

Мир меняется 진짜 быстро — и интернет тоже. За годы работы с SaaS и автоматизацией я убедился в одной простой истине: иногда самый короткий путь вперёд — внимательно посмотреть, что уже сделано другими. Анализируете конкурента, запускаете новый продукт или просто хотите иметь резервную копию собственного ресурса — умение клонировать сайт (забрать его контент, структуру или даже часть функциональности) может стать мощным ускорителем для бизнес-команд. А благодаря росту AI-инструментов вроде Thunderbit то, что раньше было «секретным оружием» разработчиков, теперь доступно каждому, у кого есть браузер.
Но давайте честно: клонирование сайта — это не про «Сохранить как…» и забыть. Современные сайты динамичные, интерактивные и порой ускользают так же ловко, как намыленный поросёнок на ярмарке. В этом руководстве я разберу, что на практике означает «клонировать сайт», зачем это нужно бизнес-пользователям, с какими сложностями вы столкнётесь и — главное — как сделать всё безопасно, быстро и законно с помощью продвинутых инструментов вроде Thunderbit.
Клонировать любой сайт: что это на самом деле значит?
Начнём с базы. Когда говорят «клонировать сайт», часто имеют в виду разные вещи:
- Клонировать дизайн: сделать страницу, которая выглядит и ощущается так же, как оригинал.
- Клонировать контент: скопировать тексты, изображения, карточки товаров и другие видимые данные.
- Клонировать функциональность: воспроизвести элементы вроде поиска, форм или интерактивных блоков.
Для большинства бизнес-задач максимальная ценность — в копировании видимого контента и данных: того, что можно увидеть, собрать и проанализировать. Не обязательно вытаскивать серверный код или закрытую логику. Представьте это как «снимок публичной витрины» сайта, превращённый в структурированный набор данных для аналитики, прототипирования или архива.
И заранее отвечу на вопрос: нет, клонирование сайта — не про воровство и не про плагиат. Во многих сценариях это абсолютно легитимно: конкурентная разведка, быстрые прототипы, офлайн-архив для комплаенса. Цель — экономить время и получать инсайты, фиксируя то, что уже работает, а не «изобретать велосипед» или нарушать чьи-то права.
Зачем клонировать любой сайт: ключевые бизнес-сценарии
Вы удивитесь, как много команд используют клонирование сайта в повседневной работе. Вот несколько самых частых кейсов:
| Сценарий | Описание и польза для бизнеса |
|---|---|
| Мониторинг цен конкурентов | Сбор данных с карточек товаров конкурентов для отслеживания цен и наличия. Помогает внедрять динамическое ценообразование — один британский ритейлер получил рост продаж на 4%. |
| Лидогенерация и обогащение CRM | Клонирование каталогов или страниц LinkedIn для сбора лидов. Автоматизация может сэкономить до 80% времени. |
| Переиспользование контента | Копирование FAQ, статей блога или отзывов, чтобы собрать инсайты или переупаковать информацию для своей аудитории. |
| Быстрое прототипирование и дизайн | Клонирование фронтенда существующих сайтов, чтобы быстрее стартовать новые проекты — прототип за дни вместо недель. |
| Резервное копирование и архивирование | Создание полных копий сайтов для комплаенса и хранения истории изменений. |
И это лишь верхушка айсберга. Исследователи могут клонировать страницы соцсетей для анализа трендов, SEO-специалисты — копировать структуру сайта для офлайн-разбора, а почти 2 700 сайтов сравнения цен вообще живут за счёт данных, собранных из интернета. Окупаемость здесь — в скорости и понимании: вместо ручного сбора или пересоздания элементов вы получаете «пакет» сразу.
Сложности клонирования сайтов: это больше, чем копировать-вставить
Если бы клонирование сайта сводилось к «Copy > Paste», этим занимались бы все. Но реальность, как обычно, сложнее.
Почему простое копирование не работает
- Динамический контент: многие сайты подгружают данные через JavaScript, поэтому обычное «Сохранить страницу» часто оставляет вам лишь каркас — без картинок и данных, с поломанной разметкой (пример эксперимента).
- API и скрипты: часть контента подтягивается из API уже после загрузки. Копирование HTML это не захватит.
- Требуется вход: если нужная информация доступна только после авторизации, нужен инструмент, который умеет работать с сессией.
- Защита от скрейпинга: CAPTCHA, лимиты запросов, детект ботов — всё это может блокировать автоматическое копирование.
- Юридические и этические границы: то, что можно скопировать технически, не всегда стоит копировать. Авторские права и условия использования важны — очень.
Итог: клонирование сайта — это одновременно про технические препятствия и про ответственность. Важно не просто «достать данные», а сделать это корректно и этично.
Сравнение решений для клонирования сайтов: от ручных методов до AI-инструментов
Теперь про инструменты для копирования сайтов. Есть несколько основных подходов — у каждого свои плюсы и минусы:
| Метод | Простота | Точность | Динамический контент | Экспорт | Юридическая аккуратность | Поддержка/обслуживание |
|---|---|---|---|---|---|---|
| Ручное копирование/скачивание | Средняя | Низкая | Плохо | HTML/CSS/JS | Зависит от пользователя | Высокая (легко ломается) |
| Классический веб-скрейпинг | Низкая | Высокая* | Хорошо* | CSV/Excel/JSON | Зависит от пользователя | Высокая (хрупко) |
| AI-инструменты (Thunderbit) | Очень высокая | Высокая | Отлично | Excel/Sheets/Notion | Понятно для пользователя | Низкая |
*Если вы понимаете, что делаете, и правильно всё настроили.
Ручное копирование/скачивание
Инструменты вроде HTTrack или функция браузера «Сохранить страницу как…» подходят для простых статичных сайтов, но это трудоёмко и почти всегда ломается на динамике. Часто вы получаете пропавшие изображения, слетевшие стили и папку файлов, в которой сложно разобраться — полный хаос, как говорят корейцы, 완전 멘붕.
Классический веб-скрейпинг
Сюда относятся скрипты (Python, BeautifulSoup и т. п.) или визуальные скрейперы, где вы кликами задаёте, что извлекать. Это мощно, но требует кода или долгой настройки. А поддержка — отдельная боль: сайт поменялся, и ваш скрейпер, скорее всего, сломался. В реальном мире это часто превращается в бесконечное «почини-обнови-перепроверь».
AI-инструменты (Thunderbit)
Вот где начинается самое вкусное. Thunderbit использует AI, чтобы «понимать» страницу — вам не нужно вручную описывать каждую мелочь. Нажимаете “AI Suggest Fields” (или “AI Suggest Columns”), AI сам предлагает поля, и вы сразу начинаете сбор. Инструмент справляется с динамическим контентом, переходами по страницам и экспортирует данные прямо в Excel, Google Sheets, Airtable или Notion. И всё это рассчитано на пользователей без технического бэкграунда — без кода, без лишней возни.
Если хотите глубже разобраться в Chrome-расширениях для Web Scraper, посмотрите это сравнение.
Пошагово: как клонировать любой сайт с помощью Thunderbit
Как собирать данные с любого сайта с помощью AI Get Started Free
Готовы перейти к практике? Ниже — как я обычно делаю клонирование сайта с Thunderbit шаг за шагом.
Шаг 1: Установите и настройте Thunderbit
Сначала зайдите на сайт Thunderbit и зарегистрируйте бесплатный аккаунт. Затем установите Thunderbit AI Web Scraper Chrome Extension. Это так же просто, как поставить любое другое расширение — буквально пару кликов, и готово.
После установки значок Thunderbit появится на панели Chrome. Нажмите на него, войдите в аккаунт — и можно начинать первый проект. Маленький 꿀팁: закрепите иконку расширения, чтобы она всегда была под рукой. Если вы собираете данные с сайта, где нужен логин, заранее войдите на этот сайт — Thunderbit использует текущую сессию браузера.
Попробовать Thunderbit AI Web Scraper бесплатно
Шаг 2: Пусть AI определит и структурирует данные
Откройте сайт, который хотите «клонировать» (например, страницу товара конкурента). Запустите боковую панель Thunderbit и создайте новый проект. Дальше — самое приятное: нажмите “AI Suggest Columns” (иногда “AI Suggest Fields”), и AI просканирует страницу, автоматически предложив набор полей — например, Название товара, Цена, URL изображения, Рейтинг и т. д.
Поля можно проверить, отредактировать или добавить свои. Хотите ещё «Наличие» или «SKU»? Просто добавьте колонку — AI постарается заполнить. Знания HTML не нужны: всю «грязную работу» делает AI, а вы фокусируетесь на том, что реально важно.
Шаг 3: Соберите данные и экспортируйте
Когда колонки готовы, нажмите “Scrape” (или “Start”). Thunderbit извлечёт данные по выбранным полям построчно. Если на странице список (например, каталог товаров), он соберёт всё.
А что с пагинацией или бесконечной прокруткой? В большинстве случаев Thunderbit справляется автоматически: есть кнопка “Next” или подгрузка при скролле — он продолжит. В редких сложных сценариях может понадобиться прокрутить вручную или включить расширенные настройки, но для большинства бизнес-сайтов всё проходит гладко, без лишнего 스트레스.
После завершения вы увидите данные в аккуратной таблице. Экспорт — без лишних движений: сразу в Excel, Google Sheets, Airtable или Notion. Никаких «танцев с CSV» — только структурированные данные, готовые к работе.
Подробнее — в гайде Thunderbit по сбору данных с любого сайта с помощью AI.
Усиливаем «клон»: сбор данных с подстраниц для полной картины
Сбор данных с подстраниц в Thunderbit Get Started Free
Здесь Thunderbit особенно силён: сбор данных с подстраниц. На главной странице часто есть только краткие сведения (название и цена), а «вкусные» детали — описание, характеристики, отзывы — спрятаны на отдельных страницах.
Функция subpage scraping позволяет копнуть глубже. Включаете её — и AI переходит по ссылкам с основной страницы на каждую карточку, забирает дополнительные поля и объединяет их в общий датасет. Например, если вы делаете клонирование сайта в формате «категория интернет-магазина “зимние куртки”», Thunderbit может зайти в карточку каждой модели и собрать материалы, наличие, отзывы и многое другое — в итоге вы получаете полный структурированный «клон» всего набора товаров.
Для бизнеса это огромная экономия времени. Собираете базу лидов, архивируете базу знаний или анализируете каталог — subpage scraping помогает ничего не упустить и не возвращаться по десять раз.
Реальный пример — как работает subpage scraping в Thunderbit.
Комплаенс: как клонировать любой сайт законно и безопасно
Поговорим о главном вопросе: законно ли клонировать любой сайт?
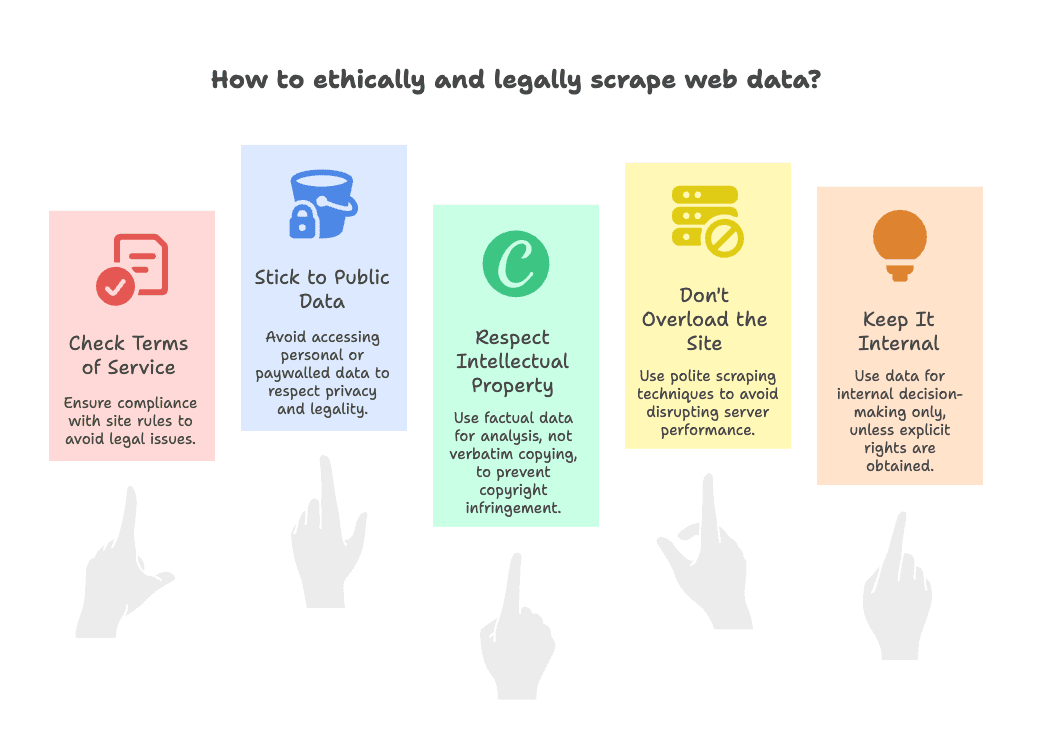
Короткий ответ: чаще всего да — если соблюдать базовые правила здравого смысла. Мой чек-лист:
- Проверьте Terms of Service: некоторые сайты прямо запрещают веб-скрейпинг. Если так — действуйте осторожно и используйте данные внутри компании, а не для публичной перепубликации (о юридических рисках).
- Собирайте только публичные данные: берите то, что видно без входа. Избегайте персональных данных, email и всего, что за paywall (юридические ориентиры).
- Уважайте интеллектуальную собственность: факты (цены, названия) обычно ок. А вот дословное копирование творческого контента (статьи, изображения) может нарушать авторские права — используйте для анализа, а не для создания «сайта-клона» (про IP).
- Не перегружайте сайт: скрейпьте «вежливо» — не отправляйте тысячи запросов за секунды. В Thunderbit есть ограничение скорости, но всё равно будьте аккуратны (про robots.txt).
- Держите данные внутри: если у вас нет явных прав, используйте собранное для внутренних решений, а не для публичного распространения.
Thunderbit помогает соблюдать порядок тем, что позволяет выгружать данные напрямую в защищённые рабочие инструменты вроде Google Sheets или Airtable — так проще управлять доступом и совместной работой. Больше советов — в подробном юридическом гайде.
Продвинутые советы: как выжать максимум из Thunderbit при клонировании сайтов
Когда базовые шаги освоены, вот несколько приёмов, которые помогут поднять клонирование сайта на новый уровень:
- Работа с динамичными и интерактивными сайтами: если контент появляется после действий (например, “Show All Reviews”), выполните действие вручную и затем запускайте Thunderbit — AI соберёт то, что видно. Для бесконечного скролла прокручивайте порциями или используйте поддержку пагинации (ещё советы).
- Кастомные AI-подсказки: помогайте AI точными названиями колонок — например, «Автор (текст после By:)» или «Краткое резюме плюсов». AI Thunderbit хорошо понимает контекст, поэтому понятные названия работают как мини-инструкции (примеры).
- AI для преобразования данных: используйте функцию AI Summarize в Thunderbit или подключайте инструменты вроде ChatGPT, чтобы на лету анализировать, классифицировать или переводить данные (идеи интеграций).
- Расписание для регулярных «клонов»: настройте плановые сборы, чтобы отслеживать изменения со временем — идеально для мониторинга цен или новых вакансий (про облачный скрейпинг).
- Массовый сбор по списку URL: загрузите список ссылок — Thunderbit пройдётся по каждой автоматически. Удобно, если ссылки вы уже собрали где-то ещё.
- Шаблоны для популярных сайтов: используйте готовые шаблоны Thunderbit для Amazon или Zillow и при необходимости донастройте (детали про шаблоны).
- Сложные случаи: если упираетесь в CAPTCHA или странную вёрстку, попробуйте собирать в два прохода или скорректируйте колонки. AI у Thunderbit устойчивый, но быстрая проверка результата всегда полезна.
Для ещё более продвинутых сценариев посмотрите API и варианты интеграций Thunderbit.
Клонируйте любой сайт с Thunderbit AI
Итоги: клонируйте любой сайт уверенно
Клонирование сайта — больше не привилегия разработчиков. Это практичный и доступный подход, который помогает бизнес-пользователям в продажах, маркетинге и операциях. Главное, что стоит запомнить:
- Польза для бизнеса: клонирование сайта даёт ощутимый ROI — помогает обгонять конкурентов, экономить время и принимать более точные решения (статистика отрасли).
- Сложности и решения: современные сайты сложные, но продвинутые инструменты для копирования сайтов вроде Thunderbit делают клонирование точным, быстрым и простым даже без технических навыков.
- Преимущество Thunderbit: функции “AI Suggest Columns” и сбор с подстраниц превращают часы ручной работы в процесс «в два клика».
- Комплаенс важен: действуйте ответственно — берите публичные данные, уважайте IP и используйте информацию для анализа или внутренних решений.
- Идите дальше: с продвинутыми советами и интеграциями Thunderbit справится даже с самыми «капризными» сайтами и процессами.
Так что в следующий раз, когда вы смотрите на страницу товара конкурента, каталог лидов или базу знаний, которую хочется проанализировать, помните: у вас есть инструменты, чтобы уверенно клонировать сайт на уровне данных. Пользуйтесь этой силой разумно — и пусть ваши проекты на данных приносят результат.
Попробовать Thunderbit AI Web Scraper сейчас Get Started Free
FAQ
1. Законно ли клонировать любой сайт для бизнес-задач?
В целом — да, если вы ограничиваетесь публичными данными, уважаете интеллектуальную собственность и используете информацию внутри компании. Всегда проверяйте условия использования сайта и не собирайте персональные или защищённые авторским правом материалы без разрешения. Подробнее — в юридическом гайде.
2. Чем отличается клонирование сайта от скрейпинга?
Клонирование сайта обычно подразумевает создание копии контента, структуры или дизайна, а веб-скрейпинг — это извлечение конкретных данных. С инструментами вроде Thunderbit граница размывается: вы можете собрать и структурировать данные так, что фактически «клонируете» нужные части.
3. Умеет ли Thunderbit работать с динамическим контентом и подстраницами?
Да. AI Thunderbit рассчитан на динамический контент (например, данные, подгружаемые JavaScript) и умеет переходить по ссылкам, собирая данные с подстраниц и объединяя всё в один датасет. Это один из самых простых способов получить «полный клон» нужной части сайта.
4. Как выгрузить клонированные данные в Excel или Google Sheets?
После сбора в Thunderbit вы можете экспортировать данные напрямую в Excel, Google Sheets, Airtable или Notion — буквально в пару кликов. Никакой ручной подготовки: данные сразу готовы к анализу и шарингу.
5. Какие есть продвинутые советы для сложных сайтов?
Используйте кастомные AI-подсказки для точного извлечения полей, настраивайте регулярные сборы по расписанию, а также применяйте массовый сбор по URL и шаблоны Thunderbit для ускорения. Для интерактивных страниц сначала выполните действия вручную, затем запускайте сбор — и обязательно проверяйте результат на точность.




