Scraper Goodreads

Zaufali nam profesjonaliści z czołowych firm














Wyodrębniaj dane z Goodreads w kilka sekund, a nie godzin
Dwa kliknięcia, aby scrapować dane z Goodreads
Masz dość ręcznego kopiowania tytułów książek, nazw autorów, ocen i liczby stron z Goodreads? Thunderbit pozwala wyodrębnić dane w zaledwie dwóch kliknięciach. Bez kodowania i bez skomplikowanej konfiguracji. Po prostu wskaż dane, których potrzebujesz, a nasza AI automatycznie wykryje pola i je wyodrębni.
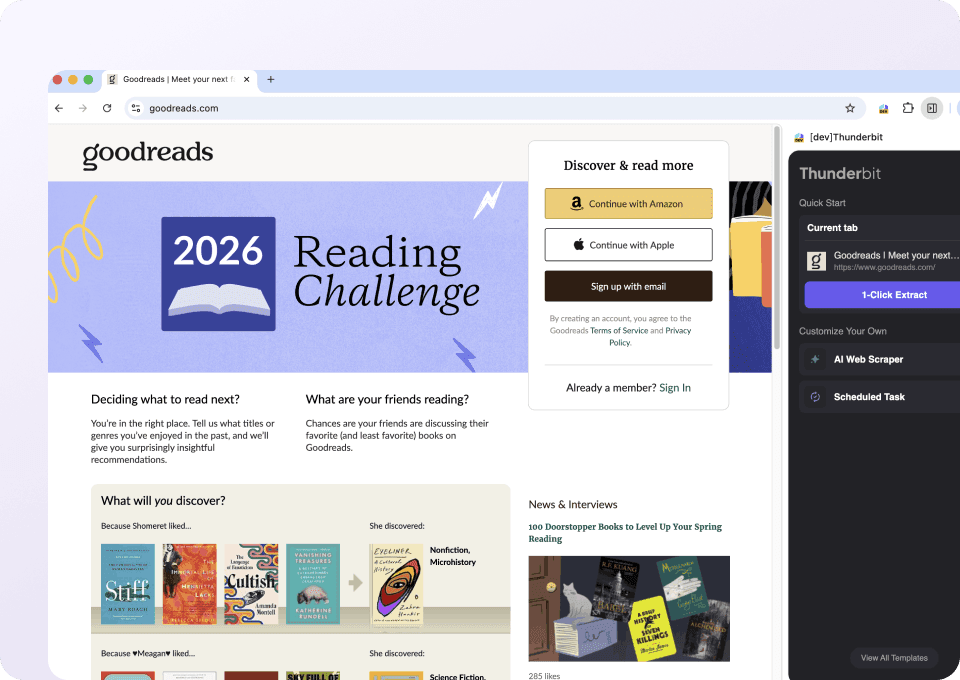
Czyste dane z Goodreads, gotowe do użycia
Dane z Goodreads potrafią być chaotyczne. Thunderbit automatycznie czyści je i strukturyzuje podczas wyodrębniania. Wyobraź sobie idealnie sformatowany arkusz Google Sheets z tytułami książek, autorami, średnią oceną, liczbą recenzji i liczbą stron — wszystko gotowe do analizy, bez ręcznego porządkowania.
Scrapuj setki stron Goodreads
Ręczne scrapowanie Goodreads, strona po stronie, jest żmudne i czasochłonne. Thunderbit może automatycznie zeskrobać setki stron Goodreads naraz. Wystarczy podać listę adresów URL, a on szybko i sprawnie wyodrębni dane o książkach, autorach lub inne potrzebne informacje.

Masz dość scrapowania Goodreads?
Zobacz, jak Thunderbit upraszcza wyodrębnianie danych z Goodreads.
Tradycyjne scrapery
Stare podejście do tematuThunderbit
Bardziej inteligentne podejścieNie wierz tylko nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.






Najczęściej zadawane pytania
Powiązane przypadki użycia
Poznaj więcej zastosowań web scrapera Thunderbit.

Trivago scraper
Wyodrębniaj nazwy hoteli, ceny i oceny z Trivago w zaledwie kilka kliknięć — bez kodowania i bez konfiguracji.
Dowiedz się więcej ->
HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->Substack scraper
Pobierz liczbę subskrybentów Substack, tytuły artykułów i opisy publikacji do przejrzystego arkusza — bez kodu, AI zajmie się strukturą danych.
Dowiedz się więcej ->
PlayStation Scraper
Odblokuj dane o grach PlayStation, takie jak tytuł, gatunek i cena po obniżce, kilkoma kliknięciami — bez ręcznego kopiowania i wklejania.
Dowiedz się więcej ->
PubMed Scraper
PubMed Scraper od Thunderbit pozwala z pomocą AI wyciągać uporządkowane dane z wyników wyszukiwania PubMed oraz stron artykułów. Zbieraj popularne publikacje medyczne, dowody z badań klinicznych, streszczenia, autorów, afiliacje, daty publikacji i linki, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion.
Dowiedz się więcej ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 profesjonalistów, którzy już używają Thunderbit do automatyzacji procesów web scrapingu.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.