personalized pet portrait”), en trång produktfråga (”gold huggie earrings”), en butik-URL med många listningar, tio detaljsidor för berikning av undersidor, en schemalagd veckouppgift för prisövervakning och en export till Google Sheets eller CSV.
Här är vad jag poängsatte på:
| Kriterium | Varför det spelar roll |
|---|---|
| Användarvänlighet (no-code kontra kod) | Etsy-säljare ska inte behöva bli skrapningsingenjörer |
| Hantering av anti-bot/CAPTCHA | Ett verktyg som fungerar för 10 rader men misslyckas på sida 2 är inte användbart |
| Extraherbara datafält | Fält från sökresultat räcker inte för seriös produktresearch |
| Exportalternativ (CSV, JSON, Sheets, Airtable) | Det verkliga arbetsflödet slutar oftast i Sheets, Airtable, Notion, CSV, JSON eller BI-verktyg |
| Pristransparens (gratisnivå + kostnad per 1K poster) | Kostnad per användbar rad är viktigare än det månatliga listpriset |
| Berikning av undersidor | Taggar, beskrivningar, frakt, material, variationer och recensioner finns ett klick djupare |
1. Thunderbit
Thunderbit är verktyget vi byggde på Thunderbit specifikt för icke-tekniska användare som snabbt behöver strukturerad webbdata. Det är ett Chrome-tillägg drivet av AI — du öppnar en Etsy-sida, klickar på ”AI Suggest Fields”, och AI:n läser sidstrukturen och föreslår kolumner som titel, pris, recensioner, säljare, URL, bild, märke och frakt. Sedan klickar du på ”Scrape” och får en tabell. Klart.
Det som gör Thunderbit särskilt användbart för Etsy-research är funktionen för skrapning av undersidor. Efter att du har skrapat en sökresultatsida kan du klicka på ”Skrapa undersidor” och Thunderbits AI besöker varje enskild listing för att berika tabellen med fullständiga beskrivningar, fraktdetaljer, material, taggar och säljarinfo — utan någon extra konfiguration. Jag har använt det här flödet för att gå från en sökfråga till ett komplett kalkylblad för konkurrensanalys på under tio minuter.
Viktiga funktioner
- AI Suggest Fields: AI läser Etsy-sidan och rekommenderar kolumner. Inga selektorer, inga gissningar.
- Skrapning i 2 klick: Perfekt för ad hoc-produktresearch.
- Skrapning av undersidor: Berika sökresultaten med fullständiga listningsdetaljer med ett klick.
- Schemalagd skrapning: Ställ in veckovis prisövervakning av konkurrenter genom att beskriva intervallet med vanlig text.
- Field AI Prompt: Lägg till egna instruktioner per kolumn (t.ex. ”kategorisera i Jewelry / Home Decor / Clothing” eller ”markera om denna listing verkar personaliserad”).
- Export: Excel, Google Sheets, Airtable, Notion, CSV, JSON — all export är gratis.
- Moln- och webbläsarläge: Molnläge för snabbare offentliga jobb; webbläsarläge för sidor där din aktuella session/rendering spelar roll (mer exakt för dynamiska fält som favoriter).
- Öppet API: Extract-endpointen accepterar URL + JSON Schema och stöder batch upp till 100 URL:er per begäran.
Så skrapar Thunderbit Etsy i 2 klick
- Gå till en Etsy-sökresultatsida (t.ex. sök efter ”personalized pet portrait”).
- Klicka på AI Suggest Fields — AI:n föreslår kolumner som titel, pris, recensioner, säljare, URL, bild och märken.
- Klicka på Scrape — data fylls i en tabell.
- Klicka valfritt på Skrapa undersidor i kolumnen med listing-URL för att berika rader med full beskrivning, fraktdetaljer, material eller recensioner.
- Exportera till Google Sheets, Airtable, Notion, Excel, CSV eller JSON.
Du kan också kolla in vår Thunderbit YouTube-kanal för videogenomgångar.
Prissättning
Thunderbit använder en kreditbaserad modell. Det finns en gratisnivå/provperiod, och Starter-planen ligger på cirka 15 USD/månad för 500 krediter (eller 108 USD/år för 5 000 årliga krediter). Skrapning av undersidor kan förbruka fler krediter eftersom varje berikad rad/sida räknas separat. Se Thunderbit prissättning för senaste uppgifter.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Ingen kod, ingen selektorinställning | Kreditbaserat; mycket stora jobb kräver betald plan |
| AI-baserad fältdetektering minskar underhåll vid sidändringar | Chrome-tillägget kräver installation av webbläsare |
| Berikning av undersidor är inbyggd | Är inte positionerat som leverantör av datamängder i enterprise-skala |
| Schemalagd skrapning och auto-export stödjer övervakningsflöden | Noggrannheten behöver fortfarande stickprovskontrolleras (gäller alla verktyg) |
| Fungerar bortom Etsy — användbart för generell e-handelsresearch | Vissa fält förblir otillgängliga eftersom Etsy inte exponerar dem |
Bäst för: Etsy-säljare som gör produktresearch, marknadsförare som bygger konkurrensrapporter och operationsteam som övervakar priser.
2. Apify Etsy Scraper
Apify är en molnautomationsplattform med en marknadsplats av ”Actors” — färdigbyggda skrapare som du kan köra utan att hantera egen infrastruktur. För Etsy finns flera Actors tillgängliga, inklusive Automation Lab Etsy Scraper och CrawlerBros Etsy Scraper.
Automation Lab-Actorn stöder sökning på nyckelord, kategorifiltrering, paginering (upp till 5 000 produkter per körning) och strukturerad utdata med fält som listing ID, titel, URL, bild-URL, butik, pris, ursprungspris, valuta, rea-status, fri frakt, betyg, tillgänglighet, position, sökfras, sida och skraptidpunkt. Det är en solid uppsättning för data på sökresultatsnivå.
Viktiga funktioner
- Molnhostad (inga lokala resurser behövs)
- Skrapning via nyckelord, kategori och butik-URL
- Hantering av paginering
- Export till JSON, CSV, Excel
- Proxy-integration (residential proxies finns mot extra kostnad)
- Schemaläggare för återkommande jobb
- API-åtkomst för pipeline-integration
Prissättning
Apify Automation Lab Etsy Scraper tar betalt per körning plus per produkt: ungefär 0,80–3,45 USD per 1K produkter beroende på din Apify-plan. Plattformens planer börjar vid cirka 9 USD/månad (Starter) plus Actor-användning. Gratisplanen inkluderar 5 USD/månad i plattformsanvändning.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Färdiga Etsy-Actors | Kvaliteten varierar beroende på underhållare |
| Molnkörning, schemaläggare, API, webhooks | Community-Actors kan halka efter när Etsy ändrar layout |
| Transparent prissättning per resultat på vissa Actors | Proxykostnader drar iväg i stor skala |
| JSON/CSV/Excel-export via Apify-dataset | Anpassad berikning av undersidor kan kräva konfiguration |
| Bra för återkommande datapipelines | Low-code, inte lika enkelt som ett webbläsartillägg för säljare |
Bäst för: Frilansare, små byråer och halvtekniska användare som vill ha en plug-and-play-datapipeline för Etsy.
3. Bright Data
Bright Data är företagsalternativet. Om du är ett stort e-handelsföretag eller ett datateam som skrapar tusentals Etsy-listningar dagligen är det här byggt för dig. Bright Data erbjuder ett dedikerat Etsy Scraper API och en färdig Etsy-dataset med över 18 miljoner poster och 59 fält.
Deras infrastruktur är enorm — över 100 miljoner residential IP:er, fullstack-hantering av anti-bot (residential proxies, CAPTCHA-lösning, browser fingerprinting), strukturerad JSON-utdata och ett compliance-först-upplägg. De har också ett no-code-alternativ i form av Data Collector för användare som inte vill röra kod.
Viktiga funktioner
- Färdigbyggd Etsy-datainsamlare (no-code dashboard-alternativ)
- Fullstack-hantering av anti-bot
- Strukturerad JSON-utdata med 59+ fält
- Hanterad leverans, webhook och integrationer för molnlagring
- Enterprise-SLA:er, compliance-verktyg, driftsgarantier
- Färdig Etsy-dataset för bulk-analys
Prissättning
Bright Datas Etsy Scraper API börjar på cirka $2,50/1K poster pay-as-you-go. Etsy-dataseten har ett minimumbelopp på 50 USD. Ingen gratisnivå, men Scraper API-sidan annonserar 1K testförfrågningar. Scale-planen är 499 USD/månad. Det här är premiumprissättning — det är inte för någon som skrapar 50 listningar en lördagseftermiddag.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Mest tillförlitliga och stabila plattformen | Överdrivet för engångsresearch av säljare |
| Branschledande bypass av anti-bot | Premiumprissättning (hög tröskel för små företag) |
| No-code Data Collector-alternativ | Överväldigande antal funktioner för enkla uppgifter |
| Strikta compliance-verktyg | Ingen gratisnivå |
| Enorm skala | Anpassning av undersidor kan kräva API-/konfigurationsarbete |
Bäst för: Stora e-handelsföretag, datateam och enterprise som behöver garanterad drifttid, juridisk compliance och skala.
4. Octoparse
Octoparse är en desktop-applikation med ett visuellt point-and-click-gränssnitt för att bygga skrapflöden. Om du gillar att se exakt vad din skrapare gör — klickar, scrollar, paginerar — är det här ditt verktyg.
Octoparse har en Etsy Product Scraper-mall som kan extrahera produktnamn, säljare, betyg, antal recensioner, pris, URL och bild-URL via nyckelord. Deras handledning i hjälpcentret går igenom hur man skrapar produktinformation från Etsy, inklusive autodetektering av webbsidesdata och skapande av arbetsflöden med paginering och sidscrollning.
Viktiga funktioner
- Visuell arbetsflödesbyggare (dra och släpp)
- Inbyggd IP-rotering
- CAPTCHA-hantering via tredjepartsintegrationer (manuell lösning nämns i Etsy-mallen)
- Stöd för oändlig scroll och paginering
- Molnkörningsalternativ
- Export: CSV, Excel, JSON, databasanslutningar, Google Sheets (på betalda planer)
Prissättning
Gratisplan med lokal extraktion och radgränser. Standard-planen ligger runt $69/månad vid årlig betalning. Betalda nivåer lägger till molnfunktioner, fler exportalternativ och högre radgränser.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Verkligt no-code visuellt gränssnitt | Desktopappen är resurskrävande |
| Etsy-mall och handledning finns | Komplex subpage-skrapning kräver manuell konfiguration av arbetsflöde |
| Hanterar paginering/oändlig scroll | CAPTCHA kan kräva manuell lösning i vissa fall |
| Exporterar till CSV, Excel, JSON, databaser | Långsammare än API-baserade lösningar i stor skala |
| Bra inlärningsväg för no-code-skrapning | Mer konfigurationsfriktion än verktyg med AI-förslag för fält |
Bäst för: Icke-tekniska marknadsanalytiker och business analysts som föredrar ett visuellt gränssnitt och vill anpassa extraktionsflöden utan kod.
5. ScrapingBee
ScrapingBee är ett API för utvecklare. Du skickar en URL, och det returnerar renderad HTML (eller extraherad JSON om du sätter upp extraktionsregler). Det finns ingen färdig Etsy-parser som lämnar över ett kalkylblad — du skriver din egen extraktionslogik i Python, JavaScript eller vilket språk du än föredrar.
ScrapingBees Etsy-sida säger att extraherbara fält kan inkludera produktnamn, kategorier, pris, lagerstatus, fraktinfo och storlek med JSON-formaterade extraktionsregler. Den noterar också att Etsy-skrapning bör ta hänsyn till premiumproxies, hantering av förfrågningshastighet och risker kring villkoren.
Viktiga funktioner
- JavaScript-rendering
- Automatisk proxy-rotering
- CAPTCHA-hantering
- Enkelt REST API
- Stöd för Python/Node.js/alla språk
- Returnerar rå HTML eller JSON; användaren parser och exporterar
Prissättning
1 000 gratis API-krediter att börja med. Freelance-planen kostar 49 USD/månad för 250K krediter och 10 samtidiga förfrågningar. Startup kostar 99 USD/månad för 1M krediter. Business kostar 249 USD/månad för 3M krediter.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Enkel API-integration | Kräver kod (Python/JS) |
| JavaScript-rendering och proxyalternativ | Returnerar rå HTML (ingen automatisk parsning av alla fält) |
| Fungerar med vilket språk som helst | Inget visuellt gränssnitt |
| Bra för skräddarsydda datapipelines | Berikning av undersidor kräver egen skriptning |
| Mer flexibelt än visuella verktyg | Export, lagring och schemaläggning är ditt ansvar |
Bäst för: Python-/JS-utvecklare som bygger interna verktyg och behöver ett tillförlitligt ”transportlager” för att få fram Etsy-HTML utan blockeringar.
6. ZenRows
ZenRows är ett annat utvecklar-API, likt ScrapingBee men med starkare fokus på att kringgå anti-bot i stor skala. Det hanterar CAPTCHAs, fingerprinting och residential proxies automatiskt.
ZenRows sida för Etsy-scraper listar fält som rabatt, URL, säljarens namn, beskrivning, betyg, produktnamn, pris, tillgänglighet, kategori, bild, recensioner och valuta. De påstår 99,93 % träffsäkerhet och har funktioner som anti-CAPTCHA, premiumproxies, stealth mode, smart extraktion och JavaScript-rendering.
Viktiga funktioner
- Bypass av anti-bot (premiumproxies, headless browsers)
- Automatiskt roterande headers
- JavaScript-rendering
- Enkla API-anrop
- Stöd för hög samtidighet
Prissättning
14 dagars gratis provperiod med 1 000 basic results och 40 protected results. Developer-planen kostar 69,99 USD/månad för 250K basic / 10K protected results. Skyddade förfrågningar (för sajter med anti-bot) kostar mer per förfrågan.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Stark bypass av anti-bot i stor skala | Kräver kod |
| Hög påstådd träffsäkerhet för e-handel | Ingen parsning — returnerar bara HTML/JSON |
| JS-rendering, premiumproxies, CAPTCHA-hantering | Inget visuellt gränssnitt |
| Bra dokumentation och API-först-modell | Berikning av undersidor är helt manuell |
| Skalar bättre än desktopverktyg | Inte idealiskt för engångsresearch av säljare |
Bäst för: Utvecklingsteam som bygger Etsy-datapipelines i stor skala och behöver robust anti-detektion med hög samtidighet.
Bästa Etsy-skraparna jämförda: tabell sida vid sida
| Verktyg | No-code? | Hantering av anti-bot | Gratisnivå/provperiod | Exportformat | Skrapning av undersidor | Ungefärlig kostnad per 1K | Bäst för |
|---|---|---|---|---|---|---|---|
| Thunderbit | ✅ Ja (Chrome-tillägg) | Moln- och webbläsarläge; AI anpassar fält | ✅ Gratisnivå/provperiod | Excel, Sheets, Airtable, Notion, CSV, JSON | ✅ Inbyggd | ~$9,60–$30/1K rader (beroende på plan) | Icke-tekniska säljare och marknadsförare |
| Apify Etsy Scraper | ⚠️ Low-code | Beroende av Actor; proxy-/sessionsförsök igen | ✅ Gratis 5 USD/mån plattform | JSON, CSV, Excel, API/webhooks | ⚠️ Kräver konfiguration | ~$0,80–$3,45/1K produkter | Dedikerade Etsy-datapipelines |
| Bright Data | ⚠️ Dashboard + API | ✅ Full stack (residential proxies, CAPTCHA) | ❌ Nej (1K testförfrågningar) | JSON, NDJSON, CSV, molnleverans | ⚠️ Kräver setup | ~$2,50/1K poster PAYG | Extraktion i enterprise-skala |
| Octoparse | ✅ Ja (desktopapp) | Inbyggd rotation; manuell CAPTCHA-möjlighet | ✅ Gratisplan (begränsad) | CSV, Excel, JSON, DB, Sheets (betalt) | ⚠️ Arbetsflödesbaserad | Fast SaaS (från cirka $69/mån) | Visuella arbetsflödesbyggare |
| ScrapingBee | ❌ Kod (API) | ✅ Proxy + JS-rendering | ✅ 1K krediter | JSON, rå HTML | ❌ Manuell | ~$4,90/1K (Freelance est.) | Utvecklare med Python/JS |
| ZenRows | ❌ Kod (API) | ✅ Bypass av anti-bot, premiumproxies | ✅ 14 dagars provperiod | JSON, HTML | ❌ Manuell | ~$7/1K protected | Utvecklingsteam som behöver skala |
Inget enskilt verktyg vinner överallt. Den bästa Etsy-skraparen beror på din tekniska nivå, budget och hur stor skala du behöver. För säljare är 500 korrekta rader i Google Sheets med titel, pris, recensioner, säljare, annonsflagga och frakt mer värdefulla än 5 000 billiga råa HTML-sidor.
Hur du verifierar att din Etsy-skrapare är korrekt (hoppa inte över detta)
Jag vill ta upp något som ständigt dyker upp i Etsy-säljarforum: skepsis kring datanoggrannhet. En Reddit-användare rapporterade att EverBee visade 0 försäljningar för ett klistermärke som faktiskt hade sålt omkring 40 enheter på två månader. En annan sade att siffrorna från EverBee, Alura och eRank var ”väldigt felaktiga” för deras egen kopplade butik. Det här är inte unikt för de verktygen — vilken skrapare som helst kan returnera gammal eller felaktig data om du inte verifierar.
Här är metoden för stickprovskontroll som jag använder:
- Skrapa först ett litet urval — 20 till 50 rader.
- Öppna manuellt 3–5 listningar från urvalet.
- Kontrollera titel, pris, valuta, antal recensioner, betyg, fri frakt, säljarens namn och listing-URL mot den live-sidan på Etsy.
- Kontrollera om sponsrade/annonsrader är korrekt märkta eller separerade.
- Kör om samma skrapning efter 24 timmar och jämför ändringar i pris/recensioner.
- Lägg till metadata-kolumner i din export: scraped_at, source_url, query, page, position, country, tool, run_id.
Aktualitet spelar roll. Verktyg som skrapar i realtid (som Thunderbits webbläsarläge, som öppnar sidan i din egen inloggade webbläsare) tenderar att ge mer aktuella resultat än batchjobb med okänd cacheålder. Etsys egna API-villkor kräver att API-användare inte visar listningsinnehåll som är mer än 6 timmar äldre än motsvarande information på Etsy-sidan — en användbar referens för hur snabbt Etsy-data kan bli inaktuell.
Och en gång till för de längst bak: alla verktyg som påstår sig kunna visa exakta försäljningssiffror per listing uppskattar, inte skrapar en offentlig fakta. Var skeptisk till påståenden om precision.
Verkliga användningsfall: så väljer du bästa Etsy-skraparen för uppgiften
”Vad säljer i min nisch?” — Konkurrensresearch av produkter
En säljare vill se topp-listningar för ”personalized pet portrait” — prisintervall, antal recensioner, bästsäljar-taggar, fri frakt, butiksnamn och listing-URL:er.
Bästa match: Thunderbit (2-klicksskrapning av sökresultat, AI föreslår alla relevanta kolumner, export till Google Sheets för analys) eller Apify (sätt upp en återkommande Actor för samma sökning varje vecka).
Tips: Ta med annons-/sponsormarkeringen och positionen. Etsy-annonser upptar särskilda sökresultatsytor, så data från första sidan är inte enbart organisk.
”Övervaka konkurrenters prissättning varje vecka” —För tre veckor sedan satte jag mig ner för att undersöka säljare av ”personalized pet portrait” på Etsy. Fyrtiosju webbläsarflikar, två timmars copy-paste och ett mycket rörigt kalkylblad senare hade jag fortfarande ingen tydlig bild av prissättning, recensioner eller vem som körde annonser jämfört med vem som rankade organiskt. Den upplevelsen satte igång hela det här projektet.
Etsy har nu över 100 miljoner varor till försäljning, 5,6 miljoner aktiva säljare och 86,5 miljoner aktiva köpare. Det är en enorm och stökig marknadsplats — och om du är säljare, marknadsförare eller e-handelsspanare som försöker förstå vad som fungerar i din nisch behöver du strukturerad data, inte en vägg av öppna flikar. Problemet? Etsys anti-bot-försvar har blivit riktigt sofistikerat år 2026. Med dynamiska sidstrukturer, TLS-fingerprinting, CAPTCHAs och beteendeanalys är tiden då man kunde skriva ett snabbt Python-skript och vara klar i princip över.
De senaste veckorna har jag testat sex Etsy-skrapare sida vid sida — från no-code AI-verktyg till utvecklar-API:er — och jag ska gå igenom exakt vad som fungerade, vad som inte gjorde det och vilket verktyg som passar vilken typ av användare. Jag går också igenom vilken data du faktiskt kan extrahera (och vad du inte kan), debatten om Etsy API kontra skrapning, verkliga användningsfall och hur du verifierar dina resultat så att du inte fattar beslut på dålig data.
Varför det är svårare att skrapa Etsy än du tror
Om du någonsin har försökt skrapa Etsy och kört fast är du långt ifrån ensam. Etsy är inte en statisk katalog — det är en dynamisk, personaliserad marknadsplats. Sökresultat, annonser, märken, fraktinformation och till och med sidans CSS-klassnamn kan ändras mellan sessioner, enheter och länder.
Här är den korta versionen av vad som gör Etsy knepigt:
- Dynamisk sidstruktur: Etsys frontend ändras ofta. Selektorer som fungerade igår kanske ger tomma resultat idag. Det är som att Etsy byter lås på sina dörrar varannan timme — sidan ser fortfarande bekant ut för en besökare, men de datakrokar som en skrapare är beroende av kan ändras utan förvarning.
- Bot-hanteringssystem: Skrapleverantörer som Apify påpekar öppet att Etsy använder ”aggressive anti-bot protection” och att sessioner kan blockeras. Vissa Actorsidor nämner URL-mönster för att undvika DataDome och imitation av Chrome TLS-fingeravtryck. Mer generellt visade Impervas 2026 Bad Bot Report att automatiserad trafik stod för 53 % av all webbtrafik år 2025, och Akamai rapporterade att bottar utgjorde 42,1 % av all webbtrafik — e-handelssajter är ett primärt mål.
- CAPTCHAs och hastighetsbegränsning: Skrapning i hög volym kan trigga CAPTCHA eller direkta blockeringar. Octoparses Etsy-mall noterar till och med att om en CAPTCHA dyker upp kan användaren pausa uppgiften och lösa den manuellt.
- Sponsrade resultat och personalisering: Etsys sökresultat blandar organiska och betalda listningar, och Etsy säger att annonser visas i särskilda annonsytor i sökresultaten. Om du inte håller koll på vilka resultat som är annonser kan din konkurrensanalys bli rejält missvisande.
Inget av detta betyder att det är omöjligt att skrapa Etsy. Det betyder att verktyget du väljer spelar mycket större roll än förr.
Vilken data kan du faktiskt skrapa från Etsy?
Det här är avsnittet jag önskar att varje konkurrentartikel tog med — men nästan ingen gör det. Innan du väljer verktyg behöver du veta vad som faktiskt är möjligt.
Data du kan få från Etsys sökresultat
Sökresultatsidor ger dig bredd. Här är vad du vanligtvis kan extrahera från rutnätet:
- Produktnamn
- Pris (aktuellt, på rea, ursprungligt när det syns)
- Valuta
- URL till huvudbild
- Listing-URL / listing-ID
- Butiksnamn (när det syns — annonser visar ibland ”Ad by Etsy Seller”)
- Betyg
- Antal recensioner
- Fri frakt-märke
- Märken för bästsäljare / Etsy's Pick / Star Seller
- Sponsor-/annonsmärkning
- Sidnummer och position
- Metadata för sökfras, filter, sortering och land/session
Apifys Automation Lab Etsy-Actor exponerar till exempel fält som listingId, name, url, imageUrl, shop, shopId, price, originalPrice, currency, onSale, freeShipping, rating, availability, position, query, page och scrapedAt — en användbar bekräftelse på vad som faktiskt går att extrahera pålitligt.
Data som kräver att du besöker varje produktsida (subpageskrapning)
Sök-korten är medvetet kompakta. Om du gör seriös produktresearch behöver du fälten som gömmer sig ett klick djupare:
- Fullständig beskrivning
- Fullt bildgalleri och videolänkar
- Variationer och personaliseringsalternativ
- Varudetaljer (material, attribut, mått)
- Bearbetningstid
- Fraktinformation och leveransestimat
- Säljar-/butiksprofil och policyer
- Utdrag ur recensioner eller fullständiga recensioner
- Relaterade varor
Etsys egna dokument om listningsskapande bekräftar att säljare anger titel, kategori, attribut, pris, variationer, personalisering, beskrivning, fraktprofil, bearbetnings-/fraktdetaljer samt mått/vikt — så fälten finns där, men du måste besöka sidan för att få fram dem.
Det är här subpage-skrapning blir genuint användbart. Med Thunderbit kan du till exempel skrapa en Etsy-sökresultatsida för titlar, priser och betyg, och sedan klicka på ”Skrapa undersidor” så att AI besöker varje enskild listing och berikar tabellen med taggar, material, fraktdetaljer och säljarinfo — utan någon extra konfiguration. Thunderbits Field AI Prompt låter dig dessutom lägga till egna instruktioner per kolumn (t.ex. ”kategorisera denna produkt i Jewelry / Home Decor / Clothing”).
Testa Thunderbit för skrapning av Etsy-undersidor
Vad skrapning inte kan tala om för dig
Jag vill vara tydlig med detta, för det är här många verktyg tappar trovärdighet:
| Datapunkt | Tillgänglig via skrapning? | Kommentarer |
|---|---|---|
| Faktisk försäljning per listing | Nej | Etsy visar inte offentligt exakt försäljning för varje listing. Butiksnivåns försäljning kan vara synlig, men inte listing-nivåns. |
| Konverteringsgrad | Nej | Endast säljaranalys, inte offentligt. |
| Verklig sökvolym för nyckelord | Nej | Etsy Marketplace Insights visar 30-dagarsdata i säljarverktyg, men detta är inte ett offentligt skrapfält. |
| Annonsutgift / buddata | Nej | Exponeras inte som offentlig listing-data. |
| Vinstmarginal | Nej | Pris och frakt syns; produktionskostnad, avgifter och returer gör det inte. |
Alla verktyg som påstår sig kunna visa exakt Etsy-försäljning för konkurrentlistningar uppskattar siffran, inte skrapar en offentlig fakta. Verktyg som EverBee, eRank och Alura beskriver öppet att de använder uppskattningsalgoritmer, inte direkt dataåtkomst.
Etsy API kontra skrapning: vad behöver du egentligen?
Det här är en fråga jag ser hela tiden i forum: ”Eftersom Etsy API inte tillhandahåller nyckelordsdata antar jag att de skrapar.” Förvirringen är verklig, så här är en tydlig genomgång.
| Dimension | Etsys officiella API | Webbskrapning |
|---|---|---|
| Bästa användningsfall | Hantera din egen butik, listningar, lager, order och betalningar | Konkurrensresearch, sökövervakning, prisintelligens, berikning av undersidor |
| Listningar | Aktiva sök- och detaljendpoints för listningar | Alla offentliga sök-, listnings-, butik- och recensionssidor |
| Försäljning/order i egen butik | Ja, med auktorisering/scopes | Inte nödvändigt; använd API/Shop Manager |
| Exakt konkurrentförsäljning | Nej | Nej (bara uppskattningar) |
| Sökvolym för nyckelord | Inte exponerad som offentlig Open API-endpoint | Inte direkt; Marketplace Insights är säljar-UI |
| Hastighetsbegränsningar | App-specifik QPS/QPD; 429-hantering | Beror på verktyg/plattform |
| TOS-hållning | Officiell väg när den används inom villkoren | Etsys villkor begränsar skrapning utan auktorisation |
| Utdata | JSON-svar från API | CSV/Sheets/JSON/HTML beroende på verktyg |
Slutsatsen: om du behöver hantera din egen butik ska du använda API:t. Om du behöver förstå konkurrenterna, övervaka priser eller undersöka en nisch är skrapning den praktiska vägen. Verktyg som eRank och Alura kombinerar sannolikt API-åtkomst med skrapning och uppskattning — nu vet du varför.
No-code kontra kod: hur du väljer bästa Etsy-skraparen
De flesta som söker efter ”bästa Etsy-skrapare” är inte utvecklare som bygger infrastruktur. De är säljare, marknadsförare, virtuella assistenter eller e-handelsforskare som vill ha en användbar tabell. Ändå fokuserar många konkurrerande artiklar på API-verktyg eller Python-bibliotek. Det är ett glapp.
Här är min beslutsmodell:
| Om du är... | Välj... | Varför |
|---|---|---|
| Icke-teknisk säljare eller marknadsförare | Thunderbit | AI-förslag för fält, Chrome-tillägg, skrapning av undersidor, direkt export, schemalagd skrapning |
| Icke-teknisk men gillar visuella arbetsflöden | Octoparse | Visuell desktop-byggare, mallar, autodetektering, molnläge |
| Frilansare eller liten byrå som bygger återkommande Etsy-jobb | Apify | Cloud Actors, schemaläggare, API, pay-per-result-alternativ |
| Utvecklare som bygger en intern pipeline | ScrapingBee eller ZenRows | API-transport, JS-rendering, proxy-/CAPTCHA-hantering; du styr parser och lagring |
| Data-team på företagsnivå | Bright Data | Hanterad scraper API/dataset, leveransalternativ, driftsäkerhets-/complianceprofil |
”No-code” för den här målgruppen betyder: ingen proxy-inställning, inga CSS-selektorer, inga terminalkommandon, ingen hantering av headless-webbläsare, ingen egen retry-logik och ingen databasuppsättning. Du exporterar direkt till ett kalkylblad eller ett arbetsverktyg, och berikning av undersidor kräver inte att du bygger klickloopar.
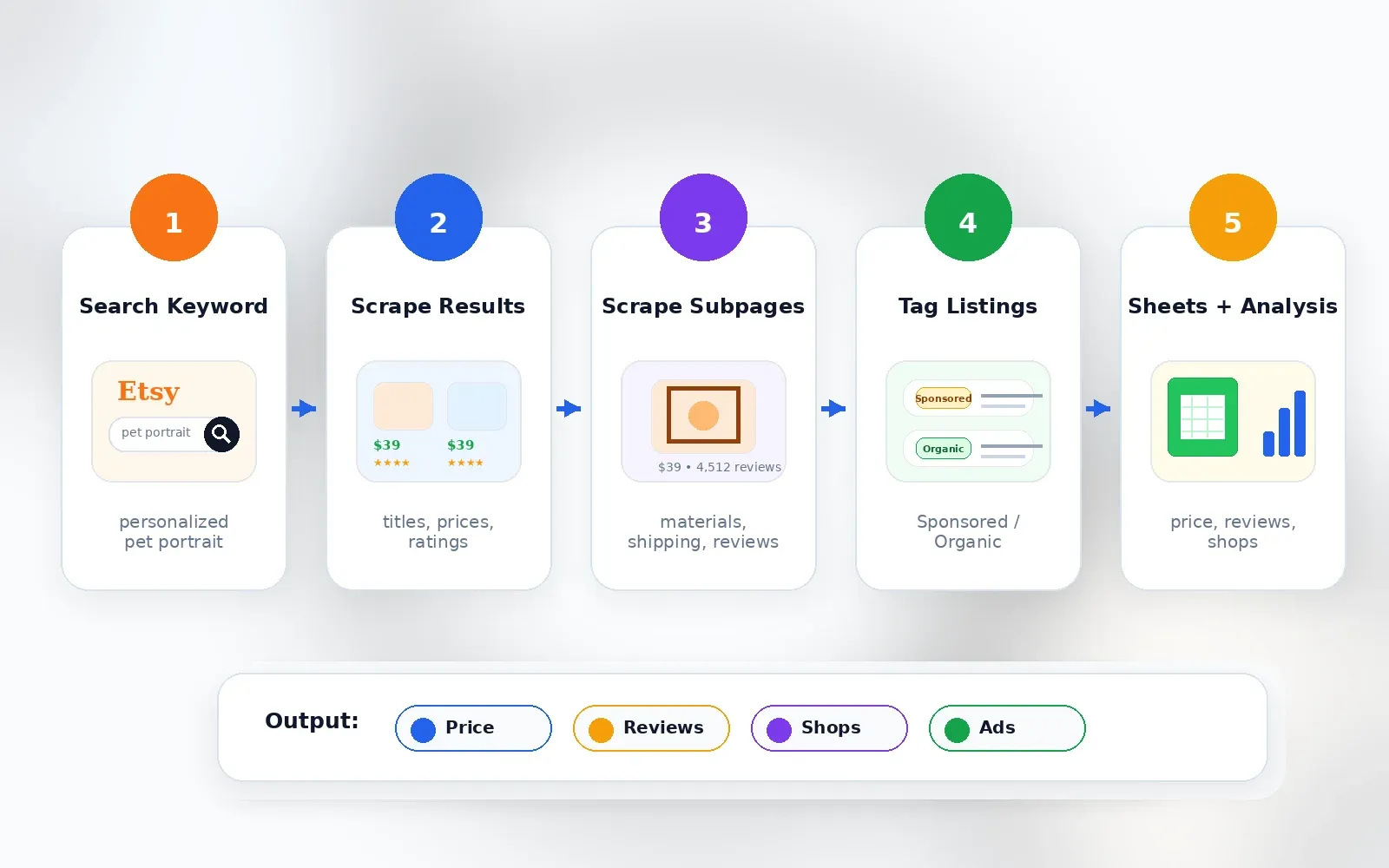
Hur jag utvärderade dessa 6 Etsy-skrapare
Jag körde varje verktyg mot samma uppsättning uppgifter: en Etsy-sökfråga (”personalized pet portrait”), en trång produktfråga (”gold huggie earrings”), en butik-URL med många listningar, tio detaljsidor för berikning av undersidor, en schemalagd veckouppgift för prisövervakning och en export till Google Sheets eller CSV.
Här är vad jag poängsatte på:
| Kriterium | Varför det spelar roll |
|---|---|
| Användarvänlighet (no-code kontra kod) | Etsy-säljare ska inte behöva bli skrapningsingenjörer |
| Hantering av anti-bot/CAPTCHA | Ett verktyg som fungerar för 10 rader men misslyckas på sida 2 är inte användbart |
| Extraherbara datafält | Fält från sökresultat räcker inte för seriös produktresearch |
| Exportalternativ (CSV, JSON, Sheets, Airtable) | Det verkliga arbetsflödet slutar oftast i Sheets, Airtable, Notion, CSV, JSON eller BI-verktyg |
| Pristransparens (gratisnivå + kostnad per 1K poster) | Kostnad per användbar rad är viktigare än det månatliga listpriset |
| Berikning av undersidor | Taggar, beskrivningar, frakt, material, variationer och recensioner finns ett klick djupare |
1. Thunderbit
Thunderbit är verktyget vi byggde på Thunderbit specifikt för icke-tekniska användare som snabbt behöver strukturerad webbdata. Det är ett Chrome-tillägg drivet av AI — du öppnar en Etsy-sida, klickar på ”AI Suggest Fields”, och AI:n läser sidstrukturen och föreslår kolumner som titel, pris, recensioner, säljare, URL, bild, märke och frakt. Sedan klickar du på ”Scrape” och får en tabell. Klart.
Det som gör Thunderbit särskilt användbart för Etsy-research är funktionen för skrapning av undersidor. Efter att du har skrapat en sökresultatsida kan du klicka på ”Skrapa undersidor” och Thunderbits AI besöker varje enskild listing för att berika tabellen med fullständiga beskrivningar, fraktdetaljer, material, taggar och säljarinfo — utan någon extra konfiguration. Jag har använt det här flödet för att gå från en sökfråga till ett komplett kalkylblad för konkurrensanalys på under tio minuter.
Viktiga funktioner
- AI Suggest Fields: AI läser Etsy-sidan och rekommenderar kolumner. Inga selektorer, inga gissningar.
- Skrapning i 2 klick: Perfekt för ad hoc-produktresearch.
- Skrapning av undersidor: Berika sökresultaten med fullständiga listningsdetaljer med ett klick.
- Schemalagd skrapning: Ställ in veckovis prisövervakning av konkurrenter genom att beskriva intervallet med vanlig text.
- Field AI Prompt: Lägg till egna instruktioner per kolumn (t.ex. ”kategorisera i Jewelry / Home Decor / Clothing” eller ”markera om denna listing verkar personaliserad”).
- Export: Excel, Google Sheets, Airtable, Notion, CSV, JSON — all export är gratis.
- Moln- och webbläsarläge: Molnläge för snabbare offentliga jobb; webbläsarläge för sidor där din aktuella session/rendering spelar roll (mer exakt för dynamiska fält som favoriter).
- Öppet API: Extract-endpointen accepterar URL + JSON Schema och stöder batch upp till 100 URL:er per begäran.
Så skrapar Thunderbit Etsy i 2 klick
- Gå till en Etsy-sökresultatsida (t.ex. sök efter ”personalized pet portrait”).
- Klicka på AI Suggest Fields — AI:n föreslår kolumner som titel, pris, recensioner, säljare, URL, bild och märken.
- Klicka på Scrape — data fylls i en tabell.
- Klicka valfritt på Skrapa undersidor i kolumnen med listing-URL för att berika rader med full beskrivning, fraktdetaljer, material eller recensioner.
- Exportera till Google Sheets, Airtable, Notion, Excel, CSV eller JSON.
Du kan också kolla in vår Thunderbit YouTube-kanal för videogenomgångar.
Prissättning
Thunderbit använder en kreditbaserad modell. Det finns en gratisnivå/provperiod, och Starter-planen ligger på cirka 15 USD/månad för 500 krediter (eller 108 USD/år för 5 000 årliga krediter). Skrapning av undersidor kan förbruka fler krediter eftersom varje berikad rad/sida räknas separat. Se Thunderbit prissättning för senaste uppgifter.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Ingen kod, ingen selektorinställning | Kreditbaserat; mycket stora jobb kräver betald plan |
| AI-baserad fältdetektering minskar underhåll vid sidändringar | Chrome-tillägget kräver installation av webbläsare |
| Berikning av undersidor är inbyggd | Är inte positionerat som leverantör av datamängder i enterprise-skala |
| Schemalagd skrapning och auto-export stödjer övervakningsflöden | Noggrannheten behöver fortfarande stickprovskontrolleras (gäller alla verktyg) |
| Fungerar bortom Etsy — användbart för generell e-handelsresearch | Vissa fält förblir otillgängliga eftersom Etsy inte exponerar dem |
Bäst för: Etsy-säljare som gör produktresearch, marknadsförare som bygger konkurrensrapporter och operationsteam som övervakar priser.
2. Apify Etsy Scraper
Apify är en molnautomationsplattform med en marknadsplats av ”Actors” — färdigbyggda skrapare som du kan köra utan att hantera egen infrastruktur. För Etsy finns flera Actors tillgängliga, inklusive Automation Lab Etsy Scraper och CrawlerBros Etsy Scraper.
Automation Lab-Actorn stöder sökning på nyckelord, kategorifiltrering, paginering (upp till 5 000 produkter per körning) och strukturerad utdata med fält som listing ID, titel, URL, bild-URL, butik, pris, ursprungspris, valuta, rea-status, fri frakt, betyg, tillgänglighet, position, sökfras, sida och skraptidpunkt. Det är en solid uppsättning för data på sökresultatsnivå.
Viktiga funktioner
- Molnhostad (inga lokala resurser behövs)
- Skrapning via nyckelord, kategori och butik-URL
- Hantering av paginering
- Export till JSON, CSV, Excel
- Proxy-integration (residential proxies finns mot extra kostnad)
- Schemaläggare för återkommande jobb
- API-åtkomst för pipeline-integration
Prissättning
Apify Automation Lab Etsy Scraper tar betalt per körning plus per produkt: ungefär 0,80–3,45 USD per 1K produkter beroende på din Apify-plan. Plattformens planer börjar vid cirka 9 USD/månad (Starter) plus Actor-användning. Gratisplanen inkluderar 5 USD/månad i plattformsanvändning.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Färdiga Etsy-Actors | Kvaliteten varierar beroende på underhållare |
| Molnkörning, schemaläggare, API, webhooks | Community-Actors kan halka efter när Etsy ändrar layout |
| Transparent prissättning per resultat på vissa Actors | Proxykostnader drar iväg i stor skala |
| JSON/CSV/Excel-export via Apify-dataset | Anpassad berikning av undersidor kan kräva konfiguration |
| Bra för återkommande datapipelines | Low-code, inte lika enkelt som ett webbläsartillägg för säljare |
Bäst för: Frilansare, små byråer och halvtekniska användare som vill ha en plug-and-play-datapipeline för Etsy.
3. Bright Data
Bright Data är företagsalternativet. Om du är ett stort e-handelsföretag eller ett datateam som skrapar tusentals Etsy-listningar dagligen är det här byggt för dig. Bright Data erbjuder ett dedikerat Etsy Scraper API och en färdig Etsy-dataset med över 18 miljoner poster och 59 fält.
Deras infrastruktur är enorm — över 100 miljoner residential IP:er, fullstack-hantering av anti-bot (residential proxies, CAPTCHA-lösning, browser fingerprinting), strukturerad JSON-utdata och ett compliance-först-upplägg. De har också ett no-code-alternativ i form av Data Collector för användare som inte vill röra kod.
Viktiga funktioner
- Färdigbyggd Etsy-datainsamlare (no-code dashboard-alternativ)
- Fullstack-hantering av anti-bot
- Strukturerad JSON-utdata med 59+ fält
- Hanterad leverans, webhook och integrationer för molnlagring
- Enterprise-SLA:er, compliance-verktyg, driftsgarantier
- Färdig Etsy-dataset för bulk-analys
Prissättning
Bright Datas Etsy Scraper API börjar på cirka $2,50/1K poster pay-as-you-go. Etsy-dataseten har ett minimumbelopp på 50 USD. Ingen gratisnivå, men Scraper API-sidan annonserar 1K testförfrågningar. Scale-planen är 499 USD/månad. Det här är premiumprissättning — det är inte för någon som skrapar 50 listningar en lördagseftermiddag.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Mest tillförlitliga och stabila plattformen | Överdrivet för engångsresearch av säljare |
| Branschledande bypass av anti-bot | Premiumprissättning (hög tröskel för små företag) |
| No-code Data Collector-alternativ | Överväldigande antal funktioner för enkla uppgifter |
| Strikta compliance-verktyg | Ingen gratisnivå |
| Enorm skala | Anpassning av undersidor kan kräva API-/konfigurationsarbete |
Bäst för: Stora e-handelsföretag, datateam och enterprise som behöver garanterad drifttid, juridisk compliance och skala.
4. Octoparse
Octoparse är en desktop-applikation med ett visuellt point-and-click-gränssnitt för att bygga skrapflöden. Om du gillar att se exakt vad din skrapare gör — klickar, scrollar, paginerar — är det här ditt verktyg.
Octoparse har en Etsy Product Scraper-mall som kan extrahera produktnamn, säljare, betyg, antal recensioner, pris, URL och bild-URL via nyckelord. Deras handledning i hjälpcentret går igenom hur man skrapar produktinformation från Etsy, inklusive autodetektering av webbsidesdata och skapande av arbetsflöden med paginering och sidscrollning.
Viktiga funktioner
- Visuell arbetsflödesbyggare (dra och släpp)
- Inbyggd IP-rotering
- CAPTCHA-hantering via tredjepartsintegrationer (manuell lösning nämns i Etsy-mallen)
- Stöd för oändlig scroll och paginering
- Molnkörningsalternativ
- Export: CSV, Excel, JSON, databasanslutningar, Google Sheets (på betalda planer)
Prissättning
Gratisplan med lokal extraktion och radgränser. Standard-planen ligger runt $69/månad vid årlig betalning. Betalda nivåer lägger till molnfunktioner, fler exportalternativ och högre radgränser.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Verkligt no-code visuellt gränssnitt | Desktopappen är resurskrävande |
| Etsy-mall och handledning finns | Komplex subpage-skrapning kräver manuell konfiguration av arbetsflöde |
| Hanterar paginering/oändlig scroll | CAPTCHA kan kräva manuell lösning i vissa fall |
| Exporterar till CSV, Excel, JSON, databaser | Långsammare än API-baserade lösningar i stor skala |
| Bra inlärningsväg för no-code-skrapning | Mer konfigurationsfriktion än verktyg med AI-förslag för fält |
Bäst för: Icke-tekniska marknadsanalytiker och business analysts som föredrar ett visuellt gränssnitt och vill anpassa extraktionsflöden utan kod.
5. ScrapingBee
ScrapingBee är ett API för utvecklare. Du skickar en URL, och det returnerar renderad HTML (eller extraherad JSON om du sätter upp extraktionsregler). Det finns ingen färdig Etsy-parser som lämnar över ett kalkylblad — du skriver din egen extraktionslogik i Python, JavaScript eller vilket språk du än föredrar.
ScrapingBees Etsy-sida säger att extraherbara fält kan inkludera produktnamn, kategorier, pris, lagerstatus, fraktinfo och storlek med JSON-formaterade extraktionsregler. Den noterar också att Etsy-skrapning bör ta hänsyn till premiumproxies, hantering av förfrågningshastighet och risker kring villkoren.
Viktiga funktioner
- JavaScript-rendering
- Automatisk proxy-rotering
- CAPTCHA-hantering
- Enkelt REST API
- Stöd för Python/Node.js/alla språk
- Returnerar rå HTML eller JSON; användaren parser och exporterar
Prissättning
1 000 gratis API-krediter att börja med. Freelance-planen kostar 49 USD/månad för 250K krediter och 10 samtidiga förfrågningar. Startup kostar 99 USD/månad för 1M krediter. Business kostar 249 USD/månad för 3M krediter.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Enkel API-integration | Kräver kod (Python/JS) |
| JavaScript-rendering och proxyalternativ | Returnerar rå HTML (ingen automatisk parsning av alla fält) |
| Fungerar med vilket språk som helst | Inget visuellt gränssnitt |
| Bra för skräddarsydda datapipelines | Berikning av undersidor kräver egen skriptning |
| Mer flexibelt än visuella verktyg | Export, lagring och schemaläggning är ditt ansvar |
Bäst för: Python-/JS-utvecklare som bygger interna verktyg och behöver ett tillförlitligt ”transportlager” för att få fram Etsy-HTML utan blockeringar.
6. ZenRows
ZenRows är ett annat utvecklar-API, likt ScrapingBee men med starkare fokus på att kringgå anti-bot i stor skala. Det hanterar CAPTCHAs, fingerprinting och residential proxies automatiskt.
ZenRows sida för Etsy-scraper listar fält som rabatt, URL, säljarens namn, beskrivning, betyg, produktnamn, pris, tillgänglighet, kategori, bild, recensioner och valuta. De påstår 99,93 % träffsäkerhet och har funktioner som anti-CAPTCHA, premiumproxies, stealth mode, smart extraktion och JavaScript-rendering.
Viktiga funktioner
- Bypass av anti-bot (premiumproxies, headless browsers)
- Automatiskt roterande headers
- JavaScript-rendering
- Enkla API-anrop
- Stöd för hög samtidighet
Prissättning
14 dagars gratis provperiod med 1 000 basic results och 40 protected results. Developer-planen kostar 69,99 USD/månad för 250K basic / 10K protected results. Skyddade förfrågningar (för sajter med anti-bot) kostar mer per förfrågan.
För- och nackdelar
| Fördelar | Nackdelar |
|---|---|
| Stark bypass av anti-bot i stor skala | Kräver kod |
| Hög påstådd träffsäkerhet för e-handel | Ingen parsning — returnerar bara HTML/JSON |
| JS-rendering, premiumproxies, CAPTCHA-hantering | Inget visuellt gränssnitt |
| Bra dokumentation och API-först-modell | Berikning av undersidor är helt manuell |
| Skalar bättre än desktopverktyg | Inte idealiskt för engångsresearch av säljare |
Bäst för: Utvecklingsteam som bygger Etsy-datapipelines i stor skala och behöver robust anti-detektion med hög samtidighet.
Bästa Etsy-skraparna jämförda: tabell sida vid sida
| Verktyg | No-code? | Hantering av anti-bot | Gratisnivå/provperiod | Exportformat | Skrapning av undersidor | Ungefärlig kostnad per 1K | Bäst för |
|---|---|---|---|---|---|---|---|
| Thunderbit | ✅ Ja (Chrome-tillägg) | Moln- och webbläsarläge; AI anpassar fält | ✅ Gratisnivå/provperiod | Excel, Sheets, Airtable, Notion, CSV, JSON | ✅ Inbyggd | ~$9,60–$30/1K rader (beroende på plan) | Icke-tekniska säljare och marknadsförare |
| Apify Etsy Scraper | ⚠️ Low-code | Beroende av Actor; proxy-/sessionsförsök igen | ✅ Gratis 5 USD/mån plattform | JSON, CSV, Excel, API/webhooks | ⚠️ Kräver konfiguration | ~$0,80–$3,45/1K produkter | Dedikerade Etsy-datapipelines |
| Bright Data | ⚠️ Dashboard + API | ✅ Full stack (residential proxies, CAPTCHA) | ❌ Nej (1K testförfrågningar) | JSON, NDJSON, CSV, molnleverans | ⚠️ Kräver setup | ~$2,50/1K poster PAYG | Extraktion i enterprise-skala |
| Octoparse | ✅ Ja (desktopapp) | Inbyggd rotation; manuell CAPTCHA-möjlighet | ✅ Gratisplan (begränsad) | CSV, Excel, JSON, DB, Sheets (betalt) | ⚠️ Arbetsflödesbaserad | Fast SaaS (från cirka $69/mån) | Visuella arbetsflödesbyggare |
| ScrapingBee | ❌ Kod (API) | ✅ Proxy + JS-rendering | ✅ 1K krediter | JSON, rå HTML | ❌ Manuell | ~$4,90/1K (Freelance est.) | Utvecklare med Python/JS |
| ZenRows | ❌ Kod (API) | ✅ Bypass av anti-bot, premiumproxies | ✅ 14 dagars provperiod | JSON, HTML | ❌ Manuell | ~$7/1K protected | Utvecklingsteam som behöver skala |
Inget enskilt verktyg vinner överallt. Den bästa Etsy-skraparen beror på din tekniska nivå, budget och hur stor skala du behöver. För säljare är 500 korrekta rader i Google Sheets med titel, pris, recensioner, säljare, annonsflagga och frakt mer värdefulla än 5 000 billiga råa HTML-sidor.
Hur du verifierar att din Etsy-skrapare är korrekt (hoppa inte över detta)
Jag vill ta upp något som ständigt dyker upp i Etsy-säljarforum: skepsis kring datanoggrannhet. En Reddit-användare rapporterade att EverBee visade 0 försäljningar för ett klistermärke som faktiskt hade sålt omkring 40 enheter på två månader. En annan sade att siffrorna från EverBee, Alura och eRank var ”väldigt felaktiga” för deras egen kopplade butik. Det här är inte unikt för de verktygen — vilken skrapare som helst kan returnera gammal eller felaktig data om du inte verifierar.
Här är metoden för stickprovskontroll som jag använder:
- Skrapa först ett litet urval — 20 till 50 rader.
- Öppna manuellt 3–5 listningar från urvalet.
- Kontrollera titel, pris, valuta, antal recensioner, betyg, fri frakt, säljarens namn och listing-URL mot den live-sidan på Etsy.
- Kontrollera om sponsrade/annonsrader är korrekt märkta eller separerade.
- Kör om samma skrapning efter 24 timmar och jämför ändringar i pris/recensioner.
- Lägg till metadata-kolumner i din export: scraped_at, source_url, query, page, position, country, tool, run_id.
Aktualitet spelar roll. Verktyg som skrapar i realtid (som Thunderbits webbläsarläge, som öppnar sidan i din egen inloggade webbläsare) tenderar att ge mer aktuella resultat än batchjobb med okänd cacheålder. Etsys egna API-villkor kräver att API-användare inte visar listningsinnehåll som är mer än 6 timmar äldre än motsvarande information på Etsy-sidan — en användbar referens för hur snabbt Etsy-data kan bli inaktuell.
Och en gång till för de längst bak: alla verktyg som påstår sig kunna visa exakta försäljningssiffror per listing uppskattar, inte skrapar en offentlig fakta. Var skeptisk till påståenden om precision.
Verkliga användningsfall: så väljer du bästa Etsy-skraparen för uppgiften
”Vad säljer i min nisch?” — Konkurrensresearch av produkter
En säljare vill se topp-listningar för ”personalized pet portrait” — prisintervall, antal recensioner, bästsäljar-taggar, fri frakt, butiksnamn och listing-URL:er.
Bästa match: Thunderbit (2-klicksskrapning av sökresultat, AI föreslår alla relevanta kolumner, export till Google Sheets för analys) eller Apify (sätt upp en återkommande Actor för samma sökning varje vecka).
Tips: Ta med annons-/sponsormarkeringen och positionen. Etsy-annonser upptar särskilda sökresultatsytor, så data från första sidan är inte enbart organisk.
”Övervaka konkurrenters prissättning varje vecka” — Prisbevakning
En butiksägare följer 50 konkurrentlistningar för prisändringar över tid.
Bästa match: Thunderbits Scheduled Scraper (beskriv intervallet med vanlig text, ange URL:erna, klart) eller Bright Data (för övervakning i enterprise-skala över tusentals SKU:er). Apify fungerar också bra för billigare återkommande molnjobb.
Tips: Spåra alltid scraped_at, valuta, land och om listningen var på rea. Ett pris utan tidsstämpel och plats är svagt bevis.
”Bygg en produktkatalog för min butik” — Massuttag av data
Extrahera 500+ listningar med bilder, titlar, priser, beskrivningar och material.
Bästa match: Thunderbit (berikning av undersidor förbättrar varje listing, bildextraktion exporterar till Airtable/Notion) eller Octoparse (visuellt arbetsflöde för massuttag). Apify fungerar om JSON-utdata och molnkörning är viktigare än visuellt arbetsflöde.
Tips: Återanvänd inte upphovsrättsskyddade beskrivningar eller bilder utan tillstånd. Använd skrapat kreativt innehåll för analys, inte för kopiering.
”Jag bygger en Etsy-datapipeline” — utvecklarfall
En utvecklare behöver rå, strukturerad JSON i stor skala med anti-bot-hantering, eget schema, retry-loggar och en warehouse-pipeline.
Bästa match: ScrapingBee eller ZenRows som API-åtkomst/renderingslager. Apify om du föredrar Actor-ekosystemet och hanterade dataset. Thunderbits Open API om JSON Schema-extraktion och batch upp till 100 URL:er passar pipelinen.
Tips: Separera crawling, parsning, validering, lagring och rapportering. Verktyget som hämtar HTML är bara en del av pipelinen.
En notis om sponsrade listningar
Forumanvändare klagar ofta på att en massiv andel av toppresultaten på Etsy bara är sponsrade annonser. En Reddit-användare som diskuterade uBlock-filter beskrev att hen såg ”Ad by Etsy Seller”-resultat om och om igen. En annan säljare beskrev att samma vara dök upp både som annons och organiskt resultat.
Praktiska skrapråd:
- Fånga is_sponsored där det syns
- Separera betalda från organiska positioner
- Skrapa bortom sida 1
- Avduplicera med listing-ID/kanonisk URL, inte titel (annonser och organiska rader kan överlappa)
- Kör en ren utloggad sökning och en inloggad/webbläsarsessionssökning om din researchfråga beror på personalisering
Juridiska och etiska överväganden vid skrapning av Etsy
Jag håller det här kort. Etsys användarvillkor säger att användare inte får crawla, skrapa eller spidera sidor utan uttryckligt tillstånd. Etsys API-villkor förbjuder också att använda automatiserade system för att komma åt, analysera eller skrapa Etsy-sajt/API/data om man inte uttryckligen har auktorisation.
Amerikansk rättspraxis är nyanserad. Fall som hiQ v. LinkedIn är positiva för vissa teorier om skrapning av offentliga data, men de suddar inte ut riskerna kopplade till avtal, upphovsrätt, integritet eller plattformens egen tillämpning. Bright Data har varit inblandat i relevant rättstvist kring dessa frågor.
Mitt råd: använd Etsys officiella API där det täcker ditt användningsfall, samla endast in offentlig och nödvändig data, undvik personliga/privata data, respektera hastighetsgränser och åtkomstkontroller, och återpublicera inte upphovsrättsskyddade foton eller beskrivningar utan tillstånd. Detta är inte juridisk rådgivning — rådfråga en professionell för specifika situationer.
Slutsats: vilken Etsy-skrapare är bäst för dig?
Efter att ha testat alla sex är min ärliga bedömning att den ”bästa” Etsy-skraparen helt beror på vem du är och vad du behöver:
- Icke-tekniska säljare och marknadsförare: Thunderbit. Två klick, AI-driven, berikning av undersidor, direkt export till Sheets/Airtable/Notion. Börja med gratisnivån och se hur långt den tar dig.
- Dedikerade Etsy-datapipelines: Apify. Cloud Actors, schemaläggare, API, transparent prissättning per resultat.
- Enterprise-skala: Bright Data. Hanterad infrastruktur, compliance, SLA:er, enorm proxy-pool.
- Visuella arbetsflöden föredras: Octoparse. Point-and-click-desktopbyggare med mallar.
- Utvecklare: ScrapingBee eller ZenRows. API-transport, JS-rendering, anti-bot — du bygger resten.
Mitt sista tips: börja med en gratisnivå eller provperiod, kör ett stickprov för att kontrollera noggrannheten och skala bara upp när du har verifierat datakvaliteten. Förbind dig inte till en betald plan innan du har bekräftat att verktyget faktiskt returnerar de fält du behöver, i det format du behöver, med den aktualitet du behöver.
Och må din Etsy-data alltid vara ren, strukturerad och fri från oväntade sponsrade listningar.
Vanliga frågor
Vad är den bästa Etsy-skraparen för icke-tekniska användare?
Thunderbit är det starkaste valet för icke-tekniska säljare och marknadsförare. Det är ett Chrome-tillägg där du klickar på ”AI Suggest Fields” på vilken Etsy-sida som helst, granskar de föreslagna kolumnerna, klickar på ”Scrape” och exporterar till Google Sheets, Airtable, Notion eller Excel. Skrapning av undersidor och schemalagd skrapning är inbyggt. Octoparse är också ett bra alternativ om du föredrar en visuell desktop-byggare för arbetsflöden.
Är det lagligt att skrapa Etsy-produkdata?
Skrapning av offentligt tillgänglig webbdata har positiv amerikansk rättspraxis i vissa sammanhang (t.ex. hiQ v. LinkedIn), men Etsys användarvillkor och API-villkor begränsar crawling, skrapning och automatiserad åtkomst utan auktorisation. För kommersiell användning är det klokt att rådfråga jurist, använda det officiella API:t där det är möjligt och undvika att kopiera upphovsrättsskyddat innehåll som produktbilder eller beskrivningar.
Vilken data kan du extrahera från Etsy med en skrapare?
Från sökresultat: titlar, priser, bilder, listing-URL:er, säljare-/butiksnamn, betyg, antal recensioner, märken (bästsäljare, fri frakt, Star Seller) och sponsor-/annonsmärkning. Från enskilda listing-sidor (via skrapning av undersidor): fullständiga beskrivningar, material, attribut, fraktdetaljer, variationer, säljarpolicyer och recensioner. Faktisk försäljning per listing, konverteringsgrad och verklig sökvolym för nyckelord är inte direkt tillgängliga via skrapning — alla verktyg som visar detta uppskattar siffrorna.
Kan jag skrapa Etsy utan att bli blockerad?
Ja, med rätt verktyg. Etsy använder anti-bot-kontroller som dynamiska sidstrukturer, TLS-fingerprinting, CAPTCHA och hastighetsbegränsning. Verktyg som Thunderbit (moln- och webbläsarskrapningslägen), Bright Data (enterprise-proxyinfrastruktur), ScrapingBee (JS-rendering och premiumproxies) och ZenRows (anti-bot-API) hanterar dessa åtgärder automatiskt. För småskalig research tenderar Thunderbits webbläsarläge — som använder din egen inloggade session — att vara pålitligt och ge aktuell data.
Hur mycket kostar en Etsy-skrapare?
Gratisnivåer eller provperioder finns hos Thunderbit, Apify, Octoparse, ScrapingBee och ZenRows. Bright Data erbjuder testförfrågningar men ingen löpande gratisnivå. Betalda planer börjar vanligtvis på 49–69 USD/månad för utvecklar- och no-code-verktyg. Etsy-specifika API:er med prissättning per resultat ligger på ungefär 0,80–3,45 USD per 1K poster (Apify) till 2,50 USD/1K (Bright Data PAYG). Thunderbits kreditbaserade modell börjar på cirka 15 USD/månad. Den verkliga kostnaden beror på hur många rader du behöver, om du använder berikning av undersidor och hur ofta du skrapar.
Testa Thunderbit för Etsy-skrapning Get Started Free
Läs mer




