

A maior parte dos textos sobre “Playwright vs Puppeteer” parte da ideia de que um deles precisa ser o melhor raspador. Mas essa premissa já pesa mais do que deveria. Coloquei as duas bibliotecas frente a frente no mesmo conjunto de páginas — um catálogo estático, um catálogo renderizado em JavaScript, um artigo, um erro 500, um pequeno grafo de crawl e dois sites públicos de prática — e o resultado foi praticamente idêntico. Mesmo recall, mesma renderização, mesmos screenshots, mesmas lacunas.
Então, este não é um anúncio de vencedor. Nas tarefas que realmente mostram se uma ferramenta de automação de navegador consegue extrair uma página, nenhuma das duas levou vantagem. O que vem a seguir é a única diferença que realmente deve guiar sua escolha, aquilo que ambas deixam discretamente por sua conta construir, e uma observação sobre a diferença de versões que eu testei (em 2026-07-09).
Por que essa comparação é justa
Textos comparativos têm o péssimo hábito de testar cada ferramenta em páginas diferentes e depois declarar uma vencedora — o que fala mais das páginas do que das ferramentas. Eu evitei isso executando Playwright e Puppeteer contra o mesmo servidor local de testes e os mesmos demos públicos, Books to Scrape e Quotes to Scrape, para que cada número pudesse ser comparado lado a lado.
Só assim uma afirmação de “empate” faz sentido. Se os testes são diferentes, empate vira ruído. Quando tudo é idêntico, byte por byte, os resultados iguais dizem algo real sobre as próprias ferramentas.
O que cada ferramenta realmente é
Puppeteer é uma API JavaScript para controlar o Chrome, operando por meio do Chrome DevTools Protocol. A própria documentação deixa isso bem claro: “uma API JavaScript para controlar o Chrome (e, experimentalmente, o Firefox).” É maduro, centrado em Chrome e baseado em Node.
Playwright se apresenta de forma um pouco diferente — “um framework para Testes e Automação Web” que controla Chromium, Firefox e WebKit por meio de uma única API, com clientes oficiais em JavaScript, Python, Java e .NET. As duas ferramentas têm uma origem parecida (Playwright surgiu a partir da equipe do Puppeteer no Google, antes de ir para a Microsoft), então acabam parecendo mais primas do que rivais.
Para scraping, porém, o comportamento é o mesmo. Inicie um navegador real, abra a página, deixe os scripts rodarem e então leia o DOM renderizado. É exatamente por isso que você escolhe qualquer uma das duas em vez de um parser HTTP: você quer a página depois da execução do JavaScript, não o esqueleto vazio antes disso. Tudo abaixo vem desse mecanismo compartilhado — e é por isso que tanta coisa entre elas termina empatando.
Os resultados, lado a lado
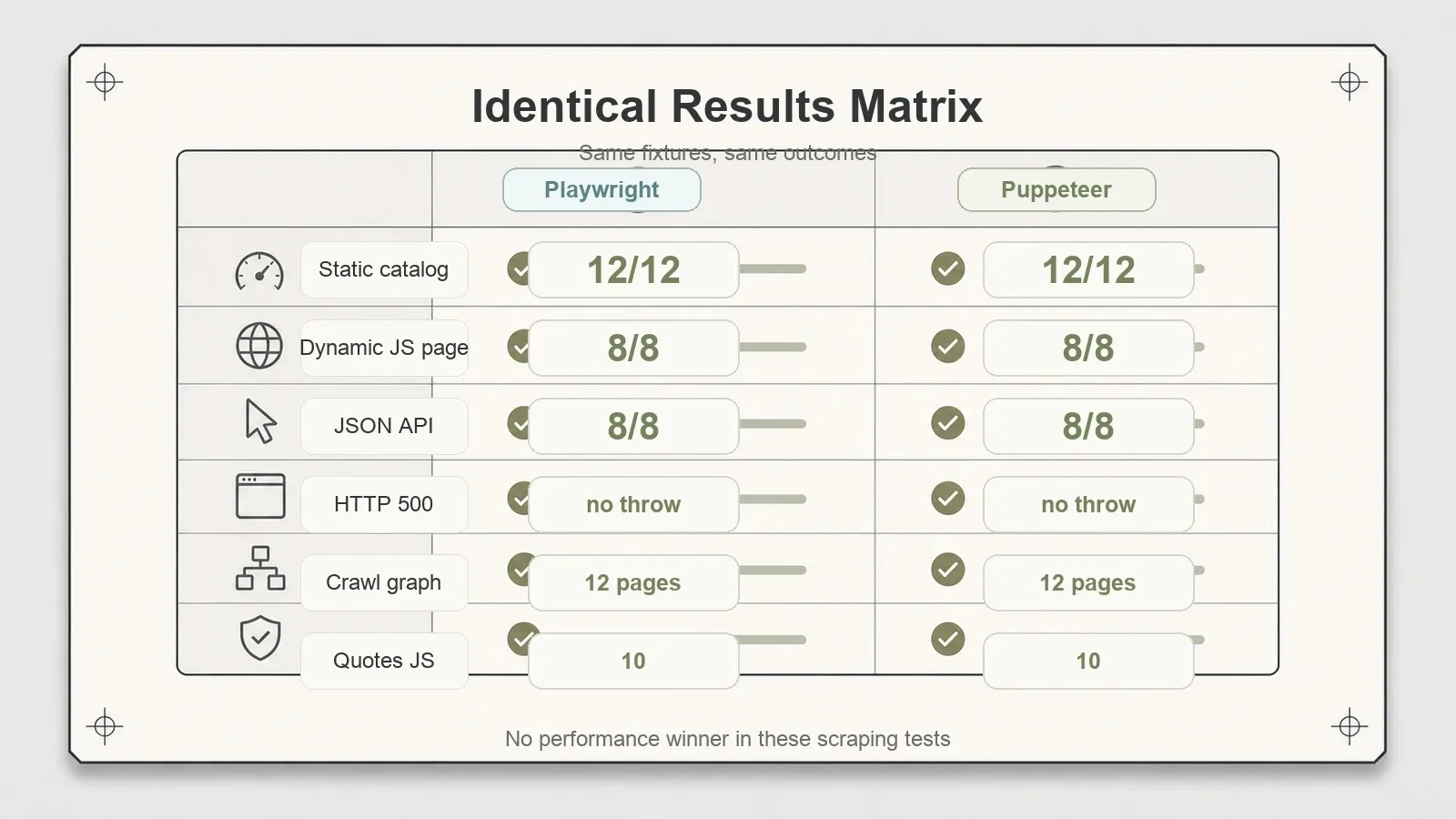
Aqui é onde a narrativa de “uma é claramente melhor” desmorona sem alarde. Mesmos testes, mesmos números, em tudo.
| Teste | Playwright | Puppeteer |
|---|---|---|
| Catálogo estático (12 produtos) | 12/12, recall 1,0 | 12/12, recall 1,0 |
| Artigo (título + 3 parágrafos) | 3/3, boilerplate separado | 3/3, boilerplate separado |
| Página dinâmica em JS (render nativo) | 8/8 + screenshot | 8/8 + screenshot |
| API JSON dinâmica | 8/8, recall 1,0 | 8/8, recall 1,0 |
| Tratamento de HTTP 500 | inspecionável, sem erro lançado | inspecionável, sem erro lançado |
| Grafo de crawl (BFS manual) | 12 páginas, profundidades {0,1,2} | 12 páginas, profundidades {0,1,2} |
| Books to Scrape | 20 produtos | 20 produtos |
| Quotes JS (público) | 10 citações | 10 citações |
As duas renderizaram JavaScript nativamente, sem nenhuma configuração especial. As duas capturaram screenshots em página inteira. As duas trataram o 500 retornando um objeto de resposta inspecionável, em vez de lançar uma exceção — algo pequeno, mas muito importante quando você faz scraping em volume e quer registrar um status ruim sem derrubar a execução.

Vale fazer uma ressalva, porque é fácil exagerar nisso: estas foram observações de uma única máquina e de uma única execução, não benchmarks. Não estou dizendo que uma é milissegundos mais rápida do que a outra, porque um cronômetro por página em um único laptop não é teste de performance. O que eu estou afirmando é mais limitado e melhor fundamentado: em recall de extração e comportamento de renderização, em oito tipos diferentes de página, elas empataram. Se você esperava que uma se destacasse numa página real, isso não aconteceu.
A única diferença que deveria decidir
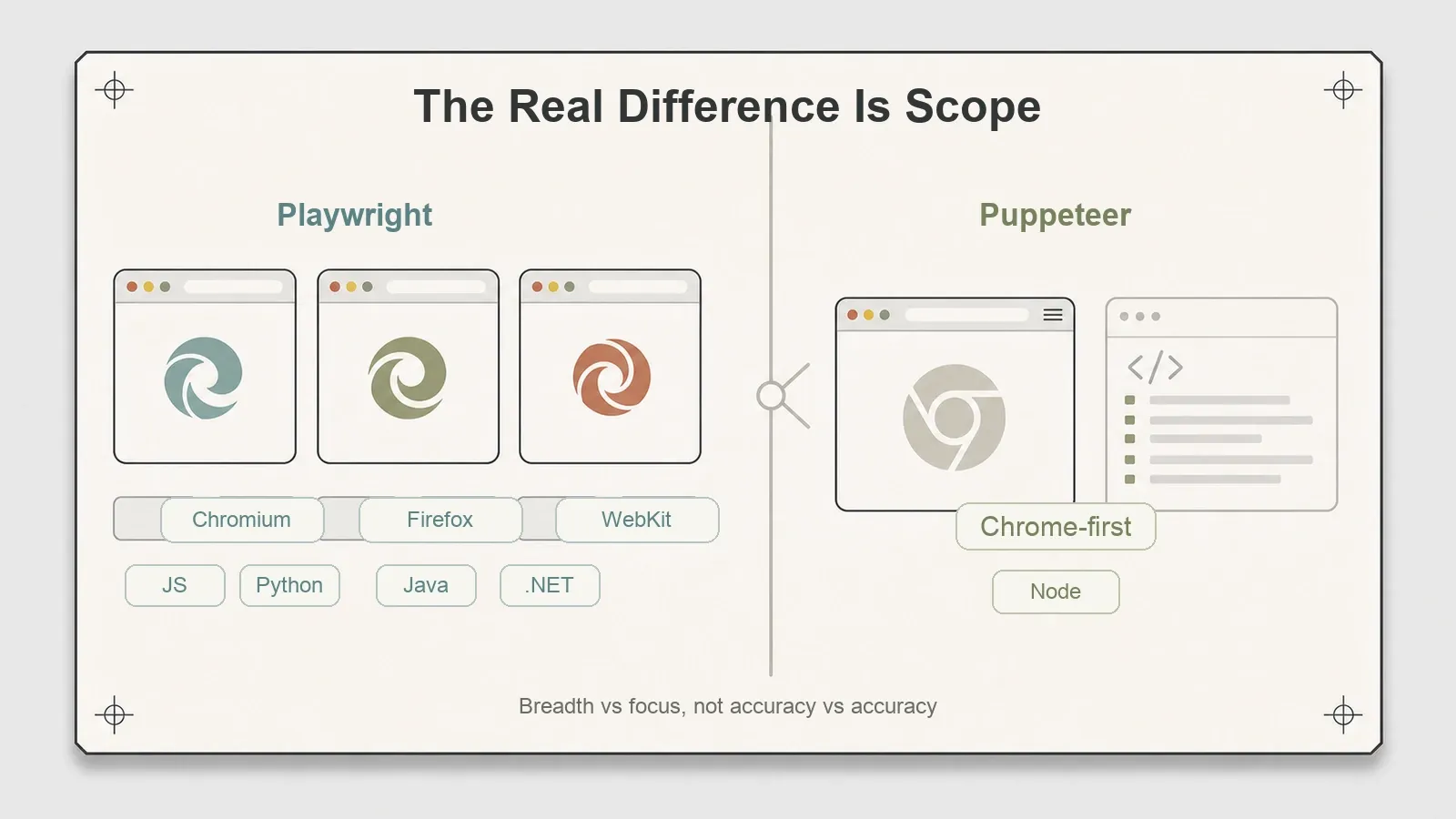
A verdadeira bifurcação não está nos números. Está no escopo.
Playwright controla três motores — Chromium, Firefox e WebKit — por meio de uma única API, e oferece clientes de primeira linha em Python, Java e .NET além de JavaScript. Isso é uma força documentada, e eu quero ser preciso ao usar a palavra “documentada”: neste teste, eu usei apenas Chromium, então estou relatando o suporte aos três motores como uma capacidade declarada que não verifiquei de forma independente, e não como algo que eu tenha testado. Se você precisa extrair um site que se comporta de forma diferente no WebKit do Safari, ou se sua equipe trabalha em Python, essa amplitude é o grande argumento do Playwright.
Puppeteer é voltado primeiro para Chrome, e aqui o resumo popular costuma errar. “Só Chrome” já não é mais correto. Desde o Puppeteer v23, ele passou a oferecer suporte pronto para produção ao Firefox via WebDriver BiDi, mantendo o CDP como padrão para o Chrome e preservando automações existentes — uma mudança documentada tanto pelo Chrome for Developers quanto pela Mozilla. A versão que eu testei (24.16.0) está bem além da v23, então o contraste real não é “Chrome contra três motores”. É este: o Puppeteer cobre Chrome (CDP) mais Firefox (BiDi), mas não WebKit, e sua história de multi-motor é mais recente do que a do Playwright. O motor que o Playwright tem e o Puppeteer não tem é o WebKit.
Essa é a decisão, em resumo. Não é velocidade, nem precisão, nem fidelidade de renderização — nesses pontos existe empate. É uma questão de escopo: você precisa de cobertura para WebKit ou de clientes em linguagens que não sejam JavaScript, ou Chrome e Firefox a partir de Node já bastam para os seus alvos? Para uma boa parte dos trabalhos de scraping, qualquer uma das duas atende, e a escolha passa a ser de aderência à stack, não de capacidade.
O que nenhuma das duas faz
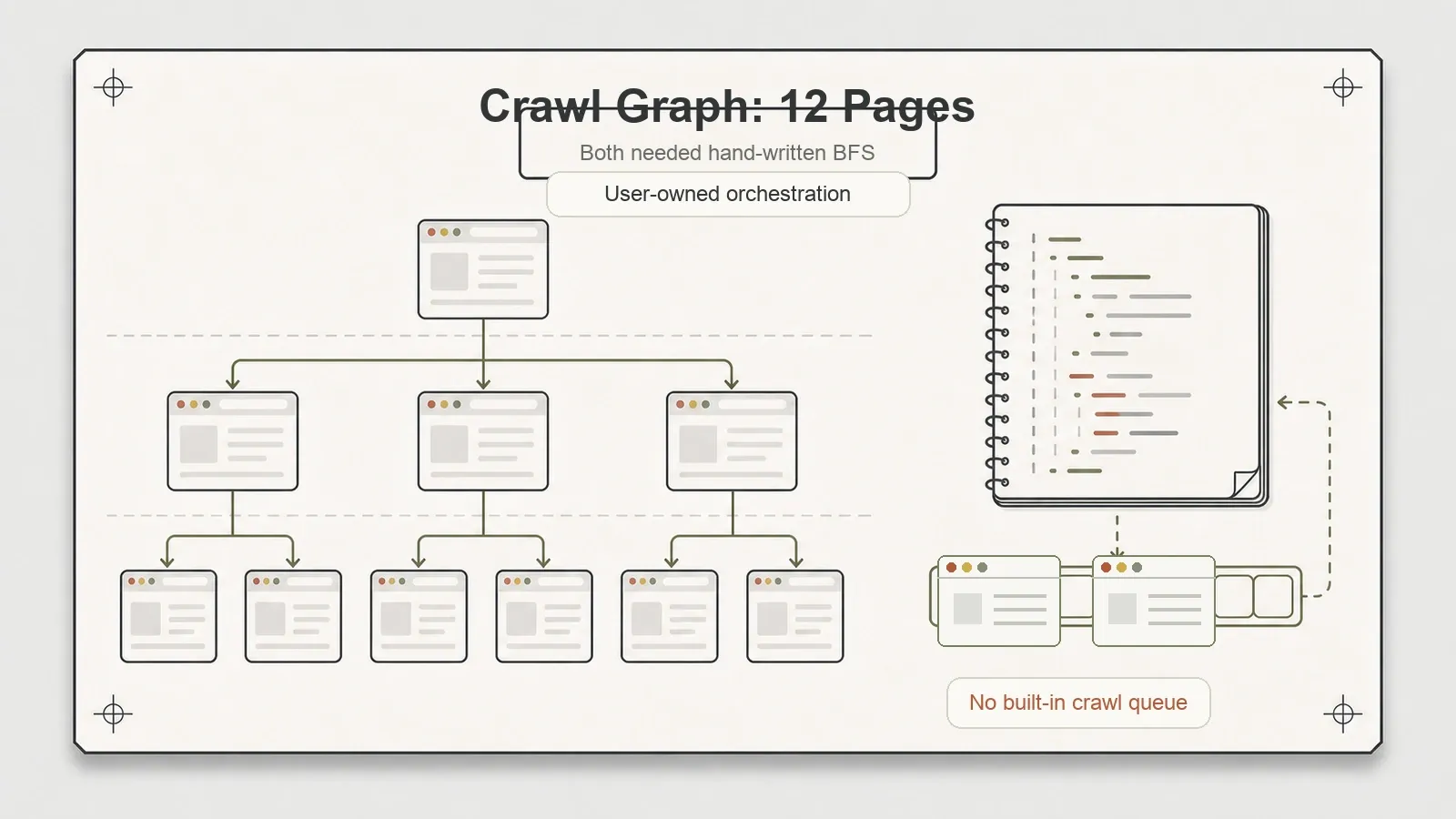
As duas ferramentas deixam a mesma tarefa na sua mesa: orquestração de crawl. Nenhuma traz fila de requisições nativa, gravador de dataset ou auto-throttling. Meu teste de grafo de crawl — seguir links internos, controlar profundidade, não revisitar URL — precisou de uma busca em largura escrita manualmente nos dois casos. Doze páginas, profundidades {0,1,2}, minha própria BFS, nas duas vezes.
Para poucas páginas, tudo bem; uma BFS pequena cabe em uma dúzia de linhas. Para crawls em escala — centenas ou milhares de URLs com deduplicação, novas tentativas e delays de polidez — você vai construir essa infraestrutura por conta própria ou recorrer a algo que já envolva esses motores. Crawlee faz exatamente isso, oferecendo uma camada real de crawling sobre Playwright e Puppeteer.
Isso não é um defeito, e eu quero deixar a atribuição correta: Playwright e Puppeteer são frameworks de automação de navegador, não frameworks de crawler. A fila ausente é um limite de escopo, não um bug. O modelo mental certo é pensar nessas ferramentas como a parte de “enxergar a página” de um scraper. A parte de “percorrer o site” ainda precisa vir de você — seja escrevendo isso, seja adicionando um wrapper que já traga esse recurso.
Instalação e a ressalva de versão
A instalação é quase idêntica. npm install baixa a biblioteca junto com o binário do navegador, e esse binário é a parte pesada — o Puppeteer inclui automaticamente um download do Chrome (uma instalação limpa na minha execução, sem vulnerabilidades reportadas), enquanto o Playwright usa um npx playwright install separado para baixar seus browsers. Nenhuma das instalações é dolorosa, mas reserve tempo para o download em qualquer caso; o peso do navegador e o custo por página são o verdadeiro preço que você paga pela renderização, em comparação com uma ferramenta apenas HTTP.
Agora, a transparência que eu devo a você. Testei Playwright 1.56.0 contra a versão mais recente 1.61.1, e Puppeteer 24.16.0 contra a versão mais recente no npm 25.3.0 — ou seja, o Puppeteer estava uma versão major inteira atrás, tudo em 2026-07-09. As APIs que usei são estáveis apesar dessas diferenças, então os resultados se sustentam. Mas, se você estiver lendo isso algum tempo depois da publicação, rode novamente nas versões atuais antes de apostar números exatos nisso. E, mais uma vez: usei apenas Chromium no Playwright, então não faço nenhuma afirmação sobre a equivalência de Firefox ou WebKit além de “isso está documentado”.
Playwright e Puppeteer: prós e contras
O empate faz com que a lista de prós e contras fale menos de “vencedor” e mais do que você está assumindo ao escolher.
Playwright
- Prós: suporte documentado a três motores (Chromium, Firefox, WebKit) por uma única API; clientes oficiais em Python, Java e .NET; renderização JavaScript nativa com recall total; expansão ativa de suporte.
- Contras: sem fila de crawl integrada; peso do navegador e custo por página; apenas Chromium foi usado neste teste; a versão que eu executei estava atrás da release mais recente.
Puppeteer
- Prós: automação madura e estável do Chrome via CDP; renderização JavaScript nativa com recall total; tratamento limpo de HTTP 500 (objeto de resposta, sem erro); ecossistema amplo e bem consolidado; suporte documentado ao Firefox via WebDriver BiDi desde a v23.
- Contras: prioridade para Chrome e Node, sem motor WebKit; sem fila de crawl integrada; peso do navegador; a versão testada estava uma versão major inteira atrás da mais recente no npm.
Quem deve escolher o quê
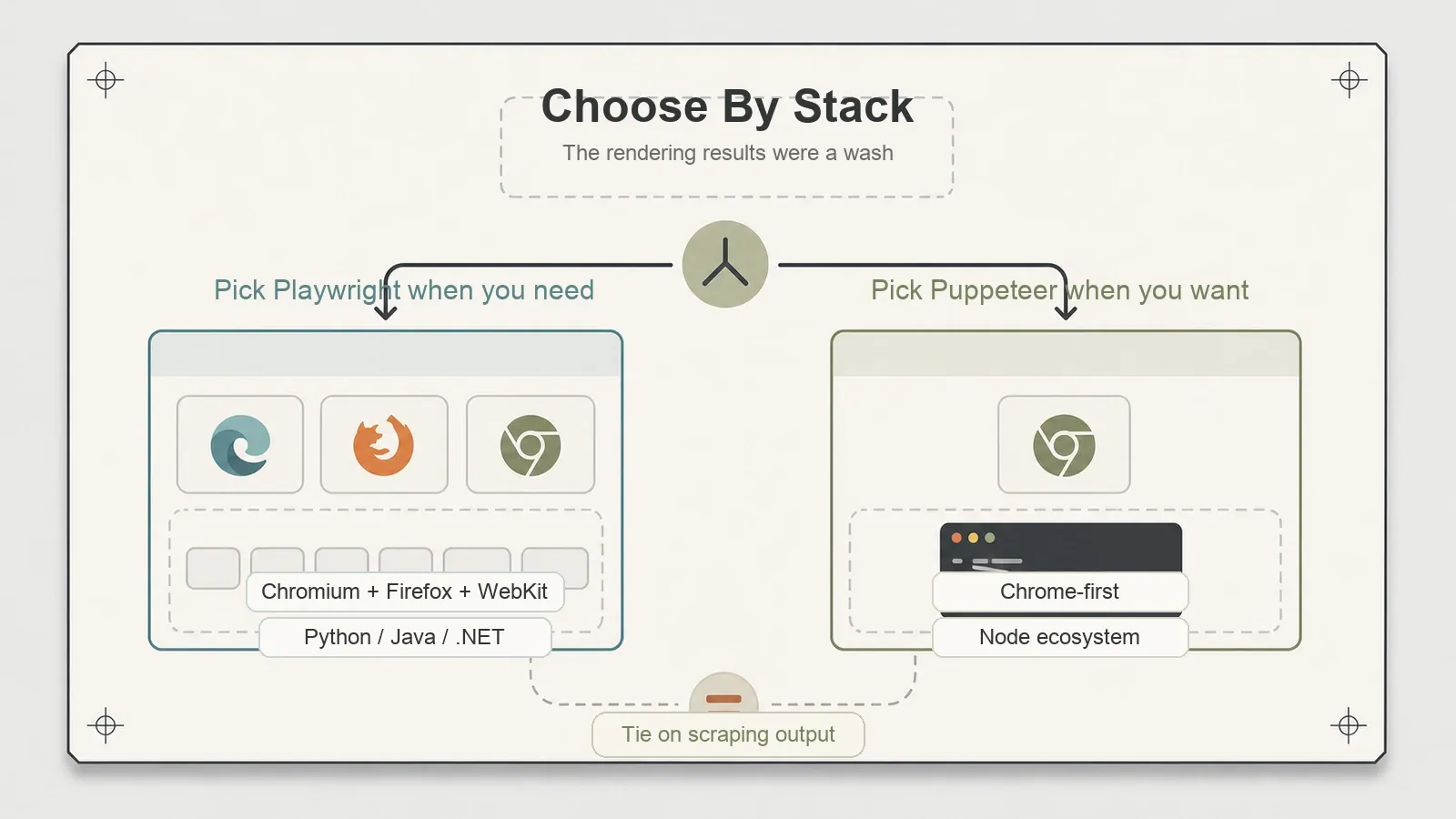
Escolha Puppeteer se você vive em Node, seus alvos renderizam bem no Chrome (a maioria renderiza), e você quer uma biblioteca madura, focada, com um ecossistema profundo e um eixo a menos de complexidade para administrar. A opção de Firefox via BiDi existe caso você precise crescer nessa direção.
Escolha Playwright se você precisa de cobertura para WebKit, quer escrever seu scraper em Python ou .NET, ou prefere apostar no projeto com maior alcance de motores e linguagens. Só esse encaixe de linguagem já costuma ser o motivo mais claro para uma equipe em Python ir de Playwright.
E há uma terceira resposta que esses comparativos costumam ignorar: não escolha nenhum dos dois se suas páginas não precisam de JavaScript para expor os dados. Se uma requisição HTTP e um parser já entregam o conteúdo, um navegador headless é excesso caro e desnecessário — isso pertence a outra categoria de ferramenta, e usá-lo ali só gasta memória e tempo de configuração sem necessidade.
Onde uma API gerenciada entra, incluindo Thunderbit
Experimente Thunderbit para extração de dados da web
Tanto Playwright quanto Puppeteer são bibliotecas gratuitas e open source que você executa e mantém por conta própria. Você é responsável pelo ambiente do navegador, pelas atualizações, pelo código de crawl que adaptar e pela corrida anti-bot. Em muitos projetos, essa responsabilidade é exatamente o que faz sentido, e nada aqui é um argumento contra isso.
Mas repare quanto do trabalho real de scraping fica fora dessas ferramentas. Elas renderizam bem uma página; não gerenciam filas de URLs, não fazem rotação automática em caso de bloqueio, não entregam JSON estruturado pronto e ainda exigem que você mantenha a frota de navegadores. Isso é uma camada diferente da stack em comparação com um serviço gerenciado de extração, e vale nomear isso com clareza para quem está avaliando construir ou comprar. A stack de desenvolvedor do nosso próprio Thunderbit atua nessa outra camada: POST /distill transforma uma página em Markdown limpo, pronto para LLM, e POST /extract devolve JSON estruturado com base em um schema definido por você, com renderização JavaScript, tratamento anti-bot e CAPTCHAs gerenciados no servidor, em vez de no seu laptop. Há um servidor Thunderbit MCP para agentes de IA e assistentes de código (onde thunderbit_suggest_fields roda grátis antes de você gastar qualquer coisa), e também uma CLI via npx @thunderbit/thunderbit-cli para CI e cron.
Não vou fingir que isso é necessariamente melhor — é uma troca de outra natureza. Com Playwright ou Puppeteer, você controla a renderização e tudo o que constrói em volta dela, sem custo por chamada. Com uma API gerenciada, você terceiriza renderização, anti-bot e a infraestrutura de crawl, e paga por requisição (no caso do Thunderbit, cobrado por chamada — um crédito para um distill, vinte para um extract — e não por linha). Projeto pequeno, hospedado por você, e você gosta de controlar o navegador? Essas bibliotecas são as ferramentas certas. Quer escalar e prefere não manter uma frota de headless, um crawler e uma camada de rotação de bloqueios? Um caminho gerenciado elimina essa categoria de trabalho.
Para o panorama mais amplo, nossa equipe também testou a abordagem de dois motores do Crawlee e um conjunto de frameworks HTTP-first contra os mesmos testes, o que é o próximo passo útil se você já concluiu que um navegador completo é mais do que suas páginas realmente exigem.
Veredito
Devo usar Playwright ou Puppeteer? Para renderizar páginas em JavaScript, qualquer um dos dois — eles empataram em todos os testes relevantes aqui, então você não está abrindo mão de capacidade ao decidir por outros critérios. Escolha Puppeteer se Chrome e Firefox a partir de Node encaixam no seu cenário e você quer maturidade e foco. Escolha Playwright se precisa de alcance para WebKit ou de clientes fora de JavaScript.
Dois pontos que esses comparativos costumam deixar de lado valem ser levados com você. Primeiro, em tarefas reais de scraping, esses dois empataram de verdade, então não vale sofrer por uma diferença de performance que simplesmente não apareceu em oito testes diferentes. Segundo, nenhum dos dois é crawler — eles renderizam, e o crawl fica por sua conta ou por conta de um wrapper como o Crawlee. Entendendo isso e alinhando o escopo à sua stack, a escolha fica pequena. A decisão sobre o motor pesa muito menos do que a metade do trabalho que nenhuma das duas ferramentas faz por você.
Saiba mais
Experimente Thunderbit para extração de dados da web Get Started Free
Perguntas frequentes
Playwright ou Puppeteer é mais rápido para web scraping? Nos mesmos testes, o resultado foi praticamente um empate — mesmo recall em páginas estáticas (12/12), dinâmicas (8/8) e extração via API JSON, mesma renderização nativa e mesmo tratamento do 500. Estas foram observações de uma única execução em uma máquina, não benchmarks, então diferenças de tempo por página não representam uma medição real de velocidade. Escolha com base no escopo e na linguagem, não numa diferença de velocidade que não apareceu.
Qual é a diferença real entre Playwright e Puppeteer? Escopo de motores e de linguagem. O Playwright controla Chromium, Firefox e WebKit por uma única API, com clientes em Python, Java e .NET. O Puppeteer é voltado primeiro para Chrome via CDP, com suporte documentado ao Firefox via WebDriver BiDi desde a v23, mas sem WebKit, e é baseado em Node. Ambos renderizam JavaScript nativamente e nenhum inclui orquestração de crawl integrada.
Consigo fazer crawl de um site inteiro com Playwright ou Puppeteer? Não pronto para uso. Nenhum dos dois traz fila de requisições, gravador de dataset ou auto-throttling — meu teste de grafo de crawl precisou de uma BFS escrita manualmente nos dois casos, com doze páginas nas profundidades {0,1,2}. Para escala, adicione uma camada de crawling como o Crawlee, que envolve ambos os motores com a infraestrutura real de crawl.
Preciso mesmo de uma ferramenta de navegador para fazer scraping? Só se a página precisar de JavaScript para revelar os dados. Se uma requisição HTTP mais um parser já entregam o conteúdo desejado, um navegador headless é um gasto caro e desnecessário — use uma ferramenta HTTP-first e elimine totalmente o peso do navegador.
Qual uma equipe de Python deveria escolher? Playwright, porque ele tem cliente Python de primeira linha. Puppeteer é baseado em Node, então usá-lo a partir de Python exige construir uma ponte que você teria de manter. Esse encaixe de linguagem é uma das razões mais claras para escolher Playwright em vez de Puppeteer.




