A internet está cheia de informações, mas transformar esse mar de dados em algo realmente útil para o seu negócio? Aí é que mora o desafio — e também a grande chance de sair na frente. Depois de anos criando soluções SaaS e ferramentas de automação, vi de perto como o mundo deixou de tomar decisões só no feeling e passou a apostar tudo em dados. E não são só as gigantes da tecnologia: até times pequenos estão correndo atrás para extrair dados de sites e turbinar vendas, marketing, precificação e produto. Só que, conforme a web fica mais dinâmica e complexa, conseguir dados limpos, em conformidade e realmente valiosos virou outro nível de dificuldade.
Vamos direto ao ponto: vou te mostrar por que extrair dados de sites é tão importante para empresas modernas, os principais perrengues que você vai enfrentar e as melhores práticas (com aprendizados de quem vive isso no Thunderbit) para fazer tudo certo — dentro da lei, com eficiência e em escala. Seja você alguém lidando com conteúdo bagunçado, preocupado com a LGPD, ou só cansado de copiar e colar em planilha, esse guia é pra você.
Por Que Extrair Dados de Sites é Essencial para Empresas Modernas
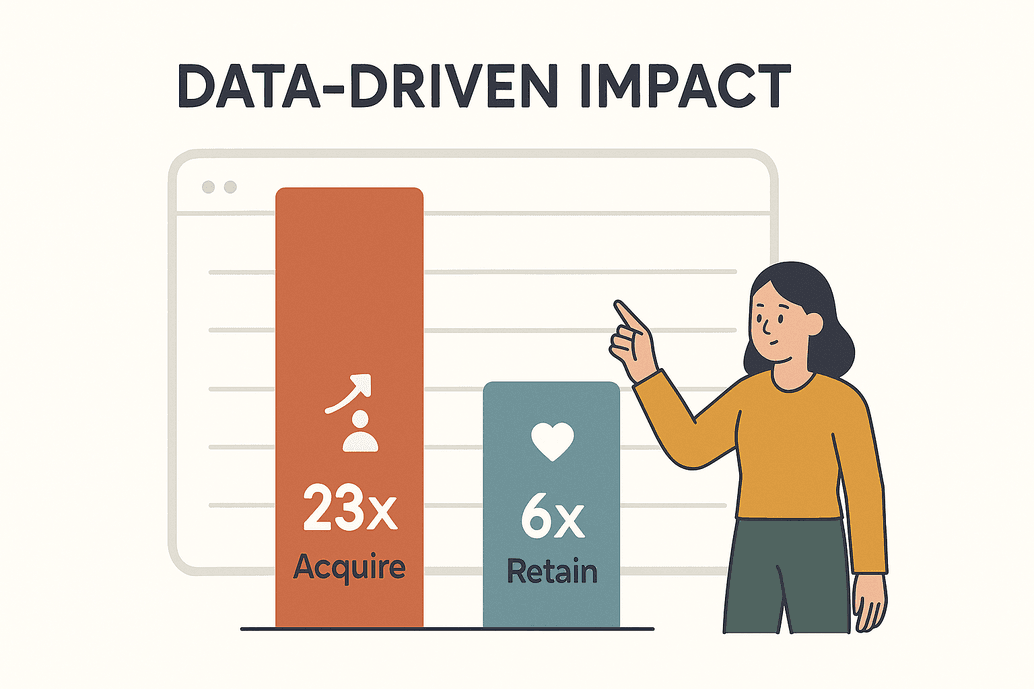 Dados não são só tendência — são o combustível das empresas que querem competir de verdade. De acordo com uma , organizações orientadas por dados têm 23 vezes mais chance de conquistar clientes e 6 vezes mais de mantê-los. Não é só impressionante — é questão de sobrevivência. Até 2025, empresas vão extrair dados de bilhões de páginas todos os dias para alimentar análises, IA e decisões em tempo real ().
Dados não são só tendência — são o combustível das empresas que querem competir de verdade. De acordo com uma , organizações orientadas por dados têm 23 vezes mais chance de conquistar clientes e 6 vezes mais de mantê-los. Não é só impressionante — é questão de sobrevivência. Até 2025, empresas vão extrair dados de bilhões de páginas todos os dias para alimentar análises, IA e decisões em tempo real ().
Como isso aparece no dia a dia? Olha só alguns exemplos que vejo toda semana:
| Aplicação de Negócio | Descrição & Benefícios | Exemplo/Estatística |
|---|---|---|
| Monitoramento de Preços | Acompanhe preços, estoques e promoções dos concorrentes em tempo real; ajuste sua estratégia para se manter à frente. | Mais de 80% dos maiores varejistas online monitoram preços da concorrência diariamente (kanhasoft.com). |
| Geração de Leads | Extraia contatos de diretórios, redes sociais ou sites de avaliações para captar novos leads. | Extração automatizada preenche CRMs muito mais rápido que pesquisa manual. |
| Análise de Tendências de Mercado | Reúna avaliações, fóruns e notícias para identificar tendências ou mudanças de sentimento rapidamente. | 26% das extrações focam em redes sociais para insights de tendências (blog.apify.com). |
| Agregação de Conteúdo | Colete notícias, listas de produtos ou eventos de vários sites para facilitar o acesso. | Equipes de mídia curam feeds para seus públicos. |
| Dados de Produto & Pesquisa | Reúna detalhes de produtos, avaliações ou dados de pesquisa para análise e desenvolvimento. | 67% dos consultores de investimento usam dados alternativos da web (scrap.io). |
| Treinamento de IA | Extraia grandes volumes de textos, imagens ou registros para treinar modelos de IA. | Cerca de 70% dos grandes modelos de IA dependem de dados extraídos da web (kanhasoft.com). |
Se você não está extraindo dados de sites, está não só atrás — está praticamente invisível no seu mercado. Já vi times de e-commerce triplicarem o ROI em seis meses só automatizando a coleta de preços dos concorrentes (). Resumindo: dados da web são um ativo estratégico, e saber extrair bem virou pré-requisito.
Principais Desafios ao Extrair Dados de Qualquer Site
Nem tudo são flores e arquivos CSV. A web é um ambiente caótico, e extrair dados de sites traz desafios reais:
- Dados Desestruturados: Cerca de 80% dos dados online não têm estrutura — estão em HTML bagunçado, espalhados por páginas ou escondidos atrás de elementos interativos. Transformar isso em uma tabela organizada não é tarefa simples ().
- Mudanças nos Sites: Os layouts mudam o tempo todo. Já vi raspadores quebrarem 15 vezes em um mês só porque o site-alvo mudou o design ().
- Volume e Escala: Empresas precisam extrair dados de centenas ou milhares de páginas — muitas vezes de forma recorrente. Copiar e colar manualmente não acompanha o ritmo.
- Defesas Anti-Scraping: CAPTCHAs, limites de acesso, áreas restritas... Os sites estão cada vez mais espertos para bloquear bots. Mais de um terço do tráfego da web já é de bots (), e as tecnologias anti-bot evoluem rápido.
- Erros Manuais: Copiar e colar é lento e sujeito a falhas. Um seletor errado e você coleta dados errados — ou nada.
Métodos tradicionais não escalam. Por isso, cada vez mais equipes buscam soluções automatizadas e inteligentes (e é por isso que aposto tanto em ferramentas com IA).
Boas Práticas Legais, de Conformidade e Segurança na Extração de Dados de Sites
Vamos ser sinceros: só porque você pode extrair dados de um site, não significa que deve — pelo menos sem pensar no lado legal e ético. Olha só o que toda empresa precisa saber:
- Dados Públicos vs. Privados: Extrair informações públicas geralmente é permitido em muitos países. Mas qualquer coisa atrás de login? Fora dos limites. Burlar autenticação não é permitido ().
- Termos de Uso: Sempre confira os Termos de Serviço do site. Se proíbe scraping, você pode ser processado ou bloqueado. Em caso de dúvida, peça permissão ou use APIs oficiais.
- Leis de Privacidade (LGPD, CCPA): Se for coletar dados pessoais, precisa de base legal (como interesse legítimo), deve minimizar a coleta e estar pronto para excluir dados se solicitado. Não cumprir pode gerar multas pesadas ().
- Respeite o robots.txt: Não é lei, mas é boa prática. Siga regras de crawl-delay e não sobrecarregue servidores.
- Segurança dos Dados: Trate os dados extraídos como sensíveis. Armazene com segurança, limite o acesso e limpe antes de usar.
Checklist de Conformidade:
| Consideração | Melhor Prática |
|---|---|
| Acesso Legal | Extraia apenas dados públicos; nunca burle logins (xbyte.io). |
| Termos de Serviço | Revise e respeite os Termos do site; use APIs se scraping for proibido. |
| Dados Pessoais | Evite se possível; se necessário, minimize e siga LGPD/CCPA. |
| robots.txt & Delays | Siga as regras do site; limite a frequência dos acessos. |
| Segurança dos Dados | Criptografe, restrinja acesso e exclua quando não precisar mais. |
Mais Eficiência: Como a IA Mudou o Jogo da Extração de Dados de Sites
Agora começa a parte boa. A IA virou o jogo na extração de dados de sites. Em vez de sofrer com seletores ou scripts frágeis, você pode usar ferramentas inteligentes que “leem” a página e entendem o que extrair — muitas vezes com só alguns cliques.
O que isso muda na prática?
- Configuração Mínima: Ferramentas com IA como o detectam campos automaticamente. É só clicar em “Sugerir Campos com IA” e a ferramenta já propõe as colunas certas — sem código, sem tentativa e erro.
- Adaptabilidade: Ferramentas com IA reconhecem padrões, não só layouts fixos. Se o site muda, a IA geralmente se adapta sozinha. Menos manutenção, menos dor de cabeça.
- Precisão: A IA filtra ruídos, remove duplicidades e até limpa dados bagunçados durante a extração. Algumas equipes relatam precisão de até 99,5% com extratores baseados em IA ().
- Conteúdo Dinâmico: Ferramentas com IA lidam com sites cheios de JavaScript, rolagem infinita e até extraem texto de imagens ou PDFs.
- Processamento em Tempo Real: Precisa traduzir, categorizar ou resumir dados enquanto extrai? A IA faz tudo de uma vez.
 Já vi equipes economizarem 30–40% do tempo na extração de dados só ao adotar ferramentas com IA (). Isso não é só produtividade — é vantagem competitiva.
Já vi equipes economizarem 30–40% do tempo na extração de dados só ao adotar ferramentas com IA (). Isso não é só produtividade — é vantagem competitiva.
O Thunderbit foi criado para deixar a extração fácil, precisa e acessível — até pra quem nunca programou. (E sim, minha mãe consegue usar. Netflix ainda é um desafio pra ela.)
Thunderbit AI Web Scraper: O Que Torna a Ferramenta Diferente
Deixa eu puxar a sardinha pro Thunderbit (afinal, é com orgulho mesmo!). O Thunderbit foi pensado pra quem trabalha com vendas, operações, marketing, imobiliário — gente que quer resultado, não dor de cabeça. Olha só o que faz a diferença:
- Sugerir Campos com IA: Um clique e a IA do Thunderbit analisa a página, sugere colunas e configura tudo pra você. Chega de mexer em seletor.
- Extração em 2 Cliques: Depois de definir os campos, é só clicar em “Extrair” e receber uma tabela limpinha — sem código, sem complicação.
- Extração de Subpáginas: Precisa de mais detalhes? O Thunderbit visita automaticamente cada subpágina (tipo páginas de produto ou perfil) e enriquece sua tabela com informações extras.
- Modelos Prontos: Para sites populares (Amazon, Zillow, Instagram, Shopify, etc.), é só escolher um modelo e começar — sem dor de cabeça.
- Exportação Livre: Exporte de graça para Excel, Google Sheets, Airtable, Notion ou CSV. Sem pegadinha.
- Extração Agendada: Automatize coletas recorrentes — só dizer o intervalo (“toda segunda às 8h”) e o Thunderbit faz o resto.
- Extração em Nuvem ou no Navegador: Use os servidores do Thunderbit pra velocidade ou seu próprio navegador pra sites que exigem login.
- Suporte Multilíngue: Extraia dados em 34 idiomas, incluindo português, inglês, espanhol, chinês e outros.
Automatize e Escale: Agendamento e Integrações para Extrair Dados
Ficar no scraping manual é coisa do passado. O segredo está em automatizar e integrar a extração de dados ao seu fluxo de trabalho:
- Extração Agendada: Programe o Thunderbit pra rodar coletas diariamente, semanalmente ou no intervalo que quiser. Perfeito pra monitorar preços, gerar leads ou agregar notícias.
- Integração Direta: Exporte os dados direto para Google Sheets, Excel, Airtable ou Notion. Chega de baixar e subir arquivo.
- Integração com CRM & Analytics: Mande os dados pro seu CRM ou BI pra dashboards em tempo real, alertas ou automação de contatos.
Exemplo: Monitoramento de Preços Automatizado
- Configure o Thunderbit na página de produto do concorrente.
- Use “Sugerir Campos com IA” pra capturar nome, preço e URL do produto.
- Programe a extração pra todo dia às 7h.
- Exporte os resultados pro Google Sheets, já conectado ao dashboard.
- O gerente de preços revisa as mudanças e ajusta a estratégia antes da concorrência.
Com automação, além de ganhar velocidade, você nunca fica desatualizado.
Boas Práticas para Lidar com Dados Desestruturados ao Extrair de Sites
Vamos falar a real: a maioria dos dados da web é desorganizada, inconsistente e, às vezes, bem confusa. Veja como colocar ordem na bagunça:
- Defina a Estrutura Antes: Use sugestões de campos com IA ou modelos pra organizar — decida colunas e tipos de dados antes de extrair.
- Prompts de IA por Campo: O Thunderbit permite adicionar instruções personalizadas pra cada campo. Quer categorizar produtos, formatar telefones ou traduzir descrições? Só avisar a IA.
- Aproveite NLP: Pra avaliações, comentários ou artigos, use recursos de NLP pra resumir, analisar sentimento ou extrair palavras-chave.
- Normalize os Dados: Padronize formatos (datas, preços, telefones) já na extração. Consistência é tudo.
- Remova Duplicatas e Valide: Elimine duplicidades e revise amostras pra garantir precisão. Se algo parecer estranho, ajuste os prompts ou configurações.
Prompts de IA por Campo: Personalize a Extração e Tenha Resultados Melhores
Esse é um dos meus recursos favoritos. Com prompts de IA por campo, você pode:
- Rotular e Categorizar: “Classifique este produto como Eletrônicos, Móveis ou Vestuário com base na descrição.”
- Padronizar Formatos: “Exiba a data no formato AAAA-MM-DD.” “Extraia só o valor numérico do preço.”
- Traduzir em Tempo Real: “Traduza a descrição do produto para português.”
- Limpar Ruídos: “Extraia a bio do usuário, ignorando links ‘Leia mais’ ou anúncios.”
- Combinar Campos: “Junte as linhas de endereço em um único campo.”
É como ter um estagiário digital dentro do seu raspador — e que nunca reclama do café.
Garantindo Qualidade e Consistência na Extração de Dados de Sites
Uma boa extração não termina ao clicar em “Exportar”. Veja como manter seus dados limpos e confiáveis:
- Validação: Use checagens de intervalo, campos obrigatórios e chaves únicas pra evitar erros.
- Auditoria de Amostras: Revise manualmente uma amostra dos dados extraídos comparando com o site — especialmente após configurar ou se o site mudar.
- Tratamento de Erros: Registre falhas e configure alertas pra anomalias (como queda brusca no número de linhas).
- Limpeza Contínua: Use planilhas ou scripts pra remover espaços, corrigir codificação e padronizar textos.
- Consistência de Esquema: Mantenha nomes e formatos de campos estáveis ao longo do tempo. Documente mudanças pra não deixar ninguém perdido.
Confiar nos dados é tudo. Um pouco de cuidado agora evita muita dor de cabeça depois.
Comparando Ferramentas: O Que Olhar Antes de Escolher
Nem todo raspador web é igual. Veja o que vale a pena analisar:
| Ferramenta | Pontos Fortes | Observações |
|---|---|---|
| Thunderbit | Mais fácil para quem não é técnico; detecção de campos com IA; extração de subpáginas; modelos prontos; exportação gratuita; planos acessíveis (Thunderbit Blog). | Não indicado para projetos gigantes ou muito técnicos; usa sistema de créditos. |
| Browse AI | Sem código, bom para monitorar mudanças; integração com Google Sheets; extração em lote. | Planos iniciais mais caros; configuração pode ser demorada. |
| Octoparse | Potente, lida com sites dinâmicos; recursos avançados para usuários técnicos. | Curva de aprendizado alta; preço elevado. |
| Web Scraper (webscraper.io) | Gratuito para projetos pequenos; configuração visual; comunidade ativa. | Configuração manual pode confundir; pouca assistência de IA. |
| Diffbot | Baseado em IA, interpreta páginas desestruturadas via API; ótimo para desenvolvedores. | Caro, baseado em API, não indicado para não técnicos. |
Minha dica: Se você é usuário de negócios e quer resultado rápido e preciso, o é uma ótima escolha. Para usuários avançados ou desenvolvedores, Octoparse ou Diffbot podem valer a complexidade extra. Sempre teste a versão gratuita antes de decidir.
Conclusão: Coloque as Melhores Práticas em Ação
Extrair dados de sites não é mais um “plus” — virou obrigação pra qualquer empresa que quer se manter competitiva. O que quero que você leve daqui:
- Valor: Dados da web geram decisões mais rápidas e inteligentes. Não desperdice esse potencial.
- Supere os Desafios: Use ferramentas com IA pra lidar com dados desestruturados, volume e mudanças nos sites.
- Esteja em Conformidade: Respeite leis de privacidade, regras dos sites e segurança dos dados.
- Automatize: Agende e integre a extração ao seu dia a dia.
- Qualidade em Primeiro Lugar: Valide, limpe e monitore seus dados pra manter a confiança.
Quer ver como é fácil? e teste no seu próximo projeto de dados. E se quiser se aprofundar, confira o pra mais guias, dicas e exemplos reais.
Boas extrações — e que seus dados estejam sempre organizados, em conformidade e prontos pra uso.
Perguntas Frequentes
1. É legal extrair dados de qualquer site?
No geral, extrair dados públicos é permitido em muitos países, mas evite burlar logins ou medidas de segurança. Sempre revise os termos de uso do site e siga leis de privacidade como LGPD e CCPA ().
2. Como a IA melhora o processo de extração de dados de sites?
Ferramentas com IA como o detectam campos automaticamente, se adaptam a mudanças de layout, limpam e formatam dados, e ainda lidam com conteúdo dinâmico ou traduções — tudo com configuração mínima e alta precisão ().
3. Quais as melhores práticas para lidar com dados desestruturados?
Defina a estrutura dos dados antes, use prompts de IA por campo para orientar a extração, normalize formatos durante a coleta e valide os resultados. Ferramentas como o Thunderbit facilitam categorizar, formatar e rotular dados em tempo real.
4. Como automatizar e escalar a extração de dados de sites?
Use recursos de agendamento para rodar extrações em intervalos regulares e integre os resultados diretamente em ferramentas como Google Sheets, Airtable ou seu CRM. A automação mantém os dados sempre atualizados e reduz o trabalho manual.
5. Como garantir a qualidade e consistência dos dados extraídos?
Implemente validações, audite amostras regularmente, trate erros de forma eficiente e mantenha o esquema de dados consistente ao longo do tempo. Monitoramento contínuo é essencial para dados confiáveis.
Quer ver essas práticas em ação? e descubra como a extração de dados web pode ser fácil, legal e escalável.
Saiba Mais