Tumblr爬虫
Zaufali nam specjaliści z czołowych firm














Odblokuj dane z Tumblr dzięki Thunderbit
Bez wysiłku wyodrębniaj dane z Tumblr, takie jak treść posta i liczba polubień.
Poznaj pełną historię Tumblr
Strony z listami na Tumblr pokazują tylko fragmenty treści. Żeby zobaczyć pełny obraz, potrzebujesz całej zawartości posta, informacji o autorze i wszystkich powiązanych danych. Thunderbit automatycznie odwiedza każdą podstronę, wyodrębnia szczegóły i dodaje je jako nowe kolumny, dzięki czemu możesz łatwo pobrać post_id, post_date i więcej — bez ręcznego klikania.
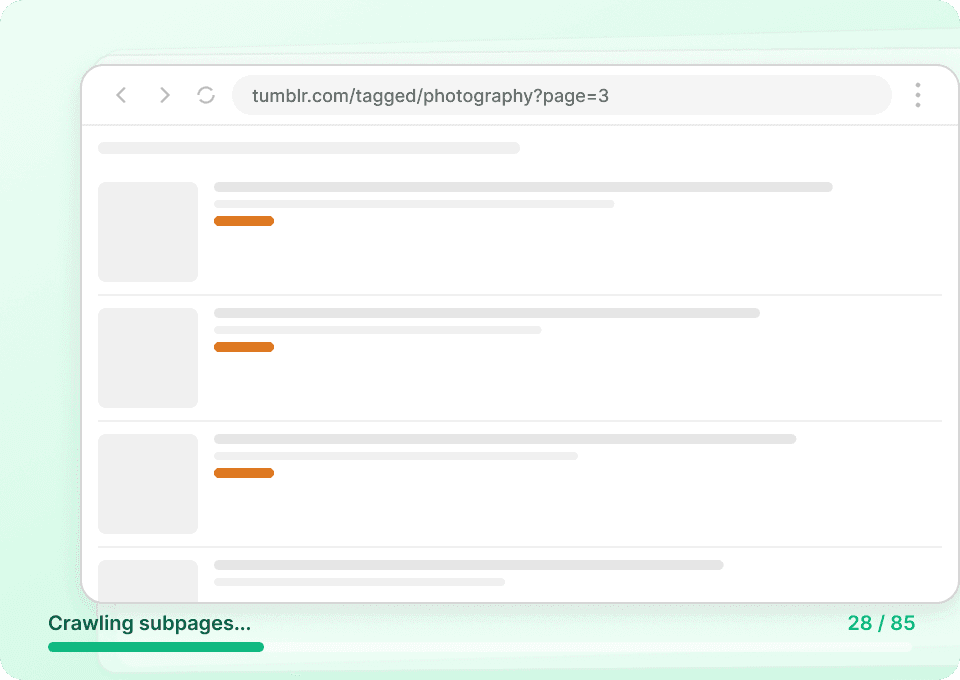
Zautomatyzuj zbieranie danych z Tumblr
Dane na Tumblr stale się zmieniają. Ręczne scrapowanie tych samych blogów w kółko to żmudne zadanie. Dzięki zaplanowanemu scrapowaniu w Thunderbit możesz ustawić powtarzalne zadania działające automatycznie. Otrzymuj świeże dane, takie jak like_count i post_content, bezpośrednio do Google Sheets, bez kiwnięcia palcem.
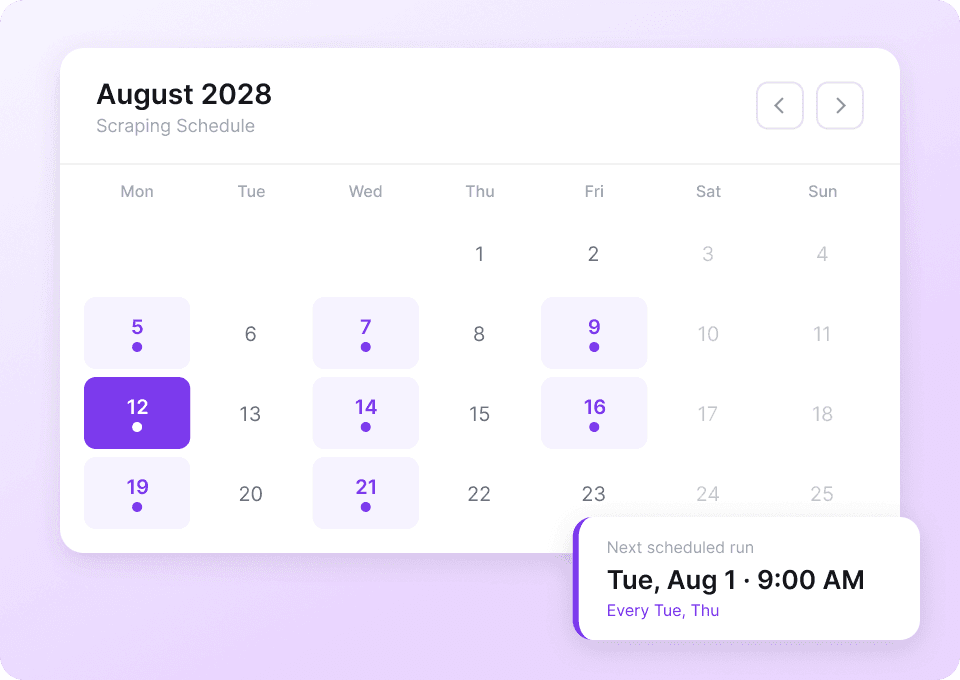
Zeskrob posty z Tumblr w dwóch kliknięciach
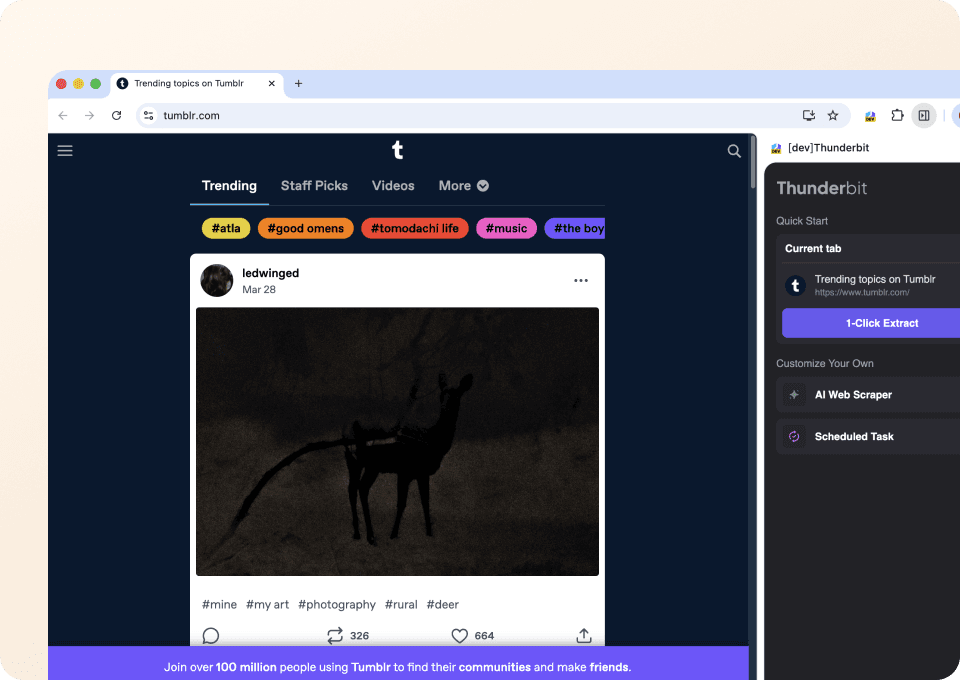
Zapomnij o skomplikowanym kodzie i selektorach CSS. Thunderbit pozwala wyodrębniać dane z Tumblr w zaledwie dwa kliknięcia. Po prostu wskaż interesujące Cię dane, a semantyczna AI Thunderbit wykryje odpowiednie pola — na przykład post_type i post_author — i je pobierze. Nie potrzebujesz kodowania, aby zdobyć dane, których szukasz na Tumblr.
Dlaczego Thunderbit różni się od tradycyjnych scraperów Tumblr?
Wyodrębniaj dane z Tumblr bez wysiłku, nawet gdy układ strony się zmienia lub niespodziewanie ewoluuje.
Tradycyjne scrapery
Stare podejście do zbierania danychThunderbit AI
Mądrzejsze podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.






Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.

Trustpilot scraper
Przekształć strony Trustpilot w przejrzysty arkusz z opiniami, ocenami i nazwami recenzentów. Czytamy każdą stronę za Ciebie, więc nie trzeba kodu ani kopiowania i wklejania.
Dowiedz się więcej ->Video Scraper
Video Scraper od Thunderbit pozwala w kilka kliknięć wyciągać z TikToka dane o filmach i twórcach z pomocą AI. Zbieraj listy filmów, metryki wyników i szczegóły profili, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion, aby prowadzić monitoring i research influencerów.
Dowiedz się więcej ->
Coupang scraper
Pobieraj nazwy produktów, ceny i stawki rabatów z Coupang w dwóch kliknięciach — bez kodowania.
Dowiedz się więcej ->
Wikipedia scraper
Pobieraj dane z infoboksów, przypisy i treść artykułów z Wikipedii do przejrzystego arkusza — bez kodu, AI zrobi strukturę za Ciebie.
Dowiedz się więcej ->
HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->
Scraper numerów telefonów z Craigslist
Scraper numerów telefonów z Craigslist od Thunderbit pomaga z pomocą AI wyciągać numery telefonów i szczegóły ogłoszeń z wyników wyszukiwania Craigslist. Zbieraj oferty, przechodź do każdego wpisu, aby pozyskać dane kontaktowe i dodatkowe pola, a następnie eksportuj do Excel, Google Sheets, Airtable, Notion, CSV lub JSON.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.