

У YouTube более 2 миллиардов пользователей в месяц и более 500 часов видео загружается каждую минуту. Это одна из самых непростых платформ для парсинга: на пути встают CAPTCHA, ошибки 429 и даже прямые IP-баны.
Если вы когда-либо пытались собирать данные каналов, комментарии или расшифровки хоть в сколько-нибудь серьёзном объёме, то знаете, насколько это бесит. Сначала у вас набирается несколько сотен результатов, а потом YouTube просто захлопывает дверь. Я потратил немало времени на то, чтобы сравнить, как разные подходы к парсингу справляются с постоянно меняющейся антибот-защитой YouTube, и разница между инструментами, которые держатся стабильно, и инструментами, которые блокируются за пару минут, колоссальная.
В этом руководстве собраны 6 лучших парсеров YouTube на 2026 год — инструменты, которые действительно рассчитаны на работу с жёсткой защитой YouTube, не сжигая ваш IP и не ломая рабочий процесс. Неважно, маркетолог вы, который отслеживает каналы конкурентов, sales-команда, которая ищет контакты авторов, или разработчик, строящий конвейер данных, — здесь найдётся подходящий вариант.
Что именно блокирует YouTube в 2026 году и почему большинство парсеров проваливаются
Антибот-защита YouTube — это не одна стена, а многоуровневая система. Понять, с чем вы имеете дело, — первый шаг к тому, чтобы не нарваться на блокировку.
Вот что YouTube делает в 2026 году, чтобы выявлять и останавливать автоматический доступ:

- Проверка репутации и скорости IP: повторяющиеся запросы с дата-центровых IP, VPN или общих прокси быстро вызывают подозрение. Вы увидите ошибки 403, лимиты 429 или экраны с просьбой «войти, чтобы подтвердить, что вы не бот».
- Браузерный и JavaScript-фингерпринтинг: YouTube проверяет, ведёт ли клиент себя как настоящий браузер — выполняет ли скрипты, рендерит ли элементы и сохраняет ли ожидаемое состояние. Headless-браузеры и обычные HTTP-клиенты часто проваливают эти проверки незаметно (вы просто получаете пустые или частичные данные).
- Доверие к cookie и сессии: если запросы идут не из распознанной, долго живущей браузерной сессии, YouTube усиливает проверку. Вход в аккаунт с историей браузинга вызывает больше доверия, чем свежая анонимная сессия.
- Поведенческий анализ: одинаковые интервалы запросов, слишком быстрое прокручивание или повторяющиеся шаблоны страниц запускают ограничение скорости. YouTube ищет действия, которые человек бы не совершал.
- CAPTCHA-барьеры: когда риск высок, YouTube требует ручную проверку — особенно в поисковой выдаче и разделах комментариев.
- Контроль квот API: официальный YouTube Data API использует дневные квоты на уровне проекта (по умолчанию 10 000 единиц в день), а поисковые сценарии могут сжечь их за считаные минуты.
Обычно всё выглядит так: вы запускаете сбор, получаете несколько сотен результатов, а затем упираетесь в Error 429, CAPTCHA-стену или тихо испорченные данные. Облачные парсеры, работающие с дата-центровых IP, особенно уязвимы.
| Метод обнаружения | Что делает | Как это выглядит для пользователя | Инструменты, снижающие риск |
|---|---|---|---|
| Репутация/скорость IP | Помечает дата-центровые/VPN/общие IP | 403, 429, подтверждение бота | Парсинг в браузерной сессии, residential-прокси |
| JS-фингерпринтинг | Проверяет, работает ли реальный браузер | Тихо пропавшие данные, CAPTCHA | Расширение для реального браузера, полный рендер |
| Доверие к cookie/сессии | Сравнивает с вошедшими профилями | «Войдите, чтобы подтвердить» | Cookie пользователя, авторизованная сессия |
| Поведенческий анализ | Выявляет неестественные паттерны | Ограничение скорости после ~200 строк | Человекообразные задержки, случайность, небольшие пачки |
| Контроль квот API | Ограничивает дневные лимиты API | 403 quotaExceeded | Использовать парсеры для поиска/комментариев, API — для точечных запросов |
| CAPTCHA-барьеры | Принуждает к ручной проверке | Извлечение останавливается посреди запуска | Браузерная сессия, прокси/антиблок, более медленный темп |
Главный вывод: инструменты, которые работают внутри настоящей браузерной сессии (например, Thunderbit), естественным образом обходят многие из этих проверок, потому что запрос выглядит как обычный просмотр YouTube человеком. Облачным парсерам нужны ротация прокси, решение CAPTCHA и аккуратный темп, чтобы выжить.
Попробовать Thunderbit для парсинга YouTube
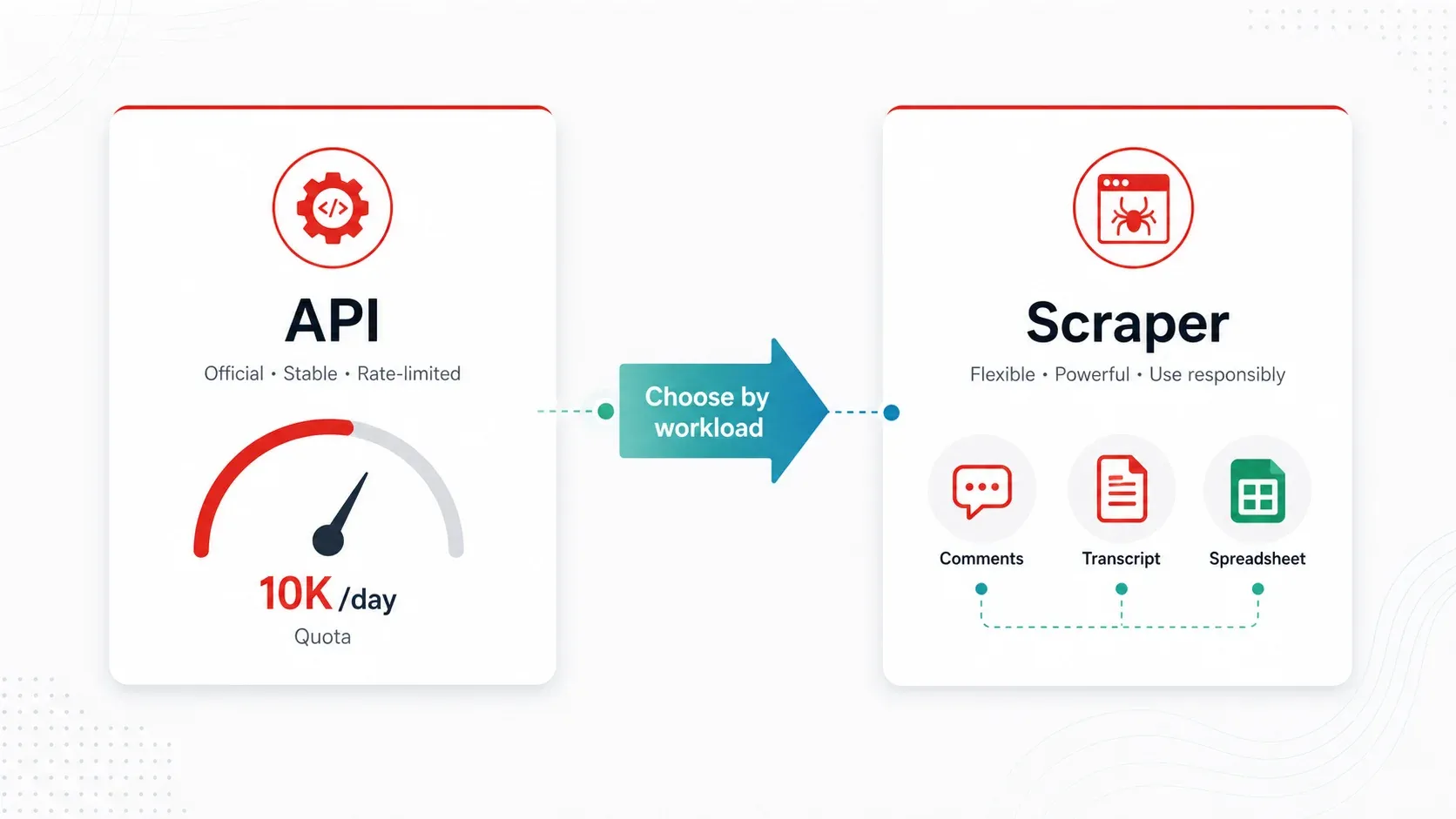
YouTube API против лучших парсеров YouTube: практическая схема выбора
YouTube Data API v3 — это «официальный» способ программного доступа к данным YouTube. Он надёжен для базовых метаданных при небольших объёмах, но модель квот делает его неудобным для большинства реальных задач конкурентной аналитики и исследований.
Вот арифметика. Каждый проект API получает 10 000 квотных единиц в день. Стоимость ключевых эндпоинтов:
search.list= 100 единиц за страницу (максимум 50 результатов на страницу)videos.list= 1 единица за вызов (до 50 video ID за вызов)commentThreads.list= 1 единица за вызов (до 100 тредов за вызов)
То есть если вы делаете 100 поисковых запросов по ключевым словам в день, вы расходуете всю дневную квоту ещё до того, как обогатите хотя бы одно видео. Сценарий, ориентированный на комментарии, дешевле за один вызов, но реальная пагинация, отключённые комментарии и раскрытие ответов быстро съедают доступную ёмкость.
Когда API достаточно:
- вам нужно меньше 100 видео в день и только публичные метаданные (название, просмотры, лайки, длительность)
- у разработчика есть возможность настроить OAuth и управлять квотой
Когда лучше парсер:
- вам нужны комментарии в масштабе (API работает, но квотные ограничения ощутимы)
- вам нужны расшифровки/субтитры в виде текста (API не выдаёт текст субтитров удобно для массового использования)
- вы регулярно отслеживаете 100+ каналов (квота быстро заканчивается, планирование вручную)
- вам нужны обогащённые или размеченные данные (категоризация, перевод, AI-определение полей)
- вы не технический пользователь и просто хотите таблицу
API также не показывает всё, что видно на сайте: данные из блока Shorts, публичные email-адреса из описаний каналов, посты сообщества и часть метаданных канала доступны только через парсинг самих страниц YouTube.
Собирайте данные YouTube с помощью AI Get Started Free
Для большинства бизнес-пользователей, которые занимаются конкурентным исследованием, поиском авторов или контент-стратегией, парсер практичнее, чем API.
Как мы отобрали 6 лучших парсеров YouTube
Каждый инструмент в этом списке мы оценивали по одним и тем же критериям — с упором на то, что действительно важно, когда YouTube активно пытается вас заблокировать:
| Критерий | Почему это важно |
|---|---|
| Надёжность против банов | Главная боль пользователей — лимиты и IP-баны в масштабе |
| Стоимость за 1 000 результатов | Нормализованная цена позволяет сравнивать инструменты честно |
| Поддерживаемые типы данных | Метаданные, комментарии, расшифровки, Shorts, миниатюры — у разных инструментов набор отличается |
| Масштабируемость | Справится ли инструмент со 100+ каналами или 10K+ видео без падений? |
| Простота настройки | Тем, кто парсит впервые, нужны понятные no-code-решения |
| Форматы экспорта | CSV, JSON, Google Sheets, Airtable — для разных процессов нужны разные форматы |
| Объём поддержки | YouTube меняется, инструменты ломаются — кто их чинит? |
Все инструменты мы тестировали на актуальных паттернах блокировок YouTube, с которыми сталкиваются пользователи в 2026 году.
1. Thunderbit
Thunderbit — это AI-расширение для Chrome, которое превращает страницы YouTube в структурированные данные примерно за два клика. Вместо работы с облачного сервера, который YouTube легко распознаёт, Thunderbit работает внутри вашей собственной браузерной сессии — поэтому для YouTube это выглядит как обычный просмотр страниц.
Базовый сценарий для YouTube: установите расширение Thunderbit для Chrome, откройте страницу канала YouTube, страницу результатов поиска или страницу видео и нажмите «AI Suggest Fields». AI читает страницу и предлагает столбцы — название видео, URL, просмотры, дату загрузки, описание, URL миниатюры, текст комментария, автора, лайки и многое другое. Вы проверяете, нажимаете «Scrape» и экспортируете данные напрямую в Google Sheets, Excel, Airtable, Notion, CSV или JSON. Никакого кода, никаких селекторов, никаких API-ключей.
Ключевые возможности для парсинга YouTube:
- AI-определение полей: AI Thunderbit читает любую страницу YouTube, на которой вы находитесь, и автоматически предлагает подходящие столбцы. Не нужно вручную настраивать CSS-селекторы или XPath.
- Парсинг подстраниц: сначала соберите список видео канала, а затем заходите на страницы каждого видео, чтобы дополнить данные комментариями, описаниями, тегами и расшифровками, если они видны.
- Планируемый парсинг: настройте повторяющиеся задачи, чтобы отслеживать каналы еженедельно без ручного участия.
- Browser Mode: работает в вашей авторизованной браузерной сессии, уменьшая отпечаток «облачный дата-центровый IP», который запускает большинство блокировок YouTube.
- Бесплатный экспорт: данные можно отправлять в Google Sheets, Excel, Airtable или Notion без платного барьера на экспорт.
Подход к обходу банов: парсинг в браузерной сессии с использованием авторизованной сессии пользователя. YouTube видит реальный браузер, реальные cookie и реальную историю сессии. Для больших объёмов более мелкие запланированные пакеты ещё сильнее снижают риск.
Цена: бесплатный тариф (6 страниц), пробный буст (10 страниц). Платные тарифы работают по кредитной модели. Актуальные цифры смотрите на странице ценообразования Thunderbit.
Лучше всего подходит для: маркетологов, sales-команд, контент-стратегов и операционных специалистов, которым нужен быстрый анализ каналов, поиска и комментариев без технической настройки.
Как парсить YouTube с Thunderbit (пошагово)
- Установите расширение Thunderbit для Chrome.
- Откройте страницу канала YouTube, результаты поиска, плейлист или страницу видео.
- Нажмите «AI Suggest Fields» — AI прочитает страницу и предложит столбцы (название, URL, просмотры, дата, описание, миниатюра и т. д.).
- Проверьте и при необходимости скорректируйте предложенные поля.
- Нажмите «Scrape» — данные будут извлечены в структурированную таблицу.
- Экспортируйте в Google Sheets, Excel, Airtable, Notion, CSV или JSON.
Для более глубокого извлечения данных, например комментариев по каждому видео канала, используйте парсинг подстраниц: сначала соберите список видео, а затем дайте Thunderbit посетить каждую страницу видео и извлечь комментарии, описания или доступность расшифровки.
Весь процесс занимает меньше двух минут для типовой задачи исследования канала. Никаких API-ключей, никакой настройки прокси, никакого кода.
Попробовать Thunderbit на YouTube в 2 клика
2. Apify
Apify — это облачная платформа для парсинга с готовыми YouTube «Actors» — специализированными парсерами для видео, комментариев, каналов, Shorts и расшифровок. Она создана для разработчиков, которым нужны автоматизированные конвейеры данных, а не разовые исследования.
Экосистема Apify для YouTube включает отдельные Actors для разных задач. Хорошо поддерживаемый Actor под названием «YouTube Scraper — Videos, Comments & Transcripts» принимает каналы, плейлисты, поисковые запросы и прямые URL видео. Он поддерживает фильтрацию Shorts, сбор комментариев и расшифровки с временными метками.
Ключевые возможности:
- Отдельные Actors для видео, комментариев, каналов, Shorts и расшифровок
- Принимает поисковые запросы, URL каналов и ID плейлистов в качестве входных данных
- Облачное планирование и интеграции через webhook
- Экспорт в JSON, CSV, Excel или отправка в базы данных через API
- Управление скоростью на уровне Actor и ротация прокси
Подход к обходу банов: индивидуальный темп для каждого Actor, прокси-инфраструктура Apify и доступ к внутреннему API YouTube (Innertube), где это применимо. Каждый Actor реализует собственную логику повторов и ограничения скорости.
Цена: указанный Actor YouTube Scraper стоит примерно $15 за 1 000 видео, $8 за 1 000 комментариев и $5 за расшифровку. Тарифы платформы начинаются от $49/месяц.
Недостатки: расходы быстро растут на крупных задачах. Интерфейс ориентирован на разработчиков — нетехническим пользователям он может показаться сложным. Схемы выходных данных отличаются между Actors, поэтому часто требуется очистка данных. Качество Actors на маркетплейсе разнится.
Лучше всего подходит для: разработчиков, строящих автоматизированные конвейеры данных, команд, которым нужно плановое извлечение в API или базы данных, и marketing-ops-команд, запускающих регулярные workflows по анализу комментариев.
3. Bright Data
Bright Data — это enterprise-платформа data infrastructure с крупнейшей в отрасли сетью residential-прокси и отдельными парсерами для YouTube. Если вам нужно собирать данные YouTube в огромном масштабе по разным географиям, это тяжёлая артиллерия.
Bright Data предлагает несколько парсеров YouTube (профили каналов, видео, комментарии), а также готовые наборы данных YouTube для покупки. Их managed scraping service означает, что они создают и поддерживают парсер за вас.
Ключевые возможности:
- 150M+ residential IP в 195 странах
- Специальные парсеры YouTube для каналов, видео и комментариев
- Полный браузерный рендеринг и решение CAPTCHA
- Геотаргетированный парсинг (сравнение результатов YouTube по странам)
- Опция управляемого сервиса (поддержку берут на себя они)
- Пакетная обработка до 5K URL за запрос
Подход к обходу банов: огромный пул residential-прокси, автоматическая ротация IP, эмуляция браузерного фингерпринта и встроенное решение CAPTCHA. Это самая сильная инфраструктура против блокировок в этом списке.
Цена: бесплатный пробный период (1K запросов на одну неделю), pay-as-you-go от $3.50 за 1K записей, тариф Scale — $499/месяц с 384 000 записей и $2.30 за каждые дополнительные 1K.
Недостатки: избыточно для небольших проектов. Сложное ценообразование (трафик + запросы + IP могут вызвать неприятный сюрприз в счёте, если лимиты не заданы). Платформа требует больше настройки, чем расширение для Chrome.
Лучше всего подходит для: крупных компаний, агентств, отслеживающих сотни каналов, и команд, которым нужны геоспецифичные данные YouTube в enterprise-масштабе.
4. Octoparse
Octoparse — это десктопный и облачный инструмент для парсинга с визуальным интерфейсом point-and-click. Вы строите workflows для извлечения данных из YouTube, просто нажимая на элементы страницы — без кода, но с большей гибкостью, чем у простого расширения.
У Octoparse есть готовые шаблоны для YouTube, включая YouTube Comments & Replies Scraper, обновлённый в апреле 2026 года. Он извлекает имя пользователя, текст комментария, лайки, время публикации и цепочки ответов из URL видео.
Ключевые возможности:
- Визуальный no-code-конструктор workflows — нажимайте на элементы, чтобы задать логику парсинга
- Готовые шаблоны YouTube для комментариев, результатов поиска и метаданных видео
- Облачное планирование с автоматической ротацией прокси
- Экспорт в Excel, CSV, JSON и подключения к базам данных
- Встроенная ротация IP и антидетекция в облачных планах
Подход к обходу банов: облачное выполнение с встроенной ротацией IP и мерами антидетекции. Шаблоны справляются с бесконечной прокруткой и динамической загрузкой на типовых страницах YouTube.
Цена: шаблон YouTube comments указан по цене $0.20 за 1 000 строк. Тарифы платформы начинаются примерно от $75/месяц (Standard, при ежегодной оплате) и включают облачные серверы, планирование и опции прокси.
Недостатки: сложные страницы YouTube (бесконечная прокрутка, лениво подгружаемые комментарии, вкладки Shorts) могут требовать настройки времени ожидания и поведения прокрутки. Извлечение расшифровок/субтитров ограничено по сравнению с yt-dlp или специализированными transcript Actors. Для продвинутых workflows есть порог входа.
Лучше всего подходит для: маркетинговых аналитиков и бизнес-исследователей, которым удобны визуальные инструменты построения workflows, но нужна более гибкая настройка, чем у расширения Chrome.
5. YT-DLP
YT-DLP (доступен на GitHub) — это open-source командная утилита, которая извлекает метаданные видео, субтитры, расшифровки и многое другое с YouTube (и ещё 1 000+ сайтов). Это швейцарский нож для технических пользователей, которым нужен максимальный контроль и нулевая стоимость подписки.
Для задач в стиле парсинга yt-dlp может извлекать метаданные без скачивания видеофайлов с помощью флагов вроде --skip-download, --write-info-json, --dump-json и --flat-playlist. Он различает автоматически сгенерированные и написанные человеком субтитры — отличие, которое большинство других инструментов не замечает.
Ключевые возможности:
- Извлечение метаданных видео (название, просмотры, лайки, дата загрузки, описание, теги) без скачивания видео
- Массовое скачивание полных плейлистов и каналов
- Доступ к субтитрам/расшифровкам (авто- и вручную созданным, отдельно)
- Пакетная обработка с пользовательскими шаблонами вывода
- Поддержка cookie/авторизации для доступа через сессию
- Полностью бесплатно, активное open-source сообщество
Подход к обходу банов: cookie пользователя для аутентификации (--cookies-from-browser), настраиваемые параметры throttling и поддерживаемые сообществом обновления экстрактора, которые адаптируются к изменениям YouTube.
Цена: бесплатно.
Недостатки: требуется уверенное владение командной строкой. Нет визуального интерфейса. Ломается при изменениях YouTube (сообщество обычно быстро чинит, но обновлять и разбираться всё равно придётся). Нет встроенного планирования и экспорта в таблицы — весь конвейер вы строите сами.
Лучше всего подходит для: разработчиков, data scientists и технических команд, которым нужен максимальный контроль над извлечением метаданных и расшифровок и которые не против работы в терминале.
6. Phantombuster
Phantombuster — это облачная платформа автоматизации с YouTube-специфичными «Phantoms», созданными скорее для growth-маркетинга и lead generation, чем для чистого хранения данных. Это хороший выбор, когда ваша цель — найти контакты авторов и собрать списки для outreach.
YouTube Channel Video Extractor в Phantombuster собирает информацию о канале, список видео и публичные email-адреса из описаний каналов. В официальной документации по rate limit указано, что YouTube Channel Video Extractor поддерживает до 100 видео за один запуск, и предупреждается, что необычная активность всё равно может вызвать ограничения YouTube.
Ключевые возможности:
- Парсер каналов YouTube (количество подписчиков, список видео, информация о канале, публичные email)
- Извлечение видео и комментариев для конкурентного анализа
- Интеграции с CRM и инструментами outreach
- Планирование и автоматизация workflows
- 14-дневный бесплатный пробный период, тариф Start от $56/месяц (при ежегодной оплате, 20 ч/месяц выполнения)
Подход к обходу банов: встроенные задержки между действиями, браузерные сессии phantom, облачное выполнение с замедленной автоматизацией. Инструмент рассчитан на безопасный темп, а не на сверхбыстрое массовое извлечение.
Цена: тариф Start — $56/месяц (годовой), Grow — $128/месяц, Scale — $352/месяц. Стоимость за 1 000 результатов зависит от времени выполнения, а не от цены за запись.
Недостатки: медленнее, чем инструменты, ориентированные на data pipeline. Ценообразование основано на часах выполнения и кредитах, а не на понятной стоимости за строку. Поддержка расшифровок/субтитров ограничена. Лимит в 100 видео за запуск означает, что для больших каналов нужны несколько прогонов.
Лучше всего подходит для: growth-маркетологов, которые занимаются исследованием авторов, sales-команд, извлекающих контакты авторов, и агентств, отслеживающих конкурентную активность на YouTube.
Все типы данных, которые можно извлечь из YouTube (матрица по инструментам)
Разные инструменты поддерживают разные типы данных YouTube. Прежде чем выбирать инструмент, важно точно понимать, что вы получите. Вот разбор:
| Тип данных | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Метаданные видео (название, просмотры, лайки, длительность, дата) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Комментарии (массово, с автором, временем, лайками) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Ответы на комментарии | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Расшифровки/субтитры | ⚠️ (зависит от страницы) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Авто- и ручные субтитры (различаются) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Метрики Shorts | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Аналитика канала (подписчики, общее число просмотров, дата регистрации) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Миниатюры/изображения | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Публичные email-адреса из описаний канала | ✅ (если видны) | Зависит от Actor | ⚠️ | ⚠️ | ❌ | ✅ |
Самые ценные данные по бизнес-сценарию:
- Комментарии → анализ тональности, сбор возражений, жалобы на конкурентов, исследование аудитории
- Расшифровки → LLM/RAG-пайплайны, анализ сообщений конкурентов, повторное использование контента
- Метаданные канала → поиск авторов, отслеживание конкурентов, sales/инфлюенсер-проспектинг
- Метаданные видео → контент-стратегия, анализ заголовков/миниатюр, частота публикаций, идеи для SEO
- Публичные email-адреса → outreach авторам (используйте ответственно и в соответствии с правилами email и privacy)
Сравнение лучших парсеров YouTube: таблица side-by-side
| Инструмент | Тип | Подход к обходу банов | Стоимость/1K результатов | Лучше всего для | Настройка | Форматы экспорта | Масштаб |
|---|---|---|---|---|---|---|---|
| Thunderbit | AI-расширение для Chrome | Браузерная сессия, AI-определение полей | Бесплатный тариф (6 страниц); платно по кредитам | No-code исследование каналов/поиска | Очень просто | Sheets, Excel, Airtable, Notion, CSV/JSON | Небольшой-средний, по расписанию |
| Apify | Облачная платформа Actors | Индивидуальный темп Actor, прокси, Innertube | ~$5–$15/1K (зависит от Actor) | Разработческие пайплайны | Средняя | JSON, CSV, Excel, API, webhooks | Средний-высокий |
| Bright Data | Enterprise-парсер/прокси | 150M+ residential IP, решение CAPTCHA | $3.50/1K записей (PAYG) | Enterprise-извлечение | Средне-сложно | JSON, NDJSON, CSV, webhooks | Очень высокий |
| Octoparse | Визуальный конструктор workflows | Облачная ротация IP, антидетекция | ~$0.20/1K строк (шаблон) + тариф | Визуальные кастомные workflows | Средняя | Excel, CSV, JSON, БД | Средний |
| YT-DLP | Open-source CLI | Cookie, настройки throttling, обновления сообщества | Бесплатно | Техническое извлечение метаданных/расшифровок | Сложно (для нетехнических) | JSON, субтитры, пользовательский вывод | Зависит от настройки пользователя |
| Phantombuster | Облачная growth-автоматизация | Встроенные задержки, сессии с темпом | По тарифу ($56+/мес); ~100 видео/запуск | Сбор лидов авторов, growth-workflows | Просто-средняя | CSV/JSON/API/CRM | Средний, с темпом |
Победители по категориям:
- Лучший вариант для нетехнических пользователей: Thunderbit
- Лучший для developer-пайплайнов: Apify
- Лучший для enterprise-масштаба: Bright Data
- Лучший визуальный конструктор: Octoparse
- Лучший бесплатный технический вариант: YT-DLP
- Лучший workflow для growth-маркетинга: Phantombuster
Бесплатные и платные парсеры YouTube: когда бесплатных инструментов достаточно
Бесплатные инструменты подходят, когда задача узкая, редкая и вы готовы к техническому сопровождению. Вот когда можно остаться на бесплатном варианте, а когда уже стоит перейти на платный:
| Сценарий | Лучший бесплатный вариант | Когда переходить на платный | Почему |
|---|---|---|---|
| Разовая загрузка расшифровки | YT-DLP | Нужно 500+ видео или есть нетехнические коллеги | Настройка CLI и работа с cookie добавляют трение |
| Быстрая проверка канала конкурента | Бесплатный тариф Thunderbit (6 страниц) | Регулярный мониторинг или больше 10 страниц | Планируемый парсинг экономит часы в неделю |
| Создание датасета для обучения LLM | YT-DLP + собственные скрипты | Нужна фильтрация авто-/ручных субтитров в масштабе | Специальные Actors Apify лучше справляются с edge cases |
| Еженедельный мониторинг 10+ каналов | — | Сразу | Планирование и повторное использование схемы экономят реальное время |
| Маркетинговая команда, собирающая лиды авторов | Пробный период Thunderbit | 10+ каналов в неделю | Масштабирование по кредитам дешевле, чем время на написание скриптов |
Честно говоря: бесплатные инструменты вроде YT-DLP мощные, но требуют постоянного технического сопровождения. Изменения интерфейса YouTube, истечение cookie, корректировка throttling и форматирование вывода — всё это требует ручного внимания. Скрипт, который ломается каждые две недели, может стоить дороже по времени инженера, чем подписка на платный парсер.
AI-инструменты вроде Thunderbit заново читают страницы при каждом запуске и автоматически подстраиваются под изменения макета. Именно эта скрытая стоимость поддержки и оправдывает платные инструменты для большинства бизнес-команд.
Как на самом деле выглядят данные, извлечённые из YouTube (реальные примеры вывода)
Один из самых больших пробелов в обзорах парсеров — почти никто не показывает, что именно вы получите на выходе. Вот реалистичные примеры данных после парсинга YouTube:
Пример 1: Метаданные канала
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Еженедельные туториалы по продуктам и руководства по workflows | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Демонстрации аналитики, автоматизации и AI-workflow | Не видно |
Пример 2: Экспорт комментариев
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Это лучше объяснило вопрос с ценой, чем страница поставщика. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Хотелось бы продолжение с сравнением этого инструмента и Apify. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Хорошее замечание, мы как раз тестируем это следующим. | 4 | 0 |
Пример 3: Извлечение расшифровки
00:00:00.000 - 00:00:04.200 Сегодня мы сравниваем шесть workflow для парсинга YouTube для маркетологов.
00:00:04.200 - 00:00:09.800 Главная разница в том, нужны ли вам метаданные, комментарии или расшифровки.
00:00:09.800 - 00:00:15.300 Для нетехнических пользователей парсер на базе браузера обычно проще поддерживать.
Типичные проблемы очистки данных, которых стоит ожидать:
- Счётчики просмотров могут содержать локализованные суффиксы (K, M) или неанглийские обозначения
- Даты загрузки иногда отображаются относительно («3 года назад»), а не в формате ISO
- По умолчанию комментарии могут сортироваться по Top, а не по New
- Скрытые ответы и лениво подгружаемые комментарии требуют прокрутки или пагинации
- Публичные email-поля могут быть скрыты взаимодействием или ограничениями аккаунта
- Расшифровки могут отсутствовать, быть сгенерированы автоматически или оказаться на неожиданном языке
Для Thunderbit процесс выглядит так: AI Suggest Fields → Scrape → Export to Google Sheets. AI сам определяет поля, поэтому вам не нужно вручную задавать, как на странице выглядят «просмотры» или «дата загрузки».
Законно ли парсить YouTube в 2026 году?
Коротко: сбор публично доступных данных YouTube обычно несёт меньший риск, чем доступ к закрытым данным, но это всё равно не зона полной свободы.
Условия использования YouTube прямо запрещают автоматизированный доступ, кроме публичных поисковых систем, соблюдающих robots.txt, или при наличии предварительного письменного разрешения YouTube. Однако меры против добросовестных бизнес-исследований применяются редко — YouTube в основном борется с массовыми злоупотреблениями, пиратством контента и нарушениями приватности.
Судебная практика США даёт некоторую ясность. Решение Девятого округа по делу hiQ v. LinkedIn поставило серьёзные вопросы о том, нарушает ли парсинг общедоступных данных CFAA. EFF утверждает, что парсинг публичных сайтов не является преступлением. Но условия платформы, авторское право, приватность и законы против спама всё равно действуют.
Практические рекомендации:
- Собирайте только публичные данные, доступные вашему аккаунту
- Не собирайте персональные данные в избыточном масштабе
- Не обходите контролируемый доступ или paywall
- Уважайте авторское право — не перепубликуйте расшифровки или видеоконтент целиком
- Ограничивайте скорость задач и не перегружайте серверы YouTube
- Для outreach соблюдайте CAN-SPAM, GDPR и местные правила
- Для рискованных сценариев консультируйтесь с юристом
Все инструменты в этом списке по замыслу включают ограничение скорости и уважительный темп работы. Это не только про этику — именно это позволяет парсингу работать долго и стабильно.
Какой парсер YouTube выбрать?
Вот краткое руководство по выбору:
- Thunderbit → лучший для нетехнических пользователей, которым нужен быстрый, устойчивый к банам парсинг YouTube в таблицы. Начните с него, если вы маркетолог, sales-менеджер или контент-стратег.
- Apify → лучший для разработчиков, строящих автоматизированные пайплайны с плановыми заданиями, webhooks и доставкой через API.
- Bright Data → лучший для извлечения данных enterprise-масштаба по разным географиям с управляемой антиблокировочной инфраструктурой.
- Octoparse → лучший для аналитиков, которым нужен визуальный конструктор workflows с большей гибкостью, чем у расширения Chrome.
- YT-DLP → лучший бесплатный вариант для технических пользователей, которым нужен максимальный контроль над метаданными и расшифровками.
- Phantombuster → лучший для growth-маркетологов, занимающихся поиском авторов и лидогенерацией через YouTube.
Ключ к тому, чтобы не попасть под бан, — не одна секретная хитрость, а выбор инструмента со встроенной умной антидетекцией. Парсинг в реальной браузерной сессии, ротация прокси, контроль темпа и небольшие запланированные пачки всё снижают риск. А вот попытка «продавить» тысячи запросов с одного облачного IP и приводит к блокировке.
Если хотите увидеть, как выглядит современный парсинг YouTube без кода, попробуйте бесплатный тариф Thunderbit. Два клика — и данные уже структурированы. А если ваши задачи более технические или enterprise-масштаба, другие инструменты из этого списка тоже подойдут. Больше о подходах к веб-парсингу читайте в наших руководствах: лучшие автоматизированные инструменты веб-парсинга и как извлекать данные с сайтов в Excel. Ещё можно посмотреть туториалы на YouTube-канале Thunderbit.
Попробовать Thunderbit для парсинга YouTube Get Started Free
FAQ
Какие данные можно собрать с канала YouTube?
Извлекаемые публичные данные включают названия видео, URL, миниатюры, просмотры, лайки (если видны), даты загрузки, описания, длительность, комментарии, ответы, имена/handle комментаторов, лайки комментариев, расшифровки/субтитры (авто- и вручную созданные), индикаторы Shorts, название канала, handle, число подписчиков, количество видео, общее число просмотров, описание, ссылки и публичные email-адреса, если они видны на странице канала.
Сколько видео YouTube можно парсить в день без бана?
Универсального числа нет. Инструменты на базе браузера, такие как Thunderbit, несут меньший риск для сценариев, похожих на действия пользователя, потому что работают внутри реальной сессии. YouTube Channel Video Extractor в Phantombuster поддерживает до 100 видео за один запуск. Облачные платформы с ротацией прокси могут обрабатывать тысячи данных при правильном темпе. Сырые скрипты с облачных серверов без ограничения скорости быстро блокируются. Самый безопасный подход — небольшие запланированные пачки, а не один огромный запуск.
Можно ли парсить комментарии YouTube для анализа тональности?
Да. Thunderbit, Apify, Bright Data и Octoparse поддерживают массовое извлечение комментариев с автором, временем, лайками и количеством ответов. Для анализа экспортируйте данные в Google Sheets или CSV. YouTube actor в Apify прямо поддерживает настраиваемый максимум комментариев на видео для этого сценария.
Есть ли бесплатный парсер YouTube, который действительно работает в 2026 году?
YT-DLP — лучший бесплатный вариант для технических пользователей, особенно для метаданных и расшифровок. Thunderbit предлагает бесплатный тариф для нетехнических пользователей (6 страниц, с пробным бустом до 10), который экспортирует данные напрямую в Google Sheets. Оба варианта работают, но YT-DLP требует навыков командной строки, а Thunderbit — только браузер.
Как парсеры YouTube избегают блокировки?
Разные инструменты используют разные подходы: парсинг в браузерной сессии (Thunderbit) использует авторизованный браузерный контекст пользователя; ротация residential-прокси (Bright Data, Apify) распределяет запросы по миллионам IP; cookie-аутентификация (YT-DLP) сохраняет доверие к сессии; встроенные задержки и контроль темпа (Phantombuster) предотвращают поведенческое обнаружение. Самый надёжный подход сочетает реальный браузерный контекст с осторожным темпом и небольшими запланированными задачами.
Подробнее




