Xiaohongshu scraper

Zaufali nam profesjonaliści z czołowych firm














Odblokuj dane z Xiaohongshu w dwa kliknięcia
Bezproblemowe pobieranie danych w dwóch kliknięciach
Masz dość skomplikowanego kodu i nieskończonej konfiguracji tylko po to, by pobrać dane z Xiaohongshu? Thunderbit pozwala wyodrębnić kluczowe pola, takie jak note_id, author_id, author_nickname, note_title, note_content i like_count, bez napisania ani jednej linijki kodu. Po prostu wskaż potrzebne dane, a Thunderbit automatycznie wykryje pola i pobierze je jednym kliknięciem.
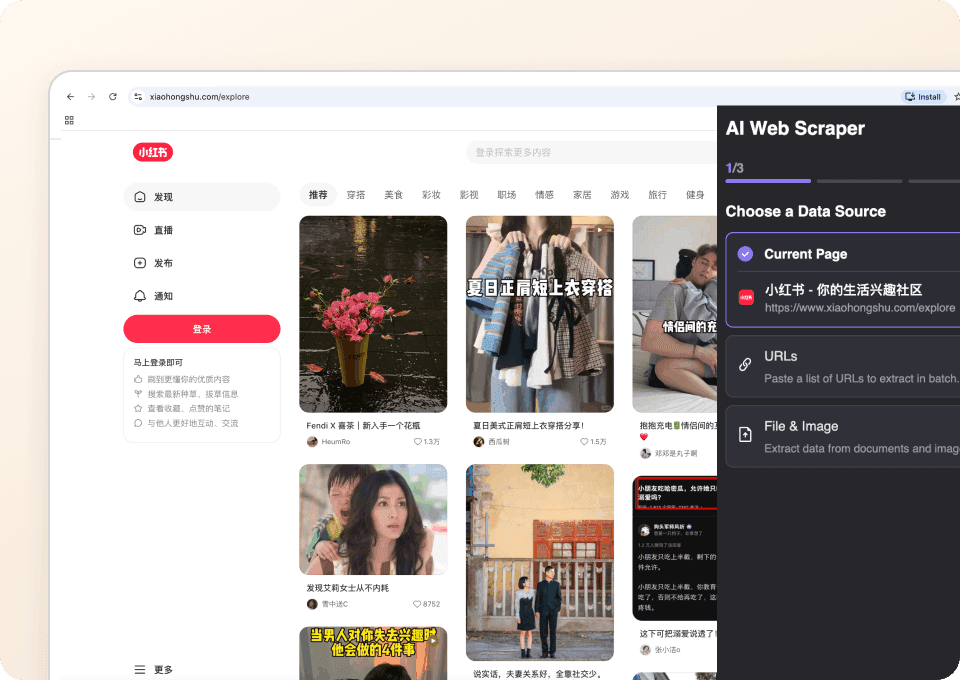
Poznaj pełny obraz automatycznie
Strony list w Xiaohongshu pokazują tylko wycinek informacji. Dzięki Thunderbit możesz automatycznie odwiedzać podstronę każdej notatki i bezpośrednio wyciągać szczegółowe informacje. Odkrywaj ukryte wnioski i uzyskaj pełny obraz, scrapując każdy istotny detal, a następnie dopisując go jako nowe kolumny w wybranym miejscu docelowym.
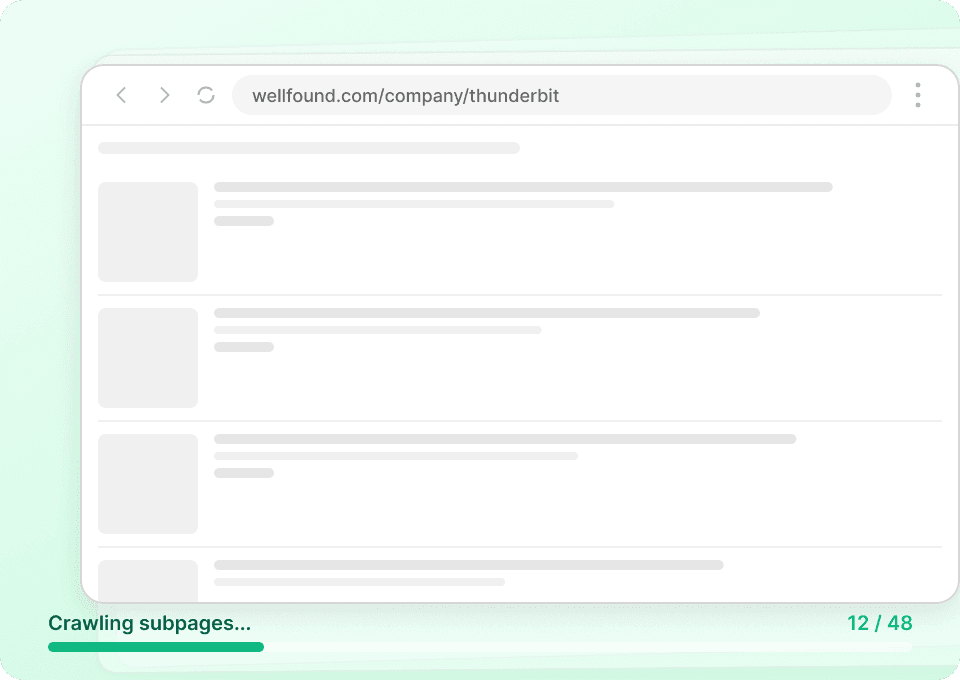
Zautomatyzuj monitorowanie danych z Xiaohongshu
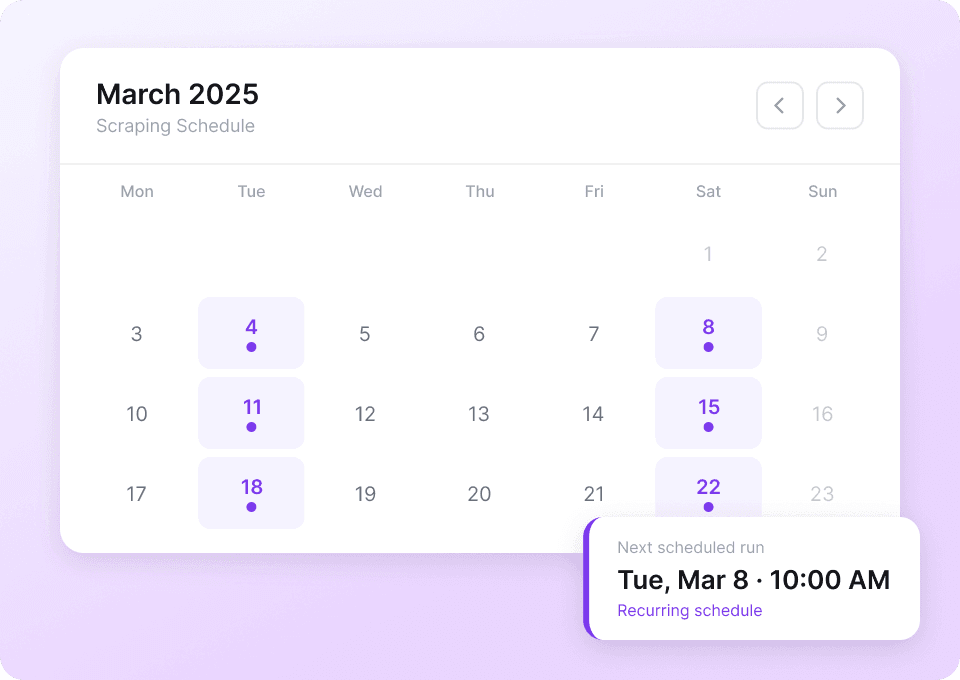
Dane w Xiaohongshu ciągle się zmieniają. Ręczne scrapowanie codziennie to uciążliwe zadanie. Harmonogramowane scrapowanie w Thunderbit pozwala ustawić cykliczne zadania, które automatycznie pobierają dane, takie jak like_count, w pełni bezobsługowo. Świeże informacje trafiają prosto do Google Sheets, Notion lub Airtable — bez żadnego wysiłku z Twojej strony.
Masz problem ze skutecznym scrapowaniem Xiaohongshu?
Zobacz, dlaczego Thunderbit to sprytniejszy sposób na wyodrębnianie danych z Xiaohongshu.
Traditional Scrapers
The old way of doing thingsThunderbit AI
The smarter approachNie wierz nam tylko na słowo
Zobacz, co użytkownicy mówią o Thunderbit.






Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.
Elgiganten Scraper
Zbierz nazwy produktów, ceny i informacje o dostępności z Elgiganten w zaledwie dwóch kliknięciach — całą ciężką pracę wykona za Ciebie AI Thunderbit.
Dowiedz się więcej ->
HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->
PlayStation Scraper
Odblokuj dane o grach PlayStation, takie jak tytuł, gatunek i cena po obniżce, kilkoma kliknięciami — bez ręcznego kopiowania i wklejania.
Dowiedz się więcej ->
Sports Direct Scraper
Wyciągaj nazwy produktów, ceny i procenty rabatów z Sports Direct dzięki AI Thunderbit — bez skomplikowanej konfiguracji i bez kodowania.
Dowiedz się więcej ->Substack scraper
Pobierz liczbę subskrybentów Substack, tytuły artykułów i opisy publikacji do przejrzystego arkusza — bez kodu, AI zajmie się strukturą danych.
Dowiedz się więcej ->Amazon price scraper
Przenieś ceny, oceny i ASIN-y z Amazon do Google Sheets dzięki scrapowaniu metodą wskaż i kliknij — bez skomplikowanej konfiguracji.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 specjalistów, którzy już używają Thunderbit do automatyzacji swoich procesów web scrapingu.
Bezpłatny okres próbny zapewnia nielimitowane kredyty na 8 stron.