

Há alguns meses, um colega da nossa equipa de vendas fez-me uma pergunta que já ouvi dezenas de vezes: “Se eu recolher preços de concorrentes num site público, posso mesmo ter problemas?” Tinha encontrado um diretório de contactos de fornecedores, preços alinhados em linhas organizadas e tudo o que queria era uma folha de cálculo. A hesitação era real — e, honestamente, compreensível.
O Reino Unido não tem uma única “lei de web scraping”. Em vez disso, quatro enquadramentos jurídicos sobrepostos determinam se uma atividade específica de scraping é lícita. É por isso que a resposta é sempre “depende” — mas isso não precisa de ser paralisante. Neste guia, vou explicar o que a lei realmente diz, como se aplica a cenários do mundo real, quais são as penalidades e como manter-se em conformidade.
Passei bastante tempo a investigar isto para a nossa equipa na Thunderbit e quero partilhar o que encontrei para que não precise de juntar as peças de cinco blogues de escritórios de advogados e um tópico no Reddit.
Experimente a Thunderbit para Web Scraping
O que é web scraping (e por que as empresas do Reino Unido o usam)
Web scraping é o uso de software para recolher dados automaticamente de sites — substituindo o processo tedioso de copiar e colar páginas web para uma folha de cálculo.
A técnica em si é neutra. Não é inerentemente legal, nem inerentemente ilegal. O que importa é o que recolhe, como recolhe e o que faz com os dados depois.
As empresas britânicas usam scraping para todo o tipo de fins legítimos:
- Comparação de preços: a PriceSpy UK, por exemplo, atualiza os preços de produtos de três a cinco vezes por dia usando web scraping automatizado.
- Geração de leads: equipas de vendas a extrair nomes de empresas, e-mails e telefones de diretórios públicos.
- Pesquisa de mercado: analistas a acompanhar anúncios imobiliários, vagas de emprego ou linhas de produtos de concorrentes.
- Pesquisa académica: o Office for National Statistics recolheu mais de 2,2 milhões de cotações de preços em sites de supermercados entre 2014 e 2015.
- Treino de modelos de IA: um caso de uso em rápido crescimento — e juridicamente ainda indefinido.
A tendência é clara. Um inquérito Bright Data/Vanson Bourne a 500 decisores (incluindo 200 no Reino Unido) mostrou que 89% viam dados públicos da web como cruciais ou muito importantes para a economia global, e 38% obtinham-nos pelo menos diariamente.
Mesmo assim, 73% disseram que a falta de regulamentação clara preocupava as suas organizações. É precisamente por isso que este artigo existe.
Web scraping é legal no Reino Unido? A resposta direta
Nenhuma lei britânica proíbe o web scraping de forma absoluta. No entanto, várias leis regulam como ele pode ser feito, e a legalidade de qualquer projeto específico depende de quatro fatores:
- Que dados está a recolher (dados pessoais vs. dados factuais/não pessoais)
- Como acede a esses dados (página pública vs. contornar logins ou CAPTCHAs)
- O que os termos do site dizem (proíbem acesso automatizado?)
- Como usa os dados depois (análise interna vs. revenda comercial)
A melhor analogia que encontrei: web scraping é como fotografar num espaço público. Tirar uma foto em público não é automaticamente ilegal — mas certos temas, locais, métodos e usos criam risco jurídico. O scraping é parecido. A disponibilidade pública é relevante, mas não conta a história toda.
A consulta recente da ICO sobre GenAI é uma das declarações oficiais mais claras do Reino Unido sobre dados pessoais recolhidos por scraping. A ICO afirmou que interesses legítimos continua a ser a única base legal disponível para treinar modelos de IA generativa usando dados pessoais obtidos por web scraping — mas apenas se o desenvolvedor passar num teste rigoroso em três partes. É um padrão elevado e mostra o quanto os reguladores britânicos levam estes dados a sério.
As quatro leis do Reino Unido que se aplicam ao web scraping
Quatro lentes sobrepostas — qualquer projeto de scraping pode acionar uma, duas ou as quatro.
UK GDPR e Data Protection Act 2018
Se recolher dados pessoais — nomes, e-mails, telefones, endereços IP, perfis de redes sociais — o UK GDPR aplica-se. “Disponível publicamente” não significa “livre para usar”.
Dados pessoais visíveis publicamente continuam a ser dados pessoais.
A base legal mais relevante para scraping comercial é interesses legítimos (Artigo 6) — mas não basta invocar essa expressão. É preciso:
- Identificar uma finalidade específica e legítima
- Demonstrar que o tratamento é necessário para essa finalidade
- Equilibrar o seu interesse com os direitos das pessoas cujos dados recolhe
A resposta da ICO à consulta sobre GenAI é especialmente incisiva: os desenvolvedores não devem presumir que um benefício social amplo é suficiente, devem demonstrar por que alternativas ao scraping são inadequadas e devem usar mecanismos de transparência que permitam às pessoas compreender e exercer os seus direitos. Fonte: resposta da ICO sobre GenAI.
Para geração de leads B2B, a mesma lógica aplica-se. Uma equipa de vendas pode apoiar-se em interesses legítimos para recolher informações comerciais de contacto listadas publicamente, mas ainda precisa de documentar o interesse legítimo, minimizar os campos recolhidos, evitar categorias especiais de dados, fornecer informações de privacidade quando viável e respeitar opt-outs.
Direitos de autor, direitos sobre bases de dados e a exceção de TDM
Direitos de autor protegem o conteúdo original dos sites: texto, imagens, descrições de produtos, artigos. Dados factuais como preços são, em geral, menos sensíveis do ponto de vista dos direitos de autor por si só — mas copiar e republicar a expressão protegida pode constituir infração.
Direitos sobre bases de dados importam mais para scraping do que muita gente imagina. O Reino Unido manteve, após o Brexit, os direitos sui generis sobre bases de dados ao estilo da UE, e extrair uma “parte substancial” de uma base protegida — diretórios curados, catálogos de produtos, listagens de marketplaces — pode infringir a lei mesmo quando os dados individuais são factuais.
A exceção de Text and Data Mining (TDM), ao abrigo da Seção 29A do CDPA, permite cópias para análise de texto e dados apenas quando o utilizador tem acesso legítimo e a finalidade é investigação não comercial. O alcance é estreito. Scraping comercial, treino comercial de IA e revenda comercial de conjuntos de dados não são abrangidos.
O governo britânico considerou ampliar esta exceção para treino de IA, mas, no seu relatório de março de 2026 sobre Copyright and AI, decidiu não implementar reformas até ter a certeza de que elas cumprem os objetivos dos criadores, dos desenvolvedores de IA e da economia do Reino Unido. No cenário atual, em geral é necessária permissão para copiar obras protegidas para treino de IA, salvo se alguma exceção existente se aplicar.
Termos de serviço do site e direito contratual
A maioria dos sites tem Termos de Serviço (ToS) que proíbem ou restringem scraping automatizado. Ao aceder ao site, pode já estar a concordar com esses termos — especialmente se clicar numa tela de aceitação (clickwrap). Acordos browsewrap (termos escondidos num link no rodapé) são mais sensíveis aos factos, mas os tribunais britânicos já demonstraram disponibilidade para fazer cumprir restrições de ToS contra scraping. Na disputa Ryanair v Billigfluege, o tribunal tratou os termos visíveis do site como vinculativos num contexto de screen scraping.
robots.txt não é uma lei. É um sinal legível por máquina enviado pelo proprietário do site. Um ficheiro típico tem este aspeto:
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
Ignorar o robots.txt não torna o scraping automaticamente ilegal, mas tribunais e a ICO tratam-no como prova da intenção do proprietário do site. Ignorá-lo aumenta a sua exposição jurídica, especialmente se vier acompanhado de violação dos ToS ou de volumes agressivos de pedidos.
Computer Misuse Act 1990
Esta lei costuma tirar o sono às pessoas — e com razão. Cria infrações criminais. A Secção 1 cobre acesso não autorizado a material informático (pena máxima de 2 anos de prisão). A Secção 3 cobre atos não autorizados que prejudiquem o funcionamento de um computador (pena máxima de 10 anos de prisão).
O risco ao abrigo da CMA é menor quando os dados são realmente públicos e o scraper não contorna barreiras técnicas. O risco aumenta quando:
- Contorna logins, CAPTCHAs ou bloqueios de IP
- Usa credenciais roubadas ou cria contas falsas
- Envia volumes de tráfego que prejudicam o serviço-alvo
O Reino Unido não criou uma regra clara, à semelhança dos EUA, de que “dados públicos estão liberados”. Isso torna a orientação britânica mais cautelosa: o acesso público reduz materialmente o risco ao abrigo da CMA, mas os termos do site, os controlos técnicos e o conhecimento que o scraper tem das restrições continuam a importar.
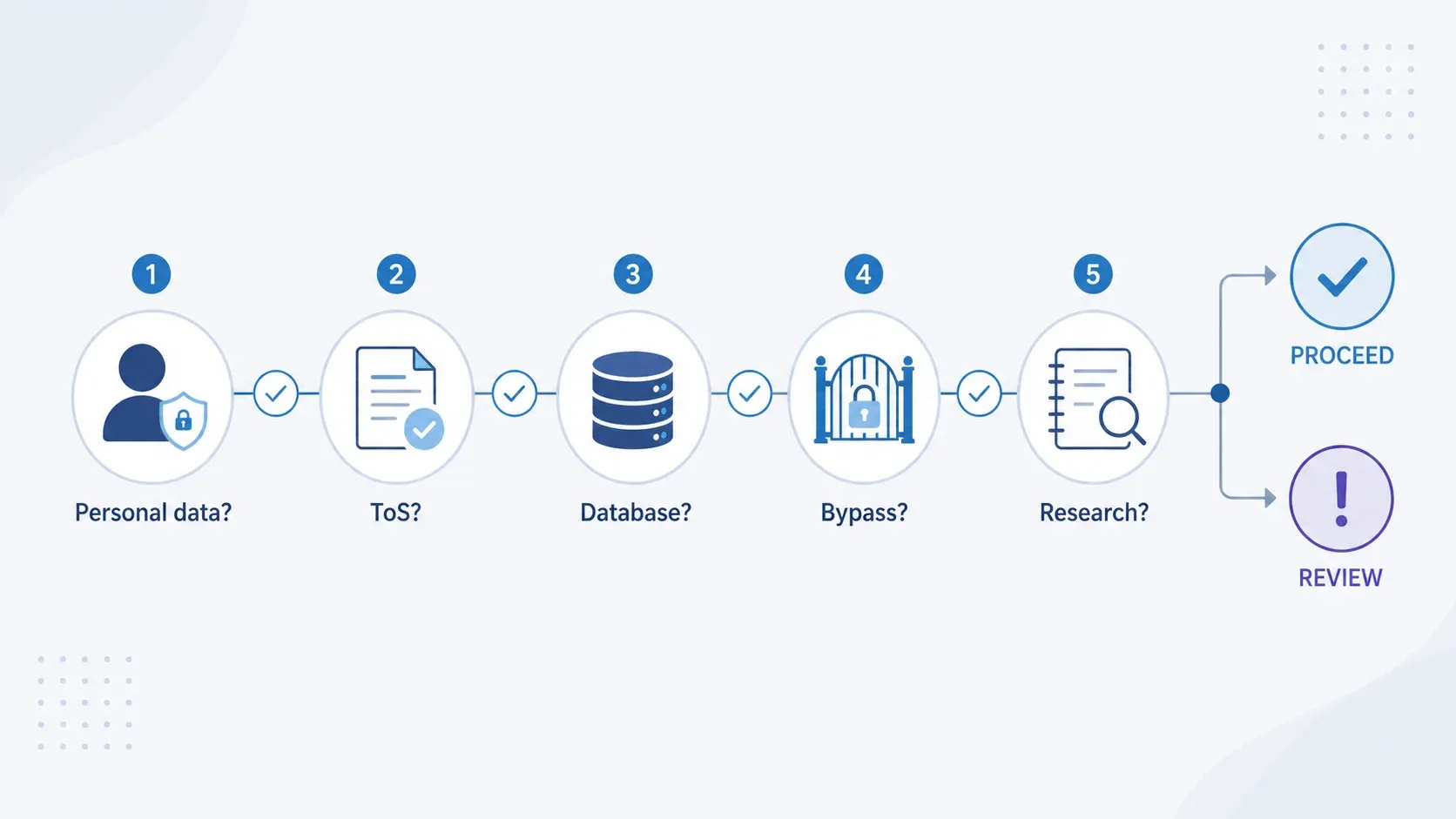
“Posso recolher isto legalmente?” — um fluxo rápido de decisão
Antes de recolher qualquer coisa, percorra estes cinco pontos de decisão. Não é aconselhamento jurídico — apenas uma triagem de risco de 60 segundos.
| Ponto de decisão | Se SIM | Se NÃO |
|---|---|---|
| Os dados são pessoais (nomes, e-mails etc.)? | O UK GDPR aplica-se. Identifique a base legal, faça uma LIA, minimize os campos e planeie a transparência. | A camada do GDPR pode não se aplicar, mas continue com as outras verificações. |
| Os ToS do site proíbem explicitamente o scraping? | Risco de violação contratual. Considere API, licença ou revisão jurídica. | Menor risco contratual, mas verifique o robots.txt. |
| Está a extrair uma parte substancial de uma base de dados? | É provável haver infração do direito sui generis sobre bases de dados. Considere licenciamento ou uma extração mais limitada. | Os direitos de autor ainda podem aplicar-se ao conteúdo individual copiado. |
| Está a contornar login, CAPTCHA ou controlos de acesso? | Possível infração criminal ao abrigo da CMA 1990. Pare e peça revisão jurídica. | Menor risco ao abrigo da CMA se o acesso for realmente público. |
| A finalidade é investigação não comercial? | A exceção de TDM da Secção 29A pode aplicar-se se tiver acesso legítimo. | Não existe um abrigo amplo de TDM comercial no Reino Unido. É necessária uma análise completa de PI e contrato. |
Sinceramente, adorava que alguém me tivesse mostrado isto quando comecei a investigar conformidade de scraping para a equipa. Transforma a complexidade jurídica numa autoavaliação estruturada que se faz em menos de um minuto.
Cenários reais: a sua atividade específica de scraping é legal no Reino Unido?
Lei abstrata é uma coisa. O que as pessoas realmente querem saber é: “o meu projeto específico vai dar problemas?”
Justo. Aqui estão cinco casos comuns de uso de scraping no Reino Unido com uma miniavaliação de risco jurídico para cada um.
Recolher preços de produtos para comparação
Um dos usos comerciais mais comuns — e, muitas vezes, de menor risco. Os preços são dados factuais, e a recolha automatizada de preços é precisamente como sites como a PriceSpy operam.
Mas o risco não desaparece por completo. Se o site-alvo proíbe scraping nos ToS, se copiar descrições de produtos ou imagens, ou se extrair uma parte substancial de uma base de dados de produtos curada, podem surgir questões de contrato, direitos de autor e direitos sobre bases de dados.
Nível de risco: BAIXO a MÉDIO
Principal medida de conformidade: recolha apenas campos factuais de preço, evite copiar descrições de produtos literalmente, respeite os ToS e o robots.txt, use limitação de taxa e não publique um espelho bruto do catálogo do concorrente.
Recolher e revender dados comercialmente
O cenário comercial de maior risco, sem rodeios. Está a transformar o investimento em dados de outra parte num produto à venda — e isso pode acionar, ao mesmo tempo, os quatro pilares jurídicos.
Nível de risco: ALTO
Principal medida de conformidade: revisão jurídica é essencial. Considere acordos de licenciamento com os proprietários dos dados. Se o produto incluir dados pessoais, adicione uma avaliação de impacto em proteção de dados.
Extrair informações de contacto comerciais para geração de leads
Toda a equipa de vendas com quem falei faz alguma variação disto: recolher e-mails, telefones e nomes de empresas em diretórios. O ponto é que dados de contacto comercial muitas vezes incluem dados pessoais. O e-mail de um funcionário identificado é dado pessoal, mesmo que esteja listado publicamente.
Nível de risco: MÉDIO
Principal medida de conformidade: faça uma Avaliação de Interesses Legítimos, recolha apenas dados de contacto comerciais (não pessoais) sempre que possível, documente a sua base legal e ofereça uma forma de opt-out. Ferramentas como a Thunderbit podem reduzir o risco de acesso aqui porque a extensão do Chrome funciona no navegador do utilizador — acede apenas ao que o utilizador já consegue ver, sem contornar controlos de acesso.
Análise de dados académicos ou de portefólio
Se estiver a fazer investigação genuinamente não comercial, terá o caminho de exceção de direitos de autor mais forte: a Secção 29A do CDPA, desde que tenha acesso legítimo.
Nível de risco: BAIXO (se for realmente não comercial)
Principal medida de conformidade: documente a finalidade não comercial, cite as fontes, anonimize ou agregue sempre que possível e evite redistribuir conteúdo protegido por direitos de autor ou dados pessoais.
Recolher conteúdo para treino de modelos de IA
Esta é a pergunta que toda a gente faz em 2026 — e a resposta continua a ser insatisfatória. A ICO trata dados pessoais obtidos por web scraping para treino como tratamento invisível de alto risco. O relatório de 2026 do governo britânico não introduziu uma exceção comercial ampla de TDM.
Nível de risco: MÉDIO a ALTO
Principal medida de conformidade: licenciamento, procedência do conjunto de dados, análise de direitos de autor, filtragem de dados pessoais, documentação da base legal e monitorização atenta das mudanças de política no Reino Unido.
Tabela-resumo dos cenários
| Cenário | Principais leis acionadas | Nível de risco | Principal medida de conformidade |
|---|---|---|---|
| Monitorização de preços de produtos | ToS, direitos sobre bases de dados, direitos de autor | Baixo–Médio | Recolha campos factuais, respeite os sinais do site |
| Revenda comercial de dados | Todos os quatro pilares | Alto | Revisão jurídica e licenciamento são essenciais |
| Geração de leads B2B | UK GDPR, ToS | Médio | Faça LIA, minimize dados pessoais |
| Investigação académica | Direitos de autor (exceção de TDM), GDPR se houver dados pessoais | Baixo | Mantenha a finalidade não comercial, não republicar |
| Treino de modelos de IA | UK GDPR, direitos de autor, direitos sobre bases de dados | Médio–Alto | Licencie os dados, documente a base legal, monitorize a política |
Reino Unido vs. EUA vs. UE: como a lei de web scraping difere
Se opera apenas no Reino Unido, pode saltar esta secção. Mas a maioria das empresas com quem falo faz scraping internacional — ou pelo menos em sites alojados noutras jurisdições. As diferenças importam mais do que parece.
| Dimensão jurídica | 🇬🇧 Reino Unido | 🇺🇸 EUA | 🇪🇺 UE |
|---|---|---|---|
| Principal lei de proteção de dados | UK GDPR + DPA 2018 | Sem equivalente federal (as leis estaduais variam) | GDPR da UE |
| Principal precedente de scraping | Clearview AI (multa de £7,5 milhões da ICO) | hiQ v LinkedIn (scraping de dados públicos OK, no Ninth Circuit — mas a hiQ foi permanentemente impedida e pagou US$ 500 mil no julgamento final por consentimento) | Ryanair v PR Aviation (TJUE, C-30/14, direitos sobre bases de dados) |
| Lei de acesso a computadores | Computer Misuse Act 1990 | CFAA (restringida por Van Buren, 2021) | Varia por Estado-membro |
| Direitos de autor / exceção TDM | Restrita: apenas investigação não comercial (Secção 29A) | Doutrina do fair use (mais ampla, caso a caso) | Diretiva DSM Art. 3 e 4 (direitos TDM mais amplos com reserva de direitos) |
| Direitos sobre bases de dados | Sim (mantidos da Diretiva de Bases de Dados da UE) | Sem direito federal equivalente | Direito sui generis sob a Diretiva de Bases de Dados |
| Execução dos ToS | Direito contratual aplica-se; browsewrap é debatido | Misto: browsewrap muitas vezes é inexequível | Varia; Ryanair fortaleceu a posição dos ToS |
A conclusão prática: se recolhe dados em várias jurisdições, cumpra a lei mais restritiva aplicável. Os EUA são mais permissivos quanto ao acesso a dados públicos ao abrigo da decisão hiQ, mas isso não é uma autorização geral — a hiQ acabou impedida de recolher dados do LinkedIn e pagou US$ 500 mil. A UE tem uma arquitetura TDM mais ampla através da Diretiva DSM. O Reino Unido fica no meio do caminho — sem uma exceção comercial ampla de TDM, com fortes direitos sobre bases de dados e um regulador ativo.
Penalidades e fiscalização: o que realmente acontece se for apanhado
Avisos vagos sobre “multas” e “problemas jurídicos” não ajudam ninguém. Aqui estão os números reais.
Multas ao abrigo do UK GDPR
Penalidade máxima: £17,5 milhões ou 4% do volume de negócios global anual, o que for maior.
Exemplo real: a Clearview AI foi multada em £7.552.800 pela ICO em 2022 por recolher imagens faciais de redes sociais do Reino Unido. O First-tier Tribunal anulou a decisão por motivos de jurisdição, mas o Upper Tribunal, em outubro de 2025, permitiu o recurso da ICO e devolveu o caso para nova análise. A ICO observou que a Clearview tinha permissão para recorrer ao Court of Appeal em dezembro de 2025.
Penalidades criminais da Computer Misuse Act
- Secção 1 (acesso não autorizado): até 2 anos de prisão
- Secção 3 (prejuízo não autorizado): até 10 anos de prisão
Processos criminais por scraping comum de páginas públicas são extremamente raros.
O perfil de risco muda drasticamente quando a conduta se parece com hacking, uso indevido de credenciais, contorno de CAPTCHA ou prejuízo ao serviço.
Direitos de autor e direitos sobre bases de dados
Indemnização civil mais ordem de cessação. Penalidades criminais são possíveis para infração comercial dolosa, mas a maioria das disputas de scraping segue como ação civil.
Violação contratual (ToS)
Indemnização civil, encerramento de conta, bloqueio de IP. Em geral, esta é a via de execução prática mais comum — e muitas vezes a primeira coisa que acontece.
Resumo da gravidade das penalidades
| Estrutura jurídica | Penalidade máxima | Probabilidade para scraping empresarial típico | Exemplo real |
|---|---|---|---|
| UK GDPR | £17,5 milhões ou 4% do volume de negócios global | Média se houver dados pessoais em escala; baixa para dados não pessoais | Multa de £7,5 milhões à Clearview AI |
| CMA Secção 1 | 2 anos de prisão | Baixa para páginas públicas; maior se houver contorno de controlos | Orientação da CPS sobre acesso não autorizado |
| CMA Secção 3 | 10 anos de prisão | Baixa, a menos que o tráfego prejudique sistemas | Exemplos de prejuízo estilo DDoS |
| Direitos de autor/direitos sobre bases de dados | Indemnização e ordem judicial | Médio ao copiar conteúdo protegido ou bases curadas | Casos Ryanair e BHB |
| Violação dos ToS | Indemnização, encerramento de conta, bloqueio | Alto como via prática de execução | Disputas de screen scraping da Ryanair |
Como a ferramenta de scraping certa reduz o seu risco jurídico
A ferramenta que escolhe não torna lícito um scraping ilegal. Mas pode eliminar riscos evitáveis.
Pela minha experiência, a diferença entre uma ferramenta que respeita os sinais do site e outra que contorna tudo de forma agressiva costuma ser a diferença entre um projeto de dados rotineiro e uma dor de cabeça jurídica.
Respeita robots.txt e sinais do site
Uma ferramenta responsável deve facilitar a verificação e o respeito ao robots.txt antes do scraping. Embora não seja juridicamente vinculativo, o cumprimento do robots.txt é tratado por tribunais e pela ICO como prova de boa-fé. A documentação da Thunderbit orienta os utilizadores a recolher dados disponíveis publicamente e respeitar o robots.txt e os termos.
Opções de scraping no navegador vs. na nuvem
Esta distinção importa juridicamente. O scraping no navegador acede apenas ao que o utilizador pode ver na sua sessão autenticada — essencialmente automatiza o que faria manualmente. O scraping na nuvem envia pedidos a partir de servidores, o que é mais rápido para sites públicos, mas pode parecer mais “acesso automatizado” do ponto de vista do site.
A Thunderbit oferece ambos os modos. O scraping no navegador é apropriado para sites que exigem login (reduzindo o risco de “acesso não autorizado” ao abrigo da CMA), enquanto o scraping na nuvem funciona bem para páginas de ecommerce publicamente disponíveis, em que a velocidade importa. Esta abordagem dupla permite aos utilizadores ajustar o método de recolha ao perfil de risco jurídico de cada site.
Sem contorno de controlos de acesso
Uma ferramenta que funciona dentro do navegador e não quebra CAPTCHAs nem contorna páginas de login é, por natureza, de menor risco ao abrigo da Computer Misuse Act. A extensão do Chrome da Thunderbit funciona dentro da sessão do navegador do utilizador — acede apenas ao que o utilizador já consegue ver.
Exportação transparente de dados (apoiando a conformidade com GDPR)
A Thunderbit exporta diretamente para Excel, Google Sheets, Airtable ou Notion. O utilizador controla para onde os dados vão. Isto apoia a transparência e a documentação da base legal no GDPR: sabe exatamente que dados recolheu e para onde foram. Sem processamento oculto nem retenção de dados pela ferramenta.
Limitação de taxa e acesso responsável
Volumes agressivos de pedidos podem acionar a Secção 3 da CMA (prejuízo não autorizado). Limitação de taxa não é apenas uma boa prática técnica — é uma salvaguarda jurídica. Ferramentas responsáveis evitam sobrecarregar servidores, o que reduz tanto o risco legal como a probabilidade de o seu IP ser bloqueado.

Lista prática de conformidade para web scraping no Reino Unido
Passe por isto antes de recolher qualquer coisa:
- Leia os Termos de Serviço e a Política de Uso Aceitável do site-alvo.
- Verifique o ficheiro robots.txt e documente se os caminhos relevantes estão bloqueados.
- Determine se os dados que quer são dados pessoais. Se sim, identifique a sua base legal ao abrigo do UK GDPR.
- Avalie se está a extrair uma “parte substancial” de uma base de dados.
- Confirme que não está a contornar controlos técnicos de acesso (CAPTCHAs, logins, limites de taxa).
- Se a sua finalidade for investigação não comercial, documente isso para beneficiar da exceção de TDM.
- Use limitação de taxa. Não sobrecarregue o servidor-alvo.
- Documente tudo: a sua base legal, revisão dos ToS, campos de dados recolhidos, destinos de exportação e prazo de retenção.
- Se houver dúvida, procure orientação jurídica com um solicitor especializado em proteção de dados e propriedade intelectual.
Esta checklist não substitui a opinião de um solicitor — mas dá um ponto de partida sólido e demonstra boa-fé se surgirem questões.
Principais conclusões
- Web scraping não é ilegal no Reino Unido — mas é regulado por quatro enquadramentos jurídicos sobrepostos: UK GDPR, direitos de autor/direitos sobre bases de dados, direito contratual e Computer Misuse Act.
- A legalidade de qualquer recolha depende do que recolhe, como acede, o que os termos do site dizem e o que faz com os dados.
- Scraping de dados pessoais tem a maior carga de conformidade. Interesses legítimos costuma ser a única base legal viável, e exige uma análise de balanceamento documentada.
- O Reino Unido não tem uma exceção comercial ampla de TDM. Treino comercial de IA e revenda de datasets são de alto risco sem licenciamento.
- Use o fluxo de decisão e a tabela de cenários acima para avaliar a sua situação específica antes de começar.
- Escolha ferramentas alinhadas com as melhores práticas de conformidade: acesso via navegador, sem contorno de CAPTCHA, exportação transparente de dados e limitação de taxa. A Thunderbit foi concebida com estes princípios em mente — mas a responsabilidade pela conformidade é sempre do utilizador.
- Na dúvida, documente a sua justificação e fale com um solicitor. O custo de uma opinião jurídica é quase sempre menor do que o custo de uma investigação da ICO.
Experimente o Raspador Web IA com a Thunderbit Get Started Free
FAQs
É legal recolher dados publicamente disponíveis no Reino Unido?
Em geral, sim — recolher dados públicos tem menos risco do que recolher dados privados ou protegidos por login. Mas “disponível publicamente” não significa “livre para usar como quiser”. O UK GDPR ainda pode aplicar-se a dados pessoais públicos, os direitos de autor podem aplicar-se à expressão copiada, os direitos sobre bases de dados podem proteger coleções curadas e os ToS podem restringir o acesso automatizado.
Posso recolher e-mails e telefones de sites do Reino Unido?
Se os dados forem dados pessoais (o que e-mails e telefones normalmente são), precisa de uma base legal ao abrigo do UK GDPR. Interesses legítimos é a base mais comum para geração de leads B2B, mas deve fazer um teste de balanceamento, minimizar os dados recolhidos e oferecer uma forma de opt-out. Recolher dados de contacto pessoais (telemóveis, e-mails pessoais) é muito mais arriscado do que listagens de diretórios comerciais.
Qual é a diferença entre web scraping e web crawling na lei do Reino Unido?
Juridicamente, não há distinção relevante — a lei preocupa-se com a conduta, não com o rótulo. Crawling geralmente significa descobrir ou indexar páginas; scraping geralmente significa extrair dados estruturados. Ambos envolvem acesso automatizado a sites e estão sujeitos aos mesmos enquadramentos legais.
O robots.txt torna o scraping ilegal?
Não. O robots.txt não é juridicamente vinculativo. No entanto, ignorá-lo aumenta a sua exposição jurídica porque tribunais e a ICO o tratam como prova da intenção do proprietário do site. Se ignorar o robots.txt e os ToS do site também proibirem scraping, estará a acumular fatores de risco — e isso é muito mais difícil de defender.
Posso ser processado criminalmente por web scraping no Reino Unido?
Só se contornar controlos de acesso (CAPTCHAs, logins, bloqueios de IP) ou causar dano a um sistema informático ao abrigo da Computer Misuse Act 1990. Scraping comum de dados realmente públicos, em volumes razoáveis e sem evasão técnica, tem probabilidade extremamente baixa de resultar em acusações criminais. O perfil de risco muda drasticamente quando a conduta se assemelha a hacking ou a prejuízo deliberado ao serviço.
Saiba mais




