

Является ли веб-скрейпинг незаконным? Это вопрос на миллион долларов, который я слышу от основателей, маркетологов и data-geek’ов каждую неделю.
Сегодня 51% всего интернет-трафика приходится на ботов — впервые автоматический трафик превысил человеческий — и огромная его часть связана с веб-скрейпингом для бизнес-аналитики, продаж и обучения ИИ. Неудивительно, что все пытаются понять, где проходит правовая граница.
В один день вы видите заголовок о решении суда, который признал сбор общедоступных данных допустимым. На следующий — регуляторы предупреждают о «незаконном» сборе данных из социальных сетей. Это сбивает с толку даже тех, кто, как я, каждый день работает над AI web scraping tools в Thunderbit.
Так является ли веб-скрейпинг незаконным? Ответ не сводится к простому «да» или «нет». Все зависит от того, что именно вы собираете, откуда собираете, как используете данные и что говорит закон в вашей стране.
В этом подробном разборе я объясню правовую картину, развею распространенные мифы и поделюсь практическими советами — а также несколькими историями из практики — которые помогут вам соблюдать требования закона, будь вы solo founder или data-команда из списка Fortune 500.
Веб-скрейпинг и закон: есть ли четкая граница?
Если вы надеетесь на ответ в одну строку, сэкономлю вам время: закон пока не провел четкой и однозначной границы для веб-скрейпинга.
Вместо этого мы имеем набор пересекающихся правил — право собственности на данные, приватность, интеллектуальную собственность, антивзломные законы и печально известные Terms of Service (ToS). Все это может иметь значение, а ответ часто зависит от конкретной ситуации (multilogin.com).
Разберем три главных правовых блока:
- Право собственности на данные: как правило, факты и публичная информация (например, цены или номера телефонов) не охраняются авторским правом. Но творческий контент (статьи, изображения) и проприетарные базы данных могут быть защищены — особенно в ЕС, где существуют «права на базы данных» (cliffordchance.com).
- Приватность: современные законы о приватности (например, GDPR в Европе и PIPL в Китае) рассматривают персональные данные как регулируемый актив — даже если они опубликованы публично. Сбор имен, email-адресов или профилей в соцсетях без законного основания может привести к серьезным проблемам (ico.org.uk).
- Договоры (Terms of Service): многие сайты прямо запрещают скрейпинг в своих ToS. Хотя ToS — это не законы, суды могут рассматривать их как обязательные договоры. Их нарушение может обернуться исками, а в некоторых случаях — даже применением антивзломных норм, если вы обходите технические блокировки (cliffordchance.com).
Так является ли веб-скрейпинг незаконным? Иногда да, иногда нет, а чаще — «зависит». Дьявол кроется в деталях.
Сравнение правовых подходов: США, ЕС, Великобритания, Китай
Вот краткая таблица, показывающая, как к веб-скрейпингу подходят крупные регионы:
| Регион | Сбор публичных данных | Сбор личных/частных данных | Применение закона и важные нюансы |
|---|---|---|---|
| США | Как правило, разрешен для публичных данных (см. hiQ v. LinkedIn). Нарушение ToS может привести к гражданским искам. | Ограничен/незаконен, если вы обходите логины или неправомерно используете персональные данные. Могут применяться законы отдельных штатов, например CCPA. | Письма с требованием прекратить действия, блокировка IP, иски. CFAA применяется, если вы обходите технические барьеры. |
| ЕС | Условно разрешен для неперсональных публичных данных. Могут применяться права на базы данных. Закон ЕС об ИИ (2026) вводит требования прозрачности для данных обучения ИИ. | Жестко регулируется GDPR — даже публичные персональные данные требуют законного основания. | Органы по защите данных могут штрафовать за нарушения приватности. Также применяется защита авторских прав и прав на базы данных. Закон ЕС об ИИ запрещает скрейпинг лицевых изображений для ИИ. |
| Великобритания | Похожа на ЕС. Публичные неперсональные данные можно собирать, но нужно уважать права на данные и договоры. | Строгое регулирование персональных данных — действует UK GDPR. Computer Misuse Act криминализует несанкционированный доступ. | ICO может штрафовать за нарушения защиты данных. Суды могут признавать ToS обязательными. |
| Китай | Жестко контролируется. Публичные неперсональные данные можно собирать для внутреннего использования, но среда остается осторожной. | Очень ограничено — PIPL требует согласия на обработку персональных данных. Применяются законы о недобросовестной конкуренции. | Уголовные дела за крупномасштабный скрейпинг. Суды используют нормы о недобросовестной конкуренции для пресечения несанкционированного сбора данных. |
Является ли веб-скрейпинг незаконным? Ключевые правовые факторы
Так что же на самом деле определяет, законен ваш проект по скрейпингу или рискован? Вот главные факторы:
- Публичные vs. частные данные: сбор данных, которые любой может увидеть в открытом интернете, обычно безопаснее. А если нужно заходить через логин, платную стену или обходить технический барьер — это, скорее всего, незаконно (thunderbit.com).
- Характер данных: персональные данные (имена, email, профили) включают режимы защиты приватности. Контент, защищенный авторским правом (статьи, изображения), нельзя копировать целиком. А чистые факты (цены, погода) обычно можно использовать (oxylabs.io).
- Цель использования: внутренний анализ или исследование обычно воспринимаются мягче, чем перепубликация или продажа собранных данных. Если вы используете скрейпинг-данные, чтобы напрямую конкурировать с источником, это почти гарантированно закончится иском (thunderbit.com).
- Соблюдение правил сайта: всегда проверяйте robots.txt и ToS. Robots.txt не имеет обязательной юридической силы, но его лучше уважать. Нарушение ToS может привести к гражданскому иску или к чему-то более серьезному (promptcloud.com).
- Технические меры: важно скрейпить с человеческой скоростью и не обходить средства защиты. Если вы перегружаете сервер или уклоняетесь от CAPTCHA, это может перейти грань и стать похоже на взлом (cliffordchance.com).
Что изменилось в 2024–2026: ключевые судебные дела и регуляторика
Правовая среда вокруг веб-скрейпинга резко изменилась с 2023 года. Вот изменения, которые должен знать каждый, кто занимается скрейпингом:
Крупные судебные решения
-
Meta v. Bright Data (2024): федеральный суд США постановил, что Terms of Service Meta не запрещают сбор публичных данных пользователями без входа в систему. Судья указал, что «посетитель не считается “пользователем”, если у него нет аккаунта». Вскоре после этого Meta отказалась от оставшихся требований. Это важная победа для сбора публичных данных.
-
X Corp v. Bright Data (2024): Twitter (теперь X) проиграл похожий иск, подтвердив тот же принцип: сбор общедоступных данных без входа в систему не нарушает ToS, потому что скрейпер никогда не соглашался с этими условиями.
-
Reddit v. Perplexity AI (октябрь 2025): Reddit подал в суд на Perplexity AI и нескольких поставщиков скрейпинга, сославшись на DMCA и заявив о обходе антибот-систем. Это сигнализирует о новой правовой стратегии: платформы переходят к претензиям по авторскому праву и обходу технических мер вместо CFAA.
-
NYT v. OpenAI (март 2025): федеральный судья разрешил делу The New York Times против OpenAI по авторскому праву двигаться дальше, отклонив ходатайство OpenAI о прекращении дела. Это может стать важным прецедентом в вопросе, считается ли сбор контента для обучения ИИ «добросовестным использованием».
-
Соглашение Anthropic (сентябрь 2025): Anthropic согласилась выплатить $1,5 млрд по групповому иску в США, связанному с использованием защищенных авторским правом текстов для обучения своей модели ИИ — это показывает, что стоимость AI scraping вполне реальна.
Главный тренд: от CFAA к договорному праву и авторскому праву
Картина очевидна: CFAA (Computer Fraud and Abuse Act) теряет силу как оружие против скрейперов публичных данных. Компании, которые пытались использовать CFAA против скрейпинга публичных данных — Meta, X, LinkedIn, — в основном проиграли. Вместо этого правовое поле смещается в сторону:
- договорного права (нарушение ToS, хотя суды говорят, что не-пользователи не обязаны ToS соблюдать)
- претензий по авторскому праву (особенно в отношении данных для обучения ИИ)
- законов против обхода технических мер (DMCA Section 1201)
Для тех, кто занимается скрейпингом, это значит, что правовой риск никуда не исчез — он просто переместился.
Регуляторные изменения
- Обновления CCPA 2026: пересмотренные правила Калифорнии по CCPA вступили в силу 1 января 2026 года, добавив новые нормы для технологий автоматизированного принятия решений (ADMT), оценки рисков и обязанностей data broker’ов.
- Новые законы о приватности в штатах США: Indiana, Kentucky и Rhode Island приняли комплексные законы о приватности, вступившие в силу в 2026 году.
- Закон ЕС об ИИ: полное применение начинается 2 августа 2026 года — требуется раскрывать источники данных для обучения ИИ, соблюдать отказ от использования материалов, защищенных авторским правом, и запрещается скрейпинг лицевых изображений для ИИ-систем.
- AI Accountability for Publishers Act (февраль 2026): предлагаемый закон США, который обязал бы компании ИИ получать разрешение и платить издателям перед тем, как скрейпить их контент.
Политика скрейпинга на крупных платформах: что важно знать
Не все сайты относятся к скрейпингу одинаково. Ниже — сравнение по платформам: что крупнейшие сайты разрешают, что блокируют и что по этому поводу говорят суды.
| Платформа | ToS о скрейпинге | Техническая защита | Юридическое применение | Что практически безопасно |
|---|---|---|---|---|
| Google (Поиск и Maps) | Запрещает автоматический доступ в ToS. У Maps Platform есть прямой пункт «No Scraping». | Проверки SearchGuard JS, CAPTCHA, rate limiting. В 2025 году обновили robots.txt, чтобы блокировать AI crawlers. | В декабре 2025 подал иски против скрейперов, ссылаясь на DMCA. Активно блокирует AI crawlers (Anthropic, Meta, OpenAI). | Сбор общедоступных бизнес-данных Google Maps юридически можно отстаивать (прецедент hiQ), но технические блокировки почти наверняка будут. По возможности используйте официальные API. |
| Amazon | Прямо запрещает любой скрейпинг в Conditions of Use («no robot, spider, scraper, or other automated means»). | Агрессивное определение ботов, CAPTCHA, блокировка IP. robots.txt блокирует всех ботов, кроме Googlebot/Bingbot. С 2025 года отдельно блокирует AI crawlers. | Подал иск против Perplexity AI в ноябре 2025. Регулярно отправляет письма с требованием прекратить нарушения. В марте 2026 обновил BSA с правилами для AI-агентов. | Публичные данные о товарах (цены, карточки) являются фактическими и в США могут быть собраны, но Amazon активно сопротивляется. Ограничивайте частоту запросов и избегайте персональных данных. |
| Запрещает скрейпинг в ToS; для доступа к сервисам требуется согласие пользователя. | Для большей части данных профиля — логин-стены, антибот-детекция, rate limiting. | Дело hiQ подтвердило, что сбор публичных профилей не нарушает CFAA, но LinkedIn выиграл по контрактным требованиям и недобросовестной конкуренции, когда использовались фейковые аккаунты. | Публичные профили, видимые без входа, юридически безопаснее для скрейпинга. Никогда не создавайте фейковые аккаунты и не собирайте данные после входа в систему. | |
| Meta (Facebook и Instagram) | ToS запрещают скрейпинг; отдельные правила действуют для данных из-под логина и без логина. | Для большей части контента — логин-стены, продвинутое обнаружение ботов. | Проиграла Bright Data в 2024 году — суд постановил, что ToS не применяются к скрейперам без входа в систему. От остальных требований отказалась. | Публичные данные (бизнес-страницы, публичные посты), видимые без входа, находятся в более безопасной зоне. Никогда не скрейпьте приватные профили или данные за логин-стеной. |
| X (Twitter) | Обновил ToS в 2023 году, запретив весь скрейпинг и crawling без письменного согласия. Убрал старое исключение для robots.txt. | robots.txt блокирует всех crawlers (Disallow: /). Проверки Cloudflare Turnstile. Жесткие лимиты запросов (300 req/hour). Оценка репутации IP. | Проиграл Bright Data по публичным данным, но очень агрессивно ограничивает технический доступ. | Публичные твиты и профили юридически можно отстаивать, но технические барьеры X в 2026 году — одни из самых жестких. Без premium proxy-инфраструктуры ожидайте блокировки. |
Итог: суды последовательно постановили, что сбор общедоступных данных без входа в систему не нарушает CFAA. Но платформы все равно могут преследовать вас по договорному праву, авторскому праву или нормам о обходе технических мер — и они будут усложнять вам жизнь техническими барьерами. Скрейпьте ответственно.
Данные для обучения ИИ и веб-скрейпинг: новый правовой фронтир
Если вы следите за новостями в 2026 году, то знаете, что сбор данных для обучения моделей ИИ стал самым горячим правовым полем боя. Вот что происходит:
- Иски по авторскому праву множатся. The New York Times, авторы и издатели подали иски против OpenAI, Anthropic и других, утверждая, что массовый скрейпинг защищенного контента для обучения LLM не является «добросовестным использованием». Anthropic в 2025 году урегулировала крупный коллективный иск на $1,5 млрд — это сигнал, что стоимость AI scraping вполне реальна.
- Защита «fair use» выглядит шатко. Суды США пока не вынесли окончательного решения о том, считается ли обучение ИИ на собранных данных добросовестным использованием. Первые решения показывают, что многое зависит от того, как были получены данные и что потом делается с результатом ИИ.
- Грядет новое законодательство. AI Accountability for Publishers Act (внесен в феврале 2026 года) должен обязать компании ИИ получать разрешение и платить издателям перед скрейпингом их контента.
- Закон ЕС об ИИ (полное применение в августе 2026) требует раскрывать источники данных для обучения, уважать машиночитаемые запреты на использование материалов, защищенных авторским правом, и маркировать контент, сгенерированный ИИ. Кроме того, он запрещает ИИ-системы, которые скрейпят лицевые изображения из интернета.
- AI/LLM crawlers стремительно растут. Их доля в веб-трафике выросла с 2,6% до 10,1% всего за восемь месяцев. Один только OpenAI GPTBot вырос на 305%. В ответ крупные сайты (Amazon, Reddit, NYT) обновляют robots.txt, чтобы прямо блокировать AI crawlers.
Что это значит для вас: если вы собираете данные для традиционных бизнес-задач — например, лидогенерации, мониторинга цен или маркетинговых исследований, — эти специфические правила для ИИ могут не применяться напрямую. Но если вы подаете собранные данные в модели ИИ, будьте крайне осторожны и получите юридическую консультацию.
Законы о веб-скрейпинге в мире: краткое сравнение
Сделаем шаг назад и посмотрим, как все это выглядит в глобальном масштабе:
- Соединенные Штаты: полного запрета нет. Скрейпинг публичных сайтов, как правило, законен (hiQ v. LinkedIn), а решения 2024 года по Meta и X Corp еще больше укрепили позицию в пользу сбора публичных данных. Но скрейпинг за логинами или техническими блокировками все еще может вызвать применение CFAA. Сейчас тренд смещается к тому, что компании используют договорное право и претензии по авторскому праву. Законы о приватности быстро ужесточаются: CCPA получила крупные обновления с 1 января 2026 года, включая новые правила для автоматизированного принятия решений и обязанностей data broker’ов. Indiana, Kentucky и Rhode Island также приняли комплексные законы о приватности в 2026 году.
- Европейский союз: строгие законы о приватности. GDPR применяется даже к публичным персональным данным. Права на базы данных могут блокировать масштабный скрейпинг структурированных данных (cliffordchance.com). НОВОЕ: Закон ЕС об ИИ вступает в полное применение 2 августа 2026 года, требуя раскрывать источники данных для обучения и соблюдать отказ от использования материалов, защищенных авторским правом. Закон запрещает скрейпинг лицевых изображений из интернета для ИИ-систем.
- Великобритания: после Brexit в целом следует правилам ЕС. Публичные данные можно собирать, но скрейпинг персональной информации жестко регулируется. Computer Misuse Act может криминализовать несанкционированный доступ.
- Китай: очень жесткое регулирование. PIPL и Data Security Law требуют согласия для персональных данных. Суды используют закон о недобросовестной конкуренции, чтобы блокировать скрейпинг, который наносит ущерб бизнесу (malwarebytes.com).
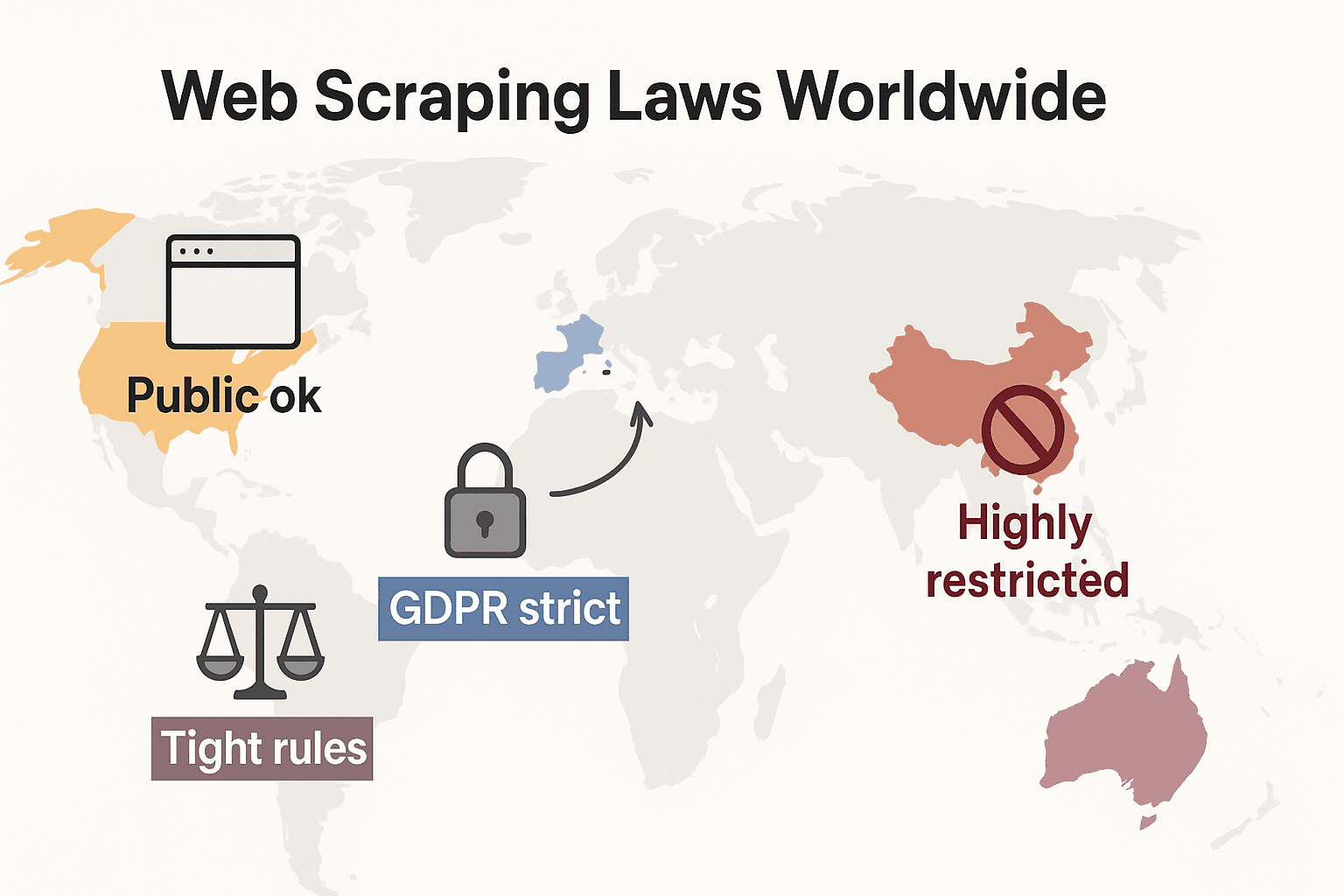
Вывод: безопаснее всего собирать публичные неперсональные данные для внутреннего использования. Все остальное? Проверяйте местные законы и действуйте осторожно.
Распространенные мифы о законности веб-скрейпинга
Разобьем несколько мифов, которые я слышу постоянно:
- Миф 1: «Веб-скрейпинг незаконен в любом случае».
Неверно. Нет закона, который запрещал бы весь веб-скрейпинг. Важны то, как и что вы собираете (oxylabs.io). - Миф 2: «Если данные публичные, я могу делать с ними что угодно».
Не совсем. Публичные данные все еще могут быть защищены законами о приватности или авторским правом, а ToS могут ограничивать определенные способы использования (ico.org.uk). - Миф 3: «Веб-скрейпинг — это то же самое, что хакерство».
Нет. Сбор данных с публичных веб-страниц — не взлом. Другое дело — обход логинов или технических барьеров (calawyers.org). - Миф 4: «Если меня не поймали, значит все нормально».
Опасная логика. Многие сайты используют антибот-технологии и заметят вас. Молчание — не согласие. - Миф 5: «Если я укажу источник или использую данные только внутри компании, это допустимо».
Указание источника не отменяет нормы авторского права или приватности. Внутреннее использование безопаснее, но это не «зеленый свет». - Миф 6: «Любой веб-скрейпинг нарушает приватность».
Не каждый скрейпинг связан с персональными данными. Но массовый сбор личной информации без защитных мер почти всегда незаконен (oxylabs.io). - Миф 7: «Если в ToS сайта запрещен скрейпинг, значит он всегда незаконен».
Не обязательно. В 2024 году суды по делам Meta v. Bright Data и X Corp v. Bright Data постановили, что ToS не могут связывать пользователей, которые на них никогда не соглашались — то есть если вы скрейпите без входа в аккаунт и без создания учетной записи, условия сайта могут на вас не распространяться. Это все еще развивающаяся область права, но сдвиг очень заметный.
Как законно собирать данные: лучшие практики для соблюдения требований
Вот мой основной чеклист для законного и этичного веб-скрейпинга:
- Читайте и соблюдайте Terms of Service сайта. Если там сказано «no scraping», лучше остановиться или запросить разрешение (ql2.com).
- Ограничивайтесь публичными данными. Если нужен пароль, доступ ограничен — не скрейпьте это (thunderbit.com).
- Проверяйте robots.txt и сканируйте вежливо. Это не юридическое обязательство, но хороший тон. Не перегружайте серверы — делайте паузы между запросами (promptcloud.com).
- Избегайте персональных данных, если у вас нет законного основания. Если вам все же нужно их собирать, соблюдайте GDPR/CCPA и минимизируйте объем.
- Не перепубликуйте собранный контент целиком. Добавляйте ценность или анализ, либо получайте разрешение (thunderbit.com).
- Не подавайте собранный контент в модели ИИ без проверки авторского права. Правовая среда меняется очень быстро — если это ваш сценарий, получите совет специалиста.
- Используйте официальные API или выгрузки данных, если они доступны. Они созданы именно для этого и обычно безопаснее (thunderbit.com).
- Будьте прозрачны и подотчетны. Если вы собираете персональные данные, сообщайте об этом людям и ведите журнал действий.
- Минимизируйте данные и защищайте их. Собирайте только то, что нужно, храните точно и обеспечивайте безопасное хранение.
- Следите за изменениями и при спорных случаях консультируйтесь с юристом. Законы и решения судов меняются быстро — особенно Закон ЕС об ИИ и законы штатов США о приватности. Если сомневаетесь, спрашивайте профессионала.
Попробовать расширение Thunderbit для Chrome для соответствующего требованиям скрейпинга
Как легально использовать инструменты для веб-скрейпинга: что важно бизнесу
Инструменты для веб-скрейпинга вроде Thunderbit делают сбор данных доступным даже без навыков программирования, но использовать их все равно нужно ответственно:
- Выбирайте инструменты с упором на compliance. Thunderbit, например, собирает только то, что вы видите в браузере — никаких скрытых API-хаках или несанкционированного доступа (thunderbit.com).
- Ограничивайтесь легитимными сценариями. Внутренняя аналитика, исследование рынка и мониторинг цен конкурентов обычно безопасны. А вот перепубликация или продажа собранных данных — уже значительно рискованнее.
- Настраивайте инструменты с учетом compliance. Устанавливайте задержки между запросами, соблюдайте robots.txt и используйте шаблоны, которые собирают только нужное.
- Держите данные внутри компании. Использовать собранные данные внутри организации безопаснее, чем перепубликовывать их.
- Обучайте команду. Убедитесь, что все понимают правила и best practices.
- Используйте встроенные функции compliance. Thunderbit предупреждает о рискованных сайтах, скрейпит со скоростью, похожей на человеческую, и не хранит ваши данные на своих серверах.
- Не пытайтесь форсировать. Если инструмент не может собрать данные с сайта, не пытайтесь обходить ограничения. Не все данные можно получить без риска.
Подход Thunderbit: безопасный AI Web Scraper для соответствующего требованиям сбора данных
В Thunderbit мы много думали о compliance. Вот как наш AI Web Scraper помогает пользователям оставаться в правовом поле:
- Собирает только то, что вы видите. Thunderbit работает в вашей браузерной сессии, поэтому не может получить данные, которые вы не смогли бы скопировать вручную.
- Предупреждает пользователей. Если вы пытаетесь собрать данные с сайта с жесткой антискрейпинг-политикой, Thunderbit предупредит вас.
- Скорость скрейпинга, похожая на человеческую. Неважно, скрейпите ли вы локально или в облаке, Thunderbit не перегружает серверы.
- Гибкий выбор данных. Наша AI предлагает релевантные столбцы, помогая собирать только нужное.
- Работа с подстраницами и пагинацией. Thunderbit перемещается по сайту как реальный пользователь, соблюдая его структуру.
- Приватность и безопасность. Ваши данные остаются у вас — Thunderbit их не хранит и не переиспользует.
- Экспорты, удобные для compliance. Экспортируйте напрямую в Google Sheets, Airtable, Notion или CSV для безопасного внутреннего использования.
- Планирование и автоматизация. Настраивайте повторяющиеся сборы данных с ответственными интервалами.
- Мультиязычная поддержка. Интерфейс Thunderbit поддерживает 34 языка, делая compliance доступным по всему миру.
- Регулярные обновления шаблонов. Наши instant templates для популярных сайтов обновляются с учетом изменений в законах и технике.
Встраивая compliance в продукт, Thunderbit помогает командам собирать нужные данные — без юридической головной боли.
Двигайтесь на опережение: адаптация к правовым и техническим изменениям в веб-скрейпинге
Изучите больше руководств по веб-скрейпингу Get Started Free
Веб-скрейпинг — это не история по принципу «настроил и забыл». Законы и структура сайтов постоянно меняются. Вот как оставаться впереди:
- Следите за правовыми изменениями. Темп изменений ускорился в 2024–2026 годах — следите за новостями в tech law, обновлениями регуляторов и отраслевыми блогами (например, Thunderbit). Отслеживайте вступление в силу Закона ЕС об ИИ (август 2026), новые законы штатов США о приватности и продолжающиеся дела об авторском праве в сфере ИИ.
- Адаптируйтесь к техническим изменениям. Сайты постоянно обновляют интерфейсы и антибот-защиту. Крупные платформы (Amazon, X, Google) значительно усилили защиту в 2025–2026 годах. AI и templates Thunderbit созданы так, чтобы адаптироваться автоматически.
- Используйте официальные API, если они доступны. Если сайт переходит на платную API-модель, стоит рассмотреть переход ради надежности и compliance.
- Регулярно проверяйте свой скрейпинг. Документируйте источники, отслеживайте изменения ToS или политики и при необходимости корректируйте стратегию.
- Используйте обновления шаблонов Thunderbit. Наша команда поддерживает шаблоны в актуальном состоянии, поэтому вам не нужно беспокоиться о несовместимых изменениях или новых требованиях compliance.
- Сохраняйте гибкость. Если источник данных становится слишком рискованным, переключитесь на другой или ищите партнерство.
С правильными инструментами и подходом вы сможете поддерживать поток данных — не наступая на правовые мины.
Заключение: как ориентироваться в правовом поле веб-скрейпинга
Сам по себе веб-скрейпинг не является незаконным — это мощный инструмент для бизнеса, исследований и инноваций. Но, как и любой инструмент, он подчиняется правилам. Главное — понимать, что именно вы скрейпите, как вы это делаете и что будете делать с данными. Уважайте местные законы, соблюдайте политики сайтов и используйте compliance-oriented tools вроде Thunderbit, чтобы держать работу в правовом поле.
Судебные решения 2024–2026 годов (Meta v. Bright Data, X Corp v. Bright Data) усилили позицию в пользу скрейпинга публичных данных, но одновременно появились новые риски вокруг данных для обучения ИИ, претензий по авторскому праву и Закона ЕС об ИИ. Политики отдельных платформ сильно различаются — Google, Amazon, LinkedIn, Meta и X применяют свои правила по-разному, так что прежде чем скрейпить, изучите ситуацию.
Если сомневаетесь — особенно в больших или чувствительных проектах — получите юридическую консультацию. И помните: правовая среда постоянно меняется, поэтому важно оставаться в курсе и быстро адаптироваться.
Хотите узнать больше о веб-скрейпинге, compliance и автоматизации? Загляните в Thunderbit Blog за новыми материалами или попробуйте расширение Thunderbit для Chrome сами.
Начать соответствующий требованиям веб-скрейпинг с Thunderbit
FAQ
1. Веб-скрейпинг незаконен везде?
Нет. Сам по себе веб-скрейпинг не является незаконным, но его законность зависит от того, что вы собираете, как вы это делаете и где находитесь. Сбор публичных неперсональных данных для внутреннего использования обычно разрешен в большинстве регионов, но сбор персональных или защищенных авторским правом данных, а также нарушение правил сайта, может быть незаконным (oxylabs.io).
2. Делает ли robots.txt скрейпинг незаконным, если я его игнорирую?
Robots.txt не имеет юридически обязательной силы, но его лучше соблюдать. Сам по себе игнор robots.txt не приведет к иску, но в споре может создать впечатление, что вы — «недобросовестная сторона» (promptcloud.com).
3. Могу ли я скрейпить Google, Amazon или LinkedIn?
Это непросто. Все три платформы запрещают скрейпинг в ToS, но суды постановили, что ToS могут не связывать пользователей без входа в систему (см. Meta v. Bright Data и X Corp v. Bright Data, оба дела 2024 года). Сбор общедоступных данных (цены товаров, бизнес-листинги, публичные профили) в США обычно можно отстаивать с юридической точки зрения. Однако каждая платформа применяет правила по-своему: Amazon действует наиболее агрессивно в юридическом плане (в ноябре 2025 года он подал иск против Perplexity AI); LinkedIn опирается на технические барьеры и контрактные требования; Google все активнее использует механизмы на базе DMCA. Всегда скрейпьте ответственно и ожидайте технических контрмер.
4. Могу ли я скрейпить Facebook или Instagram?
После дела Meta v. Bright Data (2024) сбор публичных данных из Facebook и Instagram без входа в систему находится в более сильной правовой позиции. Суд постановил, что ToS Meta не применяются к не-пользователям. Но никогда не создавайте фейковые аккаунты и не собирайте данные за логин-стеной — это уже переход границы.
5. Могу ли я скрейпить X (Twitter)?
X обновил ToS в 2023 году, запретив любой скрейпинг без письменного согласия, и развернул жесткие технические меры защиты (Cloudflare Turnstile, лимиты 300 запросов в час, оценка репутации IP). Однако Bright Data выиграла дело по схожим основаниям — публичные данные, собранные без аккаунта, не связаны ToS X. С технической точки зрения X — одна из самых сложных платформ для скрейпинга в 2026 году.
6. Законно ли собирать данные для обучения ИИ-моделей?
Это самый большой открытый вопрос в 2026 году. Крупные иски (NYT v. OpenAI, соглашение Anthropic на $1,5 млрд) указывают на серьезный правовой риск. Закон ЕС об ИИ требует раскрывать источники данных для обучения и соблюдать отказ от использования материалов, защищенных авторским правом. Предлагаемый AI Accountability for Publishers Act потребует разрешения и оплаты. Если вы скрейпите для обучения ИИ, обязательно получите юридическую консультацию до начала работы.
7. Как безопаснее всего использовать инструменты вроде Thunderbit?
Ограничивайтесь сбором публичных данных, соблюдайте правила сайтов, избегайте личной информации без законного основания и используйте данные внутри компании. Thunderbit создан так, чтобы помогать соблюдать требования: он собирает только то, что видно в браузере, и предупреждает о рискованных сайтах (thunderbit.com).
8. Можно ли собирать данные для коммерческого использования?
Зависит от ситуации. Использование собранных данных для внутренней аналитики или исследований обычно безопаснее. Перепубликация или продажа данных, особенно если они защищены авторским правом или являются персональными, гораздо рискованнее и может требовать разрешения или лицензии.
9. Как следить за правовыми и техническими изменениями в веб-скрейпинге?
Следите за новостями в сфере tech law, отслеживайте изменения ToS и политики целевых сайтов и используйте инструменты вроде Thunderbit, которые регулярно обновляют шаблоны и функции compliance. Главные вещи, за которыми стоит следить в 2026 году: введение в действие Закона ЕС об ИИ (август), продолжающиеся дела по авторскому праву в сфере ИИ и новые законы штатов США о приватности. Если сомневаетесь, проконсультируйтесь с юристом.
Попробовать AI Web Scraper Get Started Free




