Prosty Reddit Scraper

Zaufali nam profesjonaliści z czołowych firm














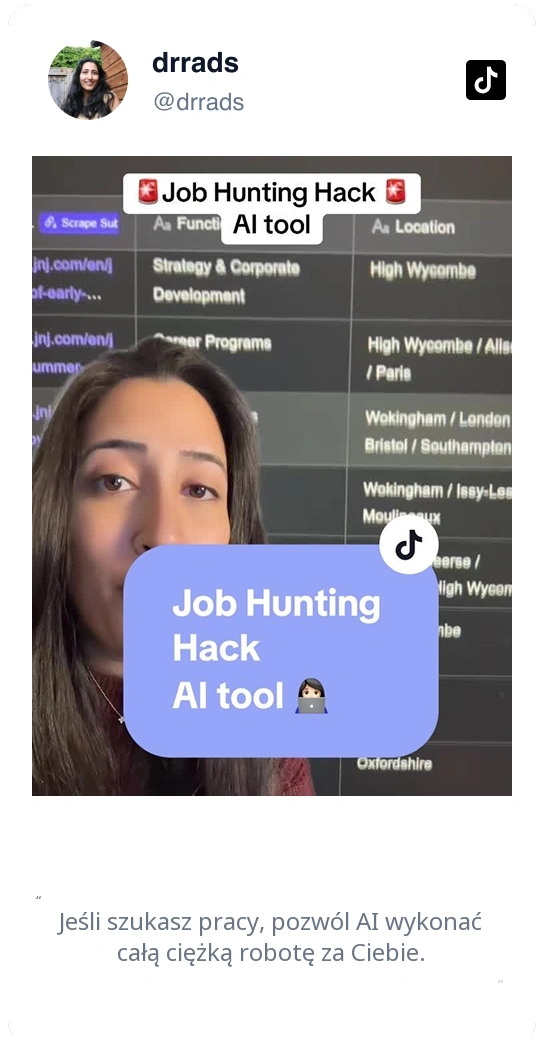
Odblokuj dane z Reddita w dwóch kliknięciach
Wyciągaj dane z Reddita w dwóch kliknięciach
Masz dość skomplikowanych scraperów, które wymagają kodowania? Thunderbit pozwala pobierać dane z Reddita, takie jak tytuły postów, treści, autorzy, subreddity i liczba upvote'ów, dosłownie w dwóch kliknięciach. Wystarczy wskazać potrzebne dane, a Thunderbit natychmiast rozpozna pola i je wyodrębni. Bez kodu, bez selektorów CSS, bez frustracji.
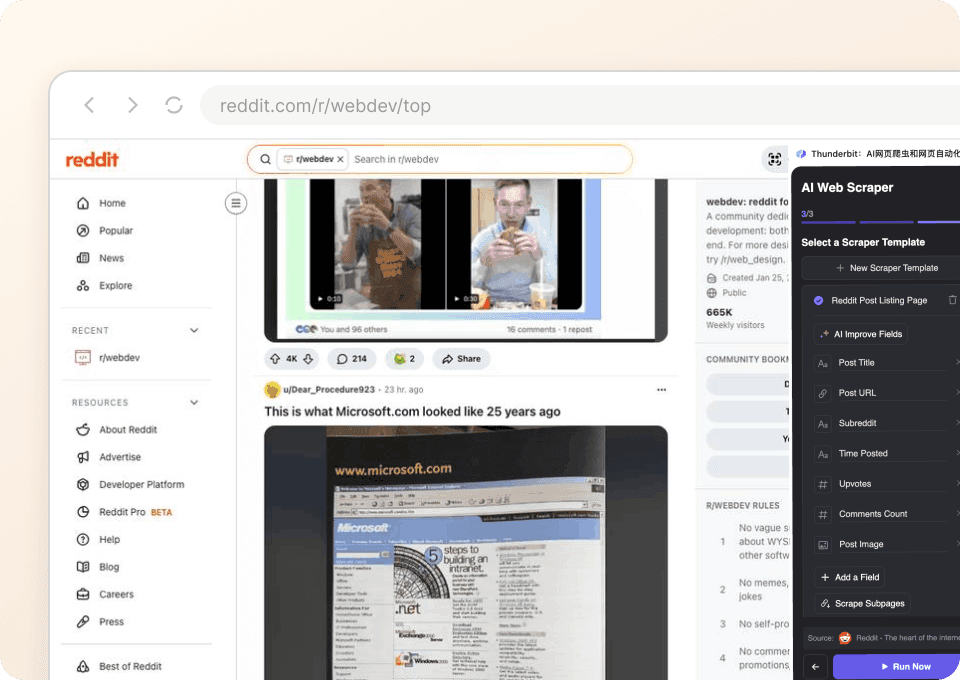
Dostosowuje się do zmian w układzie Reddita
Układ Reddita się zmienia, a większość scraperów przestaje działać. Thunderbit korzysta z semantycznej AI, która rozumie znaczenie strony, a nie tylko sztywne selektory. Dzięki temu automatycznie dopasowuje się do zmian w układzie, więc możesz bez przerw dalej zbierać dane o postach, autorach i subredditach.
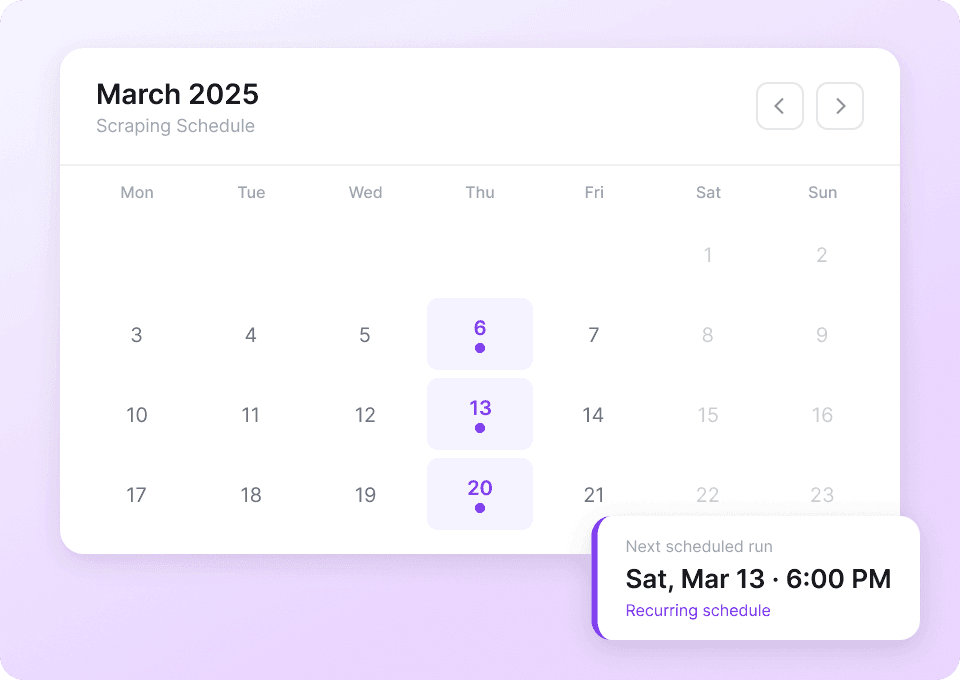
Zautomatyzuj zbieranie danych z Reddita
Dane z Reddita są stale aktualizowane. Thunderbit pozwala planować cykliczne zadania scrapowania w pełni automatycznie. Otrzymuj najnowsze tytuły postów, upvote'y i inne informacje prosto do Google Sheets, Notion lub Airtable, bez ręcznego uruchamiania scrapera. Utrzymuj dane na bieżąco bez żadnego wysiłku.
Masz dość problemów z pozyskiwaniem danych z Redfin?
Zobacz, dlaczego Thunderbit to najprostszy sposób na pobieranie danych z Redfin.
Tradycyjne scrapery
Stare podejście do tego zadaniaThunderbit
Bardziej inteligentne podejścieNie wierz tylko nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.





Najczęściej zadawane pytania
Powiązane przypadki użycia
Poznaj więcej zastosowań web scrapera Thunderbit.
Video Scraper
Video Scraper od Thunderbit pozwala w kilka kliknięć wyciągać z TikToka dane o filmach i twórcach z pomocą AI. Zbieraj listy filmów, metryki wyników i szczegóły profili, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion, aby prowadzić monitoring i research influencerów.
Dowiedz się więcej ->
Scraper Priceline
Zbieraj nazwy hoteli, ceny i oceny z Priceline w zaledwie kilka kliknięć dzięki AI od Thunderbit.
Dowiedz się więcej ->
Scraper numerów telefonów z Craigslist
Scraper numerów telefonów z Craigslist od Thunderbit pomaga z pomocą AI wyciągać numery telefonów i szczegóły ogłoszeń z wyników wyszukiwania Craigslist. Zbieraj oferty, przechodź do każdego wpisu, aby pozyskać dane kontaktowe i dodatkowe pola, a następnie eksportuj do Excel, Google Sheets, Airtable, Notion, CSV lub JSON.
Dowiedz się więcej ->
HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->Substack scraper
Pobierz liczbę subskrybentów Substack, tytuły artykułów i opisy publikacji do przejrzystego arkusza — bez kodu, AI zajmie się strukturą danych.
Dowiedz się więcej ->Amazon price scraper
Przenieś ceny, oceny i ASIN-y z Amazon do Google Sheets dzięki scrapowaniu metodą wskaż i kliknij — bez skomplikowanej konfiguracji.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 profesjonalistów, którzy już używają Thunderbit do automatyzacji procesów web scrapingu.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.