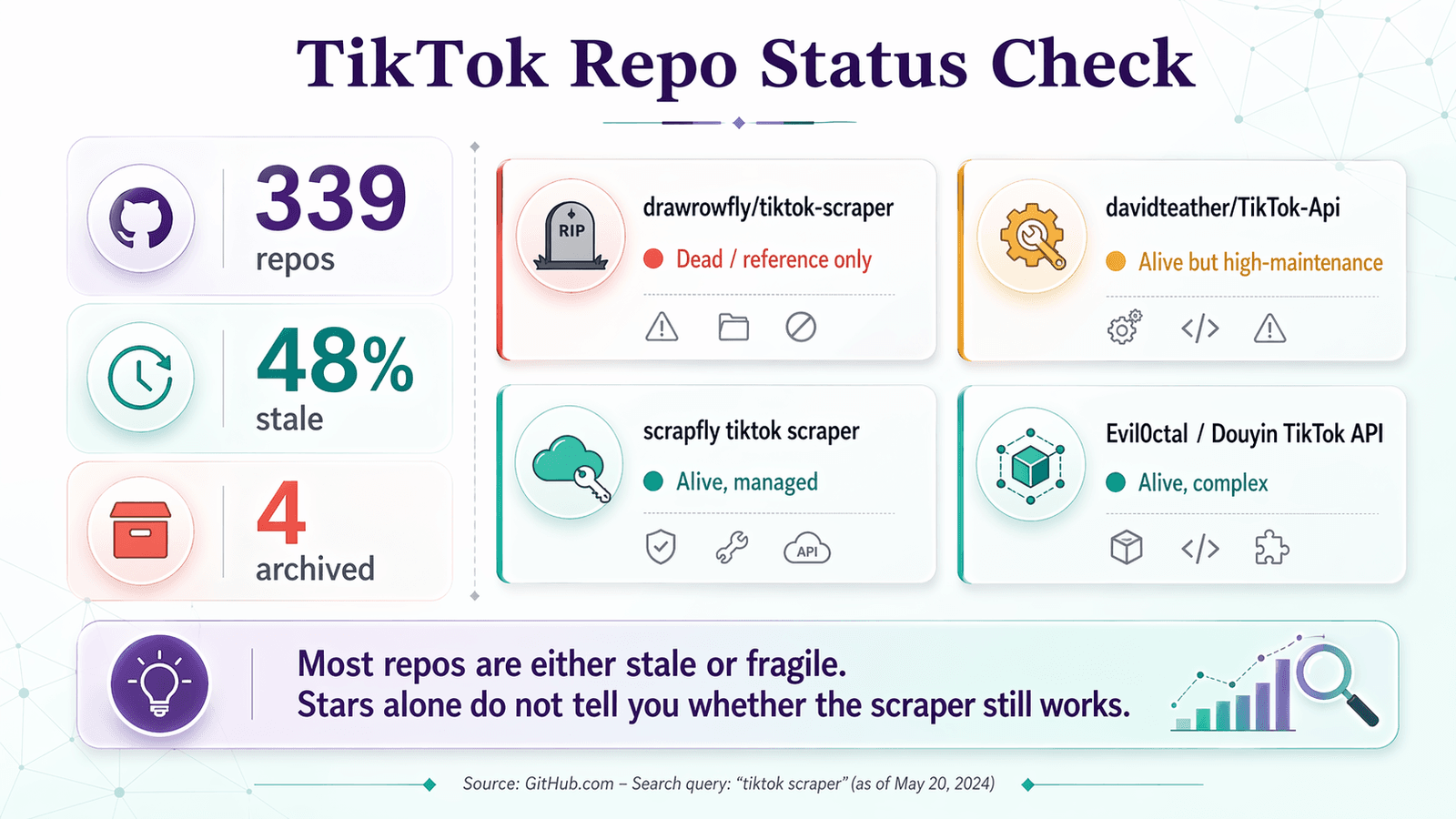
Uma busca no GitHub por "tiktok scraper" retorna . Cerca de não recebem commits há mais de um ano, e pelo menos .
Se já clonou um repositório popular de TikTok scraper, passou uma hora a lutar com dependências e no fim não obteve qualquer saída, não está sozinho. O TikTok scraper com mais estrelas no GitHub, drawrowfly/tiktok-scraper, ainda tem mais de 5.000 estrelas. Mas o rastreador de issues está cheio de tópicos como e — ambos a relatar saída zero. Nos últimos meses, tenho acompanhado na Thunderbit o estado dos repositórios de TikTok scraping, e o padrão é impossível de ignorar: estas ferramentas partem rapidamente e a maioria nunca é corrigida. Este artigo é o guia prático de sobrevivência que eu gostava de ter encontrado quando comecei a avaliar estes repositórios. Vamos ver o que ainda funciona, o que já morreu, o que fazer em alternativa e como deixar de perder horas com código que já não funciona antes mesmo de o encontrar.
Por que é que a maioria dos TikTok Scrapers no GitHub falha (e continua a falhar)
O TikTok não é um alvo típico de scraping. A superfície web muda constantemente. Ao contrário de uma página estática de produto num e-commerce ou de uma listagem de diretório, o TikTok troca endpoints, atualiza a fingerprint anti-bot, altera métodos de renderização da página e introduz novos requisitos de sessão/token — às vezes poucas semanas depois da última alteração.
Os mantenedores de open source são voluntários. Quando o TikTok lança uma atualização que quebra o caminho de requisição do scraper, o repositório pode ficar inoperacional durante dias, semanas ou para sempre. Isto não é uma crítica aos mantenedores — é uma incompatibilidade estrutural entre uma plataforma muito financiada e que muda depressa, e desenvolvedores não remunerados que têm empregos a tempo inteiro.
Mesmo os melhores repositórios de TikTok scraper vivem numa roda-viva de corrigir-quebrar-corrigir. Se quiser usar um, precisa de uma estratégia para avaliar, diagnosticar problemas e ter sempre um plano B.
As defesas anti-bot do TikTok: com o que está a lidar
- Limitação de taxa. A do TikTok documenta explicitamente quotas de requisição até para integrações aprovadas. Scrapers não oficiais batem nestes limites muito mais depressa.
- Bloqueio por cookie e sessão. Repositórios modernos como exigem um
ms_token; repositórios mais antigos como mostramtt_webid_v2nos exemplos; documentamsToken,ttwid,X-BoguseA_Bogus. O TikTok verifica se o pedido parece vir de uma sessão real de navegação. - Fingerprint do navegador. A explica por que razão os sites comparam headers, cookies, assinaturas TLS e atributos do navegador expostos por JavaScript com o tráfego de utilizadores reais. O aborda Canvas, WebGL, WebRTC, fontes e sinais de runtime. A fingerprint é a forma de o TikTok confirmar a identidade do seu navegador — se navegador, cookies, timing e assinatura de rede não coincidirem, o pedido parece falso antes mesmo de qualquer conteúdo ser devolvido.
- Deteção comportamental. Tópicos no sobre scraping do TikTok referem com frequência que sessões novas do Playwright disparam CAPTCHA. Publicações da comunidade de descrevem cada vez mais deteção baseada no timing das ações e na qualidade da interação, e não apenas na reutilização de IP.
- Parâmetros de pedido encriptados/assinados. O Evil0ctal documenta
X-BoguseA_Bogus; gists antigos da comunidade giram em torno de assinatura de URL e geração de token. O TikTok espera cada vez mais que os pedidos cheguem com os mesmos "carimbos" que o tráfego do próprio navegador/app carregaria. - Fluxos de CAPTCHA e verificação. A existência de e confirma que o CAPTCHA continua a fazer parte da superfície anti-bot.
Por que é que os mantenedores de open source não conseguem acompanhar
O ciclo é quase sempre o mesmo. Um developer cria um TikTok scraper. Ele torna-se viral no GitHub. O TikTok corrige a falha. O mantenedor ou resolve o problema ou segue em frente.
Dois repositórios ilustram isto na perfeição:
- drawrowfly/tiktok-scraper ainda tem 5.052 estrelas e 889 forks, mas o seu . É exatamente o TikTok scraper com mais estrelas no GitHub e já parece um artefacto histórico: muita visibilidade, muita confiança, manutenção zero neste momento.
- davidteather/TikTok-Api mostra . O seu mostra manutenção relevante em abril de 2025, julho de 2025, outubro de 2025 e abril de 2026 — incluindo correções para crawling de vídeos de utilizadores e novos controlos de proxy/sessão. Mas mesmo este projeto mais saudável avisa claramente que o TikTok bloqueia pedidos e que os utilizadores podem precisar de proxies, Playwright e lógica personalizada de sessão.
O padrão é simples:
- Um repositório de TikTok scraper desatualizado provavelmente está morto.
- Um repositório ativo de TikTok scraper provavelmente continua frágil.
- A única diferença real é se ainda existe alguém por perto para corrigir as falhas este mês.
Checklist de 60 segundos para verificar a saúde do repositório: como avaliar qualquer TikTok Scraper no GitHub
Antes de clonar qualquer coisa, faça este checklist. Demora menos de um minuto e poupa horas de frustração.
| Sinal | 🟢 Saudável | 🟡 Arriscado | 🔴 Morto |
|---|---|---|---|
| Último push relevante | Há menos de 3 meses | Entre 3 e 12 meses | Há 12+ meses |
| Quantidade de issues abertas | Baixa; issues recentes recebem resposta | A crescer, com alguma atividade do mantenedor | Muitos relatos sem resposta de "quebrado/bloqueado/não funciona" |
| Queixas recentes de utilizadores | Principalmente dúvidas de configuração | Mistura de dúvidas e falhas | Relatos repetidos de "saída zero", "403", "ainda funciona?" |
| Modelo atual de auth/sessão | Caminho de sessão/cookie documentado | Muito baseado em tokens, mas documentado | Depende de endpoints web antigos, sem orientação atual de auth |
| Superfície de instalação | Configuração reproduzível e testada | Alguns passos manuais | Dependências antigas, sem notas modernas de setup |
| CI/testes | Existem e estão atualizados | Existem, mas a cobertura não é clara | Sem testes ou actions desatualizadas |
| Aderência ao âmbito dos dados | Corresponde ao seu caso de uso real | Suporta só parte do caso | Resolve um problema completamente diferente |
Como verificar cada sinal em menos de 60 segundos
- Data do último push: veja o cabeçalho do repositório no GitHub. Se disser "last pushed 2 years ago", pode parar aí.
- Issues abertas: clique no separador Issues. Leia rapidamente os títulos mais recentes. Procure
not working,403,blocked,captchaouzero output. - Queixas de utilizadores: se as 5 issues abertas mais recentes forem variações de "isto já não funciona", já tem a resposta.
- Modelo de auth/sessão: abra o README. Procure orientação atual, como
ms_token, setup com Playwright ou notas sobre proxy. Se o README citar endpoints de 2023, siga em frente. - Superfície de instalação: veja se existe ficheiro de requirements, suporte a Docker ou instruções claras de setup. Se o README disser "npm install" e a última versão de Node testada for 14, espere problemas.
- CI/testes: verifique o separador Actions. Se os testes estiverem a falhar ou inexistentes, a resolução deixa de ser ciência e passa a adivinhação.
- Âmbito dos dados: o repositório descreve mesmo os tipos de dados de que precisa — perfis, metadados de vídeo, comentários, hashtags? Muitos repositórios só fazem download de vídeo, não extraem dados estruturados.
Sinais de alerta que significam "saia fora"
- O repositório está arquivado.
- O README diz "no longer maintained".
- O último commit menciona uma versão da API do TikTok de há 2+ anos.
- As issues estão inundadas com relatos de "doesn't work" e o mantenedor não responde há meses.
- O repositório tem muitas estrelas, mas poucos forks ou pull requests recentes.
Dica: pesquise no separador Issues por is:issue is:open "not working" ou is:issue is:open "403". Se os resultados forem muitos e recentes, o repositório provavelmente está quebrado.
Repositórios populares de TikTok Scraper no GitHub: uma verificação honesta do estado (2026)
Aqui está o checklist de saúde do repositório aplicado aos repositórios que realmente vai encontrar quando procurar "tiktok scraper" no GitHub:
| Repositório | Último Push | Estrelas | Issues Abertas | Veredito | Observação |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5.052 | 58 | 🔴 Morto / apenas referência | Ainda famoso, mas demasiado desatualizado para uso em produção em 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6.301 | 134 | 🟡 Vivo, mas exige muita manutenção | A opção OSS mais forte; espere Playwright, tokens e, muitas vezes, proxies |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (pai) | ~0 (monorepo) | 🟡 Vivo, mas não é OSS puro | Atual e útil, mas requer chave da API ScrapFly |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17.397 | 135 | 🟡 Vivo, amplo, complexo | Projeto multi-plataforma rico em funcionalidades; mais próximo de uma plataforma para utilizadores avançados |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Arriscado | Repositório mais pequeno com queixas em aberto sobre fluxo de informação do utilizador e hashtags |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Demasiado novo para confiar | Repositório de montra, não validado pela comunidade |
drawrowfly/tiktok-scraper
Durante anos, este scraper/downloader em TypeScript foi a resposta padrão para "tiktok scraper github" — cobrindo feeds de utilizadores, tendências, hashtags e música. Em 2026, é melhor tratá-lo como documentação histórica. O , e a fila de issues continua a incluir relatos por resolver de e de 2023–2025. Se está a ler este artigo porque clonou este repositório e não recebeu nada, está em boa companhia.
davidteather/TikTok-Api
O wrapper open source de dados do TikTok mais credível que ainda está vivo em 2026. Está ativo, tem e documenta explicitamente setup com Playwright, uso assíncrono, tratamento de tokens, suporte a proxy e funcionalidades de recuperação de sessão. Mas não é uma ferramenta de "clonar e usar". O próprio README diz que EmptyResponseException normalmente significa que o TikTok está a bloquear o pedido, e o mostra dores recorrentes com ms_token, extração quebrada de comentários, KeyError: 'ItemModule' e falhas específicas de endpoints. Veredito: vivo, útil, apenas para developers e com grande necessidade de manutenção.
Outros repositórios relevantes
- : atual e tecnicamente relevante, mas o README exige uma
SCRAPFLY_KEY. Este é um exemplo de código para uma plataforma de scraping gerida, não uma ferramenta gratuita e independente. - : cobre TikTok e Douyin, documenta lógica de assinatura (
X-Bogus,A_Bogus,msToken) e suporta comentários, seguidores, playlists e muito mais. É tecnicamente exigente e está cada vez mais misturado com referências a APIs pagas. O rastreador de issues mostra bugs em curso em 2026 relacionados com links de vídeo e endpoints de informação do utilizador. Vivo e cheio de funcionalidades, mas complexo. - : mais pequeno, com queixas em aberto. Arriscado para produção.
- : 4 estrelas, 0 issues, demasiado novo para confiar. O artigo no Medium que o promoveu fê-lo sem grande sentido crítico.
API oficial do TikTok vs. scrapers do GitHub vs. ferramentas no-code: um framework de decisão

A maioria dos artigos concorrentes ignora as rotas oficiais de acesso do TikTok ou salta diretamente de "use GitHub" para "compre o nosso serviço". Aqui vai uma comparação neutra dos três caminhos:
| Fator | TikTok Research API | Scrapers do GitHub | Ferramentas No-Code (ex.: Thunderbit) |
|---|---|---|---|
| Barreira de acesso | É necessário pedido académico/empresarial; ~4 semanas para aprovação | Git clone + setup | Instalação de extensão do navegador |
| Âmbito dos dados | Apenas endpoints aprovados (contas, vídeos, comentários, lojas) | Amplo (perfis, vídeos, comentários, hashtags, lojas) | Dados visíveis na página (perfis, vídeos, engagement, hashtags) |
| Carga de manutenção | Baixa (oficial, estável) | Alta (os repositórios partem quando o TikTok atualiza) | Nenhuma (a IA adapta-se a mudanças no layout) |
| Risco de banimento | Nenhum (autorizado) | Alto | Baixo (baseado no navegador, imita utilizador real) |
| Custo | Gratuita (se aprovada) | Gratuito (mas consome tempo) | Plano gratuito disponível; planos por créditos a partir de US$ 15/mês |
| Exige programação | Sim (Python/R) | Sim (Python/Node.js) | Não |
| Melhor para | Investigadores, académicos, organizações aprovadas | Developers confortáveis com manutenção | Profissionais de marketing, vendas, operações e pessoas sem perfil técnico |
Quando a TikTok Research API faz sentido
A do TikTok é o caminho oficial mais limpo, se se qualificar. Investigadores elegíveis nos podem candidatar-se para estudar conteúdo público e dados de contas. As categorias de dados disponíveis incluem contas, seguidores/seguindo, vídeos curtidos, vídeos fixados, vídeos republicados, conteúdo, comentários e lojas. O expõe campos como video_description, view_count, like_count, comment_count, share_count e campos de comentário como text, reply_count e create_time.
A desvantagem: a elegibilidade é limitada a instituições académicas e investigadores independentes ou de organizações sem fins lucrativos em regiões específicas, além de . Se é uma equipa de growth ou uma agência que precisa de dados operacionais rapidamente, este não é o seu caminho.
O TikTok também oferece uma para anúncios e dados de conteúdo de anunciantes, útil para investigação de transparência, mas não para scraping geral.
Quando um scraper do GitHub ainda faz sentido
Scrapers do GitHub continuam a fazer sentido para developers que precisam de acesso não oficial a dados públicos para além da barreira de aprovação da API oficial e estão dispostos a manter a stack. Isto inclui casos como scraping de grelhas visíveis de perfis, hashtags, comentários, playlists ou metadados de vídeo num pipeline personalizado em que fazer fork do repositório e corrigi-lo é aceitável.
A ressalva honesta: isto não é uma configuração única. Mesmo o repositório mais fiável de 2026, , continua a avisar os utilizadores de que poderão precisar de Playwright, cookies/tokens, proxies e fábricas personalizadas de páginas/sessões.
Quando uma ferramenta no-code como a Thunderbit faz sentido
Não é developer? Ou é developer cansado do ciclo de quebrar e corrigir? Uma ferramenta de IA baseada no navegador é o caminho mais rápido para dados estruturados do TikTok.
Criámos a como um raspador web com IA que funciona como extensão do Chrome. No TikTok, lê qualquer página visível — perfil, vídeo, hashtag, resultados de pesquisa —, sugere colunas através de "AI Suggest Fields" e permite clicar em "Scrape" para extrair dados estruturados. A documenta campos como data de publicação, duração do vídeo, gostos, partilhas, guardados, comentários, visualizações e hashtags. O mostra como recolher miniaturas de publicações, URLs, legendas, handles de criadores e sinais de engagement das páginas de perfil. O cobre URL do vídeo, nome de utilizador do criador, descrição, hora de publicação, visualizações, gostos, comentários, partilhas, som/áudio e URL da imagem de capa.
O scraping de subpáginas permite visitar cada página de vídeo a partir de uma listagem de perfil e enriquecer a tabela com métricas de engagement, legendas e hashtags — útil para profissionais de marketing que montam bases de influenciadores ou fazem auditorias ao conteúdo de concorrentes.
Sem manutenção, sem triagem de instalação, sem configuração anti-banimento. A IA adapta-se automaticamente a mudanças no layout. A exportação para Google Sheets, Excel, Airtable, Notion, CSV ou JSON é gratuita.
Se já perdeu horas com repositórios quebrados no GitHub, esta é uma alternativa legítima — não um pitch forçado de produto.
Triagem de instalação: corrigindo as 5 falhas de configuração mais comuns de TikTok Scraper no GitHub
Falhas de instalação são o terceiro ponto de dor mais citado em fóruns de scraping do TikTok, e nenhum guia grande ajuda realmente a resolvê-las. Eis o que costuma correr mal.
Conflitos de versão do Node.js
Problema: Muitos repositórios mais antigos de TikTok scraper (especialmente drawrowfly/tiktok-scraper) foram feitos para Node.js 14–16. Se estiver a correr Node 20+, npm install pode falhar silenciosamente ou gerar binários incompatíveis.
Correção: Use nvm (Node Version Manager) para instalar e alternar para a versão correta:
1nvm install 16
2nvm use 16
3npm installSe o repositório não especificar uma versão do Node, verifique o campo engines em package.json ou veja a configuração de CI.
Problemas de dependências em Python e configuração do Playwright
Problema: exige e Playwright com binários específicos do browser. Os utilizadores recebem erros como "browser not found" ou conflitos de dependências.
Correção: Use sempre um ambiente virtual e instale explicitamente os browsers do Playwright:
1python -m venv .venv
2source .venv/bin/activate # No Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installSe playwright install falhar, verifique no gestor de pacotes do sistema se faltam dependências, como libnss3 no Ubuntu.
Erros de permissões no Linux/Ubuntu
Problema: Executar sudo pip install corrompe o ambiente Python do sistema e gera problemas em cascata de dependências.
Correção: Nunca use sudo pip install. Crie sempre primeiro um ambiente virtual:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtIsto isola as dependências do scraper do Python do sistema.
Problemas de caminho e codificação no Windows
Problema: O CMD do Windows tem problemas de codificação e limites de comprimento de caminho que partem instalações de scraper, especialmente quando o Playwright faz download de binários do browser para diretórios muito aninhados.
Correção: Use WSL (Windows Subsystem for Linux) ou Git Bash em vez do CMD. O WSL dá-lhe um ambiente Linux completo dentro do Windows:
1wsl --install
2# Depois, abra um terminal WSL e siga os passos de setup do LinuxO atalho com Docker: salte totalmente os problemas de dependências
Problema: Tudo o que foi dito acima.
Correção: Se se sentir à vontade com Docker, coloque o ambiente do scraper em contentor. Um Dockerfile básico para um TikTok scraper em Python fica assim:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Isto garante um ambiente reproduzível, independentemente do sistema operativo do host. Se o scraper funciona no Docker, qualquer falha fora dele é um problema de ambiente, não de código.
Fluxograma de troubleshooting:
- O repositório consegue correr o próprio exemplo com sucesso? → Se não, verifique a versão do runtime.
- A versão do runtime está correta? → Verifique a instalação do browser/Playwright.
- O browser está instalado? → Verifique tokens/cookies.
- Tokens/cookies são válidos? → Verifique se o TikTok está a bloquear a sessão.
- Tudo isto falhou? → Assuma que o repositório partiu, não que foi erro do utilizador. Troque de ferramenta.
Melhores práticas anti-ban para scraping do TikTok (sem pagar por proxies)
Utilizadores de fóruns queixam-se repetidamente de bans e deteção: "eles fazem a sua conta ser banida, o que é um custo adicional" e "sem usar Apify ou APIs pagas caras". Aqui estão alternativas práticas e gratuitas que não exigem assinatura de proxy paga.

| Prática | Dificuldade | Custo | Efetividade |
|---|---|---|---|
| Atrasos aleatórios entre pedidos (jitter de 2–8s) | Fácil | Grátis | Moderada |
| Rotação de sessão/cookie | Média | Grátis | Moderada |
| Fazer scraping apenas de páginas públicas sem sessão iniciada | Fácil | Grátis | Moderada |
Respeitar robots.txt + headers de limitação de taxa | Fácil | Grátis | Básica |
| Randomização da fingerprint do browser headless (Playwright) | Média | Grátis | Alta |
| Usar endpoints da API móvel do TikTok (menor deteção) | Difícil | Grátis | Alta |
| Rotação de proxy residencial | Média | US$ 20–100/mês | Alta |
Técnicas gratuitas que realmente ajudam
Atrasos aleatórios entre pedidos. Não envie pedidos em loop apertado. Adicione um jitter aleatório de 2 a 8 segundos entre pedidos. É a coisa mais simples que pode fazer:
1import time, random
2time.sleep(random.uniform(2, 8))Reutilização de sessão e cookies. Não crie uma sessão completamente nova para cada pedido. Reutilize cookies e estado de sessão ao longo de um lote de pedidos e depois faça a rotação. É precisamente por isso que repositórios modernos pedem ms_token em vez de prometer scraping sem estado.
Faça scraping apenas de páginas públicas sem sessão iniciada. O que não suporta rotas autenticadas de utilizador e só funciona com dados visíveis quando se está deslogado. O scraping sem sessão tem um perfil de deteção mais baixo do que sessões autenticadas.
Respeite o robots.txt. O bloqueia muitos agentes por completo e só permite um conjunto limitado de caminhos públicos para crawling geral. Isto não autoriza scraping agressivo, mas respeitá-lo reduz a probabilidade de blacklist imediata do IP.
Técnicas intermédias para taxas de sucesso mais altas
Randomização da fingerprint do browser headless. Se estiver a usar Playwright, randomize o tamanho da viewport, o user-agent, o fuso horário e a localidade de cada sessão. Isto faz o scraper parecer um utilizador real diferente de cada vez, em vez do mesmo bot com um IP novo.
Uso dos endpoints móveis do TikTok. Alguns membros da comunidade relatam taxas de deteção mais baixas ao apontar para endpoints ao estilo mobile em vez da interface web. É mais difícil de implementar e menos documentado, mas é uma técnica real para utilizadores avançados.
Quando realmente precisa de proxy (e opções acessíveis)
Em escala, as técnicas gratuitas não chegam. A rotação de proxies residenciais é a abordagem padrão para scraping de alto volume no TikTok. Não vou recomendar aqui um serviço pago específico, mas a orientação geral é: evite proxies de data center (o TikTok sinaliza-os de forma agressiva) e procure pools de proxies residenciais ou móveis com rotação por pedido.
Como alternativa, ferramentas baseadas no browser como a contornam a questão do proxy porque correm na sua própria sessão de browser, imitando um utilizador real. Isto não as torna imunes à deteção em escala, mas, para casos típicos de marketing ou pesquisa — dezenas a centenas de páginas, não milhões —, é um caminho muito mais simples.
Que dados é que realmente obtém? Exemplos reais de saída de TikTok Scrapers
Os utilizadores querem saber que dados vão realmente receber antes de se comprometerem com uma ferramenta — e a maioria dos guias ignora esta parte por completo. Aqui estão estruturas de campos representativas, com base na documentação de origem.
Dados de perfil
| Nome de utilizador | Nome exibido | Seguidores | A seguir | Gostos totais | Bio | Verificado | URL do perfil |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1.240.000 | 312 | 48.700.000 | "Culinária + comédia 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890.000 | 150 | 22.100.000 | "Vlog de viagem 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2.100.000 | 88 | 91.300.000 | "Treinos e bem-estar" | ✅ | tiktok.com/@fitnessmaya |
Disponível em: scrapers do GitHub (TikTok-Api, Evil0ctal), Research API, Thunderbit (a partir de páginas visíveis de perfil).
Metadados de vídeo
| URL do vídeo | Legenda | Visualizações | Gostos | Comentários | Partilhas | Música | Hashtags | Data de publicação | Duração |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "A melhor dica de massa de sempre 🍝" | 4.200.000 | 312.000 | 8.400 | 21.000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: o teu gato está a julgar-te" | 9.100.000 | 1.100.000 | 23.000 | 55.000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "Rotina da manhã que ninguém pediu" | 1.800.000 | 98.000 | 3.200 | 7.500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
Disponível em: scrapers do GitHub (TikTok-Api, Evil0ctal), (campos incluem video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Dados de comentários
| Comentador | Texto do comentário | Gostos | Hora | Respostas |
|---|---|---|---|---|
| @user_abc | "Testei isto e funciona mesmo 😂" | 1.200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Coloca alho da próxima vez, acredita" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "É este tipo de conteúdo que eu queria ver" | 340 | 2026-03-16T11:30:00Z | 2 |
Disponível em: scrapers do GitHub (TikTok-Api, Evil0ctal), (campos incluem text, like_count, reply_count, create_time), Thunderbit (a partir das secções visíveis de comentários).
Dados de hashtags e pesquisa
| Hashtag | URL do vídeo principal | Visualizações agregadas | Em destaque |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4.200.000 | Sim |
| #cooking | tiktok.com/@chef/video/321 | 11.000.000 | Sim |
| #hack | tiktok.com/@tips/video/654 | 2.900.000 | Não |
Disponível em: scrapers do GitHub (varia consoante o repositório), Thunderbit ().
Nota: nenhum repositório único garante todos os campos o tempo todo. As estruturas de resposta do TikTok mudam, e até os mantenedores avisam para isso. Considere estes exemplos como representativos, não garantidos.
Como extrair dados do TikTok em 2 cliques com a Thunderbit (passo a passo)
Cansado do ciclo de quebrar e corrigir? Aqui está o caminho no-code — a saída de emergência para quem tentou e falhou com repositórios do GitHub.
- Instale a .
- Navegue até à página do TikTok que quer extrair — um perfil, uma página de resultados de pesquisa, uma página de hashtag ou um vídeo individual.
- Clique em "AI Suggest Fields". A IA da Thunderbit lê a página e sugere colunas: nome de utilizador, seguidores, legenda do vídeo, gostos, hashtags, etc.
- Ajuste os campos se necessário e clique em "Scrape". Os dados aparecem numa tabela estruturada.
- Use o scraping de subpáginas para enriquecer os dados. Clique em cada vídeo da listagem de perfil e puxe campos adicionais: legenda completa, detalhes da música, número de comentários, número de partilhas.
- Exporte para Google Sheets, Excel, Airtable ou Notion — totalmente grátis.
Sem manutenção, sem triagem de instalação, sem configuração anti-banimento. A IA adapta-se automaticamente às mudanças de layout do TikTok.
Enriquecendo dados do TikTok com scraping de subpáginas
Depois de extrair uma lista de vídeos de um perfil ou página de hashtag, clique em "Scrape Subpages" para que a IA visite cada página de vídeo e puxe campos adicionais. Isto é especialmente útil para profissionais de marketing que constroem bases de influenciadores ou fazem auditorias ao conteúdo de concorrentes — obtém uma tabela completa de dados de engagement ao nível de vídeo sem ter de clicar manualmente em dezenas de páginas.
Exportar e usar os seus dados do TikTok
A Thunderbit exporta para Google Sheets, Excel, Airtable, Notion, CSV ou JSON — tudo grátis. Casos de uso comuns:
- Colocar os dados numa folha de cálculo para análise de engagement.
- Enviar para o Airtable como rastreador de influenciadores ao estilo CRM.
- Levar para o Notion para colaboração da equipa em pesquisas de conteúdo.
Para uma visão mais aprofundada sobre como a Thunderbit trata a extração de dados da web, veja o nosso ou assista aos tutoriais no .
Manter-se dentro da lei: Termos de Serviço do TikTok e conformidade no scraping
A posição legal do TikTok é clara. O da plataforma diz que os Termos de Serviço proíbem scripts automatizados que recolhem informações ou interagem com o serviço de formas não autorizadas, e menciona explicitamente a tentativa de contornar restrições de acesso. As do TikTok também proíbem tentativas enganosas de obter informações através de scripts automatizados ou web crawling.
Orientação prática:
- Fique pelos dados publicamente disponíveis. Não faça scraping de conteúdo privado ou protegido por login.
- Respeite os limites de taxa. Não sobrecarregue os servidores do TikTok.
- Cumpra as leis de privacidade de dados. GDPR e CCPA continuam a aplicar-se se estiver a recolher, armazenar ou analisar dados pessoais.
- Use a Research API quando tiver elegibilidade. É o caminho mais seguro do ponto de vista da conformidade.
- Isto não é सलाह jurídica. Consulte um profissional para a sua situação específica.
Para saber mais sobre o panorama legal, veja o nosso guia sobre .
O que fazer quando o seu repositório de TikTok Scraper no GitHub morre
Resumo curto:
- Execute sempre o checklist de saúde do repositório de 60 segundos antes de clonar qualquer TikTok scraper do GitHub. A maioria dos repositórios já está morta.
- Perceba as suas opções. API oficial, scrapers do GitHub e ferramentas no-code servem utilizadores e casos de uso diferentes.
- Se optar pelo caminho do GitHub, reserve tempo para troubleshooting de instalação e configuração anti-banimento. Espere manutenção contínua.
- Saiba que dados vai realmente obter antes de se comprometer com uma ferramenta. Verifique os campos de saída, não apenas a contagem de estrelas.
- Se não é developer (ou está cansado de repositórios quebrados), experimente uma ferramenta no-code como a — dois cliques, dados estruturados, exportação gratuita.
Os dados do TikTok de que precisa estão acessíveis. A questão é se quer gastar o seu tempo a manter um scraper ou a usar realmente os dados. Escolha a abordagem que faz sentido para o seu nível técnico e caso de uso, e não deixe um repositório morto no GitHub desperdiçar outra tarde.
Perguntas frequentes
Existem scrapers de TikTok no GitHub que ainda funcionam em 2026?
Sim, mas a lista é curta. é a opção open source mais fiável com manutenção ativa até abril de 2026. também continua vivo, mas é mais complexo. O repositório com mais estrelas, drawrowfly/tiktok-scraper, não é atualizado desde maio de 2023 e está, na prática, morto. Execute sempre o checklist de saúde do repositório antes de investir tempo em qualquer repositório.
É legal fazer scraping do TikTok?
Os Termos de Serviço do TikTok proíbem explicitamente scraping automatizado. Dados visíveis publicamente entram numa zona jurídica cinzenta que varia consoante a jurisdição. O caminho mais seguro é a oficial para investigadores elegíveis. Se fizer scraping de dados públicos, mantenha-se em conteúdo acessível publicamente, respeite os limites de taxa e cumpra GDPR/CCPA. Isto não é aconselhamento jurídico — consulte um profissional para a sua situação.
Posso fazer scraping do TikTok sem programar?
Sim. Ferramentas de IA baseadas no browser, como a , permitem extrair dados estruturados do TikTok (perfis, metadados de vídeo, hashtags, métricas de engagement) sem escrever código. A TikTok Research API também exige programação mínima para candidatos aprovados. Para pessoas sem perfil técnico, as ferramentas no-code são o caminho mais rápido e fiável.
Que dados posso obter de um TikTok scraper?
Os tipos de dados mais comuns incluem informação de perfil (nome de utilizador, seguidores, bio, estado de verificação), metadados de vídeo (legenda, visualizações, gostos, comentários, partilhas, música, hashtags, duração, data de publicação), comentários (texto, gostos, hora, respostas) e dados de hashtags/pesquisa (vídeos principais, visualizações agregadas, estado de tendência). Os campos exatos dependem da ferramenta e do método — veja acima a secção com exemplos de saída para detalhes.
Por que razão o meu TikTok scraper continua a ser bloqueado?
O TikTok usa várias camadas de defesa anti-bot: limitação de taxa, bloqueio por cookie/sessão, fingerprint do navegador, deteção comportamental, parâmetros de pedido encriptados e fluxos de CAPTCHA. Causas comuns de bloqueio incluem enviar pedidos demasiado depressa, usar uma sessão limpa/nova para cada pedido, correr um browser headless com fingerprints padrão ou usar proxies de data center. Veja a secção de melhores práticas anti-ban acima para alternativas gratuitas e pagas.