Tumblr 爬虫
Доверяют профессионалы из ведущих компаний














Откройте данные Tumblr с Thunderbit
Легко извлекайте данные Tumblr, например содержимое постов и количество лайков.
Получите полную картину Tumblr
На страницах со списками Tumblr обычно видны только фрагменты. Чтобы увидеть полную картину, нужны полный текст поста, данные об авторе и вся сопутствующая информация. Thunderbit автоматически переходит на каждую связанную подстраницу, извлекает нужные сведения и добавляет их в виде новых столбцов, так что вы без ручных кликов сможете получить post_id, post_date и многое другое.
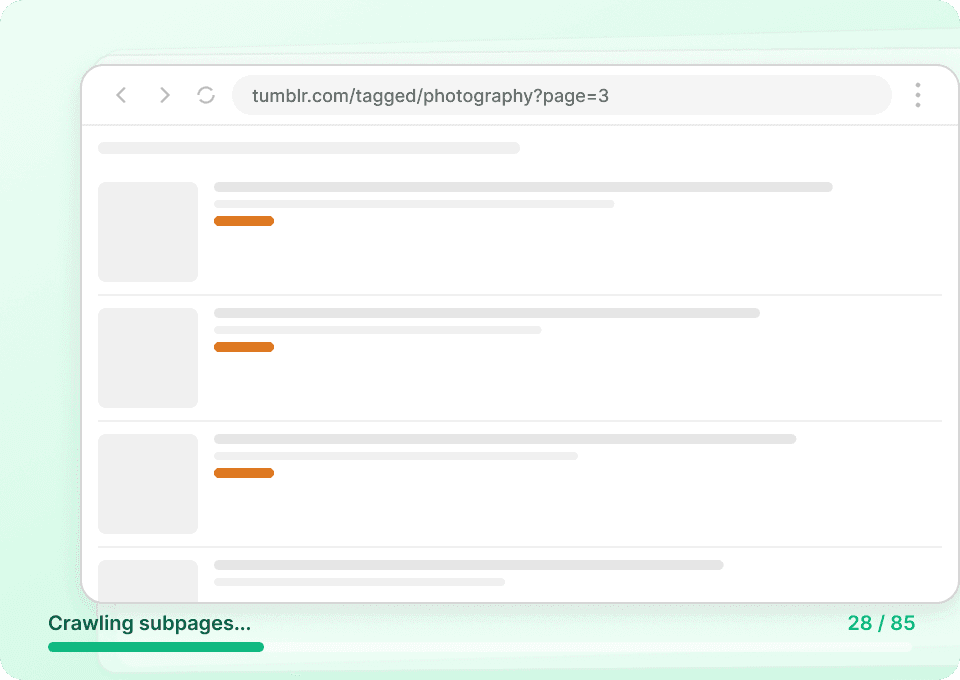
Автоматизируйте сбор данных Tumblr
Данные Tumblr постоянно меняются. Вручную собирать одни и те же блоги снова и снова — утомительно. С помощью планового сбора Thunderbit вы можете настроить повторяющиеся задачи на автопилоте. Получайте свежие данные, такие как like_count и post_content, прямо в Google Sheets без лишних усилий.
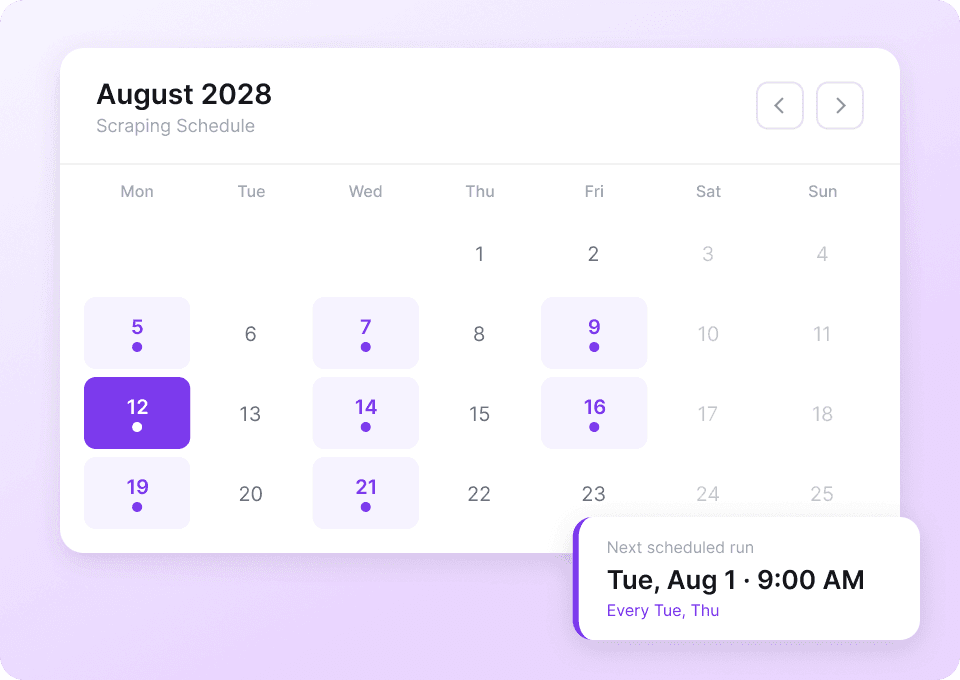
Собирайте посты Tumblr в два клика
Забудьте о сложном коде и CSS-селекторах. Thunderbit позволяет извлекать данные из Tumblr всего за два клика. Просто укажите нужные данные, и семантический ИИ Thunderbit определит соответствующие поля, например post_type и post_author, а затем извлечёт их. Никакого программирования не нужно.
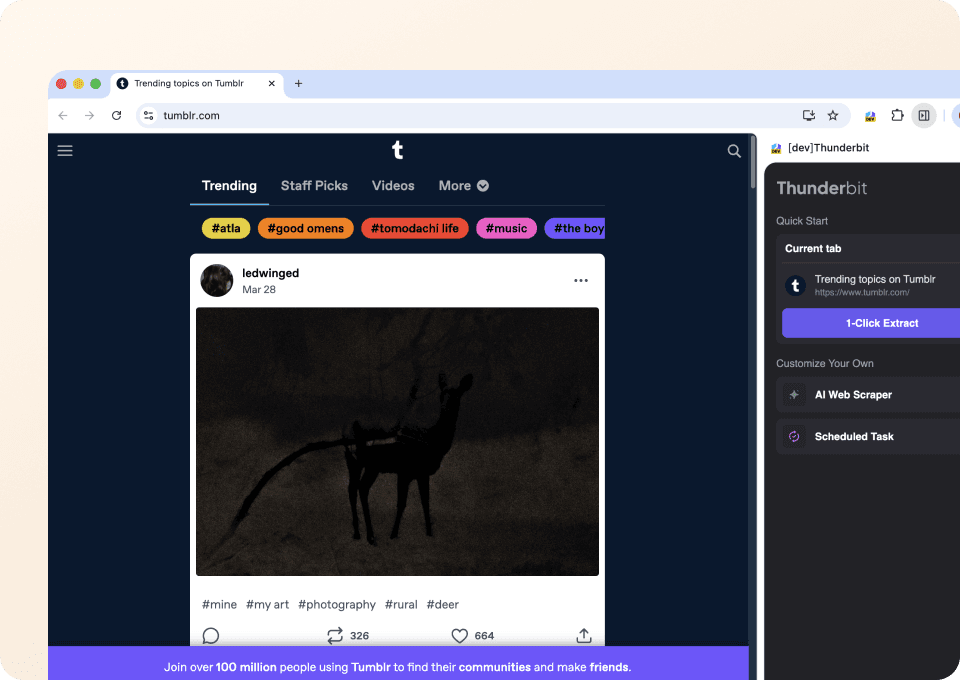
Чем Thunderbit отличается от традиционных tumblr scrapers?
Извлекайте данные Tumblr без лишних усилий, даже если оформление страниц меняется или неожиданно перестраивается.
Традиционные скрейперы
Старый способ работыThunderbit AI
Более умный подходНе верь нам на слово
Посмотри, что пользователи говорят о Thunderbit.






Часто задаваемые вопросы
Похожие сценарии использования
Изучи больше сценариев использования веб-скрапера Thunderbit.

Веб-скрейпер Wikipedia
Получайте данные из инфобоксов Wikipedia, ссылки и текст статей в аккуратную таблицу — без кода, ИИ сам структурирует данные за вас.
Узнать больше ->
HKTVmall Scraper
Собирайте названия товаров, цены и даже оценки покупателей из карточек HKTVmall всего в пару кликов — без сложной настройки.
Узнать больше ->PeopleWhiz скрейпер
Скрейпер Thunderbit для PeopleWhiz позволяет извлекать данные из результатов поиска и профилей PeopleWhiz с помощью подсказок по полям на базе ИИ. Собирайте имена, контактные данные, местоположения и многое другое для исследований, маркетинга или поиска лидов. Быстро и эффективно превращайте данные PeopleWhiz в структурированные наборы данных.
Узнать больше ->
Sports Direct Scraper
С помощью Thunderbit на базе ИИ легко извлекайте названия товаров, цены и проценты скидок из Sports Direct — без сложной настройки и без программирования.
Узнать больше ->
Скрапер телефонных номеров Craigslist
Скрапер телефонных номеров Craigslist от Thunderbit помогает с помощью ИИ извлекать номера телефонов и детали объявлений из результатов поиска Craigslist. Собирайте объявления, переходите в каждую публикацию, чтобы получить контакты и дополнительные поля, а затем выгружайте данные в Excel, Google Sheets, Airtable, Notion, CSV или JSON.
Узнать больше ->
UNIQLO Scraper
Собирайте данные о товарах UNIQLO — названия, цены и доступные размеры — всего в 2 клика с расширением Thunderbit для Chrome.
Узнать больше ->Готов вывести извлечение данных на новый уровень?
Присоединяйся к 100,000+ профессионалов, которые уже используют Thunderbit для автоматизации веб-скрапинга.
Бесплатный пробный период дает неограниченные кредиты для 8 веб-страниц.