Você cria uma conta no ScraperAPI, vê “100.000 créditos” no plano Hobby e começa a fazer scraping. Três dias depois, o painel mostra que 80% desses créditos já se foram — e talvez você tenha extraído só umas 6.000 páginas. O que aconteceu? O que aconteceu foi o sistema de multiplicadores de crédito, e esse é, disparado, o detalhe mais importante do ScraperAPI que quase nenhuma análise explica direito. Passei semanas mergulhado na documentação do ScraperAPI, juntando dados reais de preços de cinco concorrentes e lendo tudo o que encontrei em threads do Reddit e avaliações no Capterra. Esta análise do ScraperAPI é a que eu gostaria de ter lido quando o nosso time começou a avaliar APIs de scraping. Vou mostrar a matemática real dos créditos, apontar onde o ScraperAPI funciona bem (e onde falha em cheio), resumir o que usuários reais dizem no G2, Capterra e Reddit e — honestamente — ajudar você a perceber se realmente precisa de uma API de scraping.
O que é o ScraperAPI e para quem ele foi feito?
O ScraperAPI é uma API de web scraping que cuida da infraestrutura complicada por trás de raspagens em grande escala: rotação de proxy em , resolução automática de CAPTCHA, renderização de JavaScript e novas tentativas automáticas. Você envia uma URL por meio de uma chamada simples de API e recebe o HTML de volta (ou JSON já estruturado, se usar os endpoints de dados estruturados). A empresa foi fundada em 2018 por Daniel Ni, tem sede em Las Vegas e hoje atende , incluindo Deloitte, Sony e Alibaba — processando .
O público principal são equipes de desenvolvimento e operações técnicas que montam pipelines personalizados de scraping. Se você não escreve código, o ScraperAPI não foi pensado para você (a gente fala disso mais adiante).
Os recursos principais incluem rotação de proxy, renderização de JavaScript, geolocalização, endpoints de dados estruturados para sites populares e tentativas automáticas em caso de falha.
Mas tem um ponto que a maioria das análises deixa passar: os números de créditos em destaque na página de preços do ScraperAPI podem enganar bastante se você não entender como os multiplicadores funcionam. Então vamos começar por aí.
Como o sistema de créditos do ScraperAPI realmente funciona (a parte que a maioria das análises ignora)
O ScraperAPI cobra com base em créditos. A lógica básica parece simples: 1 requisição à API = 1 crédito. Só que, na prática, quase nunca é assim. O custo real em créditos depende de dois fatores: o domínio que você está raspando e os recursos que você ativa. E esses custos vão se acumulando de um jeito nada intuitivo.
A tabela de multiplicadores de crédito que todo usuário deveria ver antes de se cadastrar

Antes mesmo de ligar qualquer parâmetro, o tipo de site que você vai raspar já define o custo base em créditos:
| Categoria do domínio | Créditos base por requisição | Exemplos |
|---|---|---|
| Sites comuns | 1 | Blogs, sites de notícias, HTML simples |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (motores de busca) | 25 | Google, Bing |
| Redes sociais | 30 |
Além disso, os recursos extras somam mais créditos:
| Parâmetro | Créditos extras | Observações |
|---|---|---|
render=true (renderização JS) | +10 | Em todos os planos |
screenshot=true | +10 | Em todos os planos |
premium=true (proxy premium) | +10 | Em todos os planos |
ultra_premium=true | +30 | Apenas planos pagos |
| Bypass anti-bot (Cloudflare, DataDome, PerimeterX) | +10 cada | Detectado automaticamente — você não escolhe isso |
premium=true + render=true combinados | +25 | NÃO +20 |
ultra_premium=true + render=true combinados | +75 | NÃO +40 |
Essa última linha é o grande detalhe. Combinar recursos custa MAIS do que a soma dos custos individuais. Proxy premium (+10) mais renderização JavaScript (+10) deveria custar, logicamente, +20 créditos extras, mas o ScraperAPI cobra . Ultra-premium (+30) mais renderização JavaScript (+10) deveria custar +40, mas na prática sai por — quase o dobro. Esse acúmulo não linear não é explicado com destaque na documentação, e é a principal razão de tanta gente dizer que os créditos somem mais rápido do que esperavam.
Parâmetros que não custam créditos extras: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
O que cada plano realmente entrega: do Free ao Enterprise
Aqui estão os :
| Plano | Preço mensal | Anual (por mês) | Créditos de API | Threads simultâneas | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Não |
| Hobby | $49 | $44 | 100.000 | 20 | Apenas EUA e UE |
| Startup | $149 | $134 | 1.000.000 | 50 | Apenas EUA e UE |
| Business | $299 | $269 | 3.000.000 | 100 | Por país (mais de 50 países) |
| Scaling | $475 | $427 | 5.000.000 | 200 | Por país |
| Enterprise | Personalizado | Personalizado | 5.000.000+ | 200+ | Por país |
Agora, veja o custo efetivo por 1.000 requisições em cada plano, já considerando os multiplicadores:
| Plano | Padrão (1×) | Renderização JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0,49 | $4,90 | $2,45 | $12,25 | $36,75 |
| Startup ($149) | $0,15 | $1,49 | $0,75 | $3,73 | $11,18 |
| Business ($299) | $0,10 | $1,00 | $0,50 | $2,49 | $7,48 |
| Scaling ($475) | $0,10 | $0,95 | $0,48 | $2,38 | $7,13 |
Um plano de $49/mês anunciado como “100.000 créditos” entrega apenas 1.333 requisições reais ao raspar sites protegidos com ultra-premium mais renderização JavaScript. Isso equivale a — mais caro do que muitos serviços de scraping totalmente gerenciados.
Por que os créditos acabam mais rápido do que você espera
Três coisas costumam pegar os usuários de surpresa.
Primeiro: a precificação por domínio é automática. Você não escolhe o multiplicador 5× da Amazon nem o 25× do Google. Ele é aplicado quando o ScraperAPI detecta o domínio. O mesmo vale para os créditos de bypass anti-bot (+10 para Cloudflare, DataDome, PerimeterX) — eles também entram automaticamente quando detectados.
Segundo: os créditos NÃO acumulam para o próximo ciclo. Os créditos não usados . Não existe acúmulo.
E terceiro — esse pega pesado — o Pay-As-You-Go só está disponível no plano Scaling ($475/mês) ou acima. Se você estiver no Hobby, Startup ou Business e estourar os créditos no meio do ciclo, simplesmente fica sem acesso até o próximo período de cobrança. A única saída é fazer upgrade para o plano seguinte.
Um usuário no Reddit contou que recebeu uma cotação de US$ 3.600 por 60 milhões de créditos a 1 crédito por requisição da Amazon, mas, depois do pagamento, foi aplicado um multiplicador de 5 créditos sem aviso prévio. O plano de 60 milhões acabou virando, na prática, apenas 12 milhões de requisições — um em relação ao esperado.
A armadilha de créditos do DataPipeline
O recurso no-code DataPipeline do ScraperAPI (scraping agendado com entrega via webhook) usa uma tabela de créditos separada, bem mais cara. Uma requisição básica comum custa na API padrão:
| Tipo de requisição | API padrão | DataPipeline | Relação |
|---|---|---|---|
| Requisição básica normal | 1 | 6 | 6× |
| E-commerce básico | 5 | 10 | 2× |
| SERP básico | 25 | 30 | 1,2× |
| Ultra-premium + JS (normal) | 75 | 80 | 1,07× |
Usuários que montam pipelines no-code esperando custos normais acabam gastando 6× mais créditos em requisições básicas. Isso está documentado, mas você precisa procurar bastante para encontrar essa informação.
Custo real por requisição: ScraperAPI vs. concorrência
Preço de capa não significa nada sem considerar os multiplicadores. Comparei os preços atuais de cinco fornecedores e padronizei a comparação em torno da faixa de cerca de US$ 300/mês em três cenários comuns.
Extração HTML básica (sem JS, sem proxy premium)
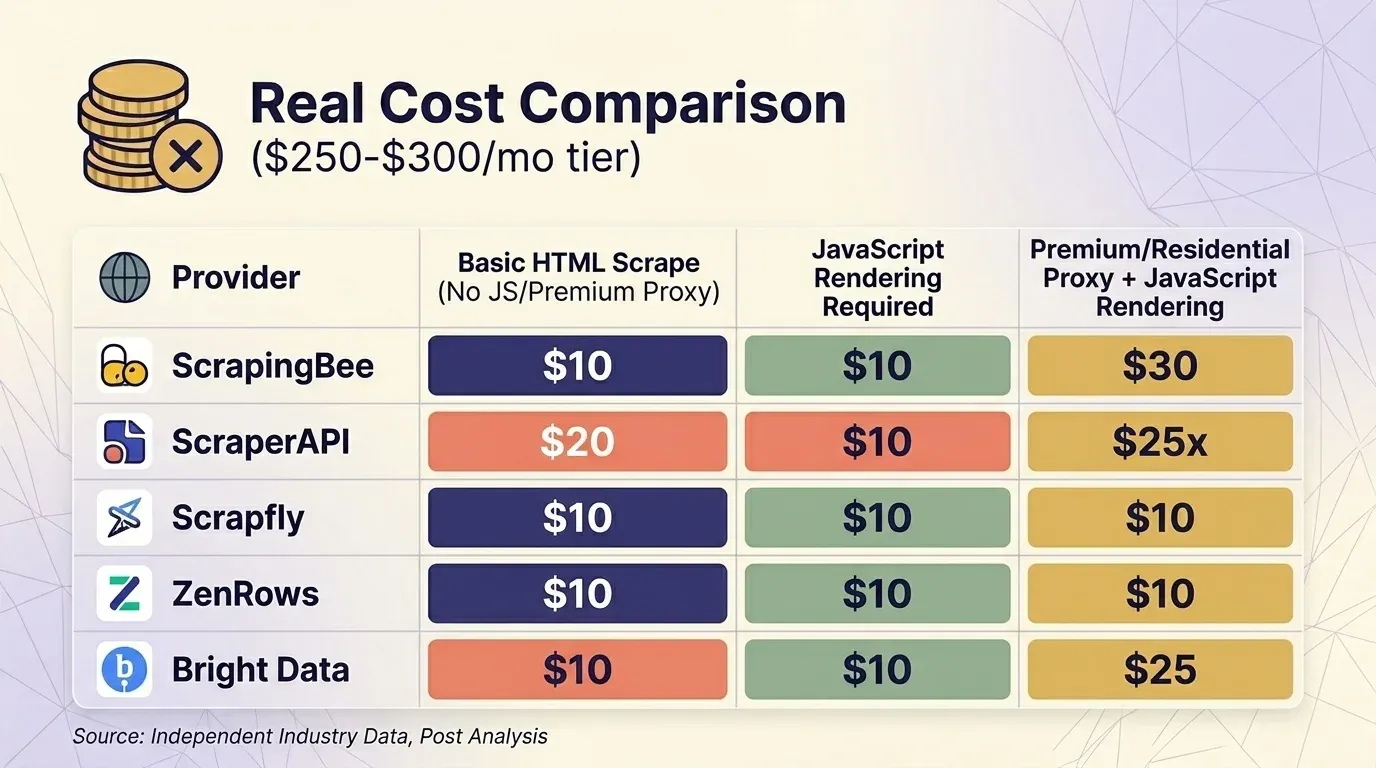
| Fornecedor | Plano | Créditos por requisição | Requisições reais | Custo por 1 mil |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0,08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0,10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0,10 |
| ZenRows | Business $300 | $0,28/1K | ~1.071.000 | $0,28 |
| Bright Data | PAYG | $1,50/1K | ~200.000 | $1,50 |
Quando é necessária renderização de JavaScript
| Fornecedor | Plano | Créditos por requisição | Requisições reais | Custo por 1 mil |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (ligado por padrão) | 600.000 | $0,42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0,60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1,00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1,40 |
| Bright Data | PAYG | fixo | ~200.000 | $1,50 |
Proxy premium/residencial + renderização de JavaScript (sites protegidos)
| Fornecedor | Plano | Créditos por requisição | Requisições reais | Custo por 1 mil |
|---|---|---|---|---|
| Bright Data | PAYG | fixo | ~200.000 | $1,50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2,08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2,49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3,10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7,00 |
O Web Unlocker da Bright Data é o único fornecedor que — todas as requisições têm a mesma tarifa fixa. Na faixa de cerca de US$ 300, ScrapingBee e ScraperAPI são competitivos para scraping de sites protegidos, enquanto o ZenRows é o mais caro.
Um ponto importante de comportamento: o ScrapingBee com custo de 5×. Se estiver comparando ScrapingBee e ScraperAPI lado a lado, certifique-se de comparar as mesmas configurações de renderização.
Uma análise independente da Scrape.do concluiu que o ScraperAPI custa em média — “mais do que qualquer outro fornecedor testado” — com tempo médio de resposta de , o que o torna “um dos fornecedores mais lentos disponíveis”. Vale saber isso antes de fechar contrato.
Taxa de sucesso por site: onde o ScraperAPI brilha e onde tropeça
Nenhuma API de scraping funciona igualmente bem em todos os sites. Benchmarks independentes da Scrapeway (abril de 2026) mostram um cenário bem dividido.
Desempenho por categoria de site
| Site-alvo | Taxa de sucesso | Velocidade média | Custo por 1 mil (plano Business) |
|---|---|---|---|
| Zillow | 100% | 10,5s | $0,49 |
| Etsy | 99% | 4,8s | $4,90 |
| Amazon | 98% | 6,5s | $2,45 |
| 95% | 17,8s | $14,70 | |
| Walmart | 93% | 11,4s | $2,45 |
| Indeed | 90% | 15,8s | $4,90 |
| StockX | 84% | 3,9s | $4,90 |
| Realtor.com | 12% | 11,8s | $0,49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Taxa média geral de sucesso: , ligeiramente acima da média do setor, que fica em 58,2–59,5%. Tempo médio de resposta: 5,2–7,3 segundos, melhor que a média do setor de 9,8 segundos.
Onde o ScraperAPI funciona bem
O ScraperAPI é realmente forte em e-commerce (Amazon, Walmart, Etsy) e imóveis (Zillow). Os endpoints de dados estruturados para esses sites retornam JSON parseado com alta confiabilidade. Se o seu caso principal é raspar páginas de produtos da Amazon ou SERPs do Google, o ScraperAPI é uma opção razoável.
Onde o ScraperAPI fica devendo
Redes sociais são um buraco negro. Instagram, Twitter/X e Booking.com apresentam taxa de sucesso de 0% nos testes independentes. O LinkedIn funciona em 95%, mas o custo de 30 créditos por requisição é alto.
Sites com login são explicitamente proibidos. O ScraperAPI oferece persistência de sessão via parâmetro session_number, mas . Ele não lida com preenchimento de formulários, autenticação em dois fatores ou fluxos de login complexos.
Dados desatualizados em alvos protegidos. O ScraperAPI aplica um , o que significa que, se você estiver raspando dados sensíveis ao tempo (preços, estoque), pode receber resultados com até 10 minutos de atraso.
No benchmark de 2025 da Proxyway, o ScraperAPI teve a , com 81,72%.
Resumo de desempenho por categoria de site
| Categoria do site | Desempenho do ScraperAPI | Problemas conhecidos | Alternativa possível |
|---|---|---|---|
| Amazon / e-commerce | ✅ Forte (endpoints SDP) | Muito caro em escala | Modelos Thunderbit (1 clique, sem créditos por linha para o template) |
| SERPs do Google | ✅ Forte | Geotargeting custa extra; pior taxa de sucesso no Google em um benchmark | — |
| Imóveis (Zillow) | ✅ Excelente (100%) | — | — |
| Instagram / redes sociais | ❌ 0% de sucesso | Falha total | Playwright + proxies (faça você mesmo) |
| SPAs com muito JavaScript | ⚠️ Moderado | Exige renderização headless com custo de 10× em créditos | Scrapfly, ZenRows |
| Sites que exigem login | ❌ Proibido pelos Termos de Uso | Sem suporte a sessão/autenticação | Browser Scraping do Thunderbit (usa sua sessão de login) |
| Booking.com / viagens | ❌ 0% de sucesso | Falha total | Bright Data |
O que usuários reais dizem: resumo de sentimento no G2, Capterra e Reddit
Reuni comentários de três plataformas. Aqui estão as avaliações atuais:
| Plataforma | Nota | Avaliações |
|---|---|---|
| G2 | 4,4/5 | 16 |
| Capterra | 4,6/5 | 62 |
| Trustpilot | 4,5/5 | 43 |
Subnotas no Capterra: Facilidade de uso 4,9/5, Atendimento ao cliente 4,6/5, Recursos 4,5/5, Custo-benefício 4,5/5.
Resumo de sentimento por tema
| Tema | Sinais positivos | Sinais negativos |
|---|---|---|
| Facilidade de configuração / documentação | “Super fácil de configurar. Dá para começar a raspar em minutos.” — comunidade Latenode; nota 4,9/5 em Facilidade de uso no Capterra | — |
| Transparência de preços | “Faixa de entrada acessível” (várias avaliações no Capterra) | “A quebra do custo em créditos pode ser confusa” — John S., fundador, Capterra (fev. 2025); “Os preços aumentaram 1000% e a qualidade piorou” — CTO, Online Media, Capterra (set. 2022) |
| Confiabilidade | “Funciona muito bem para Amazon/Google” (G2, Capterra) | “O ScraperAPI fica instável em trabalhos pesados” — emcarter, Latenode; “80% de falha em alguns alvos” (Reddit) |
| Suporte ao cliente | “Equipe responsiva” (Capterra) | Usuário relatou ter recebido uma cotação e depois sido cobrado 5× acima, sem aviso prévio (Reddit) |
| Valor ao longo do tempo | Cobra apenas por requisições bem-sucedidas (200/404) | “Se você opera em grande escala, os gastos podem subir rápido” e construir infraestrutura própria é “mais vantajoso no longo prazo” — mikezhang, Latenode |
A conclusão: o ScraperAPI é bem avaliado pela facilidade de configuração inicial e apresenta bom desempenho em alvos populares e bem suportados. As reclamações se concentram em surpresas de preço (multiplicadores, aumentos inesperados) e na confiabilidade em alvos mais difíceis.
Endpoints de dados estruturados do ScraperAPI: valem os créditos premium?
O ScraperAPI oferece em 5 plataformas, retornando JSON já parseado em vez de HTML bruto:
- Amazon (3 endpoints): detalhes do produto por ASIN, resultados de busca e ofertas de concorrentes. Retorna mais de 18 campos, incluindo preço, avaliações, descrições, reviews, BSR, imagens e informações do vendedor. Suporta .
- Google (5 endpoints): (resultados orgânicos, knowledge graph, vídeos, perguntas relacionadas, paginação), Shopping, Maps, News e Jobs.
- Walmart (4 endpoints): Produto, Busca, Categoria e Avaliações.
- eBay (2 endpoints): Produto e Busca.
- Redfin (4 endpoints): Busca, detalhes do agente, imóveis para aluguel e imóveis à venda.
Os SDEs estão disponíveis em todos os planos, inclusive no Free. O ScraperAPI afirma ter nos domínios suportados pelos SDEs — embora benchmarks independentes mostrem um quadro mais nuançado, dependendo do site.
Completude dos dados
O SDP da Amazon é a oferta mais forte do ScraperAPI. Ele retorna um conjunto completo de campos: preço, avaliações, BSR, variações, imagens, informações do vendedor e mais. O SDP de SERP do Google retorna resultados orgânicos, anúncios, trechos em destaque e People Also Ask. A completude dos dados é realmente boa para essas duas plataformas.
Eficiência de créditos: SDP vs. parsing manual
No plano Business ($299/mês, 3 milhões de créditos), raspar 10.000 produtos da Amazon via SDE custa 50.000 créditos (5 créditos cada) — cerca de US$ 5 do valor do plano. Construir seu próprio parser com uma requisição padrão (1 crédito cada) custaria só 10.000 créditos, mas você investiria tempo de desenvolvimento para criar e manter o parser.
Para equipes pequenas sem desenvolvedores, os SDEs economizam tempo de verdade.
Para equipes com capacidade de engenharia raspando em escala, o prêmio de 5× em créditos é difícil de justificar.
Como os SDPs se comparam a templates no-code de scraper
Essa comparação importa mais do que a maioria das análises admite. O oferece templates instantâneos de scraping para Amazon, Shopify, Zillow e que não exigem programação e não cobram créditos por linha para o template em si.
| Fator | ScraperAPI SDP (Amazon) | Template Amazon do Thunderbit |
|---|---|---|
| Tempo de configuração | 30–60 min (código + integração com API) | ~2 minutos (instalar extensão, abrir a Amazon, clicar no template) |
| Custo por 1.000 produtos (plano Business) | ~$5 (50.000 créditos a $0,10/crédito) | ~$16,50 (1.000 linhas × 1 crédito a $0,0165/crédito no Pro) |
| Campos retornados | 18+ (completo) | Nome do produto, preço, avaliação, reviews, imagens, URL e mais |
| Opções de exportação | JSON (requer código para interpretar) | Excel, CSV, Google Sheets, Airtable, Notion — 1 clique |
| Manutenção | O ScraperAPI mantém o SDP | A equipe do Thunderbit mantém os templates |
| Conhecimento técnico | Python/Node.js exigido | Nenhum |
Para equipes de desenvolvimento que fazem scraping de alto volume na Amazon, o SDP do ScraperAPI é mais eficiente em custo por produto em escala. Para usuários de negócio que querem dados da Amazon em uma planilha sem escrever código, o Thunderbit é muito mais rápido de configurar e usar.
Você realmente precisa de uma API de scraping? O caminho no-code que a maioria das análises ignora
Muita gente que procura uma “análise do Scraper API” ainda nem decidiu se vai seguir por um fluxo baseado em API. Na verdade, está tentando descobrir se precisa mesmo disso.
E um número surpreendentemente grande não precisa. O mercado de APIs de web scraping é uma indústria de , com crescimento anual composto de 14–18%, mas esse crescimento vem muito mais de equipes de engenharia corporativas — não do gestor de operações comerciais que precisa de 500 leads de um site.
API de scraping vs. ferramenta no-code: uma decisão lado a lado
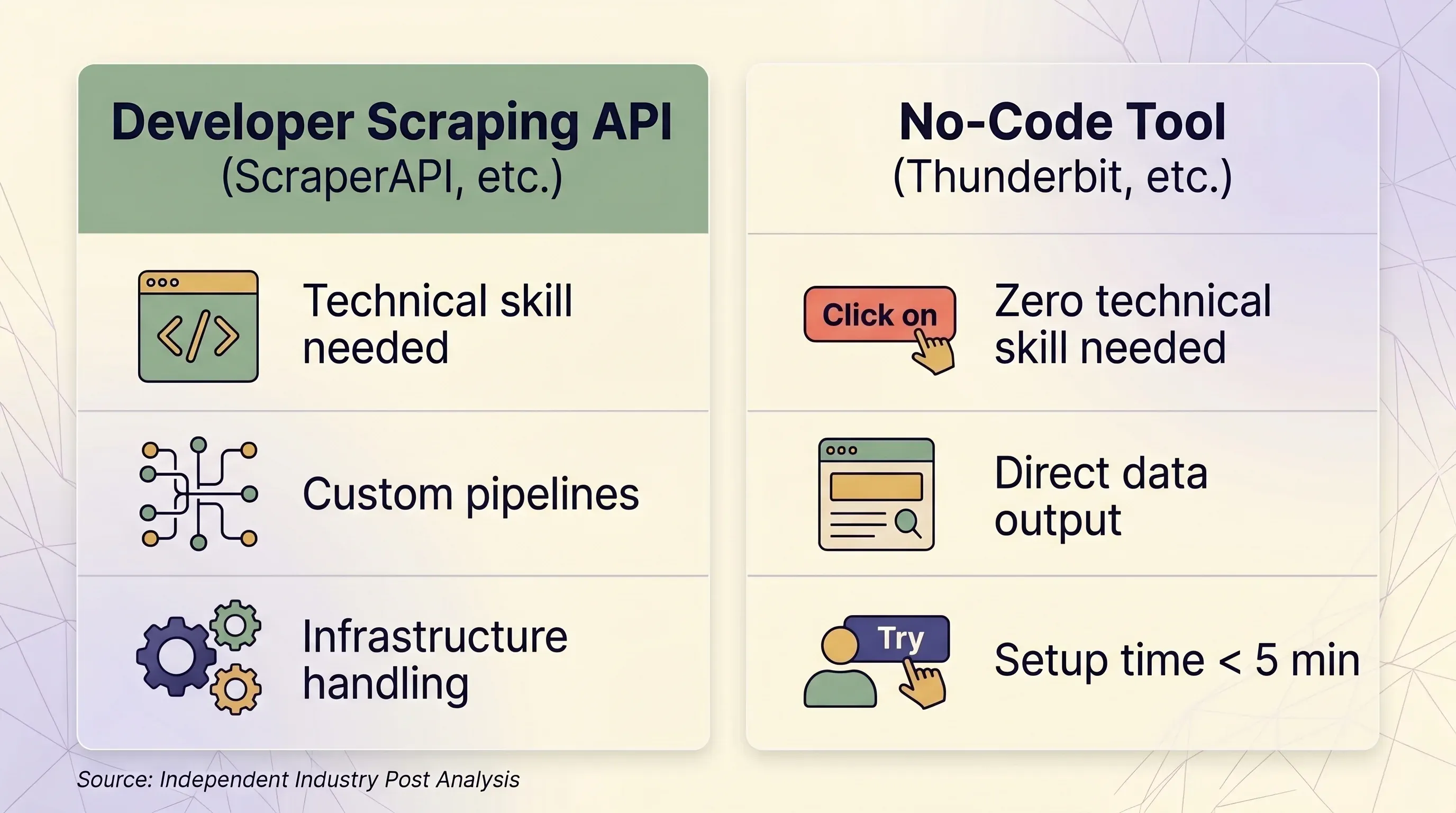
| Fator | API de scraping (ScraperAPI etc.) | Ferramenta no-code (Thunderbit etc.) |
|---|---|---|
| Melhor para | Desenvolvedores criando pipelines de dados em escala | Usuários de negócio, marketing, vendas e pesquisa |
| Conhecimento técnico necessário | Python/Node.js, conceitos de HTTP, parsing de JSON | Nenhum — clique e use no navegador |
| Tempo de configuração | Pelo menos 1–2 horas (código + teste + depuração) | Menos de 5 minutos |
| Tratamento anti-bot | Proxies premium (10–75 créditos/requisição) | Sessão real do navegador — contorna fingerprinting naturalmente |
| Sites que exigem login | ❌ Proibido pelos Termos do ScraperAPI | ✅ O Browser Scraping usa sua sessão existente |
| Escala (páginas/dia) | 100 mil–3 milhões+ de requisições/mês | Sob demanda, normalmente menos de 1.000 páginas/dia |
| Saída dos dados | HTML bruto ou JSON (exige código para processar) | Linhas/colunas estruturadas — prontas para uso |
| Exportação | JSON, CSV (via código) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON |
| Manutenção | É preciso atualizar seletores, lógica de retry e infraestrutura | Nenhuma — a IA relê a estrutura da página sempre |
| Unidade de preço | Créditos por requisição (variável: 1–75 créditos/requisição) | Créditos por linha (1 crédito = 1 linha, 2 para subpáginas) |
| Preço de entrada | $49/mês por 100 mil créditos | $9/mês por 5.000 créditos (anual) |
| Plano grátis | 1.000 créditos/mês, 5 simultâneos | 6 páginas/mês, 30 créditos/página |
| Previsibilidade de preço | Baixa — multiplicadores criam custos surpresa | Alta — 1 linha sempre = 1 crédito |
Quando uma API de scraping faz sentido
- Você tem um desenvolvedor ou uma equipe de engenharia
- Precisa raspar 100 mil+ páginas por dia de forma programática
- Precisa de personalização profunda de headers, sessões e lógica de retry
- Seus alvos são bem suportados (Amazon, Google, Walmart, Zillow)
Quando uma ferramenta no-code como o Thunderbit faz mais sentido
- Você trabalha com vendas, e-commerce ops, marketing ou mercado imobiliário — não com engenharia
- Precisa de dados de dezenas de sites diferentes sem construir parsers personalizados para cada um
- Quer exportar direto para Excel, Google Sheets, Airtable ou Notion
- Precisa raspar sites que exigem login (o do Thunderbit usa sua sessão)
- Quer que a IA leia a página de novo toda vez — sem manutenção de código quando os sites mudam o layout
- Precisa raspar subpáginas: o Thunderbit pode visitar cada página de detalhe e enriquecer as linhas automaticamente
O fluxo da é mesmo simples: instale a extensão, acesse qualquer página, clique em “AI Suggest Fields”, clique em “Scrape” e exporte. A IA identifica quais dados existem na página e sugere colunas — você não precisa escrever seletores nem código. Para saber mais, veja nosso .
tiveram estouro de custos em nuvem em 2024, e empresas que usam preços baseados em uso sem proteções adequadas apresentam por causa do susto na fatura. A previsibilidade de um modelo de créditos por linha vale ser considerada se você já foi surpreendido por custos variáveis de API antes.
Prós e contras do ScraperAPI em resumo
| Prós | Contras |
|---|---|
| Infraestrutura de proxy forte (mais de 40 milhões de IPs, mais de 50 países) | Sistema de multiplicadores de crédito confuso — combinar recursos custa mais do que a soma |
| Documentação excelente e configuração inicial fácil (Facilidade de uso no Capterra: 4,9/5) | Créditos NÃO acumulam de um mês para o outro |
| Confiável em Amazon, Google, Zillow e Etsy | 0% de sucesso em Instagram, Twitter/X e Booking.com |
| Cobra apenas por requisições bem-sucedidas (200/404) | Respostas 404 também consomem créditos |
| 18 endpoints de dados estruturados com saída JSON parseada | Sites com login são explicitamente proibidos |
| Disponível em todos os planos, inclusive Free | Pay-As-You-Go só no Scaling ($475/mês) ou acima |
| Política de reembolso de 7 dias sem perguntas | Cache forçado de 10 minutos em alvos difíceis — risco de dados desatualizados |
| Crescimento de receita de 30–35% ao ano indica desenvolvimento ativo | O DataPipeline pode custar até 6× os créditos da API padrão |
| — | Geotargeting além de EUA e UE exige o plano Business ($299/mês) |
| — | Sem alertas proativos de uso — é preciso verificar o painel manualmente |
Dicas práticas para tirar o máximo do ScraperAPI (se você decidir usar)
Monitore seu consumo de créditos todos os dias
O traz estatísticas de uso, incluindo latência média, domínios raspados e métricas de concorrência. Porém, não há alertas proativos de uso — nada de e-mail ou SMS quando os créditos estão acabando. Você precisa verificar manualmente. O histórico de análises é limitado a 2 semanas nos planos Hobby/Startup e 6 meses no Business+.
Coloque um lembrete no calendário para checar o painel todos os dias durante o primeiro mês. Você precisa ganhar noção de como os créditos queimam nos seus alvos específicos.
Comece pelo plano gratuito para testar seus sites-alvo
Use os 1.000 créditos grátis (além do teste de 7 dias com 5.000 créditos) para testar as taxas de sucesso nos seus sites-alvo antes de fechar um plano pago. Registre quais sites exigem renderização de JavaScript ou proxies premium para estimar custos mensais reais com os multiplicadores incluídos.
Desative recursos premium a menos que o alvo realmente precise deles
O ScraperAPI NÃO ativa automaticamente proxies premium nem renderização de JavaScript — você precisa definir explicitamente render=true, premium=true ou ultra_premium=true. Mas a precificação por domínio É automática: Amazon sempre custa 5 créditos, Google sempre custa 25 e LinkedIn sempre custa 30. Os créditos de bypass anti-bot (+10 para Cloudflare, DataDome, PerimeterX) também são adicionados automaticamente quando detectados. Saiba disso antes de rodar um lote.
Use endpoints de dados estruturados para sites compatíveis
Se você estiver raspando Amazon ou Google, os SDEs economizam tempo de desenvolvimento mesmo custando mais créditos. Para sites sem suporte, avalie se uma não seria mais rápida e mais barata do que construir um parser personalizado.
Tenha um plano B para alvos instáveis
Se a taxa de sucesso do ScraperAPI em um site específico ficar abaixo de 90%, considere redirecionar essas requisições para outro fornecedor ou usar uma ferramenta baseada em navegador. Para sites que exigem login, o ScraperAPI simplesmente não funciona — você vai precisar de uma ferramenta como o , que opera dentro da sua sessão do navegador.
Conheça os pontos de atenção
- Respostas 404 consomem créditos — o ScraperAPI cobra tanto por status 200 quanto 404
- Requisições canceladas são cobradas se você cancelar antes do término da janela de processamento de 70 segundos
- Cache forçado de 10 minutos em alvos difíceis — você pode receber dados desatualizados
- Pay-As-You-Go só no Scaling ($475/mês) ou acima — usuários de planos menores que esgotarem os créditos são bloqueados
- Geotargeting além de EUA e UE exige o plano Business ($299/mês)
Principais conclusões: o ScraperAPI é a ferramenta certa para você?
Depois de toda a pesquisa, cheguei a esta conclusão:
- O ScraperAPI é uma boa escolha para equipes de desenvolvimento que fazem scraping em alto volume de alvos bem suportados, como Amazon, Google, Walmart e Zillow. Os endpoints de dados estruturados são realmente úteis, a infraestrutura de proxy é grande e a documentação está acima da média.
- O sistema de multiplicadores de crédito é o maior risco. Se você não entender como os multiplicadores se acumulam, vai gastar mais do que deveria. A diferença entre créditos anunciados e requisições reais pode variar de 5× a 75×. Faça as contas para o seu caso antes de assinar um plano pago.
- A confiabilidade depende do site. O ScraperAPI é excelente em e-commerce e imóveis, mediano em sites de vagas e redes sociais, e completamente inútil em Instagram, Twitter/X e Booking.com. Não presuma desempenho uniforme.
- Para times sem perfil técnico, o ScraperAPI é a ferramenta errada. Se você trabalha com vendas, marketing ou operações e precisa de dados estruturados sem programar, uma ferramenta no-code como o leva você até lá em dois cliques — com detecção de campos por IA, exportação direta para planilhas, enriquecimento de subpáginas e sem custo de manutenção. Veja a ou assista aos tutoriais no .
- Para desenvolvedores com orçamento limitado, teste o plano grátis do ScraperAPI nos seus alvos específicos e depois compare o custo efetivo por requisição com ScrapingBee, Scrapfly e Bright Data antes de escolher. A opção mais barata depende totalmente do seu caso de uso e dos recursos necessários.
Quer ver como os números ficam no seu caso específico de scraping? Comece com o plano grátis do ScraperAPI para testar seus sites-alvo ou para ver o quanto duas cliques podem fazer. Para mais informações sobre , confira nossos planos.
FAQs
O ScraperAPI é gratuito?
Sim, o ScraperAPI oferece um plano gratuito com e um teste de 7 dias com 5.000 créditos. No entanto, os multiplicadores de crédito para renderização de JavaScript, proxies premium ou domínios de alto custo (Amazon = 5×, Google = 25×, LinkedIn = 30×) significam que sua capacidade real pode ser muito menor do que 1.000 requisições. No plano gratuito, proxies ultra-premium não estão disponíveis.
Quanto o ScraperAPI custa por requisição?
Depende bastante dos parâmetros ativados e do domínio-alvo. Uma requisição padrão para um site HTML simples custa 1 crédito. Uma requisição à Amazon custa 5 créditos. Uma requisição de SERP do Google custa 25 créditos. Adicionar renderização de JavaScript soma 10 créditos. Combinar proxy ultra-premium com renderização de JavaScript custa 75 créditos por requisição. No plano Hobby ($49/mês, 100 mil créditos), isso vai de $0,00049 por requisição (padrão) até $0,0368 por requisição (ultra-premium + JS). Veja as tabelas completas acima para mais detalhes.
O ScraperAPI é bom para raspar a Amazon?
O endpoint Amazon Structured Data do ScraperAPI é um dos seus recursos mais fortes, com em benchmarks independentes e saída JSON parseada completa (mais de 18 campos). Porém, cada requisição da Amazon custa no mínimo 5 créditos, então os custos crescem rápido em escala. Para equipes pequenas que querem dados da Amazon em planilhas sem código, o oferece uma alternativa em 1 clique com exportação direta.
Quais são as melhores alternativas ao ScraperAPI?
Para desenvolvedores: (mais barato para HTML básico), (bom para renderização de JavaScript), (melhor para sites protegidos — tarifa fixa independentemente da renderização) e . Para usuários sem perfil técnico: — uma extensão Chrome no-code, com IA, exportação direta para Excel, Google Sheets, Airtable e Notion. Veja nossa para uma análise mais profunda.
O ScraperAPI consegue raspar sites que exigem login?
O ScraperAPI oferece persistência de sessão via parâmetro session_number (mesmo IP em várias requisições), mas . Ele não consegue lidar com preenchimento de formulários, autenticação em dois fatores ou fluxos de autenticação complexos. Para sites que exigem login, ferramentas baseadas em navegador como o — que usa sua sessão atual do navegador para raspar o que você consegue ver — são a opção mais confiável.
Saiba mais