

Если вам нужны веб-данные в 2026 году, вопрос уже не в том, «можно ли это распарсить?». Главный вопрос теперь другой: «какой слой инструментов даст мне пригодные данные с минимальными затратами на настройку, поддержку и инфраструктуру?» Поэтому эта страница выстроена по принципу соответствия задаче: AI веб-скрейперы — для скорости, no-code инструменты — для повторяемых браузерных задач, API — для масштаба и обхода антибот-защиты, а Python-библиотеки — для команд, которым нужен полный контроль.
Короткий ответ
- Выбирайте AI веб-скрейпер, если хотите быстрее всего пройти путь от страницы до таблицы при минимальной настройке.
- Выбирайте no-code скрейпер, если вам нужны более явная пагинация, расписание, обработка логина или повторяемый контроль задач.
- Выбирайте API для парсинга, если рендеринг, антибот-защита, параллельность и процент успешного обхода блокировок важнее, чем простота интерфейса.
- Выбирайте Python-библиотеку, если вашей команде нужен полный контроль над запросами, парсингом, браузерной автоматизацией, повторами и деплоем.
Для большинства бизнес-команд ошибка — слишком рано спускаться по стеку. Начните с самого лёгкого инструмента, который стабильно решает задачу, и переходите от AI к no-code, затем к API и к коду только тогда, когда ваш процесс действительно требует этого шага.
Скачать полный визуальный пакет можно здесь: визуальный пакет по инструментам для парсинга сайтов.
Сравнительная таблица: инструменты для парсинга сайтов вкратце
Ниже приведены ценовые сигналы, проверенные по официальным страницам продукта, тарифов или документации 12 мая 2026 года. Если у поставщика используется индивидуальное или помесячное ценообразование по объёму, я описываю именно модель цен, а не пытаюсь натянуть её на фиктивный помесячный эквивалент.
| Инструмент | Категория | Лучше всего подходит для | Почему он попал в этот список 2026 года | Ценовой сигнал (проверено в мае 2026) |
|---|---|---|---|---|
| Thunderbit | AI веб-скрейпер | Продажи, операционные задачи, e-commerce, недвижимость | Самый быстрый путь от веб-страницы к структурированной таблице без технических навыков | Бесплатный тариф, платные уровни, бизнес-цены |
| Kadoa | Платформа извлечения данных на базе AI | Команды по данным и крупные регулярные проекты | Хорошо подходит для самовосстанавливающихся, агентных сценариев извлечения | Бесплатная оценка, тарифы по использованию и корпоративные планы |
| Octoparse | No-code скрейпер | Аналитики и регулярные операционные задачи | Зрелый облачный парсинг и визуальный конструктор задач | Бесплатный тариф, Standard от $69/месяц, более высокие уровни |
| ParseHub | Low-code скрейпер | Технически подкованные пользователи без кода и исследователи | Гибкая логика навигации для сложных сайтов | Бесплатный тариф, платные планы от $189/месяц |
| Web Scraper | Browser no-code скрейпер | Новички и лёгкие повторяемые задачи | Простой sitemap-модуль с опциональным облачным уровнем | Бесплатное расширение, Cloud от $50/месяц |
| Browse AI | No-code robot scraper | Мониторинг и команды, ориентированные на таблицы | Сильный вариант для повторяемого мониторинга и оповещений об изменениях | Бесплатный тариф, платные планы, управляемый уровень |
| Bardeen | AI браузерная автоматизация | Автоматизация GTM и revops | Лучше всего, когда парсинг — лишь один шаг в большом процессе | Бесплатный тариф, Basic от $10/месяц, Premium и Enterprise |
| ScrapeStorm | Визуальный скрейпер с AI-поддержкой | Тем, кому важна быстрая визуальная настройка | Полезный мост между ручными селекторами и AI-помощью | Бесплатная пробная версия, платные планы, корпоративные цены |
| ScraperAPI | API для парсинга | Разработчики, масштабирующие объём запросов | Простой API плюс прокси, CAPTCHA и рендеринг на стороне сервиса | Пробный период 7 дней, платно от $49/месяц |
| Bright Data Web Scraper | Корпоративная платформа для парсинга | Программы с закупками и жёсткими требованиями к соответствию | Самый широкий стек сбора данных в группе | Ценообразование по продукту и по использованию |
| Zyte | API + anti-bot стек | Разработчики и команды по данным | Сильные браузерные действия, JS-рендеринг и ротация IP | $5 кредит на пробный период, тарифы по использованию |
| ZenRows | API для парсинга | Стартапы и команды разработчиков | Чистый anti-bot API с более простым стартом | Бесплатная пробная версия, Developer от $69/месяц |
| ScrapingBee | API для парсинга | Команды, парсящие сайты с тяжёлым JS | Полезен, когда рендеринг — главная боль | Бесплатная пробная версия, платно от $49/месяц |
| Selenium | Open-source браузерная автоматизация | QA-подобные сценарии и задачи с высокой интерактивностью | Всё ещё актуален там, где важна точность пользовательских действий | Бесплатно и с открытым исходным кодом |
| Beautiful Soup | Python-библиотека для парсинга | Лёгкий Python-скрейпинг | Самый простой парсер в стеке для «грязного» HTML | Бесплатно и с открытым исходным кодом |
| Playwright | Современная браузерная автоматизация | Современные веб-приложения и команды разработчиков | Лучший современный выбор для скриптового браузерного парсинга | Бесплатно и с открытым исходным кодом |
| urllib3 | Python HTTP-библиотека | Разработчики, которым нужен низкоуровневый контроль запросов | Полезная основа, если вы хотите напрямую управлять поведением транспорта | Бесплатно и с открытым исходным кодом |
Как выбрать правильный инструмент для парсинга сайтов
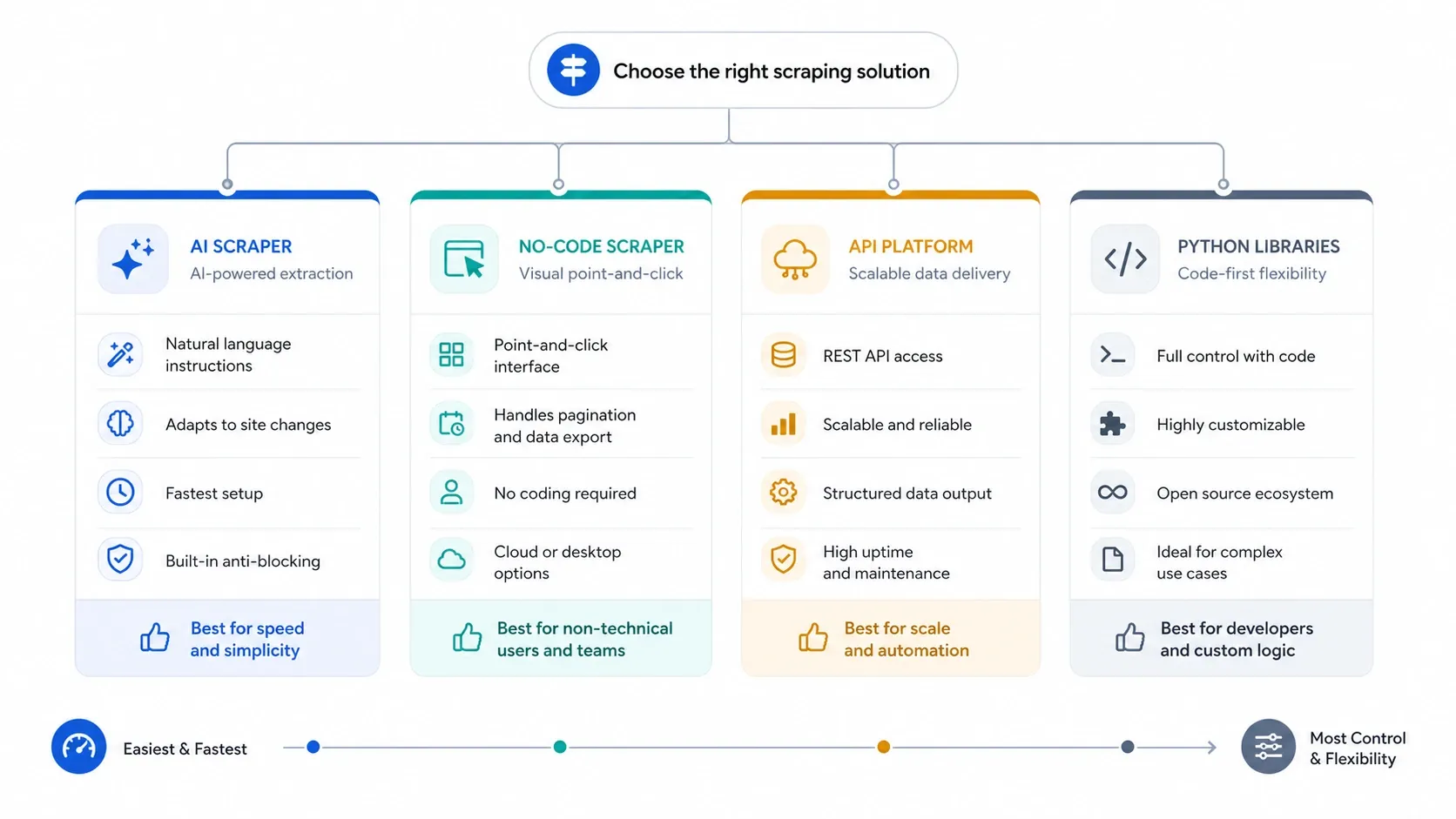
Перед сравнением брендов используйте четыре фильтра:
- Скорость до первого полезного результата
Если инструмент не может быстро выдать реальную таблицу, он уже проигрывает в большинстве бизнес-кейсов. - Нагрузка на поддержку
Дешёвый скрейпер, который ломается при каждом изменении макета, на деле совсем не дешёвый. - Потолок масштаба
Расширение для браузера может идеально подходить для 50 страниц в неделю и быть ужасным для 5 миллионов запросов в месяц. - Соответствие рабочему процессу
Лучший скрейпер для revops редко оказывается лучшим выбором для platform engineer.
Обычно эта схема выбора проще, чем команды себе представляют:
- Если нужно собирать лиды, карточки товаров или страницы продуктов без возни с селекторами, начинайте с AI.
- Если нужны повторяемые задачи, облачные запуски и более явный контроль, переходите к no-code визуальным конструкторам.
- Если настоящая проблема — антибот-защита, рендеринг JavaScript и параллельность, сразу идите в API.
- Если хотите владеть каждым слоем сами, используйте Python-библиотеки и примите нагрузку на поддержку.
Лучшие AI веб-скрейперы для быстрых бизнес-процессов
Это первая категория, которую я бы протестировал, если вам нужны данные, готовые к таблице, и при этом хочется как можно меньше настройки.
1. Thunderbit
Thunderbit по-прежнему самый простой вариант для старта для тех, кто не пишет код. Главное преимущество здесь не просто абстрактный «AI», а то, что продукт сокращает цикл настройки. Вы открываете страницу, просите AI предложить поля, при необходимости обогащаете данные через подстраницы и сразу отправляете результат в инструменты, которыми команда уже пользуется.
- Лучше всего подходит для: поиска клиентов, мониторинга e-commerce, сбора данных о недвижимости и операционных команд, работающих прямо в браузере.
- Почему выделяется: самый быстрый путь от «грязной» страницы к структурированной таблице.
- На что обратить внимание: если вам нужна логика уровня crawler или сильно кастомные инженерные сценарии, в итоге вы перейдёте к API или коду.
- Ценовой сигнал: бесплатный тариф, платные уровни для самостоятельной покупки и бизнес-цены.
Это видео по-прежнему лучший способ быстро понять, достаточно ли AI-подхода для вашего процесса:
Попробовать Thunderbit AI Web Scraper бесплатно
2. Kadoa
Kadoa — более ориентированный на инфраструктуру AI-вариант в этой группе. Он имеет смысл, когда вам нужно самовосстанавливающееся извлечение и регулярные задачи в масштабе, большем, чем обычно могут выдержать браузерные расширения.
- Лучше всего подходит для: команд по данным, внутренних аналитических программ и более крупных повторяющихся нагрузок на извлечение.
- Почему выделяется: агентоподобная оркестрация и более сильная история про сокращение затрат на поддержку.
- На что обратить внимание: он тяжелее, чем нужно большинству бизнес-пользователей для быстрых разовых задач.
- Ценовой сигнал: бесплатная оценка, тарифы по использованию и корпоративные планы.
Лучшие no-code инструменты для парсинга сайтов для повторяемых задач
Как только задача становится регулярной, визуальные конструкторы процессов и облачное выполнение начинают значить больше, чем чистая скорость в один клик.
3. Octoparse
Octoparse остаётся одним из самых убедительных no-code инструментов, когда задача уже больше, чем обычное расширение для браузера, но ещё не является индивидуальным инженерным проектом. Его ценность — в сочетании облачных запусков, шаблонов и зрелого визуального конструктора задач.
- Лучше всего подходит для: аналитиков, ценовых команд и регулярных задач сбора данных, имеющих реальное операционное значение.
- Почему выделяется: больше возможностей, чем у браузерных плагинов, но без необходимости переходить к коду.
- На что обратить внимание: за эту гибкость приходится платить более крутой кривой обучения, чем у AI-first инструментов.
- Ценовой сигнал: бесплатный тариф, Standard от $69/месяц, более дорогие уровни.
Если вы хотите оценить более традиционное no-code пространство перед покупкой AI-first инструмента, этот официальный обзор Octoparse всё ещё полезен:
4. ParseHub
ParseHub по-прежнему актуален, потому что многие команды хотят более пошаговую логику задач, чем даёт лёгкий AI-скрейпер. Это не самый красивый продукт в категории, но он остаётся гибким.
- Лучше всего подходит для: исследователей, журналистов и технически подкованных пользователей без кода, которым не жалко времени на настройку.
- Почему выделяется: более сильная условная логика и контроль навигации, чем у многих инструментов для новичков.
- На что обратить внимание: учиться дольше, и ощущается менее современно, чем новые решения.
- Ценовой сигнал: бесплатный тариф, платные планы от $189/месяц.
5. Web Scraper
Web Scraper — один из более понятных вариантов для тех, кто хочет «освоить основы, не покупая платформу». Если вам нравится модель sitemap, это по-прежнему разумная точка входа.
- Лучше всего подходит для: новичков, хобби-проектов и небольших задач через браузер.
- Почему выделяется: простая настройка и удобный переход от локального расширения к облачным тарифам.
- На что обратить внимание: становится ограниченным, когда нужна более адаптивная логика или более сильная обработка блокировок.
- Ценовой сигнал: бесплатное расширение, Cloud от $50/месяц.
6. Browse AI
Browse AI остаётся сильным выбором, когда одинаково важны и парсинг, и мониторинг. Его модель роботов интуитивно понятна бизнес-пользователям, которые мыслят в духе «следи за этой страницей и сообщай, что изменилось».
- Лучше всего подходит для: мониторинга конкурентов, отслеживания цен и команд, ориентированных на таблицы.
- Почему выделяется: качественный онбординг, повторяемый мониторинг и удобные для автоматизации результаты.
- На что обратить внимание: сложные высоконагруженные задачи могут быстро стать дороже, чем в API-first стеках.
- Ценовой сигнал: бесплатный тариф, платные планы, управляемый уровень.
Для команд, оценивающих мониторинг страниц, а не разовое извлечение данных, этот короткий официальный обзор по-прежнему хорошо показывает суть:
7. Bardeen
Bardeen — это меньше про глубину самого парсинга и больше про то, что происходит после него. Он особенно силён тогда, когда извлечение данных из веба — всего один шаг в более крупном процессе браузерной автоматизации.
- Лучше всего подходит для: GTM ops, маршрутизации лидов, передачи в CRM и автоматизации прямо в браузере.
- Почему выделяется: сильная история автоматизации рабочих процессов вокруг самого парсинга.
- На что обратить внимание: не лучший выбор, если важна только точность извлечения.
- Ценовой сигнал: бесплатный тариф, Basic от $10/месяц, уровни Premium и Enterprise.
8. ScrapeStorm
ScrapeStorm по-прежнему закрывает полезную середину для пользователей, которым нужна помощь AI, но при этом хочется более традиционной визуальной среды для парсинга.
- Лучше всего подходит для: парсинга каталогов, сбора страниц e-commerce и повторяемых визуально настроенных задач.
- Почему выделяется: начать с него проще, чем со многих старых визуальных инструментов.
- На что обратить внимание: он менее отшлифован, чем лидеры категории, и на более сложных сайтах может ощущаться более узким.
- Ценовой сигнал: бесплатная пробная версия, платные планы, корпоративные цены.

Лучшие API для парсинга, когда важны масштаб и обход антибот-защиты
В эту категорию стоит переходить тогда, когда реальное ограничение уже не в том, «как выбрать данные?», а в том, «как сохранить надёжность под нагрузкой?»
9. ScraperAPI
ScraperAPI остаётся одним из самых доступных API-first продуктов для разработчиков, которые хотят перестать думать о прокси и процентах успешных запросов.
- Лучше всего подходит для: разработчиков, которым нужно быстро масштабироваться от прототипа к продакшену.
- Почему выделяется: простой API плюс поддержка прокси, CAPTCHA и рендеринга.
- На что обратить внимание: парсинг, повторы и качество данных на выходе всё равно остаются на вашей стороне.
- Ценовой сигнал: пробный период 7 дней, платно от $49/месяц.
10. Bright Data Web Scraper
Bright Data — тяжеловесный выбор, когда важнее всего способность обходить блокировки, пул прокси, соответствие требованиям и управляемые опции, а не простота.
- Лучше всего подходит для: сбора данных в корпоративном масштабе и программ, чувствительных к требованиям комплаенса.
- Почему выделяется: самый широкий стек в сравнении — от прокси до управляемых продуктов для сбора данных.
- На что обратить внимание: легко купить лишнее, если у команды пока относительно простой процесс.
- Ценовой сигнал: ценообразование по продукту и по использованию.
11. Zyte
Zyte остаётся серьёзным вариантом для команд разработчиков, которым нужны браузерные действия, JS-рендеринг, ротация IP и антибот-позиционирование в рамках одной платформы.
- Лучше всего подходит для: инженерно управляемых программ парсинга и повторяемых систем извлечения.
- Почему выделяется: сильный anti-detection стек и API-first рабочие процессы.
- На что обратить внимание: лучше подходит командам с инженерной ответственностью, чем бизнес-пользователям.
- Ценовой сигнал: $5 кредит на пробный период, тарифы по использованию.
12. ZenRows
ZenRows — один из самых удобных вариантов для разработчиков в API-категории, если вам нужен обход антибот-защиты без корпоративного процесса закупки.
- Лучше всего подходит для: стартапов, разработчиков и компактных внутренних команд.
- Почему выделяется: относительно низкий порог входа плюс сильная антибот-позиция.
- На что обратить внимание: это всё ещё API-продукт, так что логика приложения и QA-нагрузка остаются на вас.
- Ценовой сигнал: бесплатная пробная версия, Developer от $69/месяц.
13. ScrapingBee
ScrapingBee имеет смысл, когда вам в первую очередь нужна отрендеренная страница и меньше инфраструктурной возни, особенно для сайтов с тяжёлым JS.
- Лучше всего подходит для: разработчиков, парсящих динамические сайты и желающих переложить рендеринг на сервис.
- Почему выделяется: простой API вокруг headless-браузинга и прокси.
- На что обратить внимание: он снимает инфраструктурную работу, но не необходимость хорошей логики парсинга.
- Ценовой сигнал: бесплатная пробная версия, платно от $49/месяц.
Лучшие Python-библиотеки для парсинга сайтов в кастомных стеках
Этот набор по-прежнему правильный выбор, когда контроль важнее удобства, а команда готова взять поддержку на себя.
14. Selenium
Selenium — не самый новый браузерный инструмент, но он всё ещё актуален там, где точность пользовательского взаимодействия важнее сырой скорости парсинга.
- Лучше всего подходит для: сценариев с высокой интерактивностью, пересечений с QA и сайтов, где ключевая сложность — поведение браузера.
- Почему выделяется: зрелая экосистема и широкая поддержка браузеров.
- На что обратить внимание: тяжелее и медленнее, чем более новые стеки автоматизации, для многих задач парсинга.
- Ценовой сигнал: бесплатно и с открытым исходным кодом.
15. Beautiful Soup

Beautiful Soup остаётся самым простым парсером в Python-стеке для парсинга сайтов. Это не полноценная платформа для парсинга, но по-прежнему самый простой способ превратить «грязный» HTML в пригодную структуру.
- Лучше всего подходит для: лёгких Python-задач, статических HTML-страниц и быстрых прототипов.
- Почему выделяется: низкая когнитивная нагрузка и forgiving-парсинг.
- На что обратить внимание: используйте вместе с
requests, браузерным слоем или crawler; сам по себе он только парсит. - Ценовой сигнал: бесплатно и с открытым исходным кодом.
16. Playwright
Playwright — мой стандартный современный выбор для команд разработчиков, которым нужна надёжная браузерная автоматизация для сегодняшнего веба.
- Лучше всего подходит для: сайтов с тяжёлым JavaScript, современной браузерной автоматизации и команд, уже уверенно пишущих код.
- Почему выделяется: сильное ожидание загрузки, поддержка нескольких браузеров и чистые API.
- На что обратить внимание: параллельность, селекторы, браузерная инфраструктура и валидация данных всё равно остаются на вашей стороне.
- Ценовой сигнал: бесплатно и с открытым исходным кодом.
17. urllib3
urllib3 попал в список, потому что некоторые команды хотят прямой контроль над поведением транспорта, а не более высокий уровень абстракции. Это не скрейпер для новичков, но это полезная базовая библиотека, когда вы строите свой собственный стек.
- Лучше всего подходит для: разработчиков, которым нужен точный контроль над повторными попытками, прокси, сессиями и HTTP-поведением.
- Почему выделяется: лёгкий, надёжный и широко используемый как инфраструктурный слой.
- На что обратить внимание: большую часть стека вы строите сами.
- Ценовой сигнал: бесплатно и с открытым исходным кодом.
Бесплатные инструменты для парсинга сайтов, которые стоит протестировать в первую очередь
Если хотите протестировать перед покупкой, лучшие бесплатные стартовые варианты в этом списке — Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright и urllib3. Бесплатного опыта обычно достаточно, чтобы понять, какой именно скрейпер вам действительно нужен, а это, как правило, важнее, чем в первый же день зацикливаться на идеальном чек-листе функций.
Мой шорт-лист по типам команд

- Команды продаж, operations и e-commerce: начните с Thunderbit, затем сравните с Browse AI, если мониторинг важнее обогащения через подстраницы.
- Аналитики и команды с регулярной ручной работой: сначала Octoparse, затем ParseHub, если нужна более кастомная логика задач.
- Команды автоматизации GTM: Bardeen, если парсинг должен напрямую попадать в CRM, Sheets или браузерные процессы.
- Команды разработчиков, создающие внутренние инструменты: ScraperAPI, ZenRows, Zyte или Playwright — в зависимости от того, насколько глубоко вы хотите владеть стеком.
- Корпоративные программы по данным: Bright Data и Zyte — более серьёзные инфраструктурные разговоры в этой категории, а Kadoa — AI-альтернатива, когда главная цель — сократить поддержку.
Когда переходить ниже по стеку
Используйте такую схему перехода:
- Оставайтесь на AI веб-скрейперах, пока не упрётесь в ограничения повторяемости или edge-case сценариев.
- Переходите к no-code конструкторам, когда расписание, пагинация и облачное выполнение важнее, чем простота в один клик.
- Переходите к API, когда узким местом становятся процент обхода блокировок, рендеринг и параллельность.
- Переходите к Python-библиотекам, когда абстракция поставщика обходится дороже, чем владение всей системой самим.
Большинство команд делает это в неправильном порядке. Сначала они переусложняют решение, а потом понимают, что более лёгкий инструмент мог бы закрыть реальный рабочий процесс.
Итог
Лучший инструмент для парсинга сайтов в 2026 году — не тот, у которого длиннее список функций. Лучший — тот, который доставляет точные данные в следующий этап процесса с минимальными затратами на поддержку для вашей команды. Именно поэтому AI-first инструменты продолжают выигрывать у операционных команд, no-code решения остаются ценными для повторяемых браузерных задач, API доминируют там, где важны масштаб и блокировки, а Python-библиотеки по-прежнему владеют верхним уровнем контроля в стеке.
Если ваша цель — получить полезные данные уже на этой неделе, начните просто. Если ваша нагрузка уже показывает, что настоящая проблема — это обход блокировок, браузерный рендеринг и инженерный контроль, переходите ниже по стеку осознанно, а не по привычке.
Начните с самого лёгкого скрейпера, который действительно справится с задачей Get Started Free
Часто задаваемые вопросы
1. Какой инструмент для парсинга сайтов лучше всего подходит нетехническим пользователям в 2026 году?
Для большинства нетехнических команд AI-first инструменты вроде Thunderbit и Browse AI по-прежнему дают самый быстрый результат, потому что сокращают время на настройку, работу с селекторами и поддержку.
2. Что выбрать для сайтов с тяжёлым JavaScript или антибот-защитой?
Обычно именно здесь ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright или Selenium становятся разумнее, чем браузерные расширения.
3. Актуальны ли no-code инструменты для парсинга, если AI-скрейперы уже лучше?
Да. Octoparse, ParseHub, Web Scraper и Browse AI по-прежнему важны, когда нужны более явный контроль задач, повторяемые запуски или отладка с видимым браузером.
4. Какие инструменты лучше всего подходят для команд разработчиков?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup и urllib3 — самые естественные варианты, когда процессом владеет инженерная команда.
Похожие материалы




